omówienie pozyskiwania danych Azure Synapse Data Explorer (wersja zapoznawcza)
Pozyskiwanie danych to proces służący do ładowania rekordów danych z co najmniej jednego źródła w celu zaimportowania danych do tabeli w puli Azure Synapse Data Explorer. Po pozyskiwaniu dane staną się dostępne dla zapytań.
Usługa zarządzania danymi Azure Synapse Data Explorer, która jest odpowiedzialna za pozyskiwanie danych, implementuje następujący proces:
- Ściąga dane w partiach lub przesyła strumieniowo ze źródła zewnętrznego i odczytuje żądania z oczekującej kolejki platformy Azure.
- Dane wsadowe przepływające do tej samej bazy danych i tabeli są zoptymalizowane pod kątem przepływności pozyskiwania.
- Dane początkowe są weryfikowane, a format jest konwertowany w razie potrzeby.
- Dalsze manipulowanie danymi, w tym dopasowywanie schematu, organizowanie, indeksowanie, kodowanie i kompresowanie danych.
- Dane są utrwalane w magazynie zgodnie z zasadami przechowywania zestawu.
- Pozyskane dane są zatwierdzane w aplecie, gdzie są dostępne dla zapytań.
Obsługiwane formaty danych, właściwości i uprawnienia
Właściwości pozyskiwania: właściwości wpływające na sposób pozyskiwania danych (na przykład tagowanie, mapowanie, czas tworzenia).
Uprawnienia: aby pozyskać dane, proces wymaga uprawnień na poziomie ingestora bazy danych. Inne akcje, takie jak zapytanie, mogą wymagać uprawnień administratora bazy danych, użytkownika bazy danych lub administratora tabeli.
Przetwarzanie wsadowe a pozyskiwanie przesyłania strumieniowego
Pozyskiwanie wsadowe wykonuje przetwarzanie wsadowe danych i jest zoptymalizowane pod kątem wysokiej przepływności pozyskiwania. Ta metoda jest preferowanym i najbardziej wydajnym typem pozyskiwania. Dane są wsadowe zgodnie z właściwościami pozyskiwania. Małe partie danych są scalane i zoptymalizowane pod kątem szybkich wyników zapytań. Zasady przetwarzania wsadowego pozyskiwania można ustawić w bazach danych lub tabelach. Domyślnie maksymalna wartość przetwarzania wsadowego to 5 minut, 1000 elementów lub całkowity rozmiar 1 GB. Limit rozmiaru danych dla polecenia pozyskiwania wsadowego wynosi 4 GB.
Pozyskiwanie danych przesyłanych strumieniowo trwa pozyskiwanie danych ze źródła przesyłania strumieniowego. Pozyskiwanie przesyłania strumieniowego umożliwia niemal rzeczywiste opóźnienie dla małych zestawów danych na tabelę. Dane są początkowo pozyskiwane do magazynu wierszy, a następnie przenoszone do zakresów magazynu kolumn.
Metody pozyskiwania i narzędzia
Azure Synapse Data Explorer obsługuje kilka metod pozyskiwania, z których każdy ma własne scenariusze docelowe. Te metody obejmują narzędzia pozyskiwania, łączniki i wtyczki do różnych usług, potoków zarządzanych, pozyskiwanie programowe przy użyciu zestawów SDK i bezpośredni dostęp do pozyskiwania.
Pozyskiwanie przy użyciu potoków zarządzanych
W przypadku organizacji, które chcą zarządzać (ograniczanie przepustowości, ponawianie prób, monitory, alerty i inne) wykonywane przez usługę zewnętrzną, użycie łącznika jest prawdopodobnie najbardziej odpowiednim rozwiązaniem. Pozyskiwanie w kolejce jest odpowiednie dla dużych woluminów danych. Azure Synapse Data Explorer obsługuje następujące usługi Azure Pipelines:
- Event Hub: potok, który przesyła zdarzenia z usług do Azure Synapse Data Explorer. Aby uzyskać więcej informacji, zobacz Pozyskiwanie danych z centrum zdarzeń do Azure Synapse Data Explorer.
- Potoki usługi Synapse: w pełni zarządzana usługa integracji danych dla obciążeń analitycznych w potokach usługi Synapse łączy się z ponad 90 obsługiwanymi źródłami w celu zapewnienia wydajnego i odpornego transferu danych. Potoki usługi Synapse przygotowują, przekształcają i wzbogacają dane w celu uzyskania szczegółowych informacji, które można monitorować na różne sposoby. Ta usługa może być używana jako jednorazowe rozwiązanie na okresowej osi czasu lub wyzwalane przez określone zdarzenia.
Programowe pozyskiwanie przy użyciu zestawów SDK
Azure Synapse Data Explorer udostępnia zestawy SDK, których można używać do pozyskiwania zapytań i danych. Programowe pozyskiwanie jest zoptymalizowane pod kątem zmniejszenia kosztów pozyskiwania (COG), minimalizując transakcje magazynu podczas procesu pozyskiwania i postępując zgodnie z tym procesem.
Przed rozpoczęciem wykonaj następujące kroki, aby uzyskać punkty końcowe puli Data Explorer do konfigurowania pozyskiwania programowego.
W Synapse Studio w okienku po lewej stronie wybierz pozycję Zarządzaj>Data Explorer pule.
Wybierz pulę Data Explorer, której chcesz użyć, aby wyświetlić jego szczegóły.
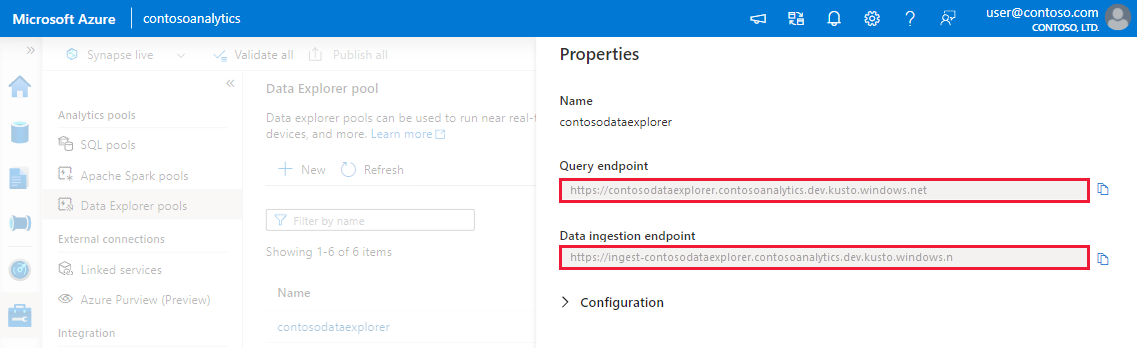
Zanotuj punkty końcowe pozyskiwania zapytań i danych. Użyj punktu końcowego zapytania jako klastra podczas konfigurowania połączeń z pulą Data Explorer. Podczas konfigurowania zestawów SDK na potrzeby pozyskiwania danych użyj punktu końcowego pozyskiwania danych.
Dostępne zestawy SDK i projekty open source
narzędzia
- Pozyskiwanie jednym kliknięciem: umożliwia szybkie pozyskiwanie danych przez utworzenie i dostosowanie tabel z szerokiego zakresu typów źródłowych. Pozyskiwanie jednym kliknięciem automatycznie sugeruje tabele i struktury mapowania na podstawie źródła danych w Azure Synapse Data Explorer. Pozyskiwanie jednym kliknięciem może służyć do jednorazowego pozyskiwania lub do definiowania ciągłego pozyskiwania za pośrednictwem usługi Event Grid w kontenerze, do którego pozyskano dane.
język zapytań Kusto polecenia sterowania pozyskiwaniem
Istnieje wiele metod, za pomocą których dane można pozyskiwać bezpośrednio do aparatu za pomocą poleceń język zapytań Kusto (KQL). Ponieważ ta metoda pomija usługi Zarządzanie danymi, jest ona odpowiednia tylko do eksploracji i tworzenia prototypów. Nie używaj tej metody w scenariuszach produkcyjnych ani dużych ilości.
Pozyskiwanie wbudowane: do aparatu jest wysyłane polecenie sterowania . ingest wbudowane , a dane, które mają być pozyskiwane jako część samego tekstu polecenia. Ta metoda jest przeznaczona do improwizowanych celów testowych.
Pozyskiwanie z zapytania: polecenie sterujące . set, .append, .set-or-append lub .set-or-replace jest wysyłane do aparatu, z danymi określonymi pośrednio jako wyniki zapytania lub polecenia.
Pozyskiwanie z magazynu (ściąganie): polecenie sterowania pozyskiwanie do jest wysyłane do aparatu, a dane przechowywane w niektórych magazynach zewnętrznych (na przykład Azure Blob Storage) dostępne przez aparat i wskazywane przez polecenie.
Przykład użycia poleceń sterowania pozyskiwaniem można znaleźć w temacie Analyze with Data Explorer (Analizowanie za pomocą Data Explorer).
Proces pozyskiwania
Po wybraniu najbardziej odpowiedniej metody pozyskiwania dla Twoich potrzeb wykonaj następujące czynności:
Ustawianie zasad przechowywania
Dane pozyskane do tabeli w Azure Synapse Data Explorer podlegają obowiązującym zasadom przechowywania tabeli. Jeśli nie ustawiono tego jawnie dla tabeli, obowiązujące zasady przechowywania pochodzą z zasad przechowywania bazy danych. Przechowywanie na gorąco jest funkcją rozmiaru klastra i zasad przechowywania. Pozyskiwanie większej ilości danych niż dostępne miejsce spowoduje wymusi na pierwszym miejscu przechowywanie danych na zimno.
Upewnij się, że zasady przechowywania bazy danych są odpowiednie dla Twoich potrzeb. W przeciwnym razie przesłoń ją jawnie na poziomie tabeli. Aby uzyskać więcej informacji, zobacz zasady przechowywania.
Tworzenie tabeli
Aby pozyskać dane, należy wcześniej utworzyć tabelę. Skorzystaj z jednej z następujących opcji:
Utwórz tabelę za pomocą polecenia . Przykład użycia polecenia create a table można znaleźć w temacie Analyze with Data Explorer (Analizowanie przy użyciu Data Explorer).
Utwórz tabelę przy użyciu pozyskiwania jednym kliknięciem.
Uwaga
Jeśli rekord jest niekompletny lub nie można przeanalizować pola jako wymaganego typu danych, odpowiednie kolumny tabeli zostaną wypełnione wartościami null.
Tworzenie mapowania schematu
Mapowanie schematu pomaga powiązać pola danych źródłowych z kolumnami tabeli docelowej. Mapowanie umożliwia przejmowanie danych z różnych źródeł do tej samej tabeli na podstawie zdefiniowanych atrybutów. Obsługiwane są różne typy mapowań, zarówno zorientowane na wiersz (CSV, JSON i AVRO) oraz zorientowane na kolumny (Parquet). W większości metod mapowania można również wstępnie utworzyć w tabeli i odwołać się do parametru polecenia pozyskiwania.
Ustawianie zasad aktualizacji (opcjonalnie)
Niektóre mapowania formatu danych (Parquet, JSON i Avro) obsługują proste i przydatne przekształcenia czasu pozyskiwania. W przypadku, gdy scenariusz wymaga bardziej złożonego przetwarzania w czasie pozyskiwania, użyj zasad aktualizacji, które umożliwiają uproszczone przetwarzanie przy użyciu poleceń język zapytań Kusto. Zasady aktualizacji automatycznie uruchamia wyodrębniania i przekształcenia na pozyskanych danych w oryginalnej tabeli i pozyskiwają wynikowe dane w co najmniej jednej tabeli docelowej. Ustaw zasady aktualizacji.