Samouczek, część 3. Trenowanie i rejestrowanie modelu uczenia maszynowego
W tym samouczku nauczysz się trenować wiele modeli uczenia maszynowego, aby wybrać najlepszy, aby przewidzieć, którzy klienci bankowi prawdopodobnie odejdą.
W tym samouczku wykonasz następujące elementy:
- Trenowanie modeli Random Forest i LightGBM.
- Natywna integracja usługi Microsoft Fabric z platformą MLflow umożliwia rejestrowanie wytrenowanych modeli uczenia maszynowego, używanych hiperparametrów i metryk oceny.
- Zarejestruj wytrenowany model uczenia maszynowego.
- Ocena wydajności wytrenowanych modeli uczenia maszynowego na zestawie danych weryfikacji.
MLflow to platforma typu open source do zarządzania cyklem życia uczenia maszynowego za pomocą funkcji takich jak Śledzenie, Modele i Rejestr modeli. Platforma MLflow jest natywnie zintegrowana z środowiskiem Nauka o danych sieci szkieletowej.
Wymagania wstępne
Uzyskaj subskrypcję usługi Microsoft Fabric. Możesz też utworzyć konto bezpłatnej wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika środowiska po lewej stronie głównej, aby przełączyć się na środowisko usługi Synapse Nauka o danych.
Jest to część 3 z 5 w serii samouczków. Aby ukończyć ten samouczek, najpierw wykonaj następujące czynności:
- Część 1. Pozyskiwanie danych do usługi Microsoft Fabric Lakehouse przy użyciu platformy Apache Spark.
- Część 2. Eksplorowanie i wizualizowanie danych przy użyciu notesów usługi Microsoft Fabric, aby dowiedzieć się więcej o danych.
Postępuj zgodnie z instrukcjami w notesie
3-train-evaluate.ipynb to notes, który towarzyszy temu samouczkowi.
Aby otworzyć towarzyszący notes na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w temacie Przygotowywanie systemu do celów nauki o danych, aby zaimportować notes do obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu pamiętaj, aby dołączyć usługę Lakehouse do notesu .
Ważne
Dołącz ten sam jezioro, którego użyto w części 1 i części 2.
Instalowanie bibliotek niestandardowych
W tym notesie zainstalujesz niezrównoważone środowisko learn (zaimportowane jako imblearn) przy użyciu polecenia %pip install. Niezrównoważona nauka to biblioteka syntetycznej techniki oversampling Mniejszości (SMOTE), która jest używana podczas radzenia sobie z niezrównoważonymi zestawami danych. Jądro PySpark zostanie uruchomione ponownie po %pip installsystemie , dlatego przed uruchomieniem innych komórek należy zainstalować bibliotekę.
Dostęp do programu SMOTE uzyskasz przy użyciu imblearn biblioteki. Zainstaluj ją teraz przy użyciu wbudowanych funkcji instalacji (np. %pip, %conda).
# Install imblearn for SMOTE using pip
%pip install imblearn
Ważne
Uruchom tę instalację za każdym razem, gdy ponownie uruchomisz notes.
Podczas instalowania biblioteki w notesie jest ona dostępna tylko przez czas trwania sesji notesu, a nie w obszarze roboczym. Jeśli ponownie uruchomisz notes, musisz ponownie zainstalować bibliotekę.
Jeśli masz bibliotekę, której często używasz, i chcesz udostępnić ją wszystkim notesom w obszarze roboczym, możesz w tym celu użyć środowiska sieci szkieletowej. Możesz utworzyć środowisko, zainstalować w nim bibliotekę, a następnie administrator obszaru roboczego może dołączyć środowisko do obszaru roboczego jako domyślne środowisko. Aby uzyskać więcej informacji na temat ustawiania środowiska jako domyślnego obszaru roboczego, zobacz Zestawy domyślne biblioteki dla obszaru roboczego.
Aby uzyskać informacje na temat migrowania istniejących bibliotek obszarów roboczych i właściwości platformy Spark do środowiska, zobacz Migrowanie bibliotek obszarów roboczych i właściwości platformy Spark do środowiska domyślnego.
Ładowanie danych
Przed rozpoczęciem trenowania dowolnego modelu uczenia maszynowego należy załadować tabelę różnicową z usługi Lakehouse, aby odczytać oczyszczone dane utworzone w poprzednim notesie.
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generowanie eksperymentu na potrzeby śledzenia i rejestrowania modelu przy użyciu biblioteki MLflow
W tej sekcji pokazano, jak wygenerować eksperyment, określić model uczenia maszynowego i parametry trenowania, a także metryki oceniania, trenować modele uczenia maszynowego, rejestrować je i zapisywać wytrenowane modele do późniejszego użycia.
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment" # MLflow experiment name
Rozszerzanie możliwości automatycznego rejestrowania MLflow działa przez automatyczne przechwytywanie wartości parametrów wejściowych i metryk wyjściowych modelu uczenia maszynowego podczas trenowania. Te informacje są następnie rejestrowane w obszarze roboczym, gdzie można uzyskać do niego dostęp i wizualizować przy użyciu interfejsów API platformy MLflow lub odpowiedniego eksperymentu w obszarze roboczym.
Wszystkie eksperymenty z odpowiednimi nazwami są rejestrowane i będzie można śledzić ich parametry i metryki wydajności. Aby dowiedzieć się więcej na temat automatycznego rejestrowania, zobacz Automatyczne rejestrowanie w usłudze Microsoft Fabric.
Ustawianie specyfikacji eksperymentu i automatycznego rejestrowania
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
Importowanie biblioteki scikit-learn i lightGBM
Dzięki danym można teraz zdefiniować modele uczenia maszynowego. W tym notesie zastosujesz modele Random Forest i LightGBM. Użyj scikit-learn funkcji i lightgbm , aby zaimplementować modele w kilku wierszach kodu.
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Przygotowywanie zestawów danych trenowania, walidacji i testowania
train_test_split Użyj funkcji z scikit-learn , aby podzielić dane na zestawy trenowania, walidacji i testowania.
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
Zapisywanie danych testowych w tabeli delty
Zapisz dane testowe w tabeli delty do użycia w następnym notesie.
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
Stosowanie funkcji SMOTE do danych treningowych w celu syntetyzowania nowych próbek dla klasy mniejszości
Eksploracja danych w części 2 wykazała, że z 10 000 punktów danych odpowiadających 10 000 klientom tylko 20 037 klientów (około 20%) opuściło bank. Oznacza to, że zestaw danych jest wysoce niezrównoważony. Problem z niezrównoważonymi klasyfikacjami polega na tym, że istnieje zbyt mało przykładów klasy mniejszości dla modelu, aby skutecznie nauczyć się granicy decyzyjnej. SMOTE to najczęściej stosowane podejście do syntezowania nowych próbek dla klasy mniejszości. Dowiedz się więcej o smOTE tutaj i tutaj.
Napiwek
Należy pamiętać, że funkcja SMOTE powinna być stosowana tylko do zestawu danych treningowych. Aby uzyskać prawidłowe przybliżenie sposobu działania modelu uczenia maszynowego na oryginalnych danych, które reprezentują sytuację w środowisku produkcyjnym, należy pozostawić zestaw danych testowych.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Napiwek
Możesz bezpiecznie zignorować komunikat ostrzegawczy platformy MLflow wyświetlany podczas uruchamiania tej komórki.
Jeśli zostanie wyświetlony komunikat ModuleNotFoundError , nie można uruchomić pierwszej komórki w tym notesie, która instaluje bibliotekę imblearn . Należy zainstalować tę bibliotekę za każdym razem, gdy ponownie uruchomisz notes. Wróć i ponownie uruchom wszystkie komórki, zaczynając od pierwszej komórki w tym notesie.
Trenowanie modelu
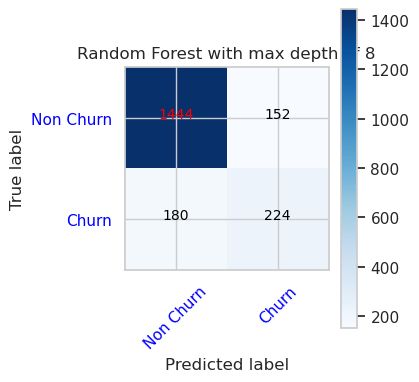
- Trenowanie modelu przy użyciu lasu losowego z maksymalną głębokością 4 i 4 cech
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- Trenowanie modelu przy użyciu lasu losowego z maksymalną głębokością 8 i 6 funkcji
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
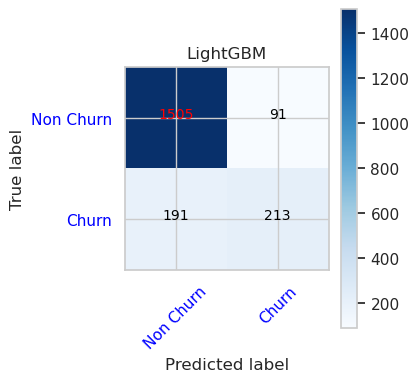
- Trenowanie modelu przy użyciu rozwiązania LightGBM
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Artefakt eksperymentów na potrzeby śledzenia wydajności modelu
Przebiegi eksperymentu są automatycznie zapisywane w artefaktie eksperymentu, który można znaleźć w obszarze roboczym. Są one nazwane na podstawie nazwy używanej do ustawiania eksperymentu. Rejestrowane są wszystkie wytrenowane modele uczenia maszynowego, ich przebiegi, metryki wydajności i parametry modelu.
Aby wyświetlić eksperymenty:
Na panelu po lewej stronie wybierz swój obszar roboczy.
W prawym górnym rogu filtruj, aby wyświetlić tylko eksperymenty, aby ułatwić znalezienie szukanych eksperymentów.

Znajdź i wybierz nazwę eksperymentu, w tym przypadku bank-churn-experiment. Jeśli nie widzisz eksperymentu w obszarze roboczym, odśwież przeglądarkę.



Ocena wydajności wytrenowanych modeli na zestawie danych weryfikacji
Po zakończeniu trenowania modelu uczenia maszynowego można ocenić wydajność wytrenowanych modeli na dwa sposoby.
Otwórz zapisany eksperyment z obszaru roboczego, załaduj modele uczenia maszynowego, a następnie oceń wydajność załadowanych modeli w zestawie danych weryfikacji.
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBMBezpośrednio oceń wydajność wytrenowanych modeli uczenia maszynowego na zestawie danych weryfikacji.
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
W zależności od preferencji jedno podejście jest dobre i powinno oferować identyczne wyniki. W tym notesie wybierzesz pierwsze podejście, aby lepiej zademonstrować możliwości automatycznego rejestrowania MLflow w usłudze Microsoft Fabric.
Pokaż wyniki prawdziwie/fałszywie dodatnie/ujemne przy użyciu macierzy pomyłek
Następnie utworzysz skrypt, aby wykreślić macierz pomyłek, aby ocenić dokładność klasyfikacji przy użyciu zestawu danych weryfikacji. Macierz pomyłek można również wykreślić przy użyciu narzędzi SynapseML, które są wyświetlane w przykładzie Wykrywania oszustw, który jest dostępny tutaj.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- Macierz pomyłek dla klasyfikatora lasu losowego z maksymalną głębokością 4 i 4 cech
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
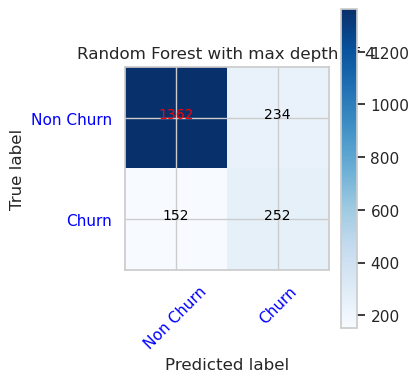
- Macierz pomyłek dla klasyfikatora lasu losowego z maksymalną głębokością 8 i 6 cech
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
- Macierz pomyłek dla lightGBM
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()