Opisywanie normalizacji
Normalizacja bazy danych to proces projektowania używany do organizowania danego zestawu danych w tabele i kolumny w bazie danych. Każda tabela powinna zawierać dane odnoszące się do określonej "rzeczy" i zawierać tylko dane, które obsługują te same "rzeczy" zawarte w tabeli. Celem tego procesu jest zmniejszenie zduplikowanych danych zawartych w bazie danych w celu zmniejszenia obniżenia wydajności wstawień i aktualizacji bazy danych. Na przykład zmiana adresu klienta jest znacznie łatwiejsza do zaimplementowania, jeśli jedynym miejscem przechowywania adresu klienta jest tabela Klienci. Najbardziej typowe formy normalizacji to pierwsza, druga i trzecia postać normalna. Poniżej opisano je.
Pierwsza postać normalna
Pierwsza postać normalna ma następujące specyfikacje:
- Tworzenie oddzielnej tabeli dla każdego zestawu powiązanych danych
- Eliminowanie powtarzających się grup w poszczególnych tabelach
- Identyfikowanie każdego zestawu powiązanych danych przy użyciu klucza podstawowego
W tym modelu nie należy używać wielu kolumn w jednej tabeli do przechowywania podobnych danych. Jeśli na przykład produkt może zawierać wiele kolorów, nie należy mieć wielu kolumn w jednym wierszu zawierającym różne wartości kolorów. Pierwsza tabela poniżej (ProductColors) nie jest w pierwszej postaci normalnej, ponieważ istnieją powtarzające się wartości koloru. W przypadku produktów z tylko jednym kolorem jest zmarnowana przestrzeń. A co zrobić, jeśli produkt przyszedł w więcej niż trzech kolorach? Zamiast ustawiać maksymalną liczbę kolorów, możemy ponownie utworzyć tabelę, jak pokazano w drugiej tabeli ProductColor. Mamy również wymóg pierwszego normalnego formularza, że istnieje unikatowy klucz dla tabeli, który jest kolumną (lub kolumnami), których wartość unikatowo identyfikuje wiersz. Żadna z kolumn w drugiej tabeli nie jest unikatowa, ale razem kombinacja wartości ProductID i Color jest unikatowa. Gdy potrzebnych jest wiele kolumn, nazywamy to kluczem złożonym.
| Productid | Kolor1 | Kolor2 | Kolor3 |
|---|---|---|---|
| 1 | Czerwony | Green (Zielony) | Yellow |
| 2 | Yellow | ||
| 3 | Niebieskie | Czerwony | |
| 4 | Niebieskie | ||
| 5 | Czerwony |
| Productid | Kolor |
|---|---|
| 1 | Czerwony |
| 1 | Green (Zielony) |
| 1 | Yellow |
| 2 | Yellow |
| 3 | Niebieskie |
| 3 | Czerwony |
| 4 | Niebieskie |
| 5 | Czerwony |
Trzecia tabela ProductInfo jest w pierwszej postaci normalnej, ponieważ każdy wiersz odwołuje się do określonego produktu, nie ma powtarzających się grup i mamy kolumnę ProductID do użycia jako klucz podstawowy.
| Productid | Productname | Cena | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | Widget | 15.95 | Stany Zjednoczone | — USA |
| 2 | Foop | 41.95 | Zjednoczone Królestwo | Zjednoczone Królestwo |
| 3 | Glombit | 49.95 | Zjednoczone Królestwo | Zjednoczone Królestwo |
| 100 | Sorfin | 99,99 | Republika Filipin | RepPhil |
| 5 | Śruba macierzowa | 29.95 | Stany Zjednoczone | — USA |
Druga postać normalna
Druga postać normalna ma następującą specyfikację, oprócz tych wymaganych przez pierwszą formę normalną:
- Jeśli tabela ma klucz złożony, wszystkie atrybuty muszą zależeć od kompletnego klucza, a nie tylko jego części.
Drugi normalny formularz dotyczy tylko tabel z kluczami złożonymi, na przykład w tabeli ProductColor, która jest drugą tabelą powyżej. Rozważmy przypadek, w którym tabela ProductColor zawiera również cenę produktu. Ta tabela ma klucz złożony w kolumnach ProductID i Color, ponieważ tylko przy użyciu obu wartości kolumn możemy jednoznacznie zidentyfikować wiersz. Jeśli cena produktu nie zmienia się wraz z kolorem, możemy zobaczyć dane, jak pokazano w poniższej tabeli:
| Productid | Kolor | Cena |
|---|---|---|
| 1 | Czerwony | 15.95 |
| 1 | Green (Zielony) | 15.95 |
| 1 | Yellow | 15.95 |
| 2 | Yellow | 41.95 |
| 3 | Niebieskie | 49.95 |
| 3 | Czerwony | 49.95 |
| 4 | Niebieskie | 99,95 |
| 5 | Czerwony | 29.95 |
Powyższa tabela nie znajduje się w drugiej postaci normalnej. Wartość ceny zależy od identyfikatora ProductID, ale nie od koloru. Istnieją trzy wiersze dla identyfikatora ProductID 1, więc cena tego produktu jest powtarzana trzy razy. Problem z naruszeniem drugiej normalnej formy polega na tym, że jeśli musimy zaktualizować cenę, musimy upewnić się, że aktualizujemy ją wszędzie. Jeśli zaktualizujemy cenę w pierwszym wierszu, ale nie drugą lub trzecią, będziemy mieć coś o nazwie "anomalia aktualizacji". Po aktualizacji nie będziemy w stanie określić, jaka była rzeczywista cena produktu ProductID 1. Rozwiązaniem jest przeniesienie kolumny Price (Cena) do tabeli, która ma wartość ProductID jako pojedynczy klucz kolumny, ponieważ jest to jedyna kolumna, od których zależy cena. Na przykład możemy użyć tabeli 3 do przechowywania ceny.
Jeśli cena produktu była inna na podstawie jego koloru, czwarta tabela będzie w drugiej postaci normalnej, ponieważ cena będzie zależeć od obu części klucza: ProductID i Color.
Trzecia postać normalna
Trzecia normalna forma jest zwykle celem większości baz danych OLTP. Trzecia postać normalna ma następującą specyfikację, oprócz tych wymaganych przez drugą formę normalną:
- Wszystkie kolumny niekluczowe są nieumiejętnie zależne od klucza podstawowego.
Relacja przechodnia oznacza, że jedna kolumna w tabeli jest powiązana z innymi kolumnami za pośrednictwem drugiej kolumny. Zależność oznacza, że kolumna może pochodzić z innej wartości w wyniku zależności. Na przykład wiek można określić od daty urodzenia, co zależy od daty urodzenia. Wróć do trzeciej tabeli ProductInfo. Ta tabela jest w drugiej postaci normalnej, ale nie w trzeciej. Kolumna ShortLocation jest zależna od kolumny ProductionCountry, która nie jest kluczem. Podobnie jak druga forma normalna, naruszenie trzeciej normalnej formy może prowadzić do aktualizacji anomalii. W przypadku zaktualizowania parametru ShortLocation w jednym wierszu będziemy mieli niespójne dane, ale nie zaktualizowaliśmy ich we wszystkich wierszach, w których wystąpiła ta lokalizacja. Aby temu zapobiec, możemy utworzyć oddzielną tabelę do przechowywania nazw krajów/regionów i skróconych formularzy.
Denormalizacja
Chociaż trzecia normalna forma jest teoretycznie pożądana, nie zawsze jest to możliwe dla wszystkich danych. Ponadto znormalizowana baza danych nie zawsze zapewnia najlepszą wydajność. Znormalizowane dane często wymagają wielu operacji sprzężenia, aby uzyskać wszystkie niezbędne dane zwrócone w jednym zapytaniu. Istnieje kompromis między normalizacją danych, gdy liczba sprzężeń wymaganych do zwrócenia wyników zapytania ma wysokie wykorzystanie procesora CPU, a zdenormalizowane dane, które mają mniej sprzężeń i mniej wymaganego procesora CPU, ale otwiera możliwość anomalii aktualizacji.
Uwaga
Zdenormalizowane dane nie są takie same jak nieznormalizowane. W przypadku denormalizacji zaczynamy od projektowania tabel, które są znormalizowane. Następnie możemy dodać dodatkowe kolumny do niektórych tabel, aby zmniejszyć wymaganą liczbę sprzężeń, ale jak to zrobimy, wiemy o możliwych anomaliach aktualizacji. Następnie upewniamy się, że mamy wyzwalacze lub inne rodzaje przetwarzania, które zapewnią, że po wykonaniu aktualizacji wszystkie zduplikowane dane również zostaną zaktualizowane.
Zdenormalizowane dane mogą być bardziej wydajne do wykonywania zapytań, szczególnie w przypadku dużych obciążeń odczytu, takich jak magazyn danych. W takich przypadkach posiadanie dodatkowych kolumn może oferować lepsze wzorce zapytań i/lub więcej uproszczonych zapytań.
Schemat gwiazdy
Podczas gdy większość normalizacji ma na celu obciążenia OLTP, magazyny danych mają własną strukturę modelowania, która jest zwykle zdenormalizowanym modelem. W tym projekcie są używane tabele faktów, które rejestrują pomiary lub metryki dla określonych zdarzeń, takich jak sprzedaż, i łączą je z tabelami wymiarów, które są mniejsze pod względem liczby wierszy, ale mogą zawierać dużą liczbę kolumn do opisania danych faktów. Niektóre przykładowe wymiary obejmują spis, czas i/lub lokalizację geograficzną. Ten wzorzec projektu służy do ułatwiania wykonywania zapytań w bazie danych i oferowania zysków wydajności dla obciążeń odczytu.
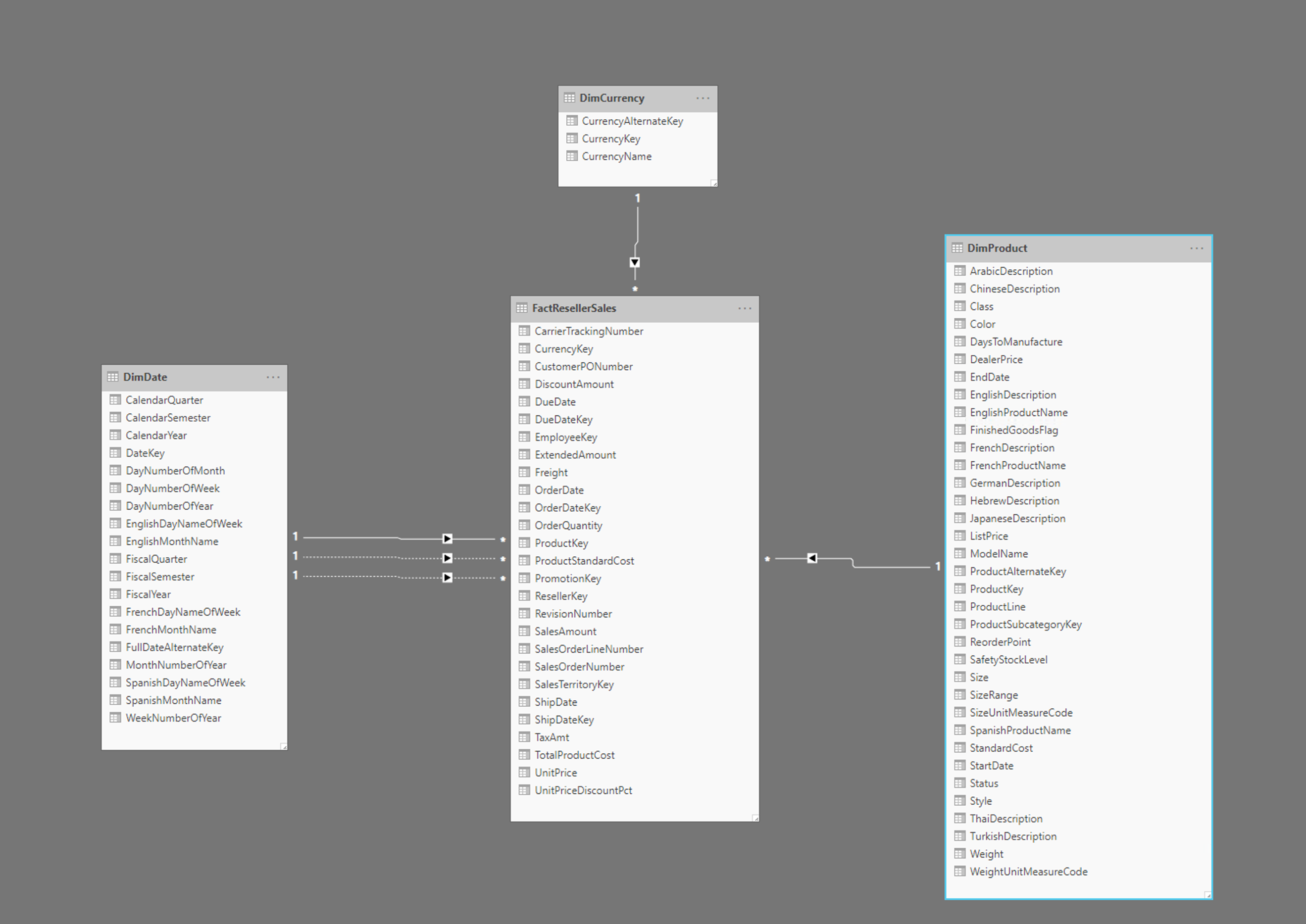
Na powyższej ilustracji przedstawiono przykład schematu gwiazdy, w tym tabelę faktów FactResellerSales oraz wymiary daty, waluty i produktów. Tabela faktów zawiera dane związane z transakcjami sprzedaży, a wymiary zawierają tylko dane powiązane z określonym elementem danych sprzedaży. Na przykład tabela FactResellerSales zawiera tylko wartość ProductKey , aby wskazać, który produkt został sprzedany. Wszystkie szczegóły dotyczące każdego produktu są przechowywane w tabeli DimProduct i powiązane z tabelą faktów z kolumną ProductKey .
Powiązany z projektem schematu gwiazdy jest schemat płatka śniegu, który używa zestawu bardziej znormalizowanych tabel dla pojedynczej jednostki biznesowej. Na poniższej ilustracji przedstawiono przykład pojedynczego wymiaru schematu płatka śniegu. Wymiar Products jest znormalizowany i przechowywany w trzech tabelach o nazwie DimProductCategory, DimProductSubcategory i DimProduct.
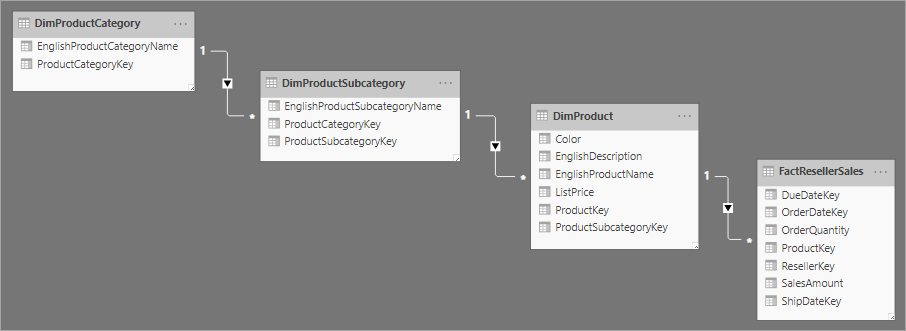
Główną różnicą między schematami gwiazdy i płatka śniegu jest to, że wymiary w schemacie płatka śniegu są znormalizowane w celu zmniejszenia nadmiarowości, co pozwala zaoszczędzić miejsce do magazynowania. Kompromis polega na tym, że zapytania wymagają większej liczby sprzężeń, co może zwiększyć złożoność i zmniejszyć wydajność.