Improve query performance on memory optimized tables with Temporal using new index creation enhancement in SP1
Reviewed by: Dimitri Furman,Sanjay Mishra, Mike Weiner
With the introduction of the Temporal feature in SQL 2016 and Azure SQL Database, there is an ability to time travel through the state of data as it was at any given point of time. Alongside In-Memory OLTP, Temporal on memory optimized tables allows you to harness the speed of In-Memory OLTP, and gives you the same ability to track history and audit every change made to a record. Temporal added to memory optimized tables also allows you to maintain a “smaller” memory optimized tables and thereby a smaller memory footprint by deleting data that isn’t “hot” anymore from the current memory optimized table, which in turn moves it to the history table without having an external archival process to do that.
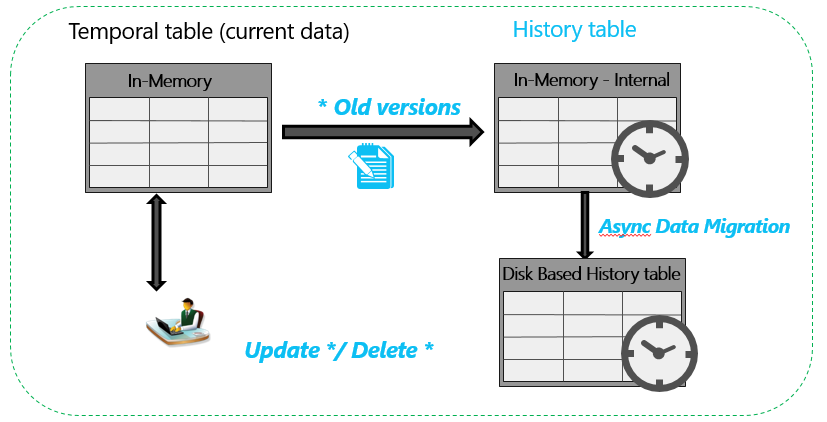
When memory optimized and temporal tables are combined, an internal memory optimized table is created in addition to the history table, as depicted in the diagram below. Data is flushed asynchronously from the internal in-memory History table to the disk based history table. The flush interval isn’t currently configurable. Data is flushed when the internal table reaches 8% of the memory consumed by the current table, OR you can flush it manually by executing the procedure sys.sp_xtp_flush_temporal_history. The internal memory optimized table is created with the same column definitions as the current in-memory table, but with a single index.
Let’s walk through some code snippets to demonstrate this:
1. Create a new database and the Orders table which is our memory optimized "current" table
CREATE DATABASE [TestTemporalDb1];
ALTER DATABASE [TestTemporalDb1]
ADD FILEGROUP [IMOLTP] CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE [TestTemporalDb1]
ADD FILE (name='TestTemporalDb1_Mod1', FILENAME='D:\Temp\TestTemporalDb1_Mod1') TO FILEGROUP [IMOLTP];
USE [TestTemporalDb1]
GO
CREATE TABLE [dbo].[Orders](
[OrderId] [INT] Identity NOT NULL,
[StoreID] int NOT NULL,
[CustomerID] int NOT NULL,
[OrderDate] [datetime] NOT NULL,
[DeliveryDate] datetime NULL,
[Amount] float,
[Notes] [NVARCHAR] (max) NULL,
[ValidFrom] [datetime2](7) NOT NULL,
[ValidTo] [datetime2](7) NOT NULL,
CONSTRAINT [PK_OrderID] PRIMARY KEY NONCLUSTERED (OrderId)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
2. Create the Orders_History table, which can be a rowstore, or columnstore, and have its own indexing scheme based on how you intend to query the history. If aggregations are being done on the history data, a columnstore index is likely the better choice. Given that the history table can grow large if many changes to the current table are made, it is usually a good idea to partition the history table. Partitioning is also recommended as you cannot directly delete from a history table outside of a partition swap without turning off system versioning. For more details: https://msdn.microsoft.com/en-us/library/mt637341.aspx . For the sake of simplicity, this example will not have partitioning implemented.
CREATE TABLE [dbo].[Orders_History](
[OrderId] [INT] NOT NULL,
[StoreID] int NOT NULL,
[CustomerID] int NOT NULL,
[OrderDate] [datetime] NOT NULL,
[DeliveryDate] datetime NULL,
[Amount] float,
[Notes] [NVARCHAR] (max) NULL,
[ValidFrom] [datetime2](7) NOT NULL,
[ValidTo] [datetime2](7) NOT NULL,
);
-- Create custom Indexing on the Temporal History table
CREATE CLUSTERED INDEX [IX_Order_History]
ON [dbo].[Orders_History] ( ValidTo, ValidFrom) WITH (DATA_COMPRESSION = PAGE)
-- Default Clustered index is on ValidFrom and ValidTo times
CREATE NONCLUSTERED INDEX [IX_OrderHistory_OrderId] ON [dbo].[Orders_History]
(
[OrderId] ASC,
ValidTo,
ValidFrom
) ;
GO
3. Turn on system versioning, defining the columns that are period columns, and the history table.
-- Make Temporal
ALTER TABLE [dbo].[Orders] ADD PERIOD FOR SYSTEM_TIME (ValidFrom,ValidTo);
GO
ALTER TABLE [dbo].[Orders] ALTER COLUMN ValidTo ADD HIDDEN;
ALTER TABLE [dbo].[Orders] ALTER COLUMN ValidFrom ADD HIDDEN;
GO
-- Enable Temporal
ALTER TABLE [dbo].[Orders]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [dbo].[Orders_History]))
GO
4. Note that until this point, we have not specifically defined any indexes on the memory optimized internal table. Let’s get the name of this internal table, to see which indexes are created by default.
SELECT SCHEMA_NAME ( T1.schema_id ) AS TemporalTableSchema
, T1.object_id AS TemporalTableObjectId
, OBJECT_NAME ( IT.parent_object_id ) AS ParentTemporalTableName
, IT.Name AS InternalHistoryStagingName
FROM sys.internal_tables IT
JOIN sys.tables T1 ON IT.parent_object_id = T1.object_id
WHERE T1.is_memory_optimized = 1 AND T1.temporal_type = 2

If we replace the Internal table name in the script below and look at its indexes, the results show that there is only one index created, with ValidTo and ValidFrom as first two columns. Currently there is no way to create any additional indexes on the internal memory optimized table when enabling system versioning. The single index has the following key columns: ValidTo,ValidFrom,{PKColumns},CHANGE_ID. CHANGE_ID is an additional column used to guarantee the uniqueness of rows in the internal history table.
sp_helpindex 'sys.memory_optimized_history_table_869578136'
GO

5. Why would we need any other indexes on the internal history table? Let’s say we have a rather large in-memory table as a current table. For every update or delete, a previous version of each affected row is added to the in-memory internal table. As mentioned earlier, this internal table is flushed to the disk based history table only when it consumes 8% of the size of the current table, or if flushed manually. As percentages go, 8% of a larger table, say a 20 million row table, is 1.6 million rows. As the current table grows, so does that internal table. There can be cases where the internal table is relatively large, before it is flushed. Given that it has only one index created with predefined key columns, if you are doing a point lookup on history table by anything other than the ValidTo column, this internal table would be scanned.
As a very simplistic example, I loaded 4.5 million rows into the Orders table, and then updated every 12th row (full definition of the InsertOrders_Native_Batch stored procedure is in the appendix).
EXEC [InsertOrders_Native_Batch] 4500000;
-- Effectively updating every 1/18th row (less than 8% of rows)
SET NOCOUNT ON
GO
UPDATE Orders SET DeliveryDate = getdate()+1
where OrderID % 18 = 0;
6. Let’s now look at a most simple form of a point lookup query on the history table. Queries on the history table will return results from all the data that exists in the on-disk history table as well as the memory optimized internal history table.
-- Though a query is on the history table, it also references in-memory internal table
SELECT * FROM [Orders_History] WHERE OrderID = 18

SQL Server Execution Times: CPU time = 578 ms, elapsed time = 837 ms.
Note that in the plan above, even though we only get one row from the memory-optimized internal table, we are still doing a full scan, because in the only index this table has, OrderID is not the leading column. The memory optimized internal table has 250,000 rows, none of which are flushed to the on-disk history table yet, since it is below the flush threshold as shown by the snapshot of memory consumption below.

The same is true if you do a query that uses any of the FOR SYSTEM_TIME constructs, and restrict it to a particular OrderID
SELECT * FROM Orders FORSYSTEM_TIME ALL
WHERE [OrderID] = 18;
Solution
Starting in SQL 2016 CU3 or SQL 2016 SP1, we have introduced the ability to add additional indexes on the in-memory internal tables, under trace flag 10316. No additional DDL syntax exists from a temporal perspective at this point of time. Additional details of this are in the KB 3198846
Using this trace flag, let’s create an index on OrderID on the internal table
DBCC TRACEON(10316)
GO
ALTER TABLE sys.memory_optimized_history_table_565577053
ADD Index IndOrderID(OrderId)
GO
DBCC TRACEOFF(10316)
Looking at the plan for the same query now, we see an index seek, given there is an index to satisfy the predicate. Execution times are substantially lower than in the prior case
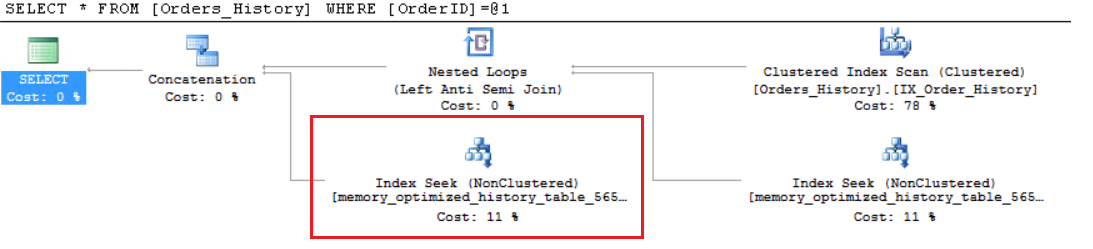
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 36 ms.
This not only allows us to be able to seek in this simplistic query case, but in more complex queries the downstream effects can result in significantly better plans and memory grants. This is another example of improvements being made based on actual customer workload feedback.
Appendix - TSQL Code:
CREATE DATABASE [TestTemporalDb1];
ALTER DATABASE [TestTemporalDb1] ADD FILEGROUP [IMOLTP] CONTAINS MEMORY_OPTIMIZED_DATA ;
ALTER DATABASE [TestTemporalDb1]
ADD FILE (name='TestTemporalDb1_Mod1', filename='H:\data\TestTemporalDb1_Mod1') TO FILEGROUP [IMOLTP];
USE [TestTemporalDb1]
GO
-- Create on In-memory table with a history table.
CREATE TABLE [dbo].[Orders](
[OrderId] [INT] Identity NOT NULL,
[StoreID] int NOT NULL,
[CustomerID] int NOT NULL,
[OrderDate] [datetime] NOT NULL,
[DeliveryDate] datetime NULL,
[Amount] float,
[Notes] [NVARCHAR] (max) NULL,
[ValidFrom] [datetime2](7) NOT NULL,
[ValidTo] [datetime2](7) NOT NULL,
CONSTRAINT [PK_OrderID] PRIMARY KEY NONCLUSTERED (OrderId)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
GO
ALTER TABLE Orders ADD INDEX IndOrders_StoreID(StoreID);
GO
-- Create the table on the partition scheme
CREATE TABLE [dbo].[Orders_History](
[OrderId] [INT] NOT NULL,
[StoreID] int NOT NULL,
[CustomerID] int NOT NULL,
[OrderDate] [datetime] NOT NULL,
[DeliveryDate] datetime NULL,
[Amount] float,
[Notes] [NVARCHAR] (max) NULL,
[ValidFrom] [datetime2](7) NOT NULL,
[ValidTo] [datetime2](7) NOT NULL,
)
GO
-- Create custom Indexing on the Temporal History table
CREATE CLUSTERED INDEX [IX_Order_History]
ON [dbo].[Orders_History] ( ValidTo, ValidFrom) WITH (DATA_COMPRESSION = PAGE);
-- Default Clustered index is on ValidFrom and ValidTo times
CREATE NONCLUSTERED INDEX [IX_OrderHistory_OrderId] ON [dbo].[Orders_History]
( [OrderId] ASC, ValidTo, ValidFrom) ;
GO
-- Make Temporal
ALTER TABLE [dbo].[Orders] ADD PERIOD FOR SYSTEM_TIME (ValidFrom,ValidTo);
ALTER TABLE [dbo].[Orders] ALTER COLUMN ValidTo ADD HIDDEN;
ALTER TABLE [dbo].[Orders] ALTER COLUMN ValidFrom ADD HIDDEN;
GO
-- Enable Temporal
ALTER TABLE [dbo].[Orders] SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = [dbo].[Orders_History]));
GO
-- Internal Tables and memory consumption of each?
WITH InMemoryTemporalTables
AS
(
SELECT SCHEMA_NAME ( T1.schema_id ) AS TemporalTableSchema
, T1.object_id AS TemporalTableObjectId
, IT.object_id AS InternalTableObjectId
, OBJECT_NAME ( IT.parent_object_id ) AS ParentTemporalTableName
, IT.Name AS InternalHistoryStagingName
FROM sys.internal_tables IT
JOIN sys.tables T1 ON IT.parent_object_id = T1.object_id
WHERE T1.is_memory_optimized = 1 AND T1.temporal_type = 2
)
, DetailedConsumption
AS
(
SELECT TemporalTableSchema
, T.ParentTemporalTableName
, T.InternalHistoryStagingName
, CASE
WHEN C.object_id = T.TemporalTableObjectId
THEN 'Temporal Table Consumption'
ELSE 'Internal Table Consumption'
END ConsumedBy
, C.*
FROM sys.dm_db_xtp_memory_consumers C
JOIN InMemoryTemporalTables T
ON C.object_id = T.TemporalTableObjectId OR C.object_id = T.InternalTableObjectId
)
--select * from DetailedConsumption
SELECT TemporalTableSchema,
ParentTemporalTableName, object_id, object_name(object_id) as MemoryUsedByTable
, sum ( allocated_bytes ) AS allocated_bytes
, sum ( used_bytes ) AS used_bytes
FROM DetailedConsumption
GROUP BY TemporalTableSchema, ParentTemporalTableName, InternalHistoryStagingName,object_id ;
-- Check indexes
-- Replace the internal table with the table name you get from the prior query
sp_helpindex 'Orders'
GO
sp_helpindex 'sys.memory_optimized_history_table_565577053'
GO
-- Insert some data?
CREATE PROCEDURE [dbo].[InsertOrders_Native_Batch]
@OrderNum INT=100
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = 'us_english')
DECLARE @counter AS INT = 1;
WHILE @counter <= @OrderNum
BEGIN
INSERT INTO dbo.Orders
VALUES (@counter % 8 , @counter %10000 , getdate(), NULL , rand() * 1000,
'Notes for a fake order temporal testing, will update these later' );
SET @counter = @counter + 1;
END
END;
GO
-- Insert some rows
EXEC [InsertOrders_Native_Batch] 500000
Go 9
-- Now update them.
-- Effectively updating every 1/18th row ( less than 10% of rows)
SET NOCOUNT ON
GO
UPDATE Orders SET DeliveryDate = getdate()+1
WHERE OrderID % 18 = 0
-- This also references In-memory temp table
select count(*) from [Orders_History]
-- Enable actual plan and also look at Statistics
set statistics time on
go
-- Though a query on the history table, it also references In-memory temp table
select * from [Orders_History] where OrderID = 18
--*******************************************************************************
-- You need SQL 2016 CU3 or SQL 2016 SP1 in order for the steps below to work
--**********************************************************************************
DBCC TRACEON(10316)
GO
ALTER TABLE sys.memory_optimized_history_table_565577053
ADD Index IndOrderID(OrderId)
GO
DBCC TRACEOFF(10316)
-- Now execute the same statement and you should see a seek
select * from [Orders_History] where OrderID = 18
-- Can we manually ensure that the in-memory history table is flushed?
exec sys.sp_xtp_flush_temporal_history 'dbo', 'Inventory'
Comments
- Anonymous
January 10, 2017
This a much needed improvement, but is not quite optimal for the following reasons: 1. requires a trace flag2. after database restart (db OFFLINE/ONLINE, FCI failover, etc.) , there is no automated mechanism to apply indexes to these hidden tables. Imagine having dozens of in-mem tables that are temporal, and having to figure out which indexes go on which internal tables.