DISTINCT x GROUP BY
1. Introdução
Em fórum de SQL Server no StackOverflow foi postada dúvida sobre a diferença entre DISTINCT e GROUP BY. O autor do tópico cita que “Ao meu entender Distinct retorna os valores diferentes, mas os valores agrupados (Group by) também ficam distintos (diferentes)”. E solicita respostas às seguintes questões:
- Qual a diferença entre ambas as declarações, além da sintaxe?
- Em relação ao desempenho, existem diferenças?
- Existe alguma possibilidade (exemplo na prática) em que o uso das duas declarações é necessária?
- Poderiam postar exemplos de uso ideal de cada uma das declarações?

2. O que consta na documentação?
2.1 DISTINCT
Na documentação da cláusula SELECT temos
SELECT [ ALL | DISTINCT ]
[ TOP ( expression ) [ PERCENT ] [ WITH TIES ] ]
<select_list>
ALL
Especifica que linhas duplicadas podem aparecer no conjunto de resultados. ALL é o padrão.
DISTINCT
Especifica que só linhas exclusivas podem aparecer no conjunto de resultados. Valores nulos são considerados iguais para os propósitos da palavra-chave DISTINCT.
O par de colchetes no trecho [ ALL | DISTINCT ] indica que os dois argumentos são opcionais e que, se informados, são mutuamente exclusivos; isto é, ou um ou outro. Como consta na documentação, o argumento ALL é o padrão. Ou seja, se nenhum dos argumentos constar do comando, assume-se a presença de ALL. A respeito do argumento DISTINCT, a documentação cita “linhas exclusivas”, o que deve-se entender por valores não repetidos.
A definição de <select_list> é extensa mas, para fins deste artigo, somente será considerada a presença de nomes de colunas:
SELECT coluna1, coluna2, ..., colunan
from tabela;
2.2 GROUP BY
Na documentação de GROUP BY temos
GROUP BY {
<column-expression>
| ROLLUP ( <group_by_expression> [ ,...n ] )
| CUBE ( <group_by_expression> [ ,...n ] )
| GROUPING SETS ( <grouping_set> [ ,...n ] )
| ()
} [ ,...n ]
Agrupa um conjunto de linhas selecionadas em um conjunto de linhas de resumo pelos valores de uma ou mais colunas ou expressões. Uma linha é retornada para cada grupo. As funções de agregação na lista de <seleção> da cláusula SELECT fornecem informações sobre cada grupo em vez de linhas individuais.
O objetivo dessa cláusula é agrupar linhas em que existam mesmos valores para as colunas definidas na cláusula, gerando subconjuntos. Para cada subconjunto podem então serem executadas funções de agregação nas demais colunas. Ao final, para cada subconjunto é retornada uma única linha, contendo as colunas de agrupamento e os resultados das funções de agregação.
Para a definição de <column_expression> iremos considerar somente nomes de colunas.
2.3 Funções de agregação
Na documentação de GROUP BY consta “funções de agregação”. Ao consultar a documentação a respeito de funções de agregação, temos
As funções de agregação executam um cálculo em um conjunto de valores e retornam um único valor. As funções de agregação normalmente são usadas com a cláusula GROUP BY da instrução SELECT.
Em um modelo simples, as funções de agregação que constem na cláusula SELECT são executadas para cada subconjunto gerado pela cláusula GROUP BY.
Como exemplos de função de agregação temos:
- Count: calcula a quantidade de elementos;
- Avg: calcula a média dos elementos;
- Sum: calcula o somatório dos elementos.
3. Demonstração de aplicação dos recursos
Para demonstrar a aplicação de DISTINCT e de GROUP BY, utilizaremos a seguinte tabela:
-- código #1
CREATE TABLE Vendas (
NomeVendedor varchar(30) not null,
ProdutoVendido varchar(50) not null,
QuantidadeVendida int not null,
ValorVenda money not null
);
que será carregada através do script
-- código #2
INSERT into Vendas values
('João', 'Macarrão', 18, 35.00),
('Maria', 'Beterraba', 3, 12.00),
('José', 'Cenoura', 5, 5.00),
('João', 'Molho de tomate', 1, 7.50),
('Antônio', 'Beterraba', 4, 16.00),
('João', 'Macarrão', 3, 4.20);
Supondo que o programador receba como incumbência gerar os seguintes relatórios:
- Quais são os vendedores?
- Quais produtos cada vendedor vendeu?
- Qual o total de vendas, em reais, de cada vendedor?
- Qual a quantidade de itens vendidos de cada produto, por vendedor?
- Quantos produtos diferentes foram vendidos por cada vendedor?
o tema será desenvolvido à medida que as solicitações acima são atendidas.
3.1 Quais são os vendedores?
Aparentemente uma requisição bem simples.
-- código #3
SELECT NomeVendedor
from Vendas;
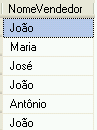
Entretanto, ao consultar o resultado o programador percebe que o nome João aparece 3 vezes. Como eliminar as repetições? É uma aplicação típica do uso de DISTINCT!
-- código #3a
SELECT distinct NomeVendedor
from Vendas;

Ao analisar os planos de execução dos códigos #3 e #3a, percebe-se a facilmente a diferença: a presença do operador lógico Distinct Sort no plano de execução relativo ao código #3a.

O operador lógico Distinct Sort ordena as linhas lidas na tabela Vendas, eliminando então as repetições.
3.2 Quais produtos cada vendedor vendeu?
Essa requisição envolve o uso de duas colunas: NomeVendedor e ProdutoVendido.
-- código #5
SELECT NomeVendedor, ProdutoVendido
from Vendas;
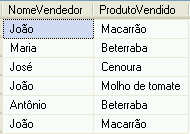
No resultado percebe-se que o par {João, Macarrão} aparece mais de uma vez. Eis outra aplicação típica do uso de DISTINCT, mas agora atuando sobre duas colunas.
-- código #5a
SELECT distinct NomeVendedor, ProdutoVendido
from Vendas;

Atenção que DISTINCT atua simultaneamente nas colunas NomeVendedor e ProdutoVendido. Isto é, ele considera as duas colunas como se fossem uma única, para eliminar as repetições.
Ao analisar os planos de execução dos códigos #5 e #5a, percebe-se a facilmente a diferença: a presença do operador lógico Distinct Sort no plano de execução relativo ao código #5a.

Como comentado no item 3.1, o operador lógico Distinct Sort ordena as linhas lidas na tabela Vendas, eliminando então as repetições.
3.3 Qual o total de vendas, em reais, de cada vendedor?
Para atender a esta solicitação será necessário somar o conteúdo da coluna ValorVenda para cada vendedor. Ou seja, será necessário primeiro separar as vendas por vendedor (gerando um subconjunto com as linhas de cada vendedor) e a seguir realizar a soma de cada subconjunto.
Eis uma aplicação típica da cláusula de agrupamento GROUP BY.
Para agrupar as linhas por vendedor utilizamos
GROUP BY NomeVendedor
E para somar as vendas, utilizamos a função de agregação SUM
Sum(ValorVenda)
Juntando isto, temos o seguinte código:
-- código #6
SELECT NomeVendedor, Sum(ValorVenda)
from Vendas
group by NomeVendedor;

Este é o primeiro código deste artigo com a cláusula GROUP BY. Ao analisar o plano de execução do código #6, percebe-se algo que não constava nos planos de execução anteriores, que é o operador Stream Aggregate.

Conforme documentação do operador Stream aggregate, “ele agrupa linhas através de uma ou mais colunas e em seguida calcula uma ou mais expressões de agregação retornadas pela consulta”.
O operador Stream Aggregate requer a entrada de dados ordenada pelas colunas dentro de seus grupos. Para garantir essa condição, o otimizador de consultas acrescenta antes o operador Sort, caso os dados ainda não estejam ordenados. Isto pode ser observado no plano de execução acima, pois a tabela Vendas é do tipo heap e sem qualquer índice. Ou seja, primeiro as linhas lidas na tabela Vendas são ordenadas pela coluna NomeVendedor, para somente após serem encaminhadas ao operador Stream Aggregate.
3.4 Quantos itens de cada produto foram vendidos, por vendedor?
Para atender a essa solicitação será necessário criar subconjuntos por vendedor e, dentro de cada um desses subconjuntos, criar subconjuntos por produto. Isto é possível pois a cláusula GROUP BY permite a definição de mais de uma coluna.
Para agrupar as linhas por vendedor utilizamos
GROUP BY NomeVendedor
e então, para agrupar cada produto dentro de cada subconjunto, acrescentamos a coluna que identifica o produto
GROUP BY NomeVendedor, ProdutoVendido
E para somar a quantidade de itens vendidos, utilizamos novamente a função de agregação SUM
Sum(QuantidadeVendida)
Juntando isto, temos o seguinte código:
-- código #7
SELECT NomeVendedor, ProdutoVendido, Sum(QuantidadeVendida)
from Vendas
group by NomeVendedor, ProdutoVendido;

Ao analisar o plano de execução do código #7, percebe-se novamente a presença do operador Stream Aggregate.

Ou seja, primeiro as linhas lidas na tabela Vendas são ordenadas pela coluna NomeVendedor, para somente após serem encaminhadas ao operador Stream Aggregate.
3.5 Quantos produtos diferentes foram vendidos por cada vendedor?
Para agrupar as linhas por vendedor utilizamos
GROUP BY NomeVendedor
e para contar quantos produtos diferentes foram vendidos por cada vendedor, a função de agregação COUNT é a opção natural, fazendo
Count(ProdutoVendido)
Juntando isto, temos o seguinte código:
-- código #8
SELECT NomeVendedor, Count(ProdutoVendido)
from Vendas
group by NomeVendedor;

Ao consultar o resultado, e comparar com o conteúdo da tabela de vendas, percebemos que para o vendedor João foram contabilizados 3 produtos quando ele somente vendeu dois tipos de produtos: “Macarrão” e “Molho de tomate”. Mas ele fez duas vendas de macarrão. Como fazer para que a função de agregação Count somente some uma vez cada produto? A resposta está no uso de DISTINCT, mas dentro do parâmetro da função, conforme
COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
-- código #8a
SELECT NomeVendedor, Count(distinct ProdutoVendido)
from Vendas
group by NomeVendedor;

Agora sim o resultado veio correto, com o vendedor João contabilizando 2 produtos diferentes.
E como ficaram os planos de execução dos códigos #8 e #8a?

Percebe-se em ambos a presença do operador Stream Aggregate, devido à cláusula GROUP BY. Com relação ao operador Sort, na primeira consulta é do tipo simples mas na na segunda consulta, referente ao código #8a, é do tipo Distinct Sort. Este operador foi incluído pelo processador de consultas para processar ordenar as linhas pla coluna NomeVendedor e ProdutoVendido, eliminando as repetições de ProdutoVendido.
4. GROUP BY no lugar de DISTINCT
Quando a cláusula GROUP BY é utilizada sem que exista função de agregação na cláusula SELECT, ela possui efeito semelhante a de DISTINCT.
Por exemplo, o código #3a pode ser reescrito, substituindo DISTINCT por GROUP BY:
|
|
O resultado das consultas é
código #3A |
código #9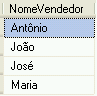 |
E os planos de execução gerados são
código #3A |
código #9 |
Ou seja, mesmo resultado e mesmo plano de execução foram gerados para as duas consultas.
5. Influência de índices
Até este ponto os testes foram realizados com tabela heap e sem qualquer índice nonclustered. Além disso, a tabela Vendas não está normalizada, de modo a simplificar o entendimento dos exemplos. O que ocorreria nos planos de execução gerados se a tabela Vendas possuísse índice pela coluna NomeVendedor? Óbvio que não pode ser índice unique, pois um mesmo vendedor pode ter várias vendas registradas na tabela.
Eis o código para criar o índice:
-- código #10
CREATE clustered INDEX ix1_Vendas on Vendas (NomeVendedor);
Após a criação do índice, a tarefa é reexecutar os códigos acima, analisando os novos planos de execução à procura de diferenças. Dois foram selecionados para constar deste artigo.
5.1 Código #3a
Na reexecução do código
-- código #3a
SELECT distinct NomeVendedor
from Vendas;
é gerado o novo plano de execução

Ao comparar com o plano de execução original (sem índice) abaixo

percebemos que o operador lógico Distinct Sort foi substituído pelo operador Stream Aggregate. Como através do índice ix1_Vendas é possível ler a tabela Vendas em ordem pela coluna NomeVendedor, não é necessário o operador Sort.
Curiosamente, enquanto que no item 4 vimos um GROUP BY ser transformado em DISTINCT, agora vemos o processo inverso: DISTINCT sendo transformado em GROUP BY.
5.2 Código #6
Na reexecução do código
-- código #6
SELECT NomeVendedor, Sum(ValorVenda)
from Vendas
group by NomeVendedor;
o novo plano de execução gerado é

Ao comparar com o plano de execução original (sem índice) abaixo

percebemos que o operador Sort é não mais é utilizado. Como através do índice ix1_Vendas é possível ler a tabela Vendas em ordem pela coluna NomeVendedor, não é necessário o operador Sort.
5.3 Demais códigos
E nos demais códigos, ocorrem diferenças nos planos de execução? Esta é uma atividade sugerida para que você a realize e avalie as diferenças.
6. Embarcando em canoa furada
Na web há vários tópicos de fóruns SQL bem como artigos sobre o tema GROUP BY x DISTINCT, sendo que alguns dos textos mais confundem do que esclarecem. Vários artigos informam ter realizado comparações entre as duas formas, mas não mencionam qual foi a metodologia utilizada para medir a performance nem exibem os planos de execução. Por exemplo, será que limparam o cache entre os testes?
No artigo “Performance Surprises and Assumptions : GROUP BY vs. DISTINCT”, em minha opinião o autor do artigo embarcou em uma canoa furada. Tanto que é alertado por Adam Machanic de que a comparação que ele realiza no artigo não está correta, pois “those queries are not really logically equivalent -- DISTINCT is on both columns, whereas your GROUP BY is only on one”. Quem se interessar em ler o artigo, o link está na parte final deste artigo, no item Referências.
A solução para o problema que o autor do artigo relata é bem simples. Ao procurar a causa das linhas repetidas, percebe-se que está no fato da tabela Sales.OrderLines possuir várias linhas com o mesmo valor de OrderID. Então, bastaria inicialmente eliminar essas repetições e somente após realizar a ação de concatenar várias linhas em uma única linha/coluna.
-- código #11
USE WideWorldImporters;
with uniqueOL as (
SELECT distinct OrderID
from Sales.OrderLines
)
SELECT O.OrderID,
STUFF((SELECT N'|' + Description
from Sales.OrderLines
where OrderID = O.OrderID
for XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'), 1, 1, N'')
from uniqueOL as O;
Temos então um código de mais fácil compreensão em relação ao que ele faz e que produz o mesmo plano de execução do código proposto pelo autor do artigo anteriormente mencionado.
7. Considerações finais
Neste artigo somente foram analisados os operadores presentes nos planos de execução, sem entrar nos detalhes de operador, pois para cada um há uma variedade de informações específicas. Não foi objetivo deste artigo analisar a performance das soluções.
As cláusulas DISTINCT e GROUP BY não fazem a mesma coisa, possuem objetivos diferentes e normalmente geram planos de execução diferentes.
Há exceções.
8. Referências
8.1 Documentação
- Cláusula SELECT
- Eliminando duplicatas com DISTINCT
- GROUP BY
- Funções de agregação
- Sum()
- Count()
- operador Stream Aggregate
- operador Sort