Personalização de modelo (pré-visualização da versão 4.0)
Importante
Esse recurso agora foi preterido. Em 10 de janeiro de 2025, os recursos de Reconhecimento de Produtos e Personalização de Modelos da Visão de IA do Azure serão desativados: após essa data, chamadas de API para esses serviços falharão.
Para manter uma operação suave dos seus modelos, faça a transição para a Visão Personalizada de IA do Azure, que agora está em disponibilidade geral. A Visão Personalizada oferece funcionalidades semelhantes às dessas características que estão sendo desativadas.
A personalização de modelo permite treinar um modelo especializado de Análise de Imagem para seu próprio caso de uso. Modelos personalizados podem fazer classificação de imagem (as marcas se aplicam a toda a imagem) ou detecção de objeto (as marcas se aplicam a áreas específicas da imagem). Depois que seu modelo personalizado for criado e treinado, ele pertencerá ao seu recurso da Visão e você poderá chamá-lo usando a API de análise de imagem.
Implemente a personalização do modelo de forma rápida e fácil seguindo um início rápido:
Importante
Você pode treinar um modelo personalizado usando o serviço de Visão Personalizada ou o serviço de Análise de Imagem 4.0 com personalização de modelo. A tabela a seguir compara os dois serviços.
| Áreas | Serviço de Visão Personalizada | Serviço de Análise de Imagem 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Tarefas | Classificação de imagem Detecção de objetos |
Classificação de imagem Detecção de objetos |
||||||||||||||||||||||||||||||||||||
| Modelos de base | CNN | Modelo de transformador | ||||||||||||||||||||||||||||||||||||
| Rotulagem | Customvision.ai | Estúdio AML | ||||||||||||||||||||||||||||||||||||
| Portal da Web | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Bibliotecas | REST, SDK | REST, Exemplo de Python | ||||||||||||||||||||||||||||||||||||
| Dados mínimos de treinamento necessários | 15 imagens por categoria | 2 a 5 imagens por categoria | ||||||||||||||||||||||||||||||||||||
| Armazenamento de dados de treinamento | Carregado para o serviço | Conta de armazenamento de blobs do cliente | ||||||||||||||||||||||||||||||||||||
| Hospedagem de modelo | Nuvem e borda | Somente hospedagem na nuvem, a hospedagem de contêiner de borda está por vir | ||||||||||||||||||||||||||||||||||||
| Qualidade da IA |
|
|
||||||||||||||||||||||||||||||||||||
| Preços | Preços de Visão Personalizada | Preços da Análise de Imagem |
Componentes do cenário
Os principais componentes de um sistema de personalização de modelo são as imagens de treinamento, o arquivo COCO, o objeto de conjunto de dados e o objeto de modelo.
Imagens de treinamento
Seu conjunto de imagens de treinamento deve incluir vários exemplos de cada um dos rótulos que você deseja detectar. Também é conveniente coletar algumas imagens adicionais para testar o seu modelo após o treinamento. As imagens precisam ser armazenadas em um contêiner de Armazenamento do Azure para serem acessíveis ao modelo.
Para treinar o seu modelo com eficiência, use imagens com variedade de visual. Selecione imagens com variação em:
- ângulo da câmera
- iluminação
- background
- estilo do visual
- assuntos individuais/agrupados
- tamanho
- type
Além disso, certifique-se de que todas as suas imagens de treinamento atendam aos seguintes critérios:
- A imagem deve ser apresentada nos formatos JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF ou MPO.
- O tamanho do arquivo da imagem deve ser inferior a 20 megabytes (MB).
- As dimensões da imagem devem ser maiores que 50 x 50 pixels e menores que 16.000 x 16.000 pixels.
Arquivo COCO
O arquivo COCO faz referência a todas as imagens de treinamento e as associa às informações de rotulagem. No caso da detecção de objeto, ele especificou as coordenadas da caixa delimitadora de cada marca em cada imagem. Esse arquivo deve estar no formato COCO, que é um tipo específico de arquivo JSON. O arquivo COCO deve ser armazenado no mesmo contêiner do Armazenamento do Azure que as imagens de treinamento.
Dica
Sobre arquivos COCO
Os arquivos COCO são arquivos JSON com campos necessários específicos: "images", "annotations" e "categories". Um exemplo de COCO se parecerá ao seguinte:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Referência de campo de arquivo COCO
Se você estiver gerando seu próprio arquivo COCO do zero, verifique se todos os campos necessários estão preenchidos com os detalhes corretos. As tabelas a seguir descrevem cada campo em um arquivo COCO:
"imagens"
| Chave | Type | Descrição | Necessário? |
|---|---|---|---|
id |
inteiro | ID de imagem exclusiva, começando em 1 | Sim |
width |
inteiro | Largura da imagem em pixels | Sim |
height |
inteiro | Altura da imagem em pixels | Sim |
file_name |
string | Um nome exclusivo para a imagem | Sim |
absolute_url ou coco_url |
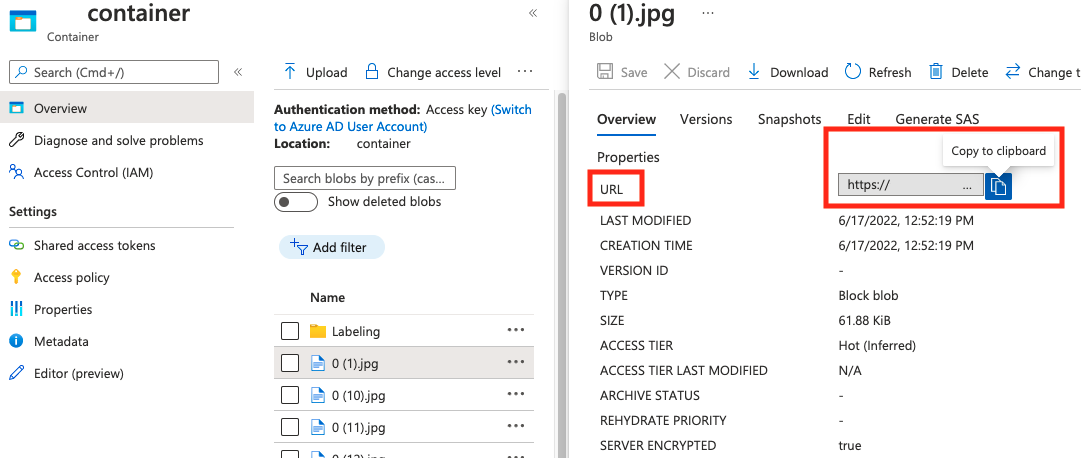
string | Caminho da imagem como um URI absoluto para um blob em um contêiner de blob. O recurso Visão deve ter permissão para ler os arquivos de anotação e todos os arquivos de imagem referenciados. | Sim |
O valor de absolute_url pode ser encontrado nas propriedades do contêiner de blob:
"anotações"
| Chave | Type | Descrição | Necessário? |
|---|---|---|---|
id |
inteiro | ID da anotação | Sim |
category_id |
inteiro | ID da categoria definida na seção categories |
Sim |
image_id |
inteiro | ID da imagem | Sim |
area |
inteiro | Valor de "Largura" x "Altura" (terceiro e quarto valores de bbox) |
No |
bbox |
list[float] | Coordenadas relativas da caixa delimitadora (0 a 1), na ordem de "Esquerda", "Superior", "Largura", "Altura" | Sim |
"categorias"
| Chave | Type | Descrição | Necessário? |
|---|---|---|---|
id |
inteiro | ID exclusiva para cada categoria (classe de rótulo). Eles devem estar presentes na seção annotations. |
Sim |
name |
string | Nome da categoria (classe de rótulo) | Yes |
Verificação do arquivo COCO
Você pode usar nosso código de exemplo do Python para verificar o formato de um arquivo COCO.
Objeto do conjunto de dados
O objeto Dataset é uma estrutura de dados armazenada pelo serviço de Análise de Imagem que faz referência ao arquivo de associação. Você precisa criar um objeto Conjunto de dados antes de criar e treinar um modelo.
Objeto de modelo
O objeto Model é uma estrutura de dados armazenada pelo serviço de Análise de Imagem que representa um modelo personalizado. Ele deve ser associado a um conjunto de dados para fazer o treinamento inicial. Depois de treinado, você pode consultar seu modelo inserindo seu nome no parâmetro de consulta model-name da chamada à API Analisar Imagem.
Limites de cota
A tabela a seguir descreve os limites na escala de seus projetos de modelo personalizado.
| Categoria | Classificador de imagem genérica | Detector de objetos genérico |
|---|---|---|
| Número máximo de horas de treinamento | 288 (12 dias) | 288 (12 dias) |
| Número máximo de imagens de treinamento | 1\.000.000 | 200.000 |
| Número máximo de imagens de avaliação | 100.000 | 100.000 |
| Número mínimo de imagens de treinamento por categoria | 2 | 2 |
| Número máximo de marcas por imagem | 1 | N/D |
| Número máximo de regiões por imagem | N/D | 1.000 |
| Número máximo de categorias | 2\.500 | 1,000 |
| Número mínimo de categorias | 2 | 1 |
| Tamanho máximo da imagem (Treinamento) | 20 MB | 20 MB |
| Tamanho máximo da imagem (Previsão) | Sincronização: 6 MB, Lote: 20 MB | Sincronização: 6 MB, Lote: 20 MB |
| Largura/altura máxima da imagem (Treinamento) | 10.240 | 10.240 |
| Largura/altura mínima da imagem (Previsão) | 50 | 50 |
| Regiões disponíveis | Oeste dos EUA 2, Leste dos EUA, Oeste da Europa | Oeste dos EUA 2, Leste dos EUA, Oeste da Europa |
| Tipos de imagem aceitos | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Perguntas frequentes
Por que minha importação de arquivo COCO está falhando ao importar do armazenamento de blobs?
Atualmente, a Microsoft está resolvendo um problema que faz com que a importação de arquivos COCO falhe com grandes conjuntos de dados quando iniciada no Vision Studio. Para treinar usando um conjunto de dados grande, é recomendável usar a API REST.
Por que o treinamento leva mais/menos tempo do que o meu orçamento especificado?
O orçamento de treinamento especificado é o tempo de computação calibrado, não a hora do relógio de parede. Veja alguns motivos comuns para a diferença a seguir:
Orçamento maior que o especificado:
- A Análise de Imagem tem um tráfego de alto treinamento e os recursos de GPU podem ser escassos. Seu trabalho pode aguardar na fila ou ser colocado em espera durante o treinamento.
- O processo de treinamento de back-end teve falhas inesperadas, o que resultou na repetição da lógica. As execuções com falha não consomem seu orçamento, mas isso pode levar a um tempo de treinamento mais longo em geral.
- Seus dados são armazenados em uma região diferente do seu recurso Visão, o que levará a um tempo de transmissão de dados mais longo.
Orçamento menor que o especificado: Os fatores a seguir aceleram o treinamento ao custo de usar mais orçamento em determinado tempo total.
- A Análise de Imagem às vezes treina com várias GPUs dependendo dos dados.
- Às vezes, a Análise de Imagem treina várias avaliações de exploração em várias GPUs ao mesmo tempo.
- Às vezes, a Análise de Imagem usa SKUs de GPU premier (mais rápidas) para treinar.
Por que meu treinamento falha e o que devo fazer?
Veja a seguir alguns motivos comuns para a falha no treinamento:
diverged: O treinamento não pode aprender coisas significativas com seus dados. As causas comuns são:- Os dados não são suficientes: fornecer mais dados deve ajudar.
- Os dados são de baixa qualidade: verifique se suas imagens são de baixa resolução ou possuem proporções extremas ou se as anotações estão erradas.
notEnoughBudget: Seu orçamento especificado não é suficiente para o tamanho do conjunto de dados e do tipo de modelo que você está treinando. Especifique um orçamento maior.datasetCorrupt: Geralmente isso significa que suas imagens fornecidas não estão acessíveis ou que o arquivo de anotação está no formato errado.datasetNotFound: o conjunto de dados não pode ser encontradounknown: pode ser um problema de back-end. Entre em contato com o suporte para investigação.
Quais métricas são usadas para avaliar os modelos?
As seguintes métricas são usadas:
- Classificação de imagem: Precisão média, Precisão Top 1, Precisão Top 5
- Detecção de objeto: Precisão média @ 30, precisão média @ 50, precisão média @ 75
Por que o registro do meu conjunto de dados falha?
As respostas à API devem ser informativas o suficiente. Eles são:
DatasetAlreadyExists: Existe um conjunto de dados com o mesmo nomeDatasetInvalidAnnotationUri: "Um URI inválido foi fornecido entre os URIs de anotação no momento do registro do conjunto de dados.
Quantas imagens são necessárias para uma qualidade de modelo razoável/boa/melhor?
Embora os modelos do Florence tenham grande capacidade de poucas capturas (obtendo um ótimo desempenho de modelo sob disponibilidade limitada de dados), em geral, mais dados tornam seu modelo treinado melhor e mais robusto. Alguns cenários exigem poucos dados (como classificar uma maçã contra uma banana), mas outros exigem mais (como detectar 200 tipos de insetos em uma floresta tropical). Isso dificulta a realização de uma única recomendação.
Se o orçamento de rotulagem de dados for restrito, nosso fluxo de trabalho recomendado será repetir as seguintes etapas:
Colete
Nimagens por classe, em queNimagens são fáceis de coletar (por exemplo,N=3)Treine um modelo e teste-o em seu conjunto de avaliação.
Se o desempenho do modelo for:
- Bom o suficiente (o desempenho é melhor do que sua expectativa ou desempenho próximo ao experimento anterior com menos dados coletados): pare aqui e use esse modelo.
- Ruim (o desempenho ainda está abaixo da sua expectativa ou melhor do que o experimento anterior com menos dados coletados em uma margem razoável):
- Colete mais imagens para cada classe, um número fácil de coletar, e volte para a Etapa 2.
- Se você notar que o desempenho não está melhorando mais após algumas iterações, pode ser porque:
- esse problema não está bem definido ou é muito difícil. Entre em contato conosco para análise caso a caso.
- os dados de treinamento podem ser de baixa qualidade: verifique se há anotações erradas ou imagens de resolução muito baixa.
Quanto orçamento de treinamento devo especificar?
Você deve especificar o limite superior de orçamento que está disposto a consumir. A Análise de Imagem usa um sistema AutoML em seu back-end para experimentar diferentes modelos e receitas de treinamento para encontrar o melhor modelo para seu caso de uso. Quanto mais orçamento for dado, maior será a chance de encontrar um modelo melhor.
O sistema AutoML também será interrompido automaticamente se concluir que não há necessidade de tentar mais, mesmo que ainda haja orçamento restante. Portanto, ele nem sempre esgota o orçamento especificado. Você tem a garantia de não ser cobrado sobre seu orçamento especificado.
Posso controlar os hiperparâmetros ou usar meus próprios modelos no treinamento?
Não, o serviço de personalização do modelo de Análise de Imagem usa um sistema de treinamento AutoML de baixo código que manipula a pesquisa de hiper-parâmetros e a seleção de modelo base no back-end.
Posso exportar meu modelo após o treinamento?
A API de previsão só tem suporte por meio do serviço de nuvem.
Por que a avaliação falha no meu modelo de detecção de objetos?
Aqui estão os possíveis motivos:
internalServerError: Ocorreu um erro desconhecido. Tente novamente mais tarde.modelNotFound: o modelo especificado não foi encontrado.datasetNotFound: o conjunto de dados especificado não foi encontrado.datasetAnnotationsInvalid: ocorreu um erro ao tentar baixar ou analisar as anotações de área real associadas ao conjunto de dados de teste.datasetEmpty: o conjunto de dados de teste não continha nenhuma anotação de "área real".
Qual é a latência esperada para previsões com modelos personalizados?
Não recomendamos que você use modelos personalizados para ambientes comercialmente críticos devido a uma possível alta latência. Quando os clientes treinam modelos personalizados no Vision Studio, esses modelos personalizados pertencem a o recurso Visão de IA do Azure no qual eles foram treinados, e o cliente pode fazer chamadas para esses modelos usando a API Análise de Imagem. Quando eles fazem essas chamadas, o modelo personalizado é carregado na memória e a infraestrutura de previsão é inicializada. Enquanto isso acontece, os clientes podem ter latência maior do que a esperada para receber resultados de previsão.
Segurança e privacidade de dados
Assim como ocorre com todos os serviços de IA do Azure, os desenvolvedores que usam a personalização de modelo de Análise de Imagem devem estar cientes das políticas da Microsoft em relação aos dados do cliente. Consulte a página de serviços de IA do Azure na Central de Confiabilidade da Microsoft para saber mais.