Como aprimorar o modelo de Visão Personalizada
Neste guia, você aprenderá como aprimorar a qualidade do seu modelo de Visão Personalizada. A qualidade do classificador ou do detector de objetos depende da quantidade, qualidade e variedade dos dados rotulados que você fornece e de qual é o balanceamento do conjunto de dados geral. Um bom modelo tem um conjunto de dados de treinamento balanceado que é representativo do que será enviado a ele. O processo de criação desse modelo é iterativo; é comum realizar algumas etapas de treinamento para alcançar os resultados esperados.
Veja abaixo um padrão geral para ajudá-lo a treinar um modelo mais preciso:
- Treinamento de primeira rodada
- Adicionar mais imagens e balancear dados; treinar novamente
- Adicionar imagens com variação de tela de fundo, iluminação, tamanho do objeto, ângulo da câmera e estilo; treinar novamente
- Usar novas imagens para testar a previsão
- Modificar os dados de treinamento existente de acordo com os resultados da previsão
Evitar o sobreajuste
Às vezes, um modelo aprenderá fazer previsões com base nas características arbitrárias que suas imagens têm em comum. Por exemplo, se você estiver criando um classificador para maçãs em comparação com frutas cítricas e tiver usado imagens de maçãs em mãos e de frutas cítricas em pratos brancos, o classificador poderá dar uma importância indevida a mãos em comparação com pratos, em vez de maçãs em comparação com cítricos.
Para corrigir esse problema, forneça imagens com diferentes ângulos, telas de fundo, tamanho de objeto, grupos e outras variações. As seções a seguir ampliam esses conceitos.
Quantidade de dados
O número de imagens de treinamento é o fator mais importante para o conjunto de dados. Recomendamos usar pelo menos 50 imagens por rótulo como um ponto de partida. Com menos imagens, há maior risco de sobreajuste e, enquanto os números de desempenho possam sugerir boa qualidade, seu modelo pode apresentar dificuldades com os dados do mundo real.
Balanceamento de dados
Também é importante considerar as quantidades relativas dos dados de treinamento. Por exemplo, usar 500 imagens para um rótulo e 50 imagens para outro cria um conjunto de dados de treinamento em desequilíbrio. Isso fará o modelo ser mais preciso na previsão de um rótulo do que o outro. É provável que você veja melhores resultados se mantiver uma proporção de pelo menos 1: 2 entre o rótulo com o menor número de imagens e o rótulo com o maior número de imagens. Por exemplo, se o rótulo com maior número de imagens tiver 500 imagens, o rótulo com o mínimo de imagens deverá ter pelo menos 250 imagens para treinamento.
Variedade de dados
Use imagens representativas do que será enviado ao classificador durante o uso normal. Caso contrário, seu modelo poderá aprender a fazer previsões com base nas características arbitrárias que suas imagens têm em comum. Por exemplo, se você estiver criando um classificador para maçãs em comparação com frutas cítricas e tiver usado imagens de maçãs em mãos e de frutas cítricas em pratos brancos, o classificador poderá dar uma importância indevida a mãos em comparação com pratos, em vez de maçãs em comparação com cítricos.

Para corrigir esse problema, inclua uma variedade de imagens para garantir que seu modelo possa generalizar bem. Abaixo, estão algumas maneiras de tornar o treinamento mais diversificado:
Tela de fundo: forneça imagens do seu objeto na frente de diferentes telas de fundo. Fotos em contextos naturais são melhores que fotos na frente de telas de fundo neutras, pois fornecem mais informações ao classificador.

Iluminação: forneça imagens com iluminação variada (ou seja, tiradas com flash, alta exposição e assim por diante), principalmente se as imagens usadas para previsão tiverem uma iluminação diferente. Também é útil usar imagens com saturação, matiz e brilho variados.

Tamanho do objeto: forneça imagens nas quais os objetos variam em tamanho e número (por exemplo, uma foto de muitas bananas e um close-up de uma banana). O dimensionamento diferente ajuda o classificador a generalizar melhor.

Ângulo da câmera: forneça imagens tiradas com diferentes ângulos de câmera. Ou, se todas as fotos precisarem ser tiradas com câmeras fixas (como câmeras de vigilância), não se esqueça de atribuir um rótulo diferente a cada objeto de ocorrência regular para evitar o sobreajuste – interpretando objetos não relacionados (como postes de luz) como o recurso principal.

Estilo: forneça imagens de estilos diferentes da mesma classe (por exemplo, variedades diferentes da mesma fruta). No entanto, se você tem objetos de estilos drasticamente diferentes (como Mickey Mouse em comparação com um rato da vida real), recomendamos rotulá-los como classes separadas para representar melhor seus diferentes recursos.

Imagens negativas (somente classificadores)
Se você estiver usando um classificador de imagens, talvez seja necessário adicionar amostras negativas para ajudar a tornar seu classificador mais preciso. Amostras negativas são imagens que não correspondem a nenhuma das outras marcas. Quando você carregar essas imagens, aplique o rótulo especial Negativo a elas.
Os detectores de objetos lidam com amostras negativas automaticamente, pois qualquer área de imagem fora das caixas delimitadoras desenhadas é considerada negativa.
Observação
O serviço de Visão Personalizada dá suporte a alguns tratamentos de imagem negativo automática. Por exemplo, se você está compilando um classificador de uva em comparação com banana e envia uma imagem de um sapato para previsão, o classificador deve classificar essa imagem em cerca de 0 % tanto para uva como para banana.
Por outro lado, nos casos em que as imagens negativas são apenas uma variação das imagens utilizadas no treinamento, é provável que o modelo classifique as imagens negativas como uma classe rotulada devido às grandes semelhanças. Por exemplo, se você tiver um classificador de laranja em comparação com toranja, e envia em uma imagem de clementina, o classificador poderá classificar a clementina como laranja porque a clementina possui muitas características semelhantes às das laranjas. Se as imagens negativas forem dessa natureza, recomendamos criar uma ou mais marcas adicionais (como Outro) e rotular as imagens negativas com essa marca durante o treinamento para permitir que o modelo diferencie melhor essas classes.
Oclusão e truncamento (somente detectores de objetos)
Se você quiser que o detector de objetos detecte objetos truncados (os objetos são parcialmente recortados da imagem) ou objetos ocluídos (os objetos são parcialmente bloqueados por outros objetos na imagem), precisará incluir imagens de treinamento que abrangem esses casos.
Observação
O problema de objetos sendo obstruídos por outros objetos não deve ser confundido com o Limite de Sobreposição, um parâmetro para o desempenho do modelo de classificação. O controle deslizante Limite de Sobreposição no site da Visão Personalizada lida com o quanto uma caixa delimitada prevista deve se sobrepor à caixa delimitadora verdadeira a ser considerada correta.
Usar imagens de previsão para obter treinamento adicional
Quando você usa ou testa o modelo enviando imagens para o ponto de extremidade de previsão, o Serviço de Visão Personalizada armazena essas imagens. É possível usá-las para melhorar o modelo.
Para ver imagens enviadas ao modelo, abra a página da Web da Visão Personalizada, acesse o projeto e selecione a guia Previsões. A exibição padrão mostra imagens da iteração atual. É possível usar o menu suspenso Iteração para exibir imagens enviadas durante iterações anteriores.
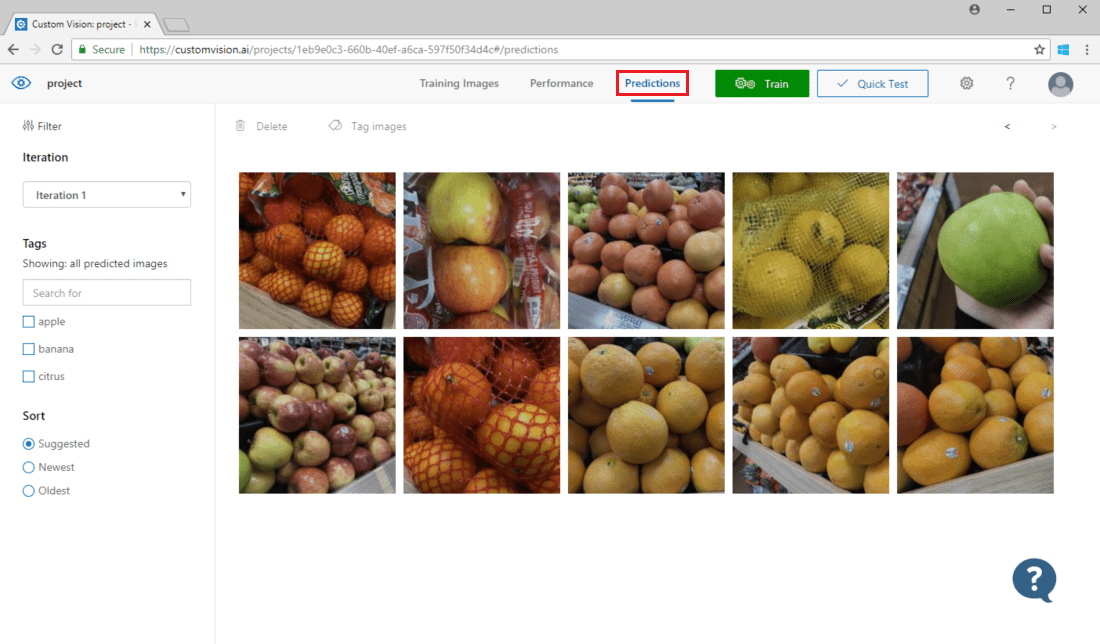
Passe o mouse sobre uma imagem para ver as marcas que foram previstas pelo modelo. As imagens são classificadas para que aquelas que puderem trazer o maior número de aprimoramentos ao modelo sejam listadas primeiro. Para usar um método de classificação diferente, crie uma seleção na seção Classificar.
Para adicionar uma imagem aos dados de treinamento existentes, selecione a imagem, defina as tags corretas e selecione Salvar e fechar. A imagem será removida de Previsões e adicionada ao conjunto de imagens de treinamento. Você pode exibi-la selecionando a guia Imagens de Treinamento.
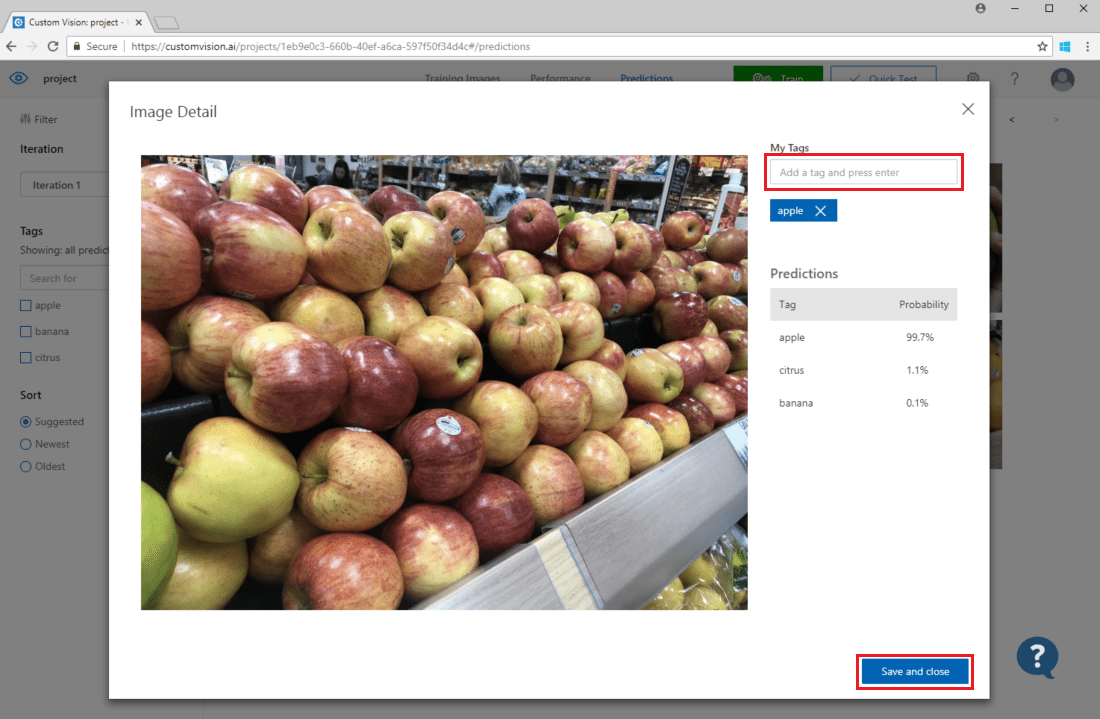
Em seguida, use o botão Treinar para treinar novamente o modelo.
Inspecionar visualmente previsões
Para inspecionar as previsões de imagem, vá até a guia Imagens de Treinamento, selecione a iteração de treinamento anterior no menu suspenso Iteração e marque uma ou mais marcas na seção Marcas. Agora a exibição deve exibir uma caixa vermelha ao redor de cada uma das imanes para as quais o modelo não conseguiu prever corretamente a tag específica.
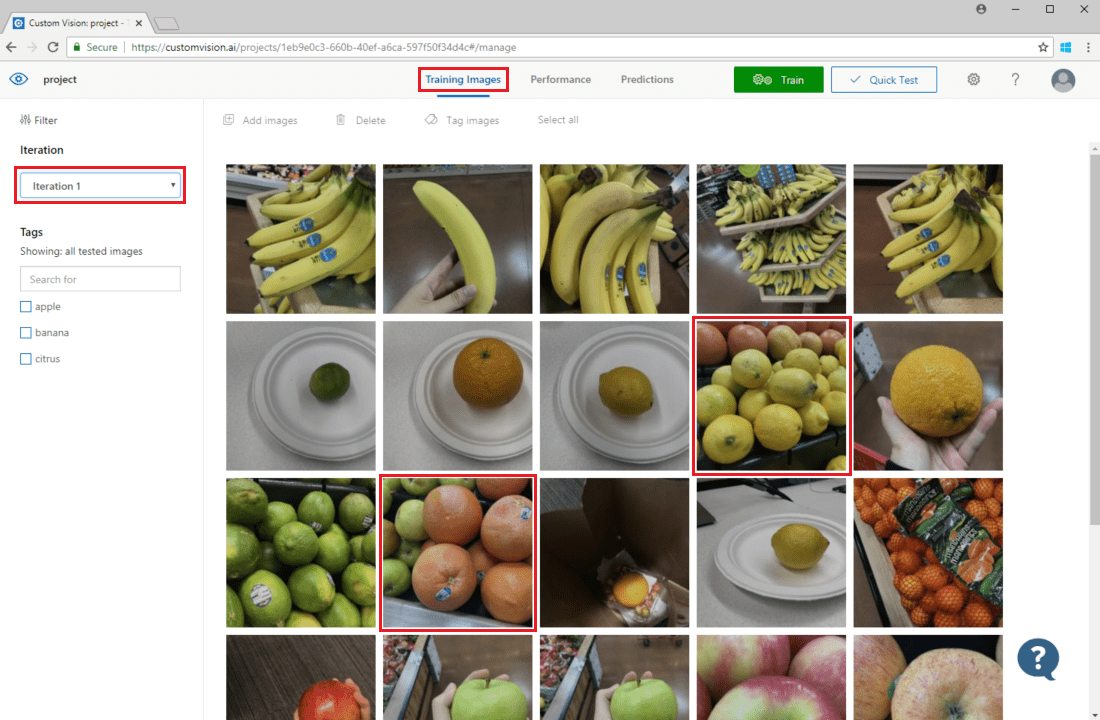
Às vezes, uma inspeção visual pode identificar padrões que você pode corrigir adicionando mais dados de treinamento ou modificando os existentes. Por exemplo, um classificador para maçãs em comparação com limões pode rotular incorretamente todas as maçãs verdes como limões. É possível corrigir esse problema adicionando e fornecendo dados de treinamento que contêm imagens marcadas de maçãs verdes.
Próximas etapas
Neste guia, você aprendeu várias técnicas para tornar seu modelo de classificação de imagem personalizada mais preciso. Em seguida, aprenda a testar imagens programaticamente enviando-as à API de Previsão.