Interpretar e melhorar a precisão do modelo e as pontuações de confiança da análise
Uma pontuação de confiança indica a probabilidade, medindo o grau de certeza estatística de que o resultado extraído é detectado corretamente. A precisão estimada é calculada com a execução de algumas combinações diferentes dos dados de treinamento para prever os valores rotulados. Neste artigo, aprenda a interpretar as pontuações de precisão e de confiança e as melhores práticas para o uso dessas pontuações a fim de melhorar a precisão e os resultados de confiança.
Pontuações de Confiança
Observação
- A confiança no nível de campo está recebendo atualização para levar em conta a pontuação de confiança do Word começando com a versão da API 07-07-07-2024-31 nos modelos personalizados.
- As pontuações de confiança para tabelas, linhas de tabela e células de tabela estão disponíveis a partir da versão da API 2024-07-31-preview nos modelos personalizados.
Os resultados da análise do Document Intelligence retornam uma confiança estimada para palavras previstas, pares chave-valor, marcas de seleção, regiões e assinaturas. Atualmente, nem todos os campos de documento retornam uma pontuação de confiança.
A confiança indica uma probabilidade estimada entre 0 e 1 de que a previsão esteja correta. Por exemplo, um valor de confiança de 0,95 (95%) indica que a previsão provavelmente está correta 19 de 20 vezes. Para cenários em que a precisão é crítica, a confiança pode ser usada para determinar se a previsão deve ser aceita automaticamente ou sinalizada para revisão humana.
Estúdio de Informação de Documentos
Modelo predefinido de fatura analisada
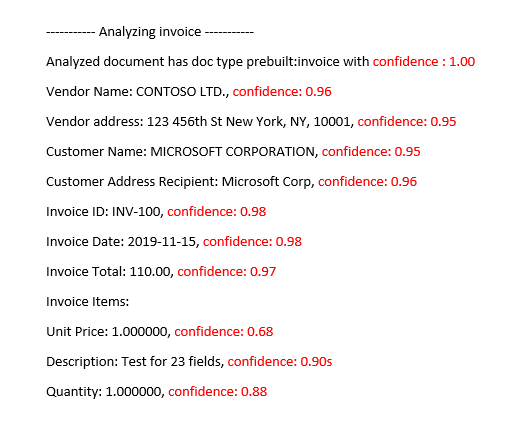
Melhorar as pontuações de confiança
Após uma operação de análise, examine a saída JSON. Examine os valores de confidence para cada resultado de chave-valor no nó pageResults. Você também deve examinar a pontuação de confiança no nó readResults, que corresponde à operação de leitura de texto. A confiança dos resultados de leitura não afeta a confiança dos resultados de extração de chave-valor, portanto, você deve verificar ambos. Veja algumas dicas:
Se a pontuação de confiança do objeto
readResultsfor baixa, melhore a qualidade dos documentos de entrada.Se a pontuação de confiança do objeto
pageResultsfor baixa, verifique se os documentos que você está analisando são do mesmo tipo.Considere a incorporação de análise humana em seus fluxos de trabalho.
Use formulários que tenham valores diferentes em cada campo.
Para modelos personalizados, use um conjunto maior de documentos de treinamento. Um conjunto de treinamento maior ensina seu modelo a reconhecer campos com maior precisão.
Pontuações de precisão para modelos personalizados
Observação
- Os Modelos neurais e generativos personalizados não fornecem pontuações de precisão durante o treinamento.
A saída de uma operação de modelo personalizado build (v3.0 e em diante) ou train (v2.1) inclui a pontuação de precisão estimada. Essa Pontuação representa a capacidade do modelo de prever com precisão o valor rotulado em um documento visualmente semelhante. A precisão é medida dentro de um intervalo de valores percentuais de 0% (baixa) a 100% (alta). É melhor ter como objetivo uma pontuação de 80% ou mais. Para casos mais confidenciais, como registros financeiros ou médicos, é recomendável uma pontuação próxima de 100%. Você também pode adicionar um estágio de revisão humana para validar fluxos de trabalho de automação mais críticos.
Estúdio de Informação de Documentos
Modelo personalizado treinado (fatura)
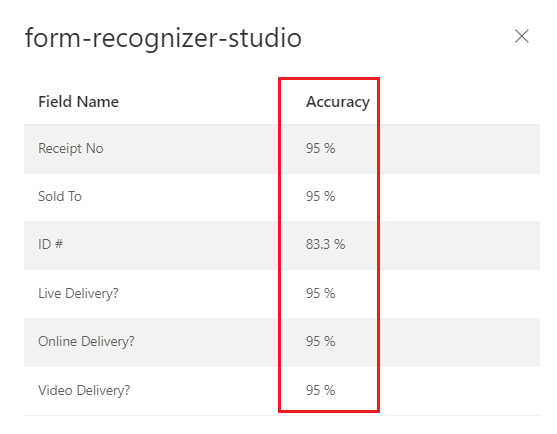
Interpretar as pontuações de precisão e confiança para modelos personalizados
Os modelos personalizados geram uma pontuação de precisão estimada quando treinados. Os documentos analisados com um modelo personalizado produzem uma pontuação de confiança para campos extraídos. Ao interpretar a pontuação de confiança de um modelo personalizado, você deve considerar todas as pontuações de confiança retornadas do modelo. Vamos começar com uma lista de todas as pontuações de confiança.
- Pontuação de confiança do tipo de documento: a confiança do tipo de documento é um indicador de que o documento analisado é semelhante aos documentos no conjunto de dados de treinamento. Uma confiança do tipo de documento baixa é um indicativo de variações estruturais ou de modelo no documento analisado. Para melhorar a confiança do tipo de documento, rotule um documento com essa variação específica e adicione-o ao conjunto de dados de treinamento. Após ter sido retreinado, o modelo deverá estar mais bem equipado para lidar com essa classe de variações.
- Confiança em nível de campo: cada campo rotulado extraído tem uma pontuação de confiança associada. Essa pontuação reflete a confiança do modelo na posição do valor extraído. Ao avaliar as pontuações de confiança, você também deve examinar a confiança de extração subjacente para gerar uma confiança abrangente para o resultado extraído. Avalie os resultados do
OCRpara extração de texto ou marcas de seleção, dependendo do tipo de campo, para gerar uma pontuação de confiança composta para o campo. - Pontuação de confiança do Word Cada palavra extraída no documento tem uma pontuação de confiança associada. A pontuação representa a confiança da transcrição. A matriz de páginas contém uma matriz de palavras e cada palavra tem um intervalo e uma pontuação de confiança associados. Os intervalos dos valores extraídos do campo personalizado correspondem aos intervalos das palavras extraídas.
- Pontuação de confiança da marca de seleção: a matriz de páginas também contém uma matriz de marcas de seleção. Cada marca de seleção tem uma pontuação de confiança que representa a confiança da marca de seleção e da detecção do estado da seleção. Quando um campo rotulado tem uma marca de seleção, a seleção de campo personalizada combinada à confiança da marca de seleção constitui uma representação precisa da precisão da confiança de modo geral.
A tabela a seguir demonstra como interpretar a precisão e as pontuações de confiança para medir o desempenho do modelo personalizado.
| Precisão | Confiança | Result |
|---|---|---|
| Alto | Alto | • O modelo tem um bom desempenho com as chaves rotuladas e formatos de documentos. • Você tem um conjunto de dados de treinamento equilibrado. |
| Alto | Baixo | • O documento analisado parece diferente do conjunto de dados de treinamento. • O modelo se beneficiaria da reciclagem com pelo menos mais cinco documentos etiquetados. • Esses resultados também podem indicar uma variação de formato entre o conjunto de dados de treinamento e o documento analisado. Considere adicionar um novo modelo. |
| Baixo | Alta | • Esse resultado é muito improvável. • Para pontuações de baixa precisão, adicione mais dados rotulados ou divida documentos visualmente distintos em vários modelos. |
| Baixo | Baixo | • Adicione mais dados rotulados. • Divida documentos visualmente distintos em vários modelos. |
Garantir alta precisão de modelo para modelos personalizados
As variações na estrutura de seus documentos afetam a precisão do seu modelo. As pontuações de precisão relatadas podem ser inconsistentes quando os documentos analisados diferem dos documentos usados no treinamento. Lembre-se de que um conjunto de documentos pode parecer semelhante quando visto por humanos, mas parece ser diferente de um modelo de IA. Siga a lista das melhores práticas para modelos de treinamento com a precisão mais alta. Seguir essas diretrizes deve produzir um modelo com pontuações de confiança e precisão mais altas durante a análise e reduzir o número de documentos sinalizados para revisão humana.
Verifique se todas as variações de um documento estão incluídas no conjunto de dados de treinamento. As variações incluem formatos diferentes, por exemplo, PDFs digitais versus digitalizados.
Adicione pelo menos cinco amostras de cada tipo ao conjunto de dados de treinamento se você espera que o modelo analise os dois tipos de documentos PDF.
Separe os tipos de documento visualmente distintos para treinar modelos diferentes nos modelos personalizados e modelos neurais.
- Como regra geral, se você remover todos os valores inseridos pelo usuário e os documentos parecerem semelhantes, será necessário adicionar mais dados de treinamento ao modelo existente.
- Se os documentos não forem semelhantes, divida os dados de treinamento em pastas diferentes e treine um modelo para cada variação. Em seguida, você pode compor as diferentes variações em um único modelo.
Certifique-se de não ter rótulos estranhos.
Certifique-se de que a assinatura e a identificação da região não incluam o texto ao redor.
Confiança de tabela, linha e célula
Com a adição da confiança de tabela, linha e célula com a API 2024-02-29-preview e em diante, aqui estão algumas perguntas comuns que devem ajudar na interpretação das pontuações de tabela, linha e célula:
Q: É possível ver uma pontuação de confiança alta para as células, mas uma pontuação de confiança baixa para a linha?
R: Sim. Os diferentes níveis de confiança da tabela (célula, linha e tabela) destinam-se a capturar a exatidão de uma previsão nesse nível específico. Uma célula prevista corretamente que pertença a uma linha com outras possíveis falhas teria alta confiança na célula, mas a confiança da linha deveria ser baixa. Da mesma forma, uma linha correta em uma tabela com desafios com outras linhas teria uma confiança de linha alta, enquanto a confiança geral da tabela seria baixa.
Q: Qual é a pontuação de confiança esperada quando as células são mescladas? Como uma mesclagem resulta na alteração do número de colunas identificadas, como as pontuações são afetadas?
A: Independentemente do tipo de tabela, a expectativa para as células mescladas é que elas tenham valores de confiança mais baixos. Além disso, a célula que está faltando (porque foi mesclada com uma célula adjacente) também deve ter o valor NULL com menor confiança. O quanto esses valores podem ser mais baixos depende do conjunto de dados de treinamento; a tendência geral de células mescladas e ausentes com pontuações mais baixas deve se manter.
Q: Qual é a pontuação de confiança quando um valor é opcional? Você deve esperar uma célula com valor NULL e alta pontuação de confiança se o valor estiver faltando?
A: Se o seu conjunto de dados de treinamento for representativo da opcionalidade das células, isso ajudará o modelo a saber com que frequência um valor tende a aparecer no conjunto de treinamento e, portanto, o que esperar durante a inferência. Esse recurso é usado ao calcular a confiança de uma previsão ou de não fazer nenhuma previsão (NULL). Você deve esperar um campo vazio com alta confiança para valores ausentes que também estão quase vazios no conjunto de treinamento.
Q: Como as pontuações de confiança são afetadas se um campo for opcional e não estiver presente ou for omitido? A expectativa é que a pontuação de confiança responda a essa pergunta?
A: Quando um valor está faltando em uma linha, a célula tem um valor NULL e uma confiança atribuída. Uma pontuação de confiança alta aqui deve significar que a previsão do modelo (de não haver um valor) tem maior probabilidade de estar correta. Em contraste, uma pontuação baixa deve sinalizar mais incerteza do modelo (e, portanto, a possibilidade de um erro, como a perda do valor).
Q: Qual deve ser a expectativa de confiança da célula e da linha ao extrair uma tabela de várias páginas com uma linha dividida entre páginas?
A: Espere que a confiança da célula seja alta e que a confiança da linha seja potencialmente menor do que as linhas que não estão divididas. A proporção de linhas divididas no conjunto de dados de treinamento pode afetar a pontuação de confiança. Em geral, uma linha dividida parece diferente das outras linhas da tabela (portanto, o modelo tem menos certeza de que está correto).
Q: Para tabelas de páginas cruzadas com linhas que terminam e começam de forma limpa nos limites da página, é correto assumir que as pontuações de confiança são consistentes entre as páginas?
R: Sim. Como as linhas parecem semelhantes em formato e conteúdo, independentemente de onde estejam no documento (ou em qual página), suas respectivas pontuações de confiança devem ser consistentes.
Q: Qual é a melhor maneira de utilizar as novas pontuações de confiança?
A: Observe todos os níveis de confiança da tabela, começando com uma abordagem de cima para baixo: comece verificando a confiança de uma tabela como um todo, depois faça uma busca detalhada até o nível da linha e observe as linhas individuais e, por fim, observe as confianças no nível da célula. Dependendo do tipo de tabela, há algumas coisas a serem observadas:
Para tabelas fixas, a confiança no nível da célula já captura bastante informação sobre a correção das coisas. Isso significa que simplesmente examinar cada célula e verificar sua confiança pode ser suficiente para ajudar a determinar a qualidade da previsão. Para tabelas dinâmicas, os níveis devem ser construídos uns sobre os outros, portanto a abordagem de cima para baixo é mais importante.