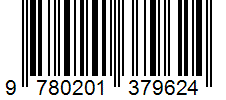As versões de visualização pública do Document Intelligence fornecem acesso antecipado a recursos que estão em desenvolvimento ativo. Recursos, abordagens e processos podem mudar, antes da Disponibilidade Geral (GA), com base nos comentários dos usuários.
A versão de visualização pública das bibliotecas de cliente do Document Intelligence usa como padrão a API REST versão 2024-07-31-preview.
A versão de pré-visualização pública 2024-07-31-preview está atualmente disponível apenas nas seguintes regiões do Azure. Observe que o modelo generativo personalizado (extração de campo de documento) no AI Studio só está disponível na região Centro-Norte dos EUA:
E.U.A. Leste
Oeste dos EUA2
Europa Ocidental
Centro-Norte dos EUA
Este conteúdo aplica-se a:v4.0 (pré-visualização) | Versões anteriores: v3.1 (GA)
Os recursos adicionais estão disponíveis em todos os modelos, exceto no modelo de cartão de visita.
Capacidades
O Document Intelligence suporta capacidades de análise mais sofisticadas e modulares. Use os recursos complementares para estender os resultados e incluir mais recursos extraídos de seus documentos. Alguns recursos adicionais incorrem em um custo extra. Esses recursos opcionais podem ser ativados e desativados dependendo do cenário de extração do documento. Para habilitar um recurso, adicione o nome do recurso associado à propriedade de cadeia de caracteres de features consulta. Você pode habilitar mais de um recurso de complemento em uma solicitação fornecendo uma lista de recursos separados por vírgula. Os seguintes recursos complementares estão disponíveis para 2023-07-31 (GA) versões posteriores.
Nem todos os recursos adicionais são suportados por todos os modelos. Para obter mais informações, consulteextração de dados do modelo.
Atualmente, os recursos de complemento não são suportados para tipos de arquivo do Microsoft Office.
O Document Intelligence suporta recursos opcionais que podem ser habilitados e desabilitados dependendo do cenário de extração de documentos. Os seguintes recursos complementares estão disponíveis para 2023-10-31-previewo , e versões posteriores:
A implementação dos campos de consulta na API 2023-10-30-preview é diferente da última versão de visualização. A nova implementação é menos dispendiosa e funciona bem com documentos estruturados.
✱ Add-On - Os campos de consulta têm um preço diferente dos outros recursos do complemento. Consulte os preços para obter detalhes.
Formatos de ficheiro suportados
PDF
Imagens: JPEG/JPG, PNG, BMP, TIFF, , HEIF
✱ Os ficheiros do Microsoft Office não são suportados no momento.
Extração de alta resolução
A tarefa de reconhecer texto pequeno de documentos de grande porte, como desenhos de engenharia, é um desafio. Muitas vezes, o texto é misturado com outros elementos gráficos e tem fontes, tamanhos e orientações variadas. Além disso, o texto pode ser dividido em partes separadas ou conectado com outros símbolos. O Document Intelligence agora suporta a extração de conteúdo desses tipos de documentos com o ocr.highResolution recurso. Você obtém melhor qualidade de extração de conteúdo de documentos A1/A2/A3 habilitando esse recurso de complemento.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.OCR_HIGH_RESOLUTION], # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_with_highres]
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
# Analyze a document at a URL:
url = "(https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-highres.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.OCR_HIGH_RESOLUTION] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_with_highres]
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
A ocr.formula capacidade extrai todas as fórmulas identificadas, como equações matemáticas, na formulas coleção como um objeto de nível superior em content. Dentro contentdo , as fórmulas detetadas são representadas como :formula:. Cada entrada nesta coleção representa uma fórmula que inclui o tipo de fórmula como inline ou display, e sua representação LaTeX como value juntamente com suas polygon coordenadas. Inicialmente, as fórmulas aparecem no final de cada página.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.FORMULAS], # Specify which add-on capabilities to enable
)
result: AnalyzeResult = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
if page.formulas:
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
# To learn the detailed concept of "polygon" in the following content, visit: https://aka.ms/bounding-region
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {formula.polygon}")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/layout-formulas.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.FORMULAS] # Specify which add-on capabilities to enable
)
result = poller.result()
# [START analyze_formulas]
for page in result.pages:
print(f"----Formulas detected from page #{page.page_number}----")
inline_formulas = [f for f in page.formulas if f.kind == "inline"]
display_formulas = [f for f in page.formulas if f.kind == "display"]
print(f"Detected {len(inline_formulas)} inline formulas.")
for formula_idx, formula in enumerate(inline_formulas):
print(f"- Inline #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
print(f"\nDetected {len(display_formulas)} display formulas.")
for formula_idx, formula in enumerate(display_formulas):
print(f"- Display #{formula_idx}: {formula.value}")
print(f" Confidence: {formula.confidence}")
print(f" Bounding regions: {format_polygon(formula.polygon)}")
"content": ":formula:",
"pages": [
{
"pageNumber": 1,
"formulas": [
{
"kind": "inline",
"value": "\\frac { \\partial a } { \\partial b }",
"polygon": [...],
"span": {...},
"confidence": 0.99
},
{
"kind": "display",
"value": "y = a \\times b + a \\times c",
"polygon": [...],
"span": {...},
"confidence": 0.99
}
]
}
]
Extração de propriedade de fonte
O ocr.font recurso extrai todas as propriedades de fonte do texto extraído na styles coleção como um objeto de nível superior em content. Cada objeto de estilo especifica uma única propriedade de fonte, a extensão de texto à qual se aplica e sua pontuação de confiança correspondente. A propriedade style existente é estendida com mais propriedades de fonte, como similarFontFamily para a fonte do texto, fontStyle para estilos como itálico e normal, fontWeight para negrito ou normal, color para cor do texto e backgroundColor para cor da caixa delimitadora de texto.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if result.styles and any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
return
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/receipt/receipt-with-tips.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.STYLE_FONT] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_fonts]
# DocumentStyle has the following font related attributes:
similar_font_families = defaultdict(list) # e.g., 'Arial, sans-serif
font_styles = defaultdict(list) # e.g, 'italic'
font_weights = defaultdict(list) # e.g., 'bold'
font_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
font_background_colors = defaultdict(list) # in '#rrggbb' hexadecimal format
if any([style.is_handwritten for style in result.styles]):
print("Document contains handwritten content")
else:
print("Document does not contain handwritten content")
print("\n----Fonts styles detected in the document----")
# Iterate over the styles and group them by their font attributes.
for style in result.styles:
if style.similar_font_family:
similar_font_families[style.similar_font_family].append(style)
if style.font_style:
font_styles[style.font_style].append(style)
if style.font_weight:
font_weights[style.font_weight].append(style)
if style.color:
font_colors[style.color].append(style)
if style.background_color:
font_background_colors[style.background_color].append(style)
print(f"Detected {len(similar_font_families)} font families:")
for font_family, styles in similar_font_families.items():
print(f"- Font family: '{font_family}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_styles)} font styles:")
for font_style, styles in font_styles.items():
print(f"- Font style: '{font_style}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_weights)} font weights:")
for font_weight, styles in font_weights.items():
print(f"- Font weight: '{font_weight}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_colors)} font colors:")
for font_color, styles in font_colors.items():
print(f"- Font color: '{font_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
print(f"\nDetected {len(font_background_colors)} font background colors:")
for font_background_color, styles in font_background_colors.items():
print(f"- Font background color: '{font_background_color}'")
print(f" Text: '{get_styled_text(styles, result.content)}'")
O ocr.barcode recurso extrai todos os códigos de barras identificados na barcodes coleção como um objeto de nível superior em content. Dentro do , os contentcódigos de barras detetados são representados como :barcode:. Cada entrada nesta coleção representa um código de barras e inclui o tipo de código de barras como kind e o conteúdo do código de barras incorporado juntamente value com suas polygon coordenadas. Inicialmente, os códigos de barras aparecem no final de cada página. O confidence é codificado para como 1.
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-barcodes.jpg?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.BARCODES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_barcodes]
# Iterate over extracted barcodes on each page.
for page in result.pages:
print(f"----Barcodes detected from page #{page.page_number}----")
print(f"Detected {len(page.barcodes)} barcodes:")
for barcode_idx, barcode in enumerate(page.barcodes):
print(f"- Barcode #{barcode_idx}: {barcode.value}")
print(f" Kind: {barcode.kind}")
print(f" Confidence: {barcode.confidence}")
print(f" Bounding regions: {format_polygon(barcode.polygon)}")
Adicionar o recurso à analyzeResult solicitação prevê o idioma principal detetado para cada linha de texto, juntamente com o confidencelanguages na coleção em analyzeResult.languages
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result: AnalyzeResult = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
if result.languages:
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(
f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'"
)
# Analyze a document at a URL:
url = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/add-on/add-on-fonts_and_languages.png?raw=true"
poller = document_analysis_client.begin_analyze_document_from_url(
"prebuilt-layout", document_url=url, features=[AnalysisFeature.LANGUAGES] # Specify which add-on capabilities to enable.
)
result = poller.result()
# [START analyze_languages]
print("----Languages detected in the document----")
print(f"Detected {len(result.languages)} languages:")
for lang_idx, lang in enumerate(result.languages):
print(f"- Language #{lang_idx}: locale '{lang.locale}'")
print(f" Confidence: {lang.confidence}")
print(f" Text: '{','.join([result.content[span.offset : span.offset + span.length] for span in lang.spans])}'")
O recurso de PDF pesquisável permite converter um PDF analógico, como arquivos PDF de imagem digitalizada, em um PDF com texto incorporado. O texto incorporado permite a pesquisa profunda de texto dentro do conteúdo extraído do PDF, sobrepondo as entidades de texto detetadas sobre os arquivos de imagem.
Importante
Atualmente, o recurso PDF pesquisável é suportado apenas pelo modelo prebuilt-readRead OCR. Ao usar esse recurso, especifique o modelId como prebuilt-read, pois outros tipos de modelo retornarão erro para esta versão de visualização.
O PDF pesquisável está incluído no modelo 2024-07-31-preview prebuilt-read sem custo de uso para consumo geral de PDF.
Use PDF pesquisável
Para usar PDF pesquisável, faça uma POST solicitação usando a Analyze operação e especifique o formato de saída como pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Quando a Analyze operação estiver concluída, faça uma GET solicitação para recuperar os resultados da Analyze operação.
Após a conclusão bem-sucedida, o PDF pode ser recuperado e baixado como application/pdf. Esta operação permite o download direto da forma de texto incorporado do PDF em vez do JSON codificado em Base64.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Pares chave-valor
Em versões anteriores da API, o modelo extraía prebuilt-document pares chave-valor de formulários e documentos. Com a adição do recurso ao layout pré-construído, o modelo de keyValuePairs layout agora produz os mesmos resultados.
Os pares chave-valor são extensões específicas dentro do documento que identificam um rótulo ou chave e sua resposta ou valor associado. Em um formulário estruturado, esses pares podem ser o rótulo e o valor que o usuário inseriu para esse campo. Em um documento não estruturado, eles podem ser a data em que um contrato foi executado com base no texto de um parágrafo. O modelo de IA é treinado para extrair chaves e valores identificáveis com base em uma ampla variedade de tipos de documentos, formatos e estruturas.
As chaves também podem existir isoladamente quando o modelo deteta a existência de uma chave, sem valor associado ou ao processar campos opcionais. Por exemplo, um campo de nome do meio pode ser deixado em branco em um formulário em alguns casos. Os pares chave-valor são extensões de texto contidas no documento. Para documentos em que o mesmo valor é descrito de maneiras diferentes, por exemplo, cliente/usuário, a chave associada é cliente ou usuário (com base no contexto).
Os campos de consulta são um recurso complementar para estender o esquema extraído de qualquer modelo pré-construído ou definir um nome de chave específico quando o nome da chave é variável. Para usar campos de consulta, defina os recursos como queryFields e forneça uma lista separada por vírgulas queryFields de nomes de campos na propriedade.
O Document Intelligence agora suporta extrações de campo de consulta. Com a extração de campo de consulta, você pode adicionar campos ao processo de extração usando uma solicitação de consulta sem a necessidade de treinamento adicional.
Use campos de consulta quando precisar estender o esquema de um modelo pré-construído ou personalizado ou precisar extrair alguns campos com a saída do layout.
Os campos de consulta são um recurso de complemento premium. Para obter melhores resultados, defina os campos que deseja extrair usando nomes de campo de caso camel ou caso Pascal para nomes de campo de várias palavras.
Os campos de consulta suportam um máximo de 20 campos por solicitação. Se o documento contiver um valor para o campo, o campo e o valor serão retornados.
Esta versão tem uma nova implementação do recurso de campos de consulta que tem um preço mais baixo do que a implementação anterior e deve ser validada.
Nota
A extração de campo de consulta do Document Intelligence Studio está atualmente disponível com a API de modelos Layout e Prebuilt 2024-02-29-preview2023-10-31-preview e versões posteriores, exceto para os US tax modelos (modelos W2, 1098s e 1099s).
Extração de campo de consulta
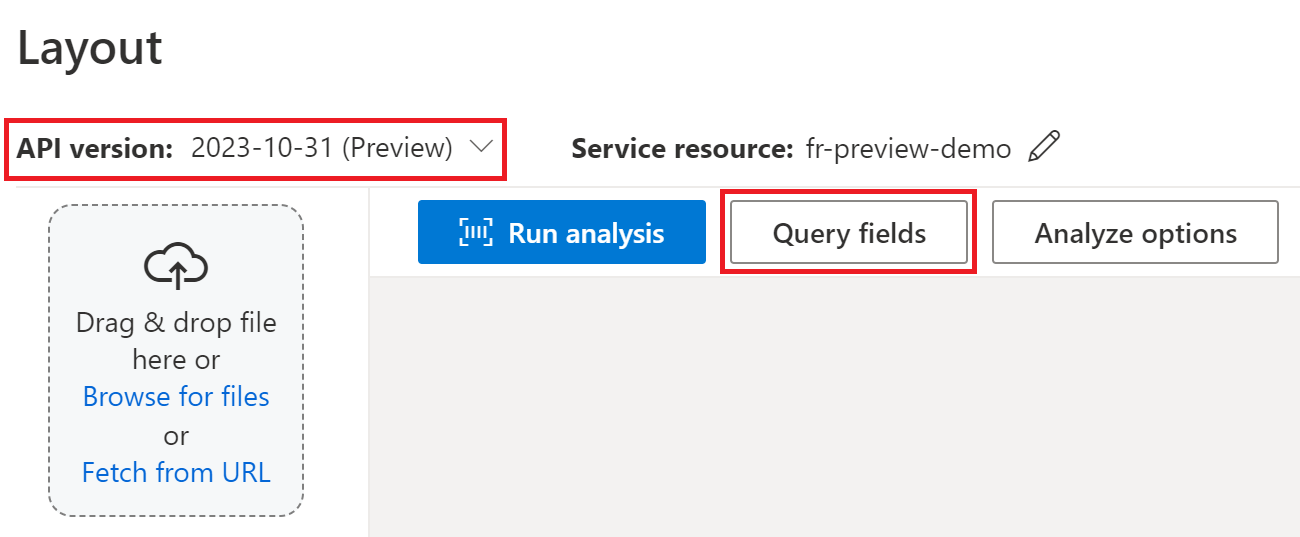
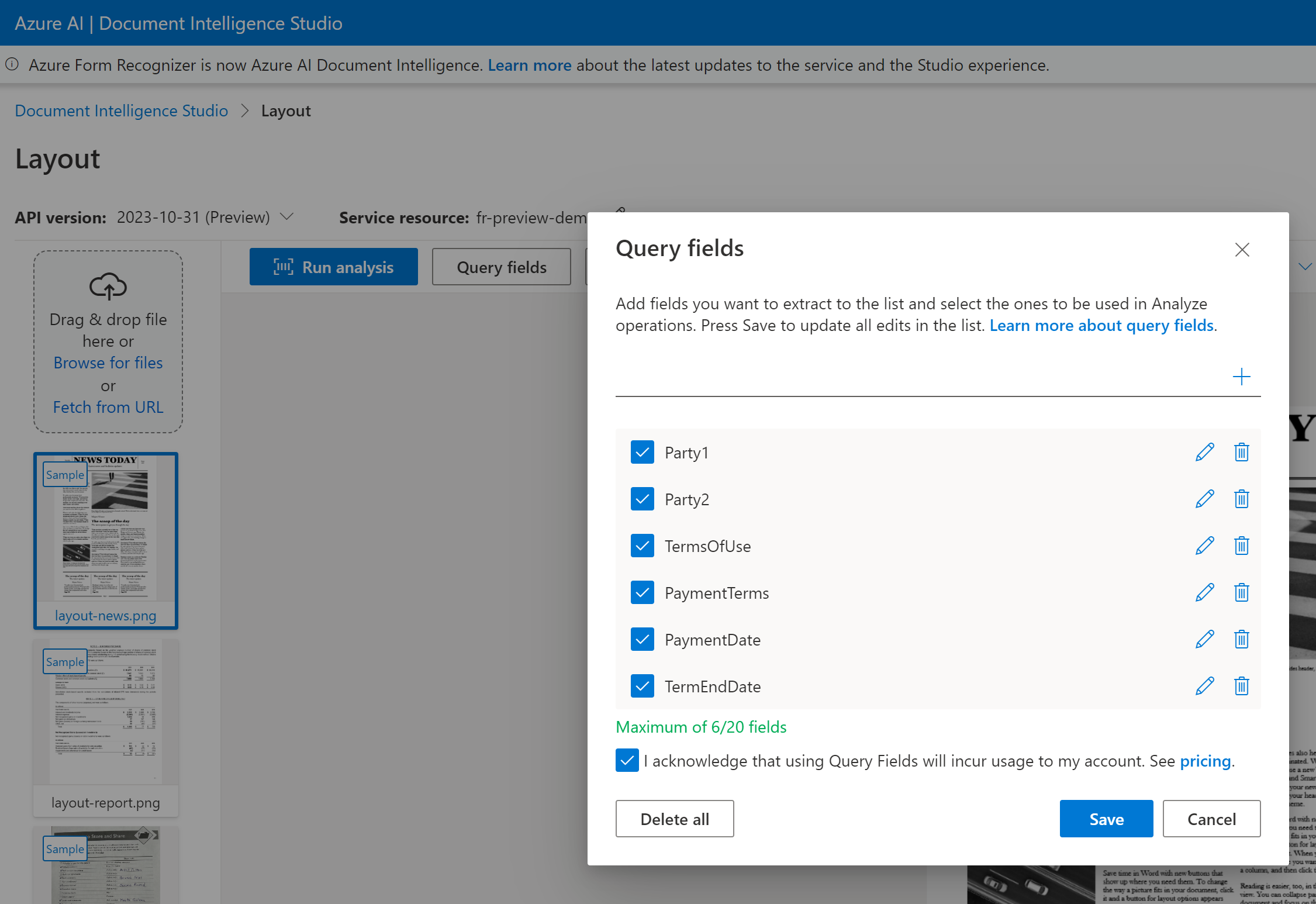
Para extração de campo de consulta, especifique os campos que deseja extrair e o Document Intelligence analisa o documento de acordo. Eis um exemplo:
Se você estiver processando um contrato no Document Intelligence Studio, use as 2024-02-29-preview versões ou 2023-10-31-preview :
Você pode passar uma lista de rótulos de campo como Party1, Party2, TermsOfUse, PaymentTerms, PaymentDatee TermEndDate como parte da analyze document solicitação.
O Document Intelligence é capaz de analisar e extrair os dados de campo e retornar os valores em uma saída JSON estruturada.
Além dos campos de consulta, a resposta inclui texto, tabelas, marcas de seleção e outros dados relevantes.
# Analyze a document at a URL:
formUrl = "https://github.com/Azure-Samples/document-intelligence-code-samples/blob/main/Data/invoice/simple-invoice.png?raw=true"
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=formUrl),
features=[DocumentAnalysisFeature.QUERY_FIELDS], # Specify which add-on capabilities to enable.
query_fields=["Address", "InvoiceNumber"], # Set the features and provide a comma-separated list of field names.
)
result: AnalyzeResult = poller.result()
print("Here are extra fields in result:\n")
if result.documents:
for doc in result.documents:
if doc.fields and doc.fields["Address"]:
print(f"Address: {doc.fields['Address'].value_string}")
if doc.fields and doc.fields["InvoiceNumber"]:
print(f"Invoice number: {doc.fields['InvoiceNumber'].value_string}")