O que é o modelo de layout da Informação de Documentos?
Esse conteúdo se aplica a: ![]() v4.0 (GA) | Versões anteriores:
v4.0 (GA) | Versões anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
O modelo de layout da Informação de Documentos é uma API avançada de análise de documentos baseada em aprendizado de máquina, disponível na nuvem da Informação de Documentos. Ela permite que você obtenha documentos em diversos formatos e retorne representações de dados estruturados desses documentos. Ela combina uma versão aprimorada de nossos poderosos recursos de OCR (reconhecimento óptico de caracteres) com modelos de aprendizado profundo para extrair texto, tabelas, marcas de seleção e estrutura do documento.
Análise de layout de estrutura do documento
Análise de layout de estrutura do documento é o processo de análise de um documento para extrair regiões de interesse e suas inter-relações. A meta é extrair texto e elementos estruturais da página para criar melhores modelos de reconhecimento de semântica. Há dois tipos de funções em um layout de documento:
- Funções geométricas: texto, tabelas, figuras e marcas de seleção são exemplos de funções geométricas.
- Funções lógicas: títulos, cabeçalhos e rodapés são exemplos de funções lógicas de textos.
A ilustração a seguir mostra os componentes típicos em uma imagem de uma página de exemplo.

Opções de desenvolvimento
Document Intelligence v4.0: 2024-11-30 (GA) oferece suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Modelo de layout | • Estúdio da Informação de Documentos • API REST • SDK do C# • SDK do Python • SDK do Java • SDK do JavaScript |
prebuilt-layout |
Idiomas com suporte
Confira Suporte a idiomas — modelos de análise de documentos para obter uma lista completa de idiomas com suporte.
Tipos de arquivo com suporte
Informação de Documentos v4.0: o modelo de layout 2024-11-30 (GA) dá suporte aos seguintes formatos de arquivo:
| Modelar | Image,: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Layout | ✔ | ✔ | ✔ |
Requisitos de entrada
Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de camada gratuita, apenas as duas primeiras páginas são processadas).
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
O tamanho do arquivo para análise de documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 x 10.000 pixels.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1.024 x 768 pixels. Essa dimensão corresponde a aproximadamente
8pontos de texto a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para o treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é de
1GB, com um máximo de 10.000 páginas. Para2024-11-30(GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Para obter mais informações sobre uso do modelo, cotas e limites de serviço, confira limites de serviço.
Introdução ao modelo layout
Veja como os dados, incluindo texto, tabelas, cabeçalhos de tabela, marcas de seleção e informações de estrutura, são extraídos de documentos usando a Informação de Documentos. Você precisa dos seguintes recursos:
Uma assinatura do Azure — você pode criar uma gratuitamente.
Uma instância da Informação de Documentos no portal do Azure. Você pode usar o tipo de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter a chave e o ponto de extremidade.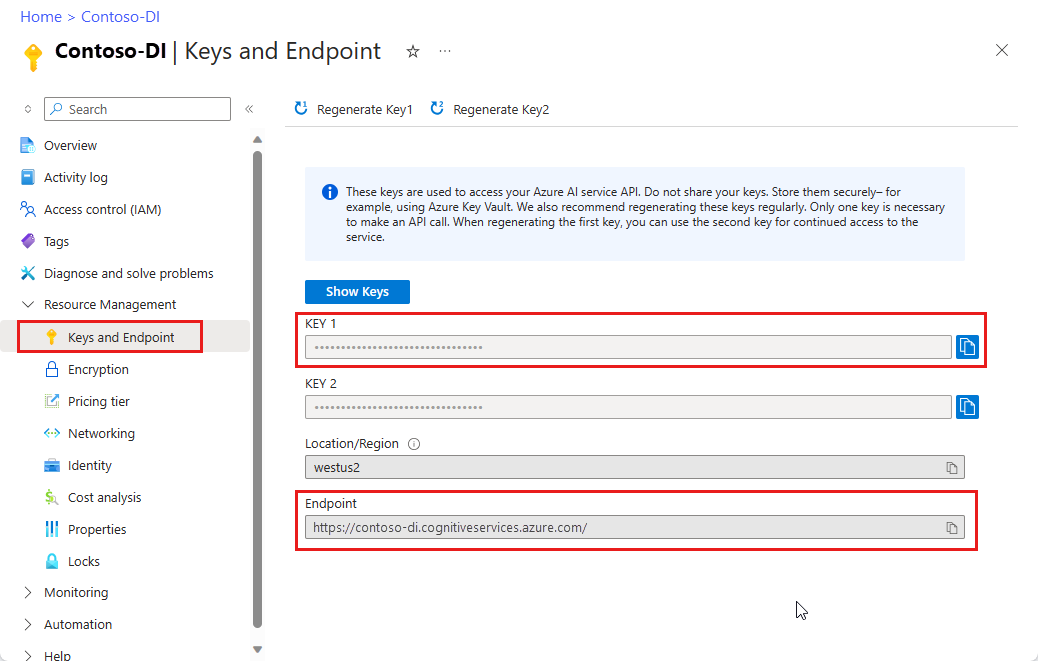
Depois de recuperar a sua chave e ponto de extremidade, você pode usar as seguintes opções de desenvolvimento para criar e implantar os seus aplicativos da Informação de Documentos:
Extração de dados
O modelo de layout extrai elementos estruturais de seus documentos. A seguir estão as descrições desses elementos estruturais com orientação sobre como extraí-los da entrada do documento:
- Páginas
- Parágrafos
- Texto, linhas e palavras
- Marcas de seleção
- Tabelas
- Resposta de saída para Markdown
- Imagens
- Seções
Pages (Páginas)
A coleção de páginas é uma lista de páginas dentro do documento. Cada página é representada sequencialmente dentro do documento e inclui o ângulo de orientação que indica se a página foi girada, além de largura e altura (dimensões em pixels). As unidades de página na saída do modelo são computadas conforme mostrado:
| Formato de arquivo | Unidade de página computada | Total de páginas |
|---|---|---|
| Imagens (JPEG/JPG, PNG, BMP, HEIF) | Cada imagem = 1 unidade de página | Total de imagens |
| Cada página no PDF = 1 unidade de página | Total de páginas no PDF | |
| TIFF | Cada imagem no TIFF = 1 unidade de página | Total de imagens no TIFF |
| Word (DOCX) | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
| Excel (XLSX) | Cada planilha = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de planilhas |
| PowerPoint (PPTX) | Cada slide = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de slides |
| HTML | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Extrair páginas selecionadas
Para grandes documentos com várias páginas, use o parâmetro de consulta pages para indicar números de página ou intervalos de página específicos para a extração de texto.
Parágrafos
O modelo do layout extrai todos os blocos de texto identificados na coleção paragraphs como um objeto de nível superior sob analyzeResults. Cada entrada dessa coleção representa um bloco de texto e ../inclui o texto extraído como content e as coordenadas do polygon delimitador. As informações de span apontam para o fragmento de texto dentro da propriedade content de nível superior que contém o texto completo do documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Funções de parágrafo
A nova detecção de objeto de página baseada em aprendizado de máquina extrai funções lógicas como títulos, títulos de seção, cabeçalhos de página, rodapés de página e mais. O modelo de layout da Informação de Documentos atribui determinados blocos de texto na coleção paragraphs com a função especializada ou o tipo previsto pelo modelo. É melhor usar funções de parágrafo com documentos não estruturados para ajudar a entender o layout do conteúdo extraído para uma análise semântica mais rica. Há suporte para as seguintes funções de parágrafo:
| Função prevista | Descrição | Tipos de arquivo com suporte |
|---|---|---|
title |
Os principais títulos da página | pdf, imagem, docx, pptx, xlsx, html |
sectionHeading |
Um ou mais subtítulos na página | pdf, imagem, docx, xlsx, html |
footnote |
Texto próximo à parte inferior da página | pdf, imagem |
pageHeader |
Texto próximo à borda superior da página | pdf, imagem, docx |
pageFooter |
Texto próximo à borda inferior da página | pdf, imagem, docx, pptx, html |
pageNumber |
Número da página | pdf, imagem |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Texto, linhas e palavras
O modelo de layout do documento na Informação de Documentos extrai texto de estilo impresso e manuscrito como lines e words. A coleção styles ../inclui qualquer estilo manuscrito para linhas (se detectado), juntamente com os intervalos apontando para o texto associado. Esse recurso se aplica a linguagens manuscritas com suporte.
Para Microsoft Word, Excel, PowerPoint e HTML, o modelo de layout Document Intelligence v4.0 2024-11-30 (GA) extrai todo o texto incorporado como está. Os textos são extraídos como palavras e parágrafos. Não há suporte para imagens incorporadas.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Estilo manuscrito para linhas de texto
A resposta ../inclui classificar se cada linha de texto tem um estilo manuscrito ou não, junto com uma pontuação de confiança. Para obter mais informações. Consulte Suporte para idiomas manuscritos. O exemplo a seguir mostra um snippet JSON de exemplo.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Se você habilitar o recurso adicional fonte/estilo, também obterá o resultado da fonte/estilo como parte do objeto styles.
Marcas de seleção
O modelo de layout também extrai marcas de seleção de documentos. As marcas de seleção extraídas aparecem na coleção pages de cada página. Elas incluem os delimitadores polygon e confidence e a seleção state (selected/unselected). A representação do texto (ou seja, :selected: e :unselected) também está incluída como o índice inicial (offset) e length que faz referência à propriedade de nível superior content que contém o texto completo do documento.
# Analyze selection marks.
if page.selection_marks:
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{selection_mark.polygon}' and has a confidence of {selection_mark.confidence}"
)
Tabelas
Extrair tabelas é um requisito fundamental para processar documentos que contêm grandes volumes de dados normalmente formatados como tabelas. O modelo de layout extrai tabelas na seção pageResults da saída JSON. As informações extraídas da tabela ../incluem o número de colunas e linhas e a extensão de linhas e de colunas. Cada célula com seu polígono delimitador é uma saída, juntamente com informações, seja a área reconhecida como columnHeader ou não. O modelo dá suporte à extração de tabelas giradas. Cada célula de tabela contém o índice de linha e coluna e as coordenadas do polygon delimitador. Para o texto da célula, o modelo gera as informações span que contêm o índice inicial (offset). O modelo também gera o length no conteúdo de nível superior que contém o texto completo do documento.
Aqui estão alguns fatores a serem considerados ao usar o recurso de extração de fardos do Document Intelligence:
Os dados que você deseja extrair são apresentados como uma tabela e a estrutura da tabela é significativa?
Os dados podem caber em uma grade bidimensional se não estiverem em um formato de tabela?
Suas tabelas abrangem várias páginas? Nesse caso, para evitar rotular todas as páginas, divida o PDF em páginas antes de enviá-lo para a Informação de Documentos. Após a análise, faça o pós-processamento das páginas em uma tabela única.
Consulte Campos tabulares se você estiver criando modelos personalizados. As tabelas dinâmicas possuem um número variável de linhas para cada coluna. As tabelas fixas possuem um número constante de linhas para cada coluna.
Observação
- Não há suporte para analisar tabelas se o arquivo de entrada for XLSX.
- Para 2024-11-30 (GA), as regiões delimitadoras para figuras e tabelas cobrem apenas o conteúdo principal e excluem legendas e notas de rodapé associadas.
if result.tables:
for table_idx, table in enumerate(result.tables):
print(f"Table # {table_idx} has {table.row_count} rows and " f"{table.column_count} columns")
if table.bounding_regions:
for region in table.bounding_regions:
print(f"Table # {table_idx} location on page: {region.page_number} is {region.polygon}")
# Analyze cells.
for cell in table.cells:
print(f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'")
if cell.bounding_regions:
for region in cell.bounding_regions:
print(f"...content on page {region.page_number} is within bounding polygon '{region.polygon}'")
Resposta de saída para o formato Markdown
A API de Layout pode gerar o texto extraído no formato markdown. Use outputContentFormat=markdown para especificar o formato de saída no markdown. O conteúdo de markdown é gerado como parte da seção content.
Observação
Para a v4.0 2024-11-30 (GA), a representação de tabelas foi alterada para tabelas HTML para permitir a renderização de células mescladas, cabeçalhos de várias linhas, etc. Outra alteração relacionada é usar caracteres ☒ da caixa de seleção Unicode e ☐ das marcas de seleção em vez de :selected: e :unselected:. Observe que isso significa que o conteúdo dos campos de marca de seleção conterá :selected: mesmo que seus intervalos se refiram aos caracteres Unicode no intervalo de nível superior.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Figuras
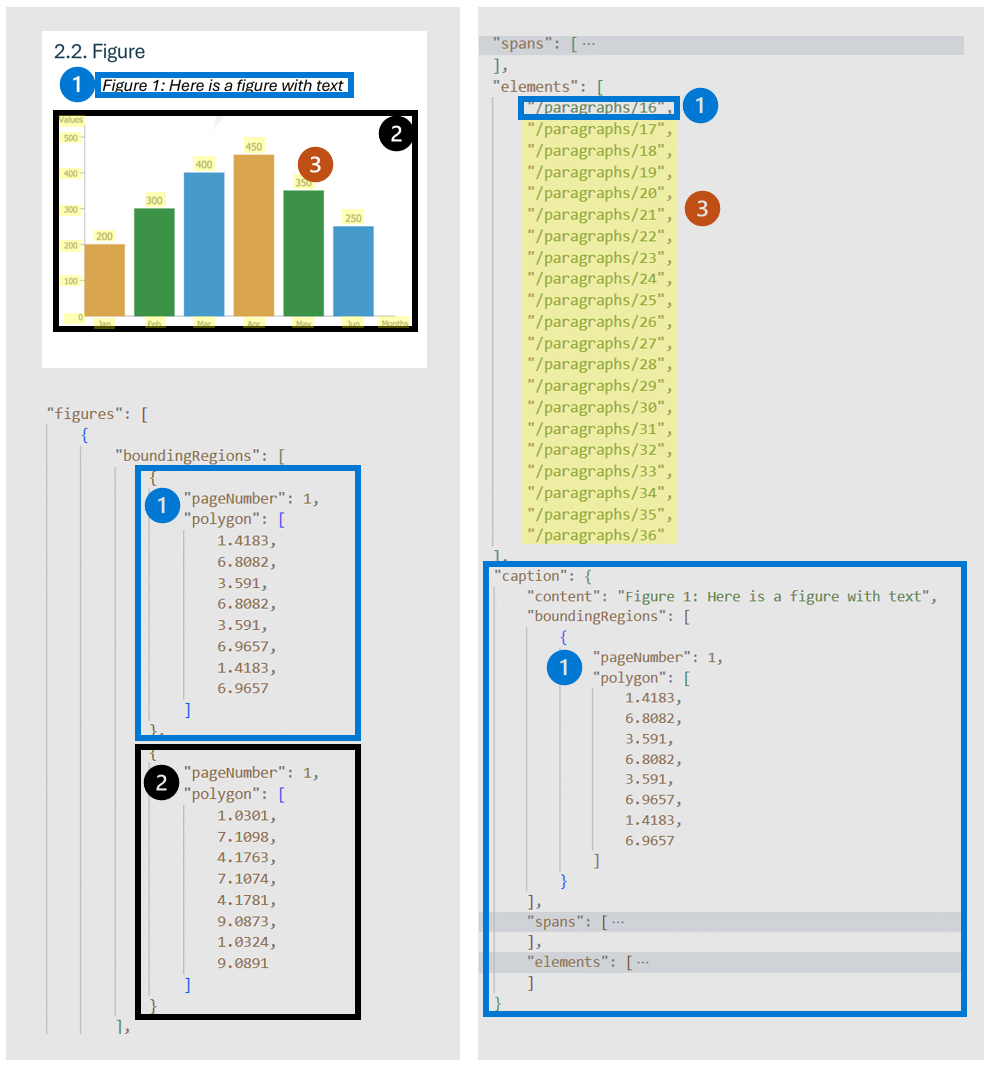
Figuras (gráficos, imagens) em documentos desempenham um papel crucial na complementação e no aprimoramento do conteúdo textual, fornecendo representações visuais que ajudam na compreensão de informações complexas. O objeto figuras detectado pelo modelo layout tem propriedades importantes como boundingRegions (os locais espaciais da figura nas páginas do documento, incluindo o número da página e as coordenadas de polígono que descrevem o limite da figura), spans (detalha os intervalos de texto relacionados à figura, especificando seus deslocamentos e comprimentos dentro do texto do documento. Essa conexão ajuda na associação da figura com seu contexto textual relevante), elements (os identificadores de elementos de texto ou parágrafos dentro do documento relacionados ou descrevem a figura) e caption se houver algum.
Quando output=figures é especificado durante a operação de análise inicial, o serviço gera imagens cortadas para todas as figuras detectadas que podem ser acessadas usando /analyeResults/{resultId}/figures/{figureId}.
FigureId é incluído nos objetos de figura, seguindo uma convenção não documentada de {pageNumber}.{figureIndex} em que figureIndex é redefinido para um por página.
Observação
Para a v4.0 2024-11-30 (GA), as regiões delimitadoras para figuras e tabelas cobrem apenas o conteúdo principal e excluem legendas e notas de rodapé associadas.
# Analyze figures.
if result.figures:
for figures_idx,figures in enumerate(result.figures):
print(f"Figure # {figures_idx} has the following spans:{figures.spans}")
for region in figures.bounding_regions:
print(f"Figure # {figures_idx} location on page:{region.page_number} is within bounding polygon '{region.polygon}'")
Seções
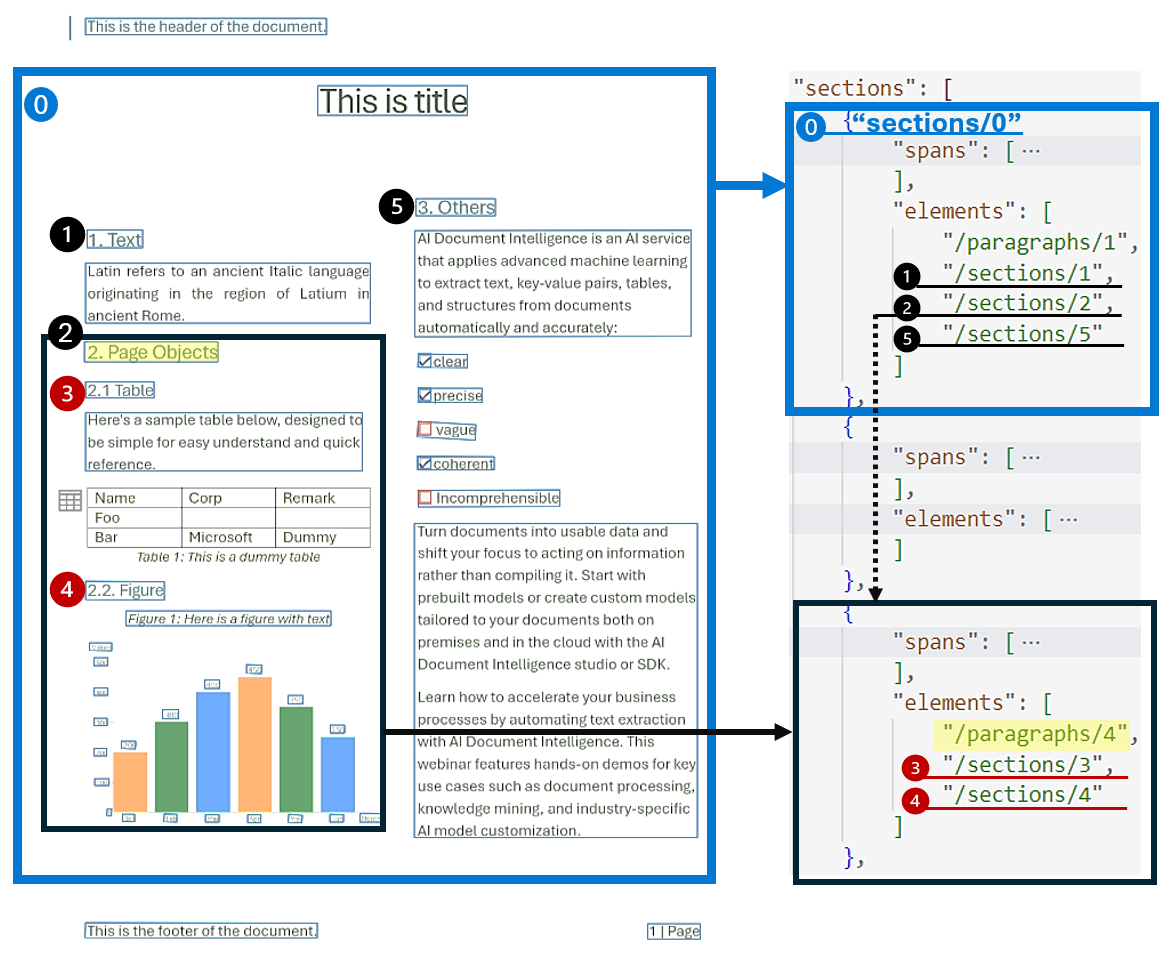
A análise hierárquica da estrutura de documentos é fundamental na organização, compreensão e processamento de documentos extensos. Essa abordagem é vital para segmentar semanticamente documentos longos para aumentar a compreensão, facilitar a navegação e melhorar a recuperação de informações. O advento de RAG (geração aumentada de recuperação) na IA generativa do documento ressalta a importância da análise hierárquica da estrutura de documentos. O modelo layout dá suporte a seções e subseções na saída, que identifica a relação de seções e objeto em cada seção. A estrutura hierárquica é mantida em elements de cada seção. Você pode usar a resposta de saída para o formato Markdown para obter facilmente as seções e subseções no Markdown.
document_intelligence_client = DocumentIntelligenceClient(endpoint=endpoint, credential=AzureKeyCredential(key))
poller = document_intelligence_client.begin_analyze_document(
"prebuilt-layout",
AnalyzeDocumentRequest(url_source=url),
output_content_format=ContentFormat.MARKDOWN,
)
Esse conteúdo se aplica a: ![]() v2.1 | Última versão:
v2.1 | Última versão: ![]() v4.0 (GA)
v4.0 (GA)
O modelo de layout da Informação de Documentos é uma API avançada de análise de documentos baseada em aprendizado de máquina, disponível na nuvem da Informação de Documentos. Ela permite que você obtenha documentos em diversos formatos e retorne representações de dados estruturados desses documentos. Ela combina uma versão aprimorada de nossos poderosos recursos de OCR (reconhecimento óptico de caracteres) com modelos de aprendizado profundo para extrair texto, tabelas, marcas de seleção e estrutura do documento.
Análise de layout do documento
Análise de layout de estrutura do documento é o processo de análise de um documento para extrair regiões de interesse e suas inter-relações. A meta é extrair texto e elementos estruturais da página para criar melhores modelos de reconhecimento de semântica. Há dois tipos de funções em um layout de documento:
- Funções geométricas: texto, tabelas, figuras e marcas de seleção são exemplos de funções geométricas.
- Funções lógicas: títulos, cabeçalhos e rodapés são exemplos de funções lógicas de textos.
A ilustração a seguir mostra os componentes típicos em uma imagem de uma página de exemplo.
Idiomas e localidades com suporte
Confira nossa página Suporte a Idiomas – modelos de análise de documentos, para obter uma lista completa dos idiomas com suporte.
A Informação de Documentos v2.1 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos |
|---|---|
| Modelo de layout | ● Ferramenta de rotulagem da Informação de Documentos • API REST • SDK da biblioteca de clientes • Contêiner do Docker da Informação de Documentos |
Diretrizes de entrada
Formatos de arquivo com suporte:
| Modelar | Image,: JPEG/JPG, PNG, BMP, TIFF, HEIF |
Microsoft Office: Word ( DOCX), Excel (XLSX), PowerPoint (PPTX), HTML |
|
|---|---|---|---|
| Ler | ✔ | ✔ | ✔ |
| Layout | ✔ | ✔ | ✔ |
| Documento geral | ✔ | ✔ | |
| Predefinida | ✔ | ✔ | |
| Extração personalizada | ✔ | ✔ | |
| Classificação personalizada | ✔ | ✔ | ✔ |
Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de camada gratuita, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para análise de documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 x 10.000 pixels.
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1.024 x 768 pixels. Essa dimensão corresponde a aproximadamente
8pontos de texto a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para o treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é de
1GB, com um máximo de 10.000 páginas. Para 2024-11-30 (GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Guia de entrada
- Formatos de arquivo com suporte: JPEG, PNG, PDF e TIFF.
- Número de páginas com suporte: para PDF e TIFF, são processadas até 2.000 páginas. Para assinantes de camada gratuita, somente as duas primeiras páginas são processadas.
- Tamanho de arquivo com suporte: o tamanho do arquivo deve ser inferior a 50 MB e as dimensões devem ter pelo menos 50 x 50 pixels e no máximo 10.000 x 10.000 pixels.
Introdução
Veja como os dados, incluindo texto, tabelas, cabeçalhos de tabela, marcas de seleção e informações de estrutura, são extraídos de documentos usando a Informação de Documentos. Você precisa dos seguintes recursos:
Uma assinatura do Azure — você pode criar uma gratuitamente.
Uma instância da Informação de Documentos no portal do Azure. Você pode usar o tipo de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter a chave e o ponto de extremidade.
Depois de recuperar a sua chave e ponto de extremidade, você pode usar as seguintes opções de desenvolvimento para criar e implantar os seus aplicativos da Informação de Documentos:
Observação
O Estúdio da Informação de Documentos está disponível com APIs v3.0 e versões posteriores.
REST API
Ferramenta de Rotulagem de Amostra da Informação de Documentos
Navegue até a Ferramenta de amostra da Informação de Documentos.
Na home page da ferramenta de exemplos, selecione Usar layout para obter texto, tabelas e marcas de seleção.
No campo Ponto de extremidade do serviço Informação de Documentos, cole o ponto de extremidade obtido com a assinatura da Informação de Documentos.
No campo chave, cole a chave obtida do recurso Informação de Documentos.
No campo Origem, selecione URL no menu suspenso Você pode usar o documento de exemplo:
Clique no botão Buscar.
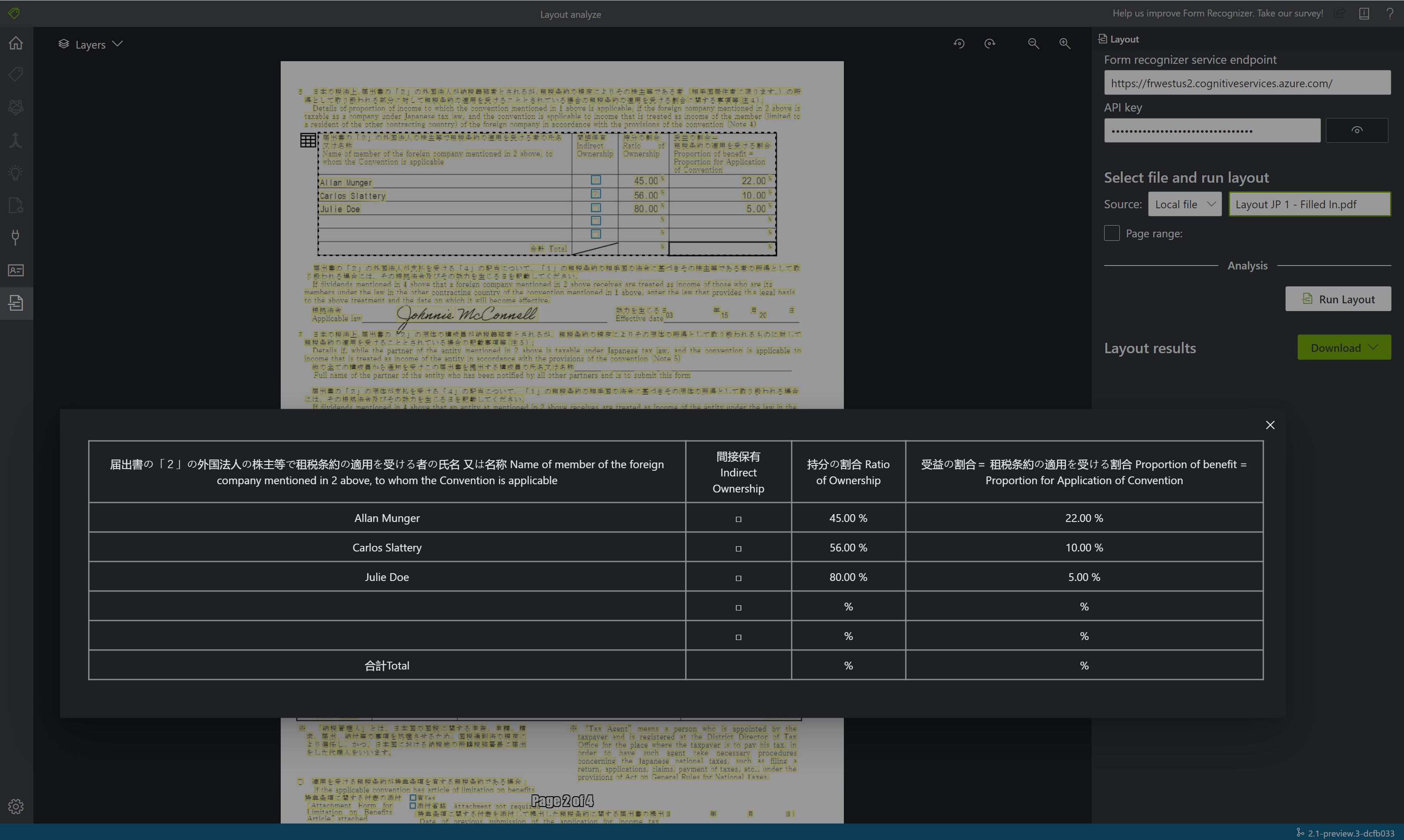
Selecione Executar Layout. A ferramenta Rotulagem de Amostra da Informação de Documentos chama a API
Analyze Layoutpara analisar o documento.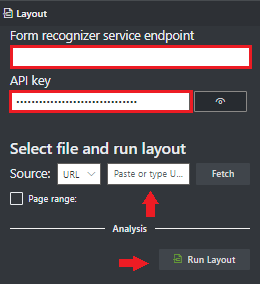
Exibir os resultados: veja o texto extraído realçado, as marcas de seleção detectadas e as tabelas detectadas.
{kind=link}
A Informação de Documentos v2.1 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos |
|---|---|
| API de layout | ● Ferramenta de rotulagem da Informação de Documentos • API REST • SDK da biblioteca de clientes • Contêiner do Docker da Informação de Documentos |
Extrair dados
O modelo de layout extrai elementos estruturais de seus documentos. A seguir estão as descrições desses elementos estruturais com orientação sobre como extraí-los da entrada do documento:
Extrair dados
O modelo de layout extrai elementos estruturais de seus documentos. A seguir estão as descrições desses elementos estruturais com orientação sobre como extraí-los da entrada do documento:
Página
A coleção de páginas é uma lista de páginas dentro do documento. Cada página é representada sequencialmente no documento e ../inclui o ângulo de orientação, indicando se a página foi girada, e a largura e a altura (dimensões em pixels). As unidades de página na saída do modelo são computadas conforme mostrado:
| Formato de arquivo | Unidade de página computada | Total de páginas |
|---|---|---|
| Imagens (JPEG/JPG, PNG, BMP, HEIF) | Cada imagem = 1 unidade de página | Total de imagens |
| Cada página no PDF = 1 unidade de página | Total de páginas no PDF | |
| TIFF | Cada imagem no TIFF = 1 unidade de página | Total de imagens no TIFF |
| Word (DOCX) | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
| Excel (XLSX) | Cada planilha = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de planilhas |
| PowerPoint (PPTX) | Cada slide = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de slides |
| HTML | Até 3.000 caracteres = 1 unidade de página, imagens inseridas ou vinculadas sem suporte | Total de páginas de até 3.000 caracteres cada |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing layout from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Extrair páginas selecionadas de documentos
Para grandes documentos com várias páginas, use o parâmetro de consulta pages para indicar números de página ou intervalos de página específicos para a extração de texto.
Paragraph
O modelo do layout extrai todos os blocos de texto identificados na coleção paragraphs como um objeto de nível superior sob analyzeResults. Cada entrada dessa coleção representa um bloco de texto e ../inclui o texto extraído como content e as coordenadas do polygon delimitador. As informações de span apontam para o fragmento de texto dentro da propriedade content de nível superior que contém o texto completo do documento.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Função de parágrafo
A nova detecção de objeto de página baseada em aprendizado de máquina extrai funções lógicas como títulos, títulos de seção, cabeçalhos de página, rodapés de página e mais. O modelo de layout da Informação de Documentos atribui determinados blocos de texto na coleção paragraphs com a função especializada ou o tipo previsto pelo modelo. É melhor usar funções de parágrafo com documentos não estruturados para ajudar a entender o layout do conteúdo extraído para uma análise semântica mais rica. Há suporte para as seguintes funções de parágrafo:
| Função prevista | Descrição | Tipos de arquivo com suporte |
|---|---|---|
title |
Os principais títulos da página | pdf, imagem, docx, pptx, xlsx, html |
sectionHeading |
Um ou mais subtítulos na página | pdf, imagem, docx, xlsx, html |
footnote |
Texto próximo à parte inferior da página | pdf, imagem |
pageHeader |
Texto próximo à borda superior da página | pdf, imagem, docx |
pageFooter |
Texto próximo à borda inferior da página | pdf, imagem, docx, pptx, html |
pageNumber |
Número da página | pdf, imagem |
{
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"role": "title",
"content": "NEWS TODAY"
},
{
"spans": [],
"boundingRegions": [],
"role": "sectionHeading",
"content": "Mirjam Nilsson"
}
]
}
Texto, linha e palavra
O modelo de layout do documento na Informação de Documentos extrai texto de estilo impresso e manuscrito como lines e words. A coleção styles ../inclui qualquer estilo manuscrito para linhas (se detectado), juntamente com os intervalos apontando para o texto associado. Esse recurso se aplica a linguagens manuscritas com suporte.
Para Microsoft Word, Excel, PowerPoint e HTML, o modelo de layout Document Intelligence v4.0 2024-11-30 (GA) extrai todo o texto incorporado como está. Os textos são extraídos como palavras e parágrafos. Não há suporte para imagens incorporadas.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has word count {len(words)} and text '{line.content}' "
f"within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Estilo manuscrito
A resposta ../inclui classificar se cada linha de texto tem um estilo manuscrito ou não, junto com uma pontuação de confiança. Para obter mais informações. Consulte Suporte para idiomas manuscritos. O exemplo a seguir mostra um snippet JSON de exemplo.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Se você habilitar o recurso adicional fonte/estilo, também obterá o resultado da fonte/estilo como parte do objeto styles.
Marca de seleção
O modelo de layout também extrai marcas de seleção de documentos. As marcas de seleção extraídas aparecem na coleção pages de cada página. Elas incluem os delimitadores polygon e confidence e a seleção state (selected/unselected). A representação do texto (ou seja, :selected: e :unselected) também está incluída como o índice inicial (offset) e length que faz referência à propriedade de nível superior content que contém o texto completo do documento.
{
"selectionMarks": [
{
"state": "unselected",
"polygon": [],
"confidence": 0.995,
"span": {
"offset": 1421,
"length": 12
}
}
]
}
# Analyze selection marks.
for selection_mark in page.selection_marks:
print(
f"Selection mark is '{selection_mark.state}' within bounding polygon "
f"'{format_polygon(selection_mark.polygon)}' and has a confidence of {selection_mark.confidence}"
)
Tabela
Extrair tabelas é um requisito fundamental para processar documentos que contêm grandes volumes de dados normalmente formatados como tabelas. O modelo de layout extrai tabelas na seção pageResults da saída JSON. As informações extraídas da tabela ../incluem o número de colunas e linhas e a extensão de linhas e de colunas. Cada célula com seu polígono delimitador é uma saída, juntamente com informações, seja a área reconhecida como columnHeader ou não. O modelo dá suporte à extração de tabelas giradas. Cada célula de tabela contém o índice de linha e coluna e as coordenadas do polygon delimitador. Para o texto da célula, o modelo gera as informações span que contêm o índice inicial (offset). O modelo também gera o length no conteúdo de nível superior que contém o texto completo do documento.
Aqui estão alguns fatores a serem considerados ao usar o recurso de extração de fardos do Document Intelligence:
Os dados que você deseja extrair são apresentados como uma tabela e a estrutura da tabela é significativa?
Os dados podem caber em uma grade bidimensional se não estiverem em um formato de tabela?
Suas tabelas abrangem várias páginas? Nesse caso, para evitar rotular todas as páginas, divida o PDF em páginas antes de enviá-lo para a Informação de Documentos. Após a análise, faça o pós-processamento das páginas em uma tabela única.
Consulte Campos tabulares se você estiver criando modelos personalizados. As tabelas dinâmicas possuem um número variável de linhas para cada coluna. As tabelas fixas possuem um número constante de linhas para cada coluna.
Observação
- Não há suporte para analisar tabelas se o arquivo de entrada for XLSX.
- O Document Intelligence v4.0 2024-11-30 (GA) oferece suporte a regiões delimitadoras para figuras e tabelas que abrangem apenas o conteúdo principal e excluem legendas e notas de rodapé associadas.
{
"tables": [
{
"rowCount": 9,
"columnCount": 4,
"cells": [
{
"kind": "columnHeader",
"rowIndex": 0,
"columnIndex": 0,
"columnSpan": 4,
"content": "(In millions, except earnings per share)",
"boundingRegions": [],
"spans": []
},
]
}
]
}
# Analyze tables.
for table_idx, table in enumerate(result.tables):
print(
f"Table # {table_idx} has {table.row_count} rows and "
f"{table.column_count} columns"
)
for region in table.bounding_regions:
print(
f"Table # {table_idx} location on page: {region.page_number} is {format_polygon(region.polygon)}"
)
for cell in table.cells:
print(
f"...Cell[{cell.row_index}][{cell.column_index}] has text '{cell.content}'"
)
for region in cell.bounding_regions:
print(
f"...content on page {region.page_number} is within bounding polygon '{format_polygon(region.polygon)}'"
)
Anotações
O modelo layout extrai anotações em documentos, como verificações e cruzes. A resposta ../inclui o tipo de anotação, juntamente com uma pontuação de confiança e um polígono delimitador.
{
"pages": [
{
"annotations": [
{
"kind": "cross",
"polygon": [...],
"confidence": 1
}
]
}
]
}
Saída em ordem de leitura natural (somente idiomas latinos)
Você pode especificar a ordem em que as linhas de texto são geradas com o parâmetro de consulta readingOrder. Use natural para uma saída de ordem de leitura mais amigável, conforme mostrado no exemplo a seguir. Esse recurso é compatível apenas com idiomas latinos.

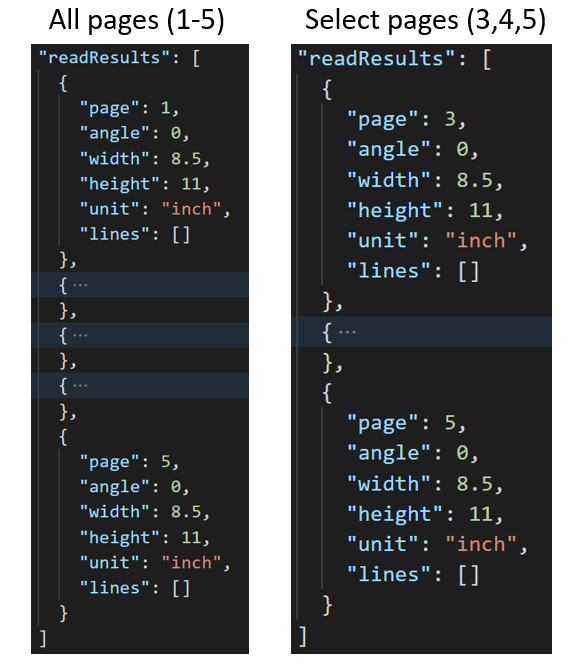
Selecionar número de página ou intervalo para extração de texto
Para grandes documentos com várias páginas, use o parâmetro de consulta pages para indicar números de página ou intervalos de página específicos para a extração de texto. O exemplo a seguir mostra um documento com 10 páginas, com texto extraído para ambos os casos – todas as páginas (1 a 10) e páginas selecionadas (3 a 6).
A operação Obter Resultado de Analisar Layout
A segunda etapa é chamar a operação Obter Resultado de Analisar Layout. Essa operação usa como entrada a ID de Resultado criada pela operação Analyze Layout. Ela retorna uma resposta JSON que contém um campo de status com os seguintes valores possíveis.
| Campo | Tipo | Valores possíveis |
|---|---|---|
| status | string | notStarted: a operação de análise não foi iniciada.running: a operação de análise está em andamento.failed: falha na operação de análise.succeeded: a operação de análise foi bem-sucedida. |
Chame essa operação iterativamente até que ela retorne o valor succeeded. Para evitar exceder a taxa de solicitações por segundo (RPS), use um intervalo de 3 a 5 segundos.
Quando o campo status tiver o valor succeeded, a resposta JSON ../inclui o layout extraído, o texto, as tabelas e as marcas de seleção. Os dados extraídos ../incluem linhas e palavras de texto extraídas, caixas delimitadas, aparência de texto com indicação manuscrita, tabelas e marcas de seleção com a indicação selecionada/não selecionada.
Classificação manuscrita para linhas de texto (somente idiomas latinos)
A resposta ../inclui classificar se cada linha de texto tem um estilo manuscrito ou não, junto com uma pontuação de confiança. Esse recurso é compatível apenas com idiomas latinos. O exemplo a seguir mostra a classificação manuscrita para o texto na imagem.

Saída JSON de exemplo
A resposta para a operação Obter Resultado de Analisar Layout é uma representação estruturada do documento com todas as informações extraídas. Confira aqui um arquivo de documento de exemplo e a respectiva saída de layout de exemplo de saída estruturada.
A saída JSON tem duas partes:
- O nó
readResultscontém todas as marcas de texto e seleção reconhecidas. A hierarquia de apresentação de texto é página, linha e, em seguida, palavras individuais. - O nó
pageResultscontém tabelas e células extraídas com as caixas delimitadoras, a confiança e uma referência às linhas e palavras no campo "readResults".
Saída de exemplo
Texto
A API de Layout extrai texto de documentos e imagens com várias cores e ângulos de texto. Ela aceita fotos de documentos, faxes, texto impresso e/ou manuscrito (somente em inglês) e modos mistos. O texto é extraído com informações fornecidas em linhas, palavras, caixas delimitadoras, pontuações de confiança e estilo (manuscrito ou outro). Todas as informações de texto são incluídas na seção readResults da saída JSON.
Tabelas com cabeçalhos
A API de layout extrai tabelas na seção pageResults da saída JSON. Os documentos podem ser fotografados ou digitalizados. As tabelas podem ser complexas com células ou colunas mescladas, com ou sem bordas e com ângulos peculiares. As informações extraídas da tabela ../incluem o número de colunas e linhas e a extensão de linhas e de colunas. Cada célula com sua caixa delimitadora é gerada junto com o fato da área ser reconhecida como parte de um cabeçalho ou não. As células do cabeçalho previsto do modelo podem abranger várias linhas e não são necessariamente as primeiras linhas em uma tabela. Eles também funcionam com tabelas giradas. Cada célula de tabela também ../inclui o texto completo com referências às palavras individuais na seção readResults.
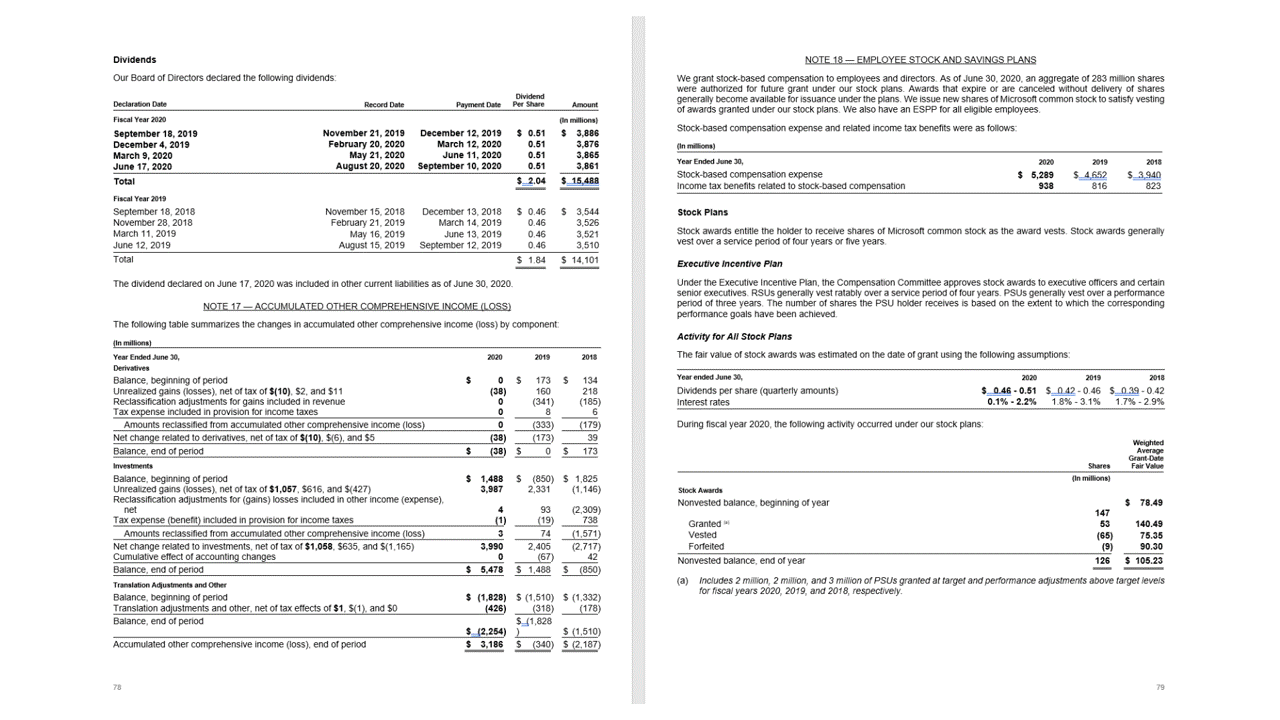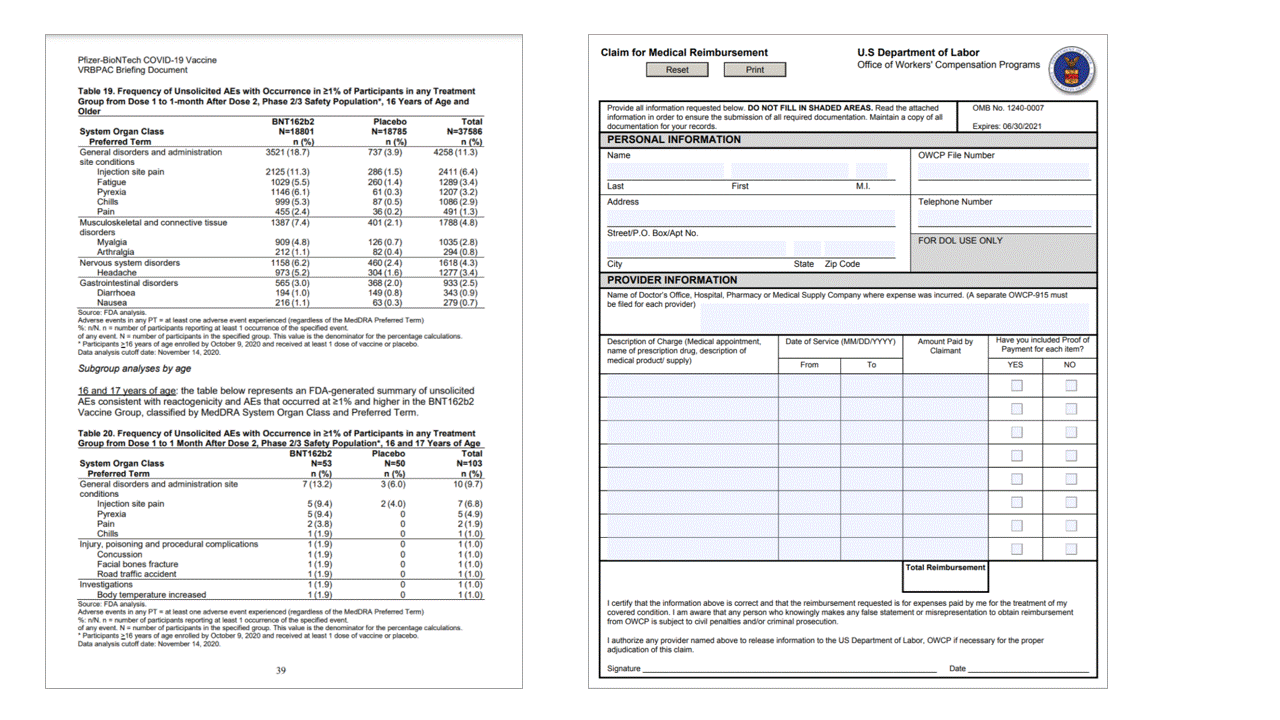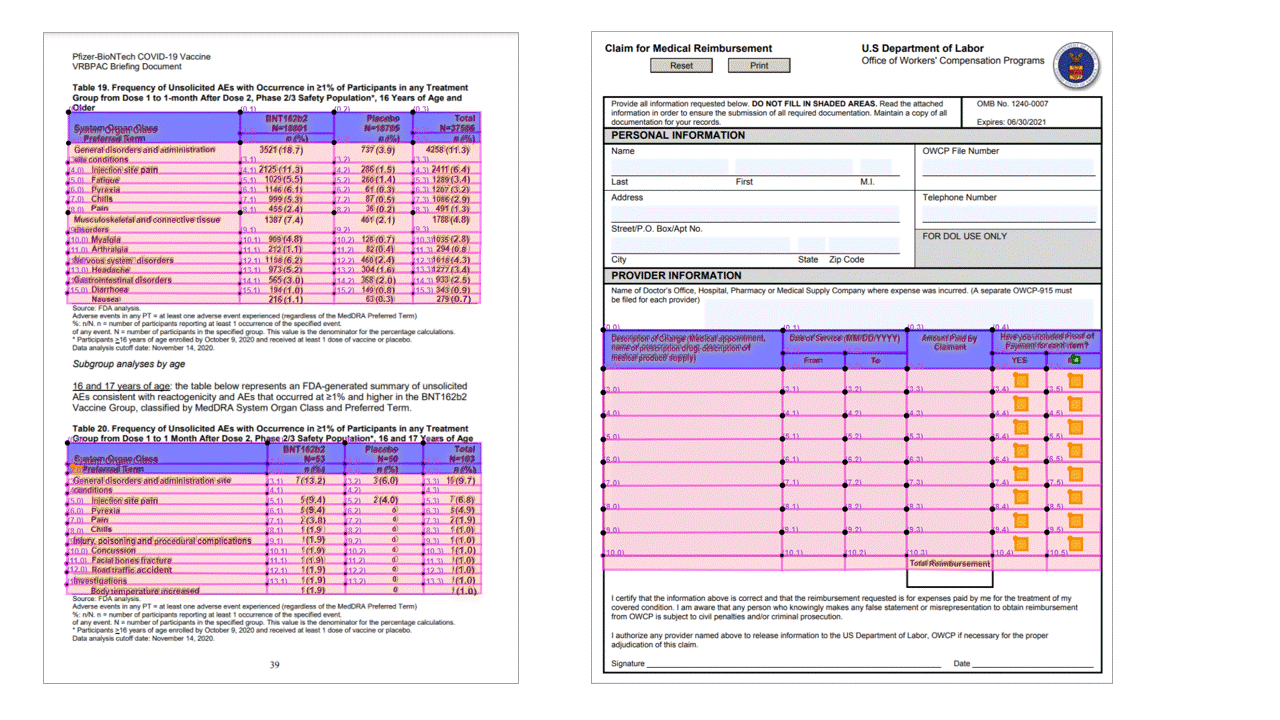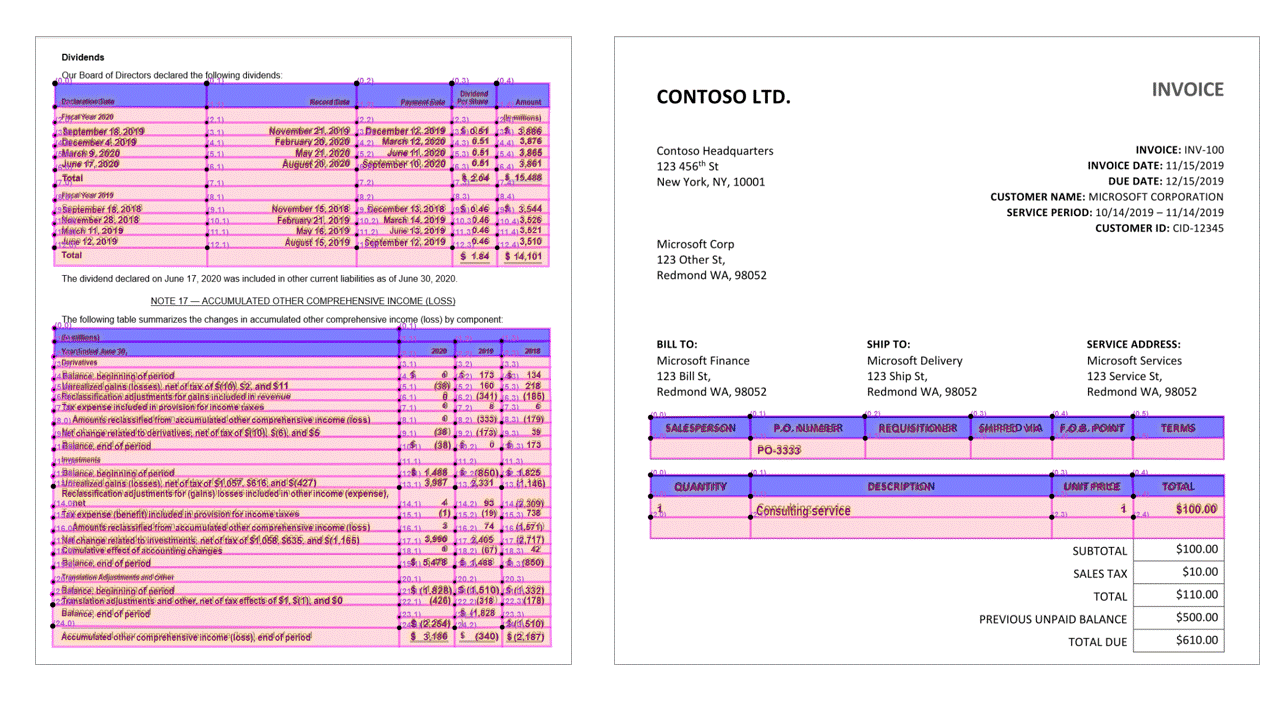
Marcas de seleção (documentos)
A API de Layout também extrai marcas de seleção de documentos. As marcas de seleção extraídas incluem a caixa delimitadora, a confiança e o estado (selecionado/não selecionado). As informações da marca de seleção são extraídas na seção readResults da saída JSON.
Guia de migração
- Siga nosso Guia de migração da Informação de Documentos v3.1 para saber como usar a versão v3.1 em seus aplicativos e fluxos de trabalho.
Próximas etapas
Saiba como processar seus formulários e documentos com o Estúdio da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Saiba como processar seus próprios formulários e documentos com a ferramenta Rotulagem de Amostra da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.