Tradutor Personalizado para iniciantes
O Tradutor Personalizado permite que você crie um sistema de tradução que reflita sua terminologia e seu estilo específicos do domínio, do setor e do seu negócio. O treinamento e a implantação de um sistema personalizado são fáceis e não exigem habilidades de programação. O sistema de tradução personalizado se integra perfeitamente aos seus aplicativos, fluxos de trabalho e sites existentes e está disponível no Azure por meio do mesmo serviço de API de Tradução de Texto da Microsoft baseado em nuvem que fornece bilhões de traduções todos os dias.
A plataforma permite que os usuários criem e publiquem sistemas de tradução personalizados de e para o inglês. O Tradutor Personalizado dá suporte a mais de 60 idiomas que são mapeados diretamente para os idiomas disponíveis na NMT (tradução automática neural). Para obter uma lista completa, consulte Suporte ao idioma do tradutor.
Um modelo de tradução personalizada é a opção certa para mim?
Um modelo de tradução personalizado bem treinado fornece traduções específicas de domínio mais precisas porque se baseia em documentos do domínio traduzidos anteriormente para aprender traduções preferenciais. O Tradutor usa esses termos e essas frases no contexto para produzir traduções fluentes no idioma de destino, respeitando a gramática dependente de contexto.
O treinamento de um modelo de tradução personalizada completo exige um volume substancial de dados. Se você não tiver, pelo menos, dez mil frases de documentos treinados anteriormente, não poderá treinar um modelo de tradução de idioma completo. No entanto, você pode treinar um modelo somente de dicionário ou usar as traduções de alta qualidade prontas para uso disponíveis na API de Tradução de Texto.
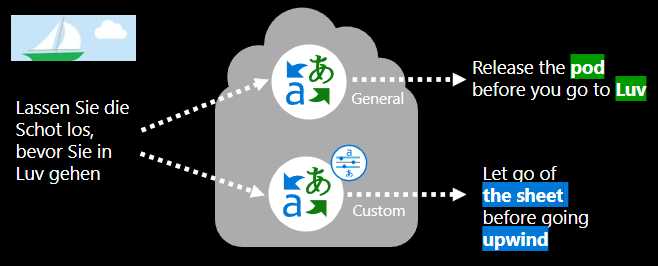
O que envolve o treinamento de um modelo de tradução personalizada?
A criação de um modelo de tradução personalizada exige:
Noções básicas sobre seu caso de uso.
Obtenção de dados traduzidos no domínio (preferencialmente traduzidos por pessoas).
Avaliação da qualidade da tradução ou das traduções de idioma de destino.
Como fazer para avaliar meu caso de uso?
Ter clareza sobre seu caso de uso e a definição do sucesso é a primeira etapa para a obtenção de dados de treinamento proficientes. Veja algumas considerações:
O resultado desejado é especificado e como ele é medido?
Seu domínio de negócios está identificado?
Você tem frases no domínio de terminologia e estilo semelhantes?
Seu caso de uso envolve vários domínios? Nesse caso, você deve criar um sistema de tradução ou vários sistemas?
Você tem requisitos que afetam a residência de dados regionais inativos e em trânsito?
Os usuários de destino estão em uma ou várias regiões?
Como devo obter meus dados?
Em geral, localizar dados de qualidade no domínio é uma tarefa complexa que varia de acordo com a classificação do usuário. Estas são algumas perguntas que você pode se fazer ao avaliar quais dados podem estar disponíveis para você:
Sua empresa tem dados de tradução anteriores disponíveis que você pode usar? As empresas costumam ter um grande volume de dados de tradução acumulado ao longo de vários anos por meio da tradução humana.
Você tem uma amplo volume de dados monolíngues? Dados monolíngues são dados em apenas um idioma. Nesse caso, é possível obter traduções para esses dados?
Você pode rastrear portais online para coletar frases de origem e sintetizar frases de destino?
O que devo usar para o material de treinamento?
| Origem | O que faz | Regras a seguir |
|---|---|---|
| Documentos de treinamento bilíngue | Ensina ao sistema sua terminologia e estilo. | Seja liberal. Qualquer tradução humana no domínio é melhor do que a tradução automática. Adicione e remova documentos conforme o uso e tente melhorar a pontuação BLEU. |
| Ajustar documentos | Treina os parâmetros da Tradução Automática Neural. | Seja estrito. Componha-os para que sejam idealmente representativos do que você vai traduzir no futuro. |
| Documentos de teste | Calcule a pontuação BLEU. | Seja estrito. Redija documentos de teste para serem idealmente representativos do que você planeja traduzir no futuro. |
| Dicionário de frase | Força a tradução especificada 100% do tempo. | Seja restritivo. Um dicionário de frases diferencia maiúsculas de minúsculas e toda palavra ou frase listada é traduzida da forma que você especificar. Em muitos casos, é melhor não usar um dicionário de frases e, em vez disso, permitir que o sistema aprenda o conteúdo. |
| Dicionário de frases | Força a tradução especificada 100% do tempo. | Seja estrito. Um dicionário de frases não diferencia maiúsculas de minúsculas e é bom para frases curtas comuns no domínio. Para que uma correspondência de dicionário de sentença ocorra, toda a sentença enviada deve corresponder à entrada do dicionário de origem. Se apenas uma parte da frase corresponder, a entrada não será igual. |
O que é uma pontuação no BLEU?
O BLEU (Bilingual Evaluation Understudy) é um algoritmo usado para avaliar a precisão do texto que foi traduzido automaticamente de um idioma para outro. O Tradutor Personalizado usa a métrica do BLEU como uma forma de transmitir a precisão da tradução.
Uma pontuação do BLEU é um número entre zero e 100. Uma pontuação igual a zero indica uma tradução de baixa qualidade em que nada na tradução correspondeu à referência. Uma pontuação igual a 100 indica uma tradução perfeita idêntica à referência. Não é necessário obter uma pontuação igual a 100: uma pontuação BLEU entre 40 e 60 indica uma tradução de alta qualidade.
O que acontecerá se eu não enviar dados de ajuste ou de teste?
As frases de ajuste e de teste são idealmente representativas do que você pretende traduzir no futuro. Se você não enviar dados de ajuste ou de teste, o Tradutor Personalizado excluirá automaticamente frases dos seus documentos de treinamento para usá-las como dados de ajuste e de teste.
| Gerada pelo sistema | Seleção manual |
|---|---|
| Conveniente. | Permite o ajuste refinado para suas necessidades futuras. |
| Bom, se você sabe que os dados de treinamento são representativos do que você pretende traduzir. | Fornece mais liberdade para compor os dados de treinamento. |
| Fácil de refazê-los quando você expande ou reduz o domínio. | Permite mais dados e uma melhor cobertura de domínio. |
| É alterado a cada execução de treinamento. | Permanece estático após várias execuções de treinamento repetidas |
Como o material de treinamento é processado pelo Tradutor?
Para se preparar para o treinamento, os documentos passam por uma série de etapas de processamento e filtragem. O conhecimento do processo de filtragem pode ajudar a entender a contagem de frases exibida, bem como as etapas que podem ser seguidas a fim de preparar documentos de treinamento para treinamento com o Tradutor Personalizado. As etapas de filtragem são as seguintes:
Alinhamento de frases
Se o documento não estiver no formato
XLIFF,XLSX,TMXouALIGN, o Tradutor Personalizado alinhará as frases dos documentos de origem e de destino um ao outro, frase por frase. O Tradutor Personalizado não faz o alinhamento de documento: ele segue sua convenção de nomenclatura para os documentos a fim de localizar o documento correspondente no outro idioma. Dentro do texto de origem, o Tradutor Personalizado tenta encontrar a frase correspondente no idioma de destino. Ele usa as marcas do documento como as marcas HTML incorporadas para ajudar com o alinhamento.Se você observa uma discrepância grande entre o número de frases nos documentos de origem e de destino, seu documento de origem pode não ser paralelo ou não pôde ser alinhado. Os pares de documento com uma grande diferença (> 10%) de frases em cada lado justificam uma segunda olhada para garantir que eles sejam, realmente, paralelos.
Extração de dados de ajuste e de teste
O ajuste e o teste de dados são opcionais. Se você não os fornecer, o sistema removerá um percentual apropriado dos documentos de treinamento a ser usado para ajuste e teste. A remoção ocorre dinamicamente como parte do processo de treinamento. Como essa etapa ocorre como parte do treinamento, os documentos que você carregou não são afetados. Você poderá ver as contagens de frases usadas finais para cada categoria de dados (treinamento, ajuste, teste e dicionário) na página Detalhes do modelo após o treinamento ser bem-sucedido.
Filtro de comprimento
- Remove as frases com apenas uma palavra em ambos os lados.
- Remove as frases com mais de 100 palavras em ambos os lados. Chinês, japonês, coreano são isentos.
- Remove as frases com menos de três caracteres. Chinês, japonês, coreano são isentos.
- Remove as frases com mais de dois mil caracteres em chinês, japonês e coreano.
- Remove as frases com menos de 1% de caracteres alfanuméricos.
- Remove as entradas de dicionário que contêm mais de 50 palavras.
Espaço em branco
- Substitui qualquer sequência de caracteres de espaço em branco, incluindo tabulações e sequências de CR/LF, por um só caractere de espaço.
- Remove os espaços à esquerda ou à direita na frase.
Pontuação de final de frase
Substitui vários caracteres de pontuação de final de frase por uma só instância. Normalização de caracteres japoneses.
Converte letras e dígitos de largura inteira em caracteres de meia largura.
Marcas XML sem escape
Transforma as marcas sem escape em marcas com escape:
Marca Torna-se < < > > & & Caracteres inválidos
O tradutor personalizado remove frases que contenham o caractere Unicode U+FFFD. O caractere U+FFFD indica uma falha na conversão de codificação.
Quais etapas devo seguir antes de carregar dados?
- Remova as frases com uma codificação inválida.
- Remova os caracteres de controle Unicode.
- Alinhe as frases (origem para destino), se possível.
- Remova as frases de origem e de destino que não correspondem aos idiomas de origem e de destino.
- Quando as frases de origem e de destino têm idiomas mistos, verifique se as palavras não traduzidas são intencionais, por exemplo, nomes de organizações e produtos.
- Evite ensinar erros ao seu modelo, garantindo que a gramática e a tipografia estejam corretas.
- Mapeie uma frase de origem para uma frase de destino. Embora nosso processo de treinamento processe linhas de origem e de destino que contêm várias frases, o mapeamento um-para-um é uma melhor prática.
Como fazer para avaliar os resultados?
Depois que o modelo for treinado com êxito, você poderá ver a pontuação BLEU do modelo e a pontuação BLEU do modelo de linha de base na página de detalhes do modelo. Usamos o mesmo conjunto de dados de teste para gerar a pontuação de BLEU do modelo e a pontuação de BLEU de linha de base. Esses dados ajudam você a tomar uma decisão informada sobre qual modelo seria melhor para seu caso de uso.