Permita que um aplicativo trate falhas transitórias quando tentar se conectar a um serviço ou recurso de rede ao repetir de forma transparente uma operação com falha. Isso pode melhorar a estabilidade do aplicativo.
Contexto e problema
Um aplicativo que se comunica com os elementos em execução na nuvem precisa ser suscetível às falhas transitórias que podem ocorrer nesse ambiente. As falhas incluem perda momentânea da conectividade de rede com os componentes e serviços, indisponibilidade temporária de um serviço ou tempos limite que surgem quando um serviço está ocupado.
Essas falhas geralmente são autocorretivas e, se a ação que disparou uma falha for repetida após um atraso razoável, é provável que seja bem-sucedida. Por exemplo, um serviço de banco de dados que está processando um grande número de solicitações simultâneas pode implementar uma estratégia de limitação que rejeita temporariamente solicitações adicionais até que sua carga de trabalho diminua. Um aplicativo que tentar acessar o banco de dados pode não conseguir se conectar, mas se ele tentar novamente após um atraso, talvez tenha êxito.
Solução
Na nuvem, são esperadas falhas transitórias, e um aplicativo deve ser criado para lidar com elas com elegância e transparência. Isso minimiza os efeitos que as falhas podem ter sobre as tarefas comerciais que o aplicativo está executando. O padrão de design mais comum a ser adotado é introduzir um mecanismo de repetição.
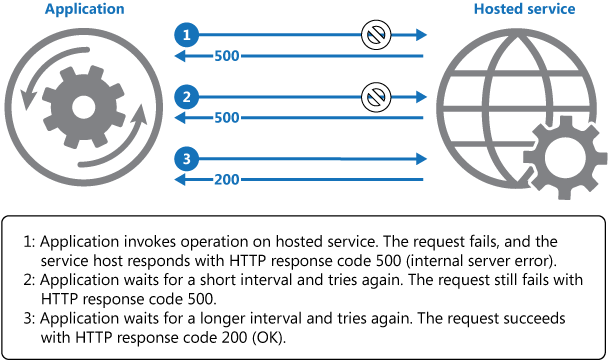
O diagrama acima ilustra a invocação de uma operação em um serviço hospedado usando um mecanismo de repetição. Se a solicitação for mal-sucedida depois de um número predefinido de tentativas, o aplicativo deverá considerar a falha como uma exceção e tratá-la adequadamente.
Observação
Devido à natureza comum de falhas transitórias, os mecanismos de repetição internos agora estão disponíveis em muitas bibliotecas de cliente e serviços de nuvem, com algum grau de capacidade de configuração para o número máximo de tentativas, o atraso entre as tentativas e outros parâmetros. O suporte à repetição interna para muitos serviços do Azure pode ser encontrado aqui e o Microsof Entity Framework fornece recursos para repetir operações de banco de dados com falha.
Estratégias de repetição
Se um aplicativo detectar uma falha ao tentar enviar uma solicitação para um serviço remoto, ele poderá lidar com falhas usando as seguintes estratégias:
Cancelar. Se a falha indica não ser transitória ou provavelmente não será bem-sucedida se for repetida, o aplicativo deve cancelar a operação e relatar uma exceção.
Tente novamente imediatamente. Se a falha específica relatada for incomum ou rara, como um pacote de rede corrompido durante a transmissão, o melhor curso de ação poderá repetir imediatamente a solicitação.
Tentar novamente após atraso. Se a falha for causada por uma ou mais falhas comuns de conectividade ou ocupado, a rede ou o serviço poderão precisar de um breve período enquanto os problemas de conectividade são corrigidos ou a lista de pendências de trabalho é limpa, portanto atrasar de forma programática a nova tentativa é uma boa estratégia. Em muitos casos, deve ser escolhido o período entre as novas tentativas a fim de distribuir solicitações de várias instâncias do aplicativo da maneira mais uniforme possível para reduzir a chance de um serviço ocupado continuar sobrecarregado.
Se a solicitação ainda assim falhar, o aplicativo poderá esperar e fazer outra tentativa. Se necessário, esse processo pode ser repetido com atrasos maiores entre as novas tentativas, até que o número máximo de solicitações ser tentado. O atraso pode ser aumentado de forma incremental ou exponencial, dependendo do tipo de falha e da probabilidade de que ela será corrigida durante esse tempo.
O aplicativo deve encapsular todas as tentativas de acessar um serviço remoto no código que implementa uma política de repetição correspondente a uma das estratégias listadas acima. As solicitações enviadas a serviços diferentes podem estar sujeitas a políticas diferentes.
Um aplicativo deve registrar em log os detalhes das falhas e as falhas de operações. Essas informações são úteis para os operadores. Dito isto, para evitar sobrecarregar os operadores com alertas sobre operações em que as tentativas subsequentes foram bem-sucedidas, é melhor registrar falhas iniciais como entradas informativas e apenas a falha da última tentativa de repetição como um erro real. Aqui está um exemplo de como seria a aparência desse modelo de registro em log.
Se um serviço fica indisponível ou ocupado com frequência, isso normalmente ocorre porque ele esgotou seus recursos. Você pode reduzir a frequência dessas falhas expandindo o serviço. Por exemplo, se um serviço de banco de dados fica continuamente sobrecarregado, pode ser benéfico particionar o banco de dados e distribuir a carga entre vários servidores.
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar esse padrão.
Impacto sobre o desempenho
A política de repetição deve ser ajustada para atender aos requisitos de negócios do aplicativo e a natureza da falha. Para algumas operações não críticas, é melhor falhar rapidamente do que repetir várias vezes e afetar a taxa de transferência do aplicativo. Por exemplo, em um aplicativo Web interativo que acessa um serviço remoto, é melhor falhar após um número menor de novas tentativas com um pequeno atraso entre elas e exibir uma mensagem apropriada para o usuário (por exemplo, “tente novamente mais tarde”). Para um aplicativo de lote, pode ser mais apropriado aumentar o número de tentativas de repetição com um atraso exponencialmente maior entre as tentativas.
Uma política de repetição agressiva com atraso mínimo entre as tentativas e um grande número de repetições poderia prejudicar ainda mais um serviço ocupado executado no limite da capacidade ou próximo desse limite. Essa política de repetição também poderá afetar a capacidade de resposta do aplicativo se ele tentar continuamente executar uma operação com falha.
Se uma solicitação ainda falhar após um número significativo de tentativas, é melhor para o aplicativo evitar que outras solicitações sejam enviadas para o mesmo recurso e simplesmente relatar uma falha imediatamente. Quando o período expirar, o aplicativo pode tentar permitir uma ou mais solicitações para ver se elas são bem-sucedidas. Para obter mais detalhes sobre essa estratégia, consulte o Padrão de disjuntor.
Idempotência
Considere se a operação é idempotente. Nesse caso, tentar novamente é inerentemente seguro. Caso contrário, as repetições podem fazer com que a operação seja executada mais de uma vez, com efeitos colaterais imprevistos. Por exemplo, um serviço pode receber a solicitação, processá-la com êxito, mas falha ao enviar uma resposta. Nesse ponto, a lógica de repetição pode reenviar a solicitação, supondo que a primeira solicitação não foi recebida.
Tipo de exceção
Uma solicitação para um serviço pode falhar por várias razões e gerar exceções diferentes dependendo da natureza da falha. Algumas exceções indicam uma falha que pode ser resolvida rapidamente, enquanto outras indicam que a falha é mais duradoura. É útil para a política de repetição ajustar o tempo entre as tentativas de repetição com base no tipo de exceção.
Consistência de transação
Considere como repetir uma operação que faz parte de uma transação afeta a consistência geral da transação. Ajuste a política de repetição para operações transacionais a fim de maximizar a chance de sucesso e reduzir a necessidade de desfazer todas as etapas da transação.
Orientação geral
Verifique se todo o código de repetição foi totalmente testado para uma variedade de condições de falha. Verifique se ele não afeta gravemente o desempenho ou a confiabilidade do aplicativo, causando excesso de carga em serviços e recursos ou gerando condições de corrida ou gargalos.
Implemente a lógica de repetição somente onde o contexto completo de uma operação com falha for compreendido. Por exemplo, se uma tarefa que contém uma política de repetição invocar outra tarefa que também contém uma política de repetição, essa camada extra de repetições pode adicionar atrasos longos para o processamento. Talvez seja melhor configurar a tarefa de nível inferior para falhar rapidamente e relatar o motivo da falha para a tarefa que a invocou. Esta tarefa de nível mais alto pode então tratar a falha com base em sua própria política.
Registre todas as falhas de conectividade que causam uma tentativa para que os problemas subjacentes com o aplicativo, serviços ou recursos que possam ser identificados.
Investigue as falhas que têm mais probabilidade de ocorrer para um serviço ou um recurso para descobrir se elas provavelmente serão de longa duração ou terminal. Se elas forem, é melhor tratar a falha como uma exceção. O aplicativo pode relatar ou registrar a exceção e, em seguida, tentar continuar com a invocação de um serviço alternativo (se houver) ou oferecer funcionalidade degradada. Para obter mais informações sobre como detectar e tratar falhas de longa duração, consulte o Padrão de disjuntor.
Quando usar esse padrão
Use esse padrão quando um aplicativo poderia apresentar falhas transitórias ao interagir com um serviço remoto ou acessar um recurso remoto. Espera-se que tais falhas sejam breves e repetir uma solicitação que falhou anteriormente pode ter êxito em uma tentativa subsequente.
Esse padrão pode não ser útil:
- Quando uma falha provavelmente é de longa duração, pois isso pode afetar a capacidade de resposta de um aplicativo. O aplicativo pode estar desperdiçando tempo e recursos tentando repetir uma solicitação que provavelmente falhará.
- Para tratar falhas não causadas por falhas transitórias, como exceções internas causadas por erros de lógica de negócios de um aplicativo.
- Como uma alternativa para tratar problemas de escalabilidade em um sistema. Se um aplicativo apresentar falhas frequentes de ocupado, isso geralmente é um sinal de que o serviço ou recurso que está sendo acessado deve ser escalado verticalmente.
Design de carga de trabalho
Um arquiteto deve avaliar como o padrão Repetir pode ser usado no design das suas cargas de trabalho para abordar os objetivos e os princípios discutidos nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão apoia os objetivos do pilar |
|---|---|
| As decisões de design de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | A mitigação de falhas transitórias em um sistema distribuído é uma técnica essencial para melhorar a resiliência de uma carga de trabalho. - RE:07 Autopreservação - RE:07 Falhas transitórias |
Tal como acontece com qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com este padrão.
Exemplo
Consulte o guia para Implementar uma política de repetição com .NET para obter um exemplo detalhado usando o SDK do Azure com suporte interno ao mecanismo de repetição.
Próximas etapas
Antes de criar uma lógica de repetição personalizada, considere usar uma estrutura geral, como Polly para .NET ou Resilience4j para Java.
Ao processar comandos que alteram dados de negócios, lembre-se de que as tentativas podem resultar na execução da ação duas vezes, o que pode ser problemático se essa ação for algo como cobrar o cartão de crédito de um cliente. Usar o padrão Idempotente descrito nesta postagem do blog pode ajudar a lidar com essas situações.
Recursos relacionados
O padrão de aplicativo Web confiável mostra como aplicar o padrão de tentativa a aplicativos Web convergindo para a nuvem.
Para a maioria dos serviços do Azure, os SDKs do cliente incluem lógica de repetição interna. Para saber mais, veja Diretrizes de repetição para serviços do Azure.
Padrão de disjuntor. Se espera-se que uma falha seja mais duradoura, pode ser mais apropriado implementar o Padrão de disjuntor. A combinação dos padrões Repetir e Disjuntor fornece uma abordagem abrangente para lidar com falhas.