Este artigo descreve uma carga de trabalho de Internet das Coisas (IoT) que depende de vários recursos do serviço de banco de dados do Azure Cosmos DB. O Azure Cosmos DB é um banco de dados multimodelo criado para distribuição global e escala horizontal.
A distribuição global dimensiona e replica dados de forma transparente entre as regiões do Azure. Você pode dimensionar a taxa de transferência e o armazenamento em todo o mundo e pagar apenas pela quantia necessária. O dimensionamento elástico instantâneo acomoda cargas de trabalho de IoT diversas e imprevisíveis, sem sacrificar a ingestão ou o desempenho da consulta.
O Azure Cosmos DB é ideal para cargas de trabalho de IoT porque é capaz de:
- Ingerir dados de telemetria de dispositivos a altas taxas e retornar consultas indexadas com baixa latência e alta disponibilidade.
- Armazenamento do formato JSON de diferentes fornecedores de dispositivos, o que fornece flexibilidade no esquema de carga útil.
- Usando endpoints de API compatíveis com protocolo wire para Cassandra, MongoDB, SQL, Gremlin, etcd e bancos de dados de tabela, e suporte integrado para arquivos Jupyter Notebook.
Possíveis casos de uso
- Use recursos internos do Azure Cosmos DB distribuídos globalmente para habilitar leitura-gravação de baixa latência para aplicativos IoT altamente responsivos.
- Manipule dados de uma ampla variedade de fornecedores de dispositivos e tipos de dados.
Arquitetura
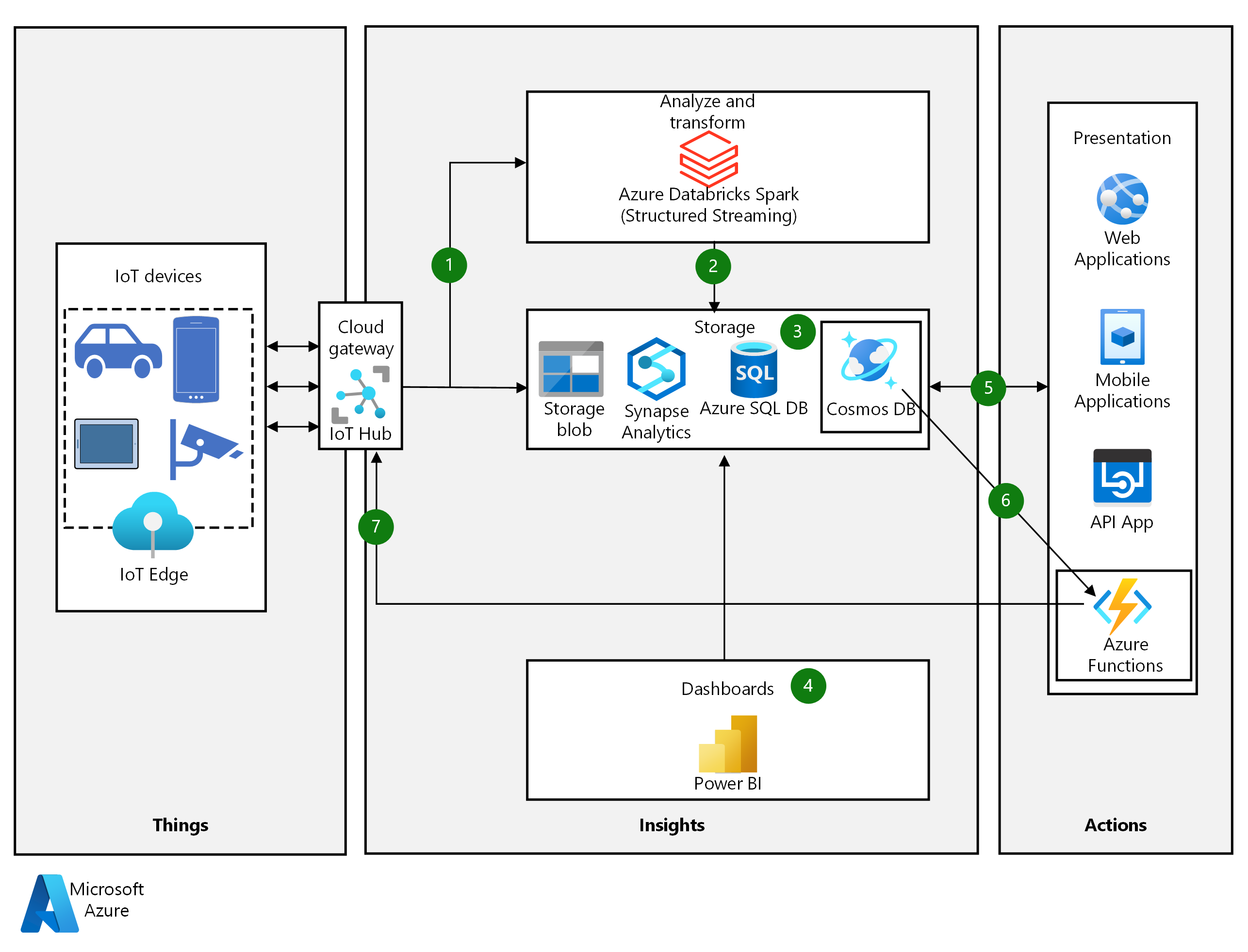 Baixe um Arquivo Visio dessa arquitetura.
Baixe um Arquivo Visio dessa arquitetura.
Fluxo de dados
Os sensores IoT e os dispositivos Edge enviam eventos como fluxos de mensagens por meio do Hub IoT do Azure para a camada de análise e transformação. O Hub IoT pode armazenar fluxos de dados em partições por uma duração especificada.
O Azure Databricks com Apache Spark Structured Streaming coleta mensagens do Hub IoT em tempo real, processa os dados com base na lógica de negócios e envia os dados para o armazenamento. O Streaming estruturado pode fornecer análises em tempo real, como calcular médias móveis ou valores mínimos e máximos ao longo de períodos de tempo.
O Azure Cosmos DB armazena mensagens de dispositivo como documentos JSON no armazenamento de dados ativo. O Azure Cosmos DB pode validar esquemas JSON de diferentes fornecedores de dispositivos.
A camada de armazenamento também consiste em:
- Armazenamento de Blobs do Azure. O roteamento de mensagens do Hub IoT salva mensagens brutas do dispositivo no armazenamento de Blobs, fornecendo um armazenamento de dados frio barato e de longo prazo.
- Banco de Dados SQL do Azure, para armazenar dados transacionais e relacionais, como dados de cobrança e funções de usuário.
- Armazém de dados do Azure Synapse Analytics, preenchido pelo Azure Data Factory, que agrega dados do Azure Cosmos DB e do Azure SQL DB.
O Microsoft Power BI analisa o data warehouse.
A camada de apresentação usa dados da camada de armazenamento para criar aplicativos Web, móveis e de API.
Sempre que uma mensagem de dispositivo nova ou atualizada chega, o feed de alterações do Azure Cosmos DB aciona uma função do Azure Functions.
A função determina se a mensagem requer uma ação do dispositivo, como uma reinicialização. Nesse caso, a função se conecta ao Hub IoT usando a API do Serviço de Hub IoT e inicia a ação do dispositivo. A função pode iniciar a ação usando gêmeos de dispositivo, mensagens de nuvem para dispositivo ou métodos diretos.
Componentes
Essa carga de trabalho utiliza os seguintes componentes do Azure:
Azure Cosmos DB
Essa carga de trabalho de IoT destaca o Azure Cosmos DB, um banco de dados multimodelo distribuído globalmente. A carga de trabalho usa os seguintes recursos do Azure Cosmos DB:
Níveis de consistência. O Azure Cosmos DB oferece suporte a cinco níveis de consistência de leitura, do mais forte ao mais fraco: forte, desatualização limitada, sessão, prefixo consistente e eventual. Em geral, uma consistência mais forte leva a menor disponibilidade, maior latência e menor taxa de transferência. Você pode escolher um nível de consistência com base em seus requisitos de carga de trabalho.
Vida útil (TTL). O Azure Cosmos DB pode excluir itens automaticamente de um contêiner após um período de tempo determinado. Esse recurso permite que o Azure Cosmos DB atue como um armazenamento de dados de acesso frequente para dados recentes, com dados de longo prazo armazenados no armazenamento frio de Blobs do Azure.
Feed de alterações. O recurso de feed de alterações gera uma lista classificada de documentos alterados, na ordem em que foram modificados. Cada novo evento no feed de alterações do contêiner do Azure Cosmos DB aciona automaticamente uma pequena função reativa do Azure Functions. Dependendo do conteúdo do documento JSON, a função pode se conectar à API do Serviço de Hub IoT do Azure e executar uma ação no dispositivo.
Unidades de solicitação (RUs) RUs são unidades de computação que medem a taxa de transferência do Azure Cosmos DB. Você pode usar RUs para escalar dinamicamente o Azure Cosmos DB para cima e para baixo, mantendo a disponibilidade e otimizando o custo e o desempenho.
Particionamento. A chave de partição determina como o Azure Cosmos DB roteia dados em partições. A ID do dispositivo IoT é a chave de partição usual para aplicativos IoT.
Outros componentes do Azure
A solução também usa os seguintes componentes do Azure:
O Azure IoT Edge executa aplicativos na borda, como modelos de machine learning.
O Hub IoT do Azure atua como o gateway de nuvem, ingerindo telemetria de dispositivo em escala. O Hub IoT oferece suporte à comunicação de volta aos dispositivos, permitindo que as ações sejam enviadas da nuvem para o IoT Edge para o dispositivo.
O Azure Databricks com Spark Structured Streaming é um sistema de processamento de fluxo escalonável e tolerante a falhas que oferece suporte nativo a cargas de trabalho em lote e streaming. O Azure Databricks é a camada de transformação e análise e se conecta ao ponto de extremidade compatível com o hub de eventos do Hub IoT usando a biblioteca azure-eventhubs-spark_2.11:2.3.6 Maven.
O Armazenamento de Blobs do Azure fornece armazenamento de dados frios escalonável, barato e de longo prazo para dados não estruturados.
O Banco de Dados SQL do Azure é o banco de dados relacional para dados transacionais e outros dados que não sejam da IoT.
O Azure Synapse Analytics é um data warehouse e uma plataforma de relatórios para armazenamento de dados corporativos e análise de big data. O Synapse Analytics contém dados agregados do Banco de Dados SQL do Azure e do Azure Cosmos DB.
O Azure Synapse Link para Azure Cosmos DB permite análises quase em tempo real em dados operacionais do Azure Cosmos DB, sem qualquer impacto de desempenho ou custo nas cargas de trabalho transacionais. O Synapse Link usa os dois mecanismos de análise no espaço de trabalho do Azure Synapse: SQL Serverless e Spark Pools.
Power BI é um conjunto de ferramentas de análise de negócios para analisar dados e compartilhar informações. O Power BI pode consultar um modelo semântico armazenado no Azure Analysis Services ou pode consultar diretamente o Synapse Analytics.
O Serviço de Aplicativo do Azure cria aplicativos Web e móveis. O Aplicativo de API do Azure permite que aplicativos de terceiros consumam APIs com base nos dados da camada de serviço.
O Azure Functions é uma plataforma de computação sem servidor orientada a eventos que pode operar em escala na nuvem e integrar serviços usando gatilhos e associações. O Azure Functions pode traduzir formatos de mensagem IoT ou acionar ações quando conectado ao feed de alterações do Azure Cosmos DB.
Alternativas
Em vez do Azure Databricks, a camada de transformação e análise poderia usar o HDInsight Storm, o HDInsight Spark ou o Azure Stream Analytics para fazer análises de streaming e usar o Azure Functions para transformar as cargas de mensagens.
A camada de armazenamento de serviço pode usar o Azure Data Explorer para armazenar mensagens de IoT. Esse serviço também tem recursos avançados de análise.
Considerações
O Azure Cosmos DB tem um limite de 20 GB para uma única partição lógica. Para a maioria das soluções de IoT, esse tamanho é suficiente. Caso contrário, você pode:
Defina a chave de partição como um campo artificial e atribua ao campo um valor composto, como ID do dispositivo + Mês e ano atuais. Essa estratégia garante cardinalidade de alto valor para um bom design de partição. Para obter mais informações, consulte Escolher uma chave de partição.
Com base no ciclo de vida dos dados, você pode mover dados mais antigos do Azure Cosmos DB para o armazenamento frio, como o Armazenamento de Blobs do Azure. Você pode usar uma combinação de feed de alterações para replicar os dados para armazenamento frio e TTL para excluir dados automaticamente de um contêiner após um determinado período de tempo.
Próximas etapas
- Soluções de IoT e Azure Cosmos DB
- Particionamento e escala horizontal no Azure Cosmos DB
- Ordenar eventos de conexão de dispositivo do Hub IoT usando o Azure Cosmos DB