Escalar horizontalmente com o Banco de Dados SQL do Azure
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Você pode escalar horizontalmente com facilidade bancos de dados do Banco de Dados SQL do Azure usando as ferramentas do Banco de Dados Elástico. Essas ferramentas e recursos permitem que você use os recursos de banco de dados do Banco de Dados SQL do Azure para criar soluções para cargas de trabalho transacionais e, especialmente, aplicativos SaaS (software como serviço). Os recursos do Banco de Dados Elástico são compostos pelo seguinte:
- Biblioteca de cliente do Banco de Dados Elástico: a biblioteca de cliente é um recurso que permite criar e manter bancos de dados fragmentados. Consulte Introdução às ferramentas do Banco de Dados Elástico.
- Mover dados entre bancos de dados em nuvem escalonados: move dados entre bancos de dados fragmentados. Essa ferramenta é útil para mover dados de um banco de dados multilocatário para um banco de dados de locatário único (ou vice-versa). Consulte Implantar um serviço de mesclagem dividida para mover dados entre bancos de dados compartilhados.
- Trabalhos elásticos no Banco de Dados SQL do Azure: use trabalhos para gerenciar um grande número de bancos de dados no Banco de Dados SQL do Azure. Execute operações administrativas facilmente, como alterações de esquema, gerenciamento de credenciais, atualizações de dados de referência, desempenho de coleta de dados ou coleção de telemetria do locatário (cliente), usando trabalhos.
- Visão geral da consulta elástica do Banco de Dados SQL do Azure (preview) (preview): Permite que você execute uma consulta Transact-SQL que abranja vários bancos de dados. Isso permite a conexão com ferramentas de relatório, como Excel, Power BI, Tableau, etc.
- Transações distribuídas em bancos de dados na nuvem: Esse recurso permite que você execute transações que abrangem vários bancos de dados. As transações de banco de dados elástico estão disponíveis para aplicativos .NET usando ADO .NET e se integram à experiência de programação conhecida usando as classes System.Transaction.
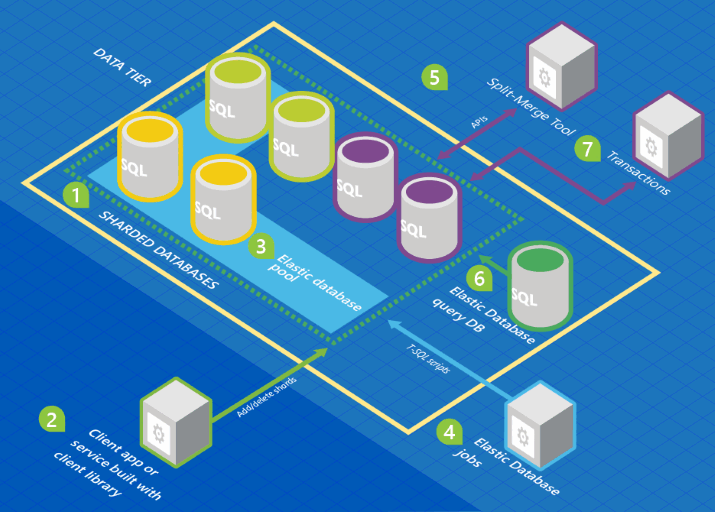
O gráfico a seguir mostra uma arquitetura que inclui os recursos do Banco de Dados Elástico em relação a uma coleção de bancos de dados.
Neste gráfico, as cores do banco de dados representam esquemas. Bancos de dados com a mesma cor compartilham o mesmo esquema.
- Um conjunto de Bancos de Dados SQL é hospedado no Azure usando a arquitetura de fragmentação.
- A biblioteca de clientes do Banco de Dados Elástico é usada para gerenciar um conjunto de fragmentos.
- Um subconjunto dos bancos de dados é colocado em um pool elástico.
- Um Trabalho do Elastic Database executa scripts T-SQL em todos os bancos de dados.
- A ferramenta de divisão e mesclagem é usada para mover dados de um fragmento para outro.
- A consulta ao Banco de Dados Elástico permite gravar uma consulta que se estenda por todos os bancos de dados no conjunto de fragmentos.
- Transações elásticas permitem a execução de transações que abrangem vários bancos de dados.
Por que usar as ferramentas?
Obter elasticidade e escala para aplicativos em nuvem é fácil para o armazenamento de blobs e VMs – basta adicionar ou subtrair unidades ou aumentar a potência. Mas continuou sendo um desafio para processamento de dados com estado em bancos de dados relacionais. Desafios surgiram nesses cenários:
- Aumentando e diminuindo a capacidade para a parte do banco de dados relacional da carga de trabalho.
- Gerenciar hotspots que podem surgir afetando um subconjunto específico de dados, como cliente final movimentado (locatário).
Tradicionalmente, cenários como esses foram resolvidos com o investimento em servidores de grande escala para dar suporte ao aplicativo. No entanto, essa opção é limitada a nuvem em que todo o processamento ocorre em hardware de mercadoria predefinidos. Em vez disso, distribuir dados e processar entre vários bancos de dados estruturados de forma idêntica (um padrão de escala vertical conhecido como “fragmentação”) oferece uma alternativa às abordagens tradicionais de escala vertical tanto em termos de custo quanto de elasticidade.
Dimensionamento horizontal e vertical
A figura a seguir mostra as dimensões horizontal e vertical da colocação em escala, que são as maneiras básicas de dimensionar os bancos de dados elásticos.

O dimensionamento horizontal refere-se à adição ou remoção de bancos de dados para ajustar a capacidade ou o desempenho geral, também chamado de "expansão". A fragmentação, na qual os dados são particionados em uma coleção de bancos de dados estruturados de forma idêntica, é uma maneira comum de implementar o dimensionamento horizontal.
O dimensionamento vertical refere-se ao aumento ou à diminuição do tamanho da computação de um banco de dados individual. Isso também é conhecido como “escalar ou reduzir verticalmente”.
A maioria dos aplicativos de banco de dados de escala de nuvem usa uma combinação dessas duas estratégias. Por exemplo, um aplicativo de Software como um Serviço pode usar o dimensionamento horizontal para provisionar novos clientes finais e o dimensionamento vertical para permitir que o banco de dados de cada cliente final aumente ou reduza em recursos conforme necessário para a carga de trabalho.
- A escala horizontal é gerenciada com a biblioteca de cliente do Banco de Dados Elástico.
- A escala vertical é realizada usando cmdlets do Azure PowerShell para alterar a camada de serviço ou colocando os bancos de dados em um pool elástico.
Fragmentação
A fragmentação é uma técnica usada para distribuir grandes volumes de dados estruturados de maneira idêntica entre vários bancos de dados independentes. É especialmente popular com desenvolvedores de nuvem que estão criando ofertas de SaaS (software como serviço) para clientes finais ou empresas. Esses clientes finais são frequentemente chamados de "locatários". A fragmentação pode ser necessária por vários motivos:
- A quantidade total de dados é muito grande para caber dentro das restrições de um banco de dados individual
- A taxa de transferência de transação da carga de trabalho geral excede as capacidades de um banco de dados individual
- Inquilinos podem exigir isolamento físico entre si, para que bancos de dados separados são necessários para cada locatário
- Seções diferentes de um banco de dados talvez precisem residir em regiões diferentes para questões geopolíticas, de desempenho ou de conformidade.
Em outros cenários, como inclusão de dados de dispositivos distribuídos, a fragmentação pode ser usada para preencher um conjunto de bancos de dados que são organizados temporariamente. Por exemplo, um banco de dados pode ser dedicado a cada dia ou semana. Nesse caso, a chave de fragmentação pode ser um número inteiro que representa a data (presente em todas as linhas das tabelas fragmentadas) e as consultas que recuperam informações para um intervalo de datas devem ser roteadas pelo aplicativo para o subconjunto de bancos de dados que abrangem o intervalo em questão.
A fragmentação funciona melhor quando todas as transações em um aplicativo podem ser restrita a um único valor de uma chave de fragmentação. Isso garante que todas as transações são locais para um banco de dados específico.
Multilocatário e locatário único
Alguns aplicativos usam a abordagem mais simples de criar um banco de dados separado para cada locatário. Essa abordagem é o padrão de fragmentação de locatário único que fornece isolamento, capacidade de backup/restauração e dimensionamento de recursos na granularidade do locatário. Com o sharding de locatário único, cada banco de dados é associado a um valor específico de ID de locatário (ou valor de chave de cliente), mas essa chave não precisa estar presente nos próprios dados. É responsabilidade do aplicativo rotear cada solicitação para o banco de dados apropriado, e a biblioteca de cliente pode simplificar essa tarefa.

Outros cenários de vários locatários pack juntos em bancos de dados, em vez de isolá-los em bancos de dados separados. Esse padrão é um padrão de fragmentação multilocatário típico, que pode ser orientado pelo fato de que um aplicativo gerencia um grande número de locatários pequenos. Na fragmentação multilocatária, as linhas nas tabelas de banco de dados foram projetadas para executar uma chave que identifica a ID do locatário ou a chave de fragmentação. Novamente, a camada de aplicativo é responsável por rotear a solicitação de um locatário no banco de dados apropriado, e isso pode ter suporte na biblioteca de cliente do banco de dados elástico. Além disso, a segurança no nível de linha pode ser usada para filtrar quais linhas cada locatário pode acessar. Para obter detalhes, confira Aplicativos multilocatários com ferramentas de banco de dados elástico e segurança em nível de linha. Redistribuir dados entre bancos de dados pode ser necessário com o padrão de fragmentação de multilocatário, e isso é facilitado pela ferramenta de divisão/mesclagem de banco de dados elástico. Para saber mais sobre padrões de design para aplicativos SaaS usando pools elásticos, consulte Padrões de locação de banco de dados SaaS multilocatário.
Mover dados de bancos de dados de vários locatários para de um locatário
Ao criar um aplicativo SaaS, é comum para oferecer aos clientes em potencial uma versão de avaliação do software. Nesse caso, é econômico usar um banco de dados multilocatário para os dados. No entanto, quando um cliente em potencial se torna um cliente, um banco de dados de um único locatário é melhor, já que fornece maior desempenho. Se o cliente criar dados durante o período de avaliação, use a ferramenta de divisão/mesclagem para mover os dados do banco de dados multilocatário para o novo banco de dados de um único locatário.
Observação
A restauração de bancos de dados multilocatários para um único locatário não é possível.
Exemplos e tutoriais
Para ver um aplicativo de exemplo que demonstra a biblioteca de cliente, confira Introdução às ferramentas do Banco de Dados Elástico.
Para converter os bancos de dados existentes para usar as ferramentas, consulte Migrar bancos de dados existentes para escala horizontal.
Para ver os detalhes do pool elástico, confira Considerações de preço e desempenho para um pool elástico ou crie um novo pool com os pools elásticos.
Conteúdo relacionado
Ainda não está usando ferramentas de banco de dados elástico? Confira nosso Guia de Introdução. Em caso de dúvidas, entre em contato conosco na página de perguntas do Microsoft Q&A para Banco de Dados SQL e, para solicitações de recursos, adicione novas ideias ou vote em ideias existentes no Fórum de comentários sobre o Banco de Dados SQL.