Gerenciar o espaço de arquivo para bancos de dados no Banco de Dados SQL do Azure
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Este artigo descreve os diferentes tipos de espaço de armazenamento para bancos de dados no Banco de Dados SQL do Azure e as etapas que podem ser executadas quando o espaço no arquivo alocado precisa ser gerenciado explicitamente.
Visão geral
Com o Banco de Dados SQL do Azure, há padrões de carga de trabalho nos quais a alocação de arquivos de dados subjacentes para bancos de dados pode se tornar maior do que o número de páginas de dados usadas. Essa condição pode ocorrer quando o espaço usado aumenta e os dados são excluídos posteriormente. O motivo é porque o espaço no arquivo alocado não é recuperado automaticamente quando os dados são excluídos.
O monitoramento do uso do espaço no arquivo e a redução dos arquivos de dados podem ser necessários nos seguintes cenários:
- Permitir o crescimento de dados em um pool elástico quando o espaço no arquivo alocado para seus bancos de dados atingir o tamanho máximo do pool.
- Permitir diminuir o tamanho máximo de um único banco de dados ou conjunto elástico.
- Permitir a alteração de um único banco de dados ou conjunto elástico para uma camada de serviço ou camada de desempenho diferente com um tamanho máximo menor.
Observação
As operações de redução não devem ser consideradas uma operação de manutenção regular. Arquivos de dados e de log que crescem devido a operações de negócios regulares e recorrentes não exigem operações de redução.
Monitorar o uso do espaço de arquivo
A maioria das métricas de espaço de armazenamento exibido nas seguintes APIs apenas medir o tamanho das páginas de dados usados:
- APIs de métricas baseadas no Azure Resource Manager, incluindo get-metrics do PowerShell
No entanto, as seguintes APIs também medem o tamanho do espaço alocado para os bancos de dados Elástico e de pools:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
Reconhecer os tipos de espaço de armazenamento para um banco de dados
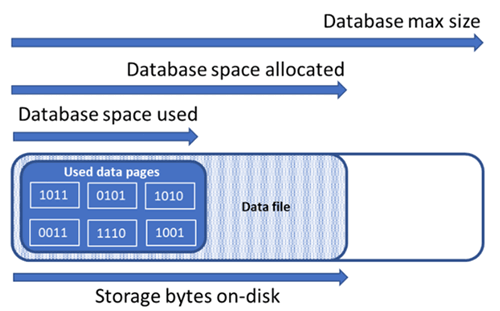
Noções básicas sobre as quantidades de espaço de armazenamento a seguir são importantes para gerenciar o espaço de arquivo de banco de dados.
| Quantidade de banco de dados | Definição | Comentários |
|---|---|---|
| Espaço de dados usado | A quantidade de espaço usada para armazenar dados do banco de dados. | Geralmente, esse espaço utilizado aumenta (diminui) em inserções (exclusões). Em alguns casos, o espaço utilizado não é alterado em inserções ou exclusões, dependendo da quantidade e do padrão de dados envolvidos na operação e de qualquer fragmentação. Por exemplo, excluir uma linha de cada página de dados não diminui necessariamente o espaço usado. |
| Espaço alocado de dados | A quantidade de espaço no arquivo formatado disponibilizada para armazenar dados do banco de dados. | O quantidade de espaço alocado cresce automaticamente, mas nunca diminui após as exclusões. Esse comportamento garante que as futuras inserções sejam mais rápidas, já que o espaço não precisa ser reformatado. |
| Espaço de dados alocados, mas não utilizado | A diferença entre a quantidade de espaço de dados alocado e espaço de dados usado. | Essa quantidade representa a quantidade máxima de espaço livre que pode ser recuperado pela redução de arquivos de dados do banco de dados. |
| Tamanho máximo dos dados | A quantidade máxima de espaço para dados que pode ser usada para armazenar dados do banco de dados. | A quantidade do espaço de dados alocados não pode crescer além do tamanho máximo de dados. |
O diagrama a seguir ilustra o relacionamento entre os tipos de espaço diferentes de espaço de armazenamento para um banco de dados.
Consultar um banco de dados individual para informações de espaço de arquivo
Use a consulta a seguir em sys.database_files para devolver o valor de espaço de arquivo de banco de dados alocado e o valor de espaço não utilizado alocado. Unidades do resultado da consulta são em MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Compreender os tipos de espaço de armazenamento para um pool elástico
Noções básicas sobre as quantidades de espaço de armazenamento a seguir são importantes para gerenciar o espaço de arquivo de banco de dados.
| Quantidade de pool elástico | Definição | Comentários |
|---|---|---|
| Espaço de dados usado | O resumo de espaço de dados usado por todos os bancos de dados no pool elástico. | |
| Espaço alocado de dados | O resumo de espaço de dados alocado por todos os bancos de dados no pool elástico. | |
| Espaço de dados alocados, mas não utilizado | A diferença entre a quantidade de espaço de dados alocado e espaço de dados usado por todos os banco de dados no pool elástico. | Essa quantidade representa a quantidade máxima de espaço alocado para o pool elástico que pode ser recuperado pela redução de arquivo de dados do banco de dados. |
| Tamanho máximo dos dados | A quantidade máxima de espaço para dados que pode ser usada pelo pool elástico de todos esses bancos de dados. | O espaço alocado não deve exceder o tamanho máximo do pool elástico. Se essa condição ocorrer, o espaço alocado que não for utilizado poderá ser recuperado, encolhendo os arquivos de dados do banco de dados. |
Observação
A mensagem de erro "O pool elástico atingiu o limite de armazenamento" indica que os objetos de banco de dados receberam espaço suficiente para atender ao limite de armazenamento do pool elástico, mas pode haver espaço não utilizado na alocação do espaço de dados. Considere aumentar o limite de armazenamento do pool elástico ou, como solução de curto prazo, liberar espaço para dados usando os exemplos em Recuperar espaço alocado não usado. Você também deve estar ciente do potencial impacto negativo no desempenho da redução de arquivos de banco de dados. Consulte Manutenção de índice após redução.
Consultar um pool elástico para informações de espaço de armazenamento
As consultas a seguir podem ser usadas para determinar as quantidades de espaço de armazenamento para um pool elástico.
Espaço de dados do pool elástico usado
Modifique a consulta a seguir para retornar a quantidade de espaço para dados do conjunto elástico usado. Unidades do resultado da consulta são em MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Espaço de dados de pool elástico alocado e espaço alocado não usado
Modifique os exemplos a seguir para retornar uma tabela listando o espaço total alocado e o espaço não utilizado alocado para cada banco de dados em um pool elástico. A tabela ordena bancos de dados desses bancos de dados com a maior quantidade de espaço alocado não utilizado para a menor quantidade de espaço alocado não utilizado. Unidades do resultado da consulta são em MB.
Os resultados da consulta para determinar o espaço alocado para cada banco de dados no pool podem ser incluídos juntos para determinar o espaço do pool elástico alocado. O espaço do pool elástico alocado não deve exceder o tamanho máximo do pool elástico.
Importante
O módulo Azure Resource Manager do PowerShell ainda tem suporte do Banco de Dados SQL do Azure, mas todo o desenvolvimento futuro é para o módulo Az.Sql. O módulo AzureRM continuará a receber as correções de bugs até pelo menos dezembro de 2020. Os argumentos para os comandos no módulo Az e nos módulos AzureRm são substancialmente idênticos. Para saber mais sobre a compatibilidade entre eles, confira Apresentação do novo módulo Az do Azure PowerShell.
O script do PowerShell requer o módulo do SQL Server PowerShell - consulte Download do módulo do PowerShell para instalar.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
A captura de tela a seguir é um exemplo da saída do script:

Tamanho máximo dos dados do pool elástico
Modifique a consulta T-SQL a seguir para retornar o tamanho máximo dos últimos dados registrados do pool elástico. Unidades do resultado da consulta são em MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Recuperar espaço alocado não utilizado
Importante
Comandos de redução afetam o desempenho do banco de dados enquanto ele está em execução e, se possível, deve ser executado durante períodos de baixa utilização.
Reduzir arquivos de dados
Devido a um impacto potencial no desempenho do banco de dados, o Banco de Dados SQL do Azure não reduz automaticamente os arquivos. No entanto, os clientes podem reduzir os arquivos de dados por conta própria quando desejarem. Isso não deve ser uma operação agendada regularmente, mas sim um evento único em resposta a uma grande redução no consumo de espaço usado do arquivo de dados.
Dica
Não é recomendável reduzir os arquivos de dados se a carga de trabalho regular do aplicativo faz com que os arquivos voltem para o mesmo tamanho alocado novamente.
No Banco de Dados SQL do Azure, para reduzir arquivos, você pode usar os comandos DBCC SHRINKDATABASE ou DBCC SHRINKFILE:
DBCC SHRINKDATABASEreduz todos os dados e arquivos de log em um banco de dados usando um só comando. O comando reduz um arquivo de dados por vez, o que pode levar muito tempo para bancos de dados maiores. Ele também reduz o arquivo de log, o que normalmente é desnecessário porque o Banco de Dados SQL do Azure reduz arquivos de log automaticamente conforme necessário.- O comando
DBCC SHRINKFILEdá suporte a cenários mais avançados:- Ele pode direcionar arquivos individuais conforme necessário, em vez de reduzir todos os arquivos no banco de dados.
- Cada comando
DBCC SHRINKFILEpode ser executado em paralelo com outros comandosDBCC SHRINKFILEpara reduzir vários arquivos ao mesmo tempo e diminuir o tempo total da redução, às custas de maior uso de recursos e com maior chance de bloquear consultas de usuário se elas estiverem sendo executadas durante a redução.- A redução de múltiplos arquivos de dados ao mesmo tempo permite concluir a operação de redução mais rapidamente. Se você usar a redução simultânea de arquivos de dados, poderá ocorrer o bloqueio transitório de uma solicitação de redução por outra.
- Se a parte final do arquivo não tiver dados, o tamanho do arquivo alocado poderá ser reduzido muito mais rapidamente através da especificação do argumento
TRUNCATEONLY. Isso não requer a movimentação de dados no arquivo.
- Para obter mais informações sobre esses comandos de redução, confira DBCC SHRINKDATABASE e DBCC SHRINKFILE.
- As operações de redução de banco de dados e arquivos são suportadas na visualização do Banco de Dados SQL do Azure Hyperscale. Para obter mais informações, consulte Redução do Banco de Dados SQL do Azure Hyperscale.
Os exemplos a seguir devem ser executados enquanto conectados ao banco de dados de usuário de destino, não ao banco de dados master.
Para usar DBCC SHRINKDATABASE para reduzir todos os dados e arquivos de log em um determinado banco de dados:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
No Banco de Dados SQL do Azure, um banco de dados pode ter um ou mais arquivos de dados, criados automaticamente à medida que os dados crescem. Para determinar o layout de arquivos do banco de dados, incluindo o tamanho usado e alocado de cada arquivo, consulte o exibição de catálogo sys.database_files usando o seguinte script de exemplo:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Você pode executar uma redução em um arquivo somente por meio do comando DBCC SHRINKFILE, por exemplo:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Esteja ciente do potencial impacto negativo sobre o desempenho causado pela redução de arquivos de banco de dados. Confira Manutenção do índice após a redução.
Reduzir arquivo de log de transações
Ao contrário dos arquivos de dados, o Banco de Dados SQL do Azure reduz automaticamente o arquivo de log de transações para evitar o uso excessivo de espaço que pode causar erros de indisponibilidade de espaço. Normalmente, não é necessário que os clientes reduzam o arquivo de log de transações.
Nas camadas de serviço Premium e Comercialmente Crítico, se o log de transações ficar grande, ele poderá contribuir significativamente para o consumo de armazenamento local até o limite de armazenamento local máximo. Se o consumo de armazenamento local estiver próximo do limite, os clientes poderão optar por reduzir o log de transações usando o comando DBCC SHRINKFILE, conforme mostrado no exemplo a seguir. Isso libera o armazenamento local assim que o comando é concluído, sem esperar a operação de redução automática periódica.
Os exemplos a seguir devem ser executados enquanto conectados ao banco de dados de usuário de destino, não ao banco de dados master.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
A redução automática
Como alternativa à redução manual dos arquivos de dados, a redução automática pode ser habilitada para um banco de dados. No entanto, a redução automática pode ser menos eficaz na recuperação de espaço no arquivo do que DBCC SHRINKDATABASE e DBCC SHRINKFILE.
A redução automática é desabilitada por padrão, o que é recomendado para a maioria dos bancos de dados. Se for necessário ativar a redução automática, é recomendável desativá-la quando as metas de gerenciamento de espaço forem atingidas, em vez de mantê-la ativada permanentemente. Para obter mais informações, confira Considerações sobre AUTO_SHRINK.
Por exemplo, a redução automática pode ser útil no cenário específico em que um pool elástico contém muitos bancos de dados que apresentam crescimento significativo e redução no espaço de arquivo de dados usado, fazendo com que o pool se aproxime do limite de tamanho máximo. Esse não é um cenário comum.
Para habilitar a redução automática, execute o comando a seguir enquanto conectado ao banco de dados (não no banco de dados master).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Para obter mais informações sobre esse comando, consulte banco de dados definido opções.
Manutenção de índice após a redução
Depois que uma operação de redução é concluída nos arquivos de dados, os índices podem ficar fragmentados. Isso reduz a eficácia da otimização de desempenho para determinadas cargas de trabalho, como as consultas que usam verificações grandes. Se a degradação do desempenho ocorrer após a conclusão da operação de redução, considere a manutenção do índice para recompilar índices. Lembre-se de que as recompilações de índice exigem espaço livre no banco de dados e, portanto, podem fazer com que o espaço alocado aumente, neutralizando o efeito da redução.
Para obter mais informações sobre a manutenção de índice, confira Otimizar a manutenção do índice para aprimorar o desempenho da consulta e reduzir o consumo de recursos.
Reduzir bancos de dados grandes
Quando o espaço alocado do banco de dados é de centenas de gigabytes ou mais, a redução pode exigir um tempo significativo para ser concluída, geralmente medido em horas ou dias para bancos de dados com múltiplos terabytes. Há otimizações de processo e melhores práticas que você pode usar para tornar esse processo mais eficiente e menos impactante para as cargas de trabalho do aplicativo.
Capturar a linha de base de uso de espaço
Antes de começar a reduzir, capture o espaço usado e alocado atualmente em cada arquivo de banco de dados executando a seguinte consulta de uso de espaço:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Depois que a redução for concluída, você poderá executar a consulta novamente e comparar o resultado com a linha de base inicial.
Truncar arquivos de dados
É recomendável primeiro executar a redução para cada arquivo de dados com o parâmetro TRUNCATEONLY. Dessa forma, se houver algum espaço alocado, mas não utilizado no final do arquivo, ele será removido rapidamente e sem nenhuma movimentação de dados. O seguinte comando de exemplo trunca o arquivo de dados com file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Depois que esse comando for executado para cada arquivo de dados, você poderá executar novamente a consulta de uso de espaço para ver a redução no espaço alocado, se houver. Você também pode exibir o espaço alocado para o banco de dados no portal do Azure.
Avaliar a densidade da página de índice
Se truncar os arquivos de dados não resultar em uma redução suficiente do espaço alocado, você precisará reduzir os arquivos de dados. No entanto, como uma etapa opcional, mas recomendada, primeiro você deve determinar a densidade média da página para os índices no banco de dados. Para a mesma quantidade de dados, a redução será concluída mais rapidamente se a densidade da página for alta, pois terá que mover menos páginas. Se a densidade de página for baixa para alguns índices, considere executar a manutenção nesses índices para aumentar a densidade antes de reduzir os arquivos de dados. Isso também permitirá que a redução seja mais profunda no espaço de armazenamento alocado.
Para determinar a densidade de página para todos os índices no banco de dados, use a consulta a seguir. A densidade de página é relatada na coluna avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Se houver índices com alta contagem de páginas e com densidade de página inferior a 60 a 70%, considere recompilar ou reorganizar esses índices antes de reduzir arquivos de dados.
Observação
Em bancos de dados maiores, a consulta para determinar a densidade da página pode levar um tempo considerável (horas) para ser concluída. Além disso, recompilar ou reorganizar índices grandes também requer tempo e uso de recursos substanciais. Há uma compensação entre gastar mais tempo aumentando a densidade de página por um lado e diminuir a duração da redução e atingir mais economia de espaço por outro.
Se houver múltiplos índices com baixa densidade de páginas, talvez seja possível fazer a recompilação em paralelo em múltiplas sessões do banco de dados para acelerar o processo. No entanto, certifique-se de que não esteja se aproximando dos limites de recursos do banco de dados ao fazer isso e garanta uma reserva dinâmica de recursos suficiente para as cargas de trabalho de aplicativos que possam estar em execução. Monitore o consumo de recursos (CPU, E/S de dados, E/S de logs) no portal do Azure ou usando a exibição sys.dm_db_resource_stats e inicie recompilações paralelas adicionais somente se a utilização de recursos em cada uma dessas dimensões permanecer substancialmente inferior a 100%. Se a utilização de CPU, a E/S de dados ou a E/S de logs estiver em 100%, você poderá escalar verticalmente o banco de dados para ter mais núcleos de CPU e aumentar a taxa de transferência de E/S. Isso pode permitir recompilações paralelas adicionais para concluir o processo mais rapidamente.
Comando de recompilação de índice de amostra
A seguir, temos um comando de amostra para recompilar um índice e aumentar sua densidade de página, usando a instrução ALTER INDEX:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Esse comando inicia uma recompilação de índice online e retomável. Isso permite que cargas de trabalho simultâneas continuem usando a tabela enquanto a recompilação está em andamento e permite que você retome a recompilação se ela for interrompida por qualquer motivo. No entanto, esse tipo de recompilação é mais lento do que uma recompilação offline, que bloqueia o acesso à tabela. Se nenhuma outra carga de trabalho precisar acessar a tabela durante a recompilação, defina as opções ONLINE e RESUMABLE como OFF e remova a cláusula WAIT_AT_LOW_PRIORITY.
Para saber mais sobre a manutenção de índice, confira Otimizar a manutenção do índice para aprimorar o desempenho da consulta e reduzir o consumo de recursos.
Reduzir vários arquivos de dados
Como já foi observado, a redução com movimentação de dados é um processo de execução longa. Se o banco de dados tiver vários arquivos de dados, você poderá acelerar o processo reduzindo vários arquivos de dados em paralelo. Faça isso abrindo várias sessões de banco de dados e usando DBCC SHRINKFILE em cada sessão com um valor de file_id diferente. Semelhante à recompilação de índices, verifique se você tem reserva dinâmica de recursos (CPU, E/S de dados, E/S de logs) suficiente antes de iniciar cada comando de redução paralelo.
O seguinte comando de exemplo reduz o arquivo de dados com file_id 4, tentando reduzir o tamanho alocado para 52.000 MB movendo páginas dentro do arquivo:
DBCC SHRINKFILE (4, 52000);
Se quiser reduzir o espaço alocado para o arquivo ao mínimo possível, execute a instrução sem especificar o tamanho de destino:
DBCC SHRINKFILE (4);
Se uma carga de trabalho estiver sendo executada simultaneamente com a redução, ela poderá começar a usar o espaço de armazenamento liberado pela redução antes que ela seja concluída e trunque o arquivo. Nesse caso, a redução não poderá reduzir o espaço alocado para o destino especificado.
Você pode atenuar isso reduzindo cada arquivo em etapas menores. Isso significa que, no comando DBCC SHRINKFILE, você define o destino um pouco menor do que o espaço alocado atualmente para o arquivo, conforme visto nos resultados da consulta de linha de base de uso de espaço. Por exemplo, se o espaço alocado para o arquivo com file_id 4 é de 200.000 MB e você quer reduzi-lo para 100.000 MB, você pode primeiro definir o destino como 170.000 MB:
DBCC SHRINKFILE (4, 170000);
Quando esse comando for concluído, ele terá truncado o arquivo e reduzido o tamanho alocado para 170.000 MB. Em seguida, você pode repetir o comando, definindo o destino primeiro como 140.000 MB, depois como 110.000 MB etc., até que o arquivo seja reduzido para o tamanho desejado. Se o comando for concluído, mas o arquivo não estiver truncado, use etapas menores, por exemplo, 15.000 MB em vez de 30.000 MB.
Para monitorar o progresso da redução para todas as sessões de redução em execução simultânea, você pode usar a seguinte consulta:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Observação
O progresso da redução pode ser não linear, e o valor na coluna percent_complete pode permanecer praticamente inalterado por longos períodos de tempo, mesmo que a redução ainda esteja em andamento.
Após a redução ser concluída para todos os arquivos de dados, execute novamente a consulta de uso de espaço (ou verifique no portal do Azure) para determinar a redução resultante no tamanho de armazenamento alocado. Se ainda houver uma grande diferença entre o espaço usado e o espaço alocado, você pode recompilar índices, conforme descrito anteriormente. Isso pode aumentar temporariamente o espaço alocado, mas reduzir os arquivos de dados novamente após a recompilação dos índices deve resultar em uma redução maior no espaço alocado.
Erros transitórios durante a redução
Ocasionalmente, um comando de redução pode falhar com vários erros, como tempo limite atingido e deadlocks. Em geral, esses erros são transitórios e não ocorrem novamente se o mesmo comando é repetido. Se a redução falhar com um erro, o progresso que ela fez até o momento quanto à movimentação de páginas de dados será mantido e o mesmo comando de redução poderá ser executado novamente para continuar a redução do arquivo.
O script de exemplo a seguir mostra como você pode executar a redução em um loop de repetição para repetir automaticamente até um número configurável de vezes quando ocorre um erro de tempo limite ou de deadlock. Essa abordagem de repetição é aplicável a muitos outros erros que podem ocorrer durante a redução.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Além do tempo limite e dos deadlocks, a redução pode apresentar erros devido a alguns problemas conhecidos.
Os erros retornados e as etapas de mitigação são os seguintes:
- Número do erro: 49503, mensagem de erro: %. *Is: A página %d:%d não pôde ser movida porque é uma página de armazenamento de versão persistente fora de linha. Motivo da retenção da página: %ls. Carimbo de data/hora da retenção da página: %I64d.
Esse erro ocorre quando há transações ativas de execução prolongada que geraram versões de linha no PVS (armazenamento de versão persistente). As páginas que contêm essas versões de linha não podem ser movidas por redução, portanto, ela não pode progredir e falha com esse erro.
Para atenuar, você precisa esperar até que essas transações de execução prolongada tenham sido concluídas. Como alternativa, você pode identificar e terminar essas transações de execuções prolongadas, mas isso pode afetar o aplicativo se ele não tratar as falhas de transação normalmente. Uma maneira de encontrar as transações de execução prolongada é executando a seguinte consulta no banco de dados em que você executou o comando de redução:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Você pode terminar uma transação usando o comando KILL e especificando o valor session_id associado do resultado da consulta:
KILL 4242; -- replace 4242 with the session_id value from query results
Cuidado
Terminar uma transação pode afetar negativamente as cargas de trabalho.
Depois que as transações de execução prolongada forem terminadas ou concluídas, uma em segundo plano interna limpará as versões de linha que não são mais necessárias após algum tempo. Você pode monitorar o tamanho do PVS para medir o progresso da limpeza usando a consulta a seguir. Execute a consulta no banco de dados em que você executou o comando de redução:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Depois que o tamanho do PVS relatado na coluna persistent_version_store_size_gb for reduzido substancialmente em comparação com o tamanho original, a nova execução da redução deverá ser bem-sucedida.
- Número do erro: 5223, mensagem de erro: %.*ls: A página vazia %d:%d não pôde ser desalocada.
Esse erro pode ocorrer se houver operações de manutenção de índice em andamento, como ALTER INDEX. Repita o comando de redução após a conclusão dessas operações.
Se o erro persistir, o índice associado poderá ter que ser recompilado. Para encontrar o índice a ser recompilado, execute a seguinte consulta no mesmo banco de dados em que você executou o comando de redução:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Antes de executar a consulta, substitua os espaços reservados <file_id> e <page_id> por valores reais da mensagem de erro recebida. Por exemplo, se a mensagem for A página vazia 1:62669 não pôde ser desalocada, <file_id> será 1 e <page_id> será 62669.
Recompile o índice identificado pela consulta e repita o comando de redução.
- Número do erro: 5201, mensagem de erro: DBCC SHRINKDATABASE: ID do arquivo %d da ID de banco de dados %d ignorada porque não há espaço livre suficiente no arquivo para recuperação.
Esse erro significa que o arquivo de dados não pode ser reduzido ainda mais. Você pode passar para o próximo arquivo de dados.
Conteúdo relacionado
Para obter informações sobre tamanhos máximos do banco de dados, consulte:
- Banco de dados SQL do Azure Limites do modelo de compra baseado em vCore para um único banco de dados
- Limites de recursos para bancos de dados individuais usando o modelo de compra baseado em DTU
- Limites do modelo de compra baseado em vCore para Banco de Dados SQL do Azure para pools elásticos
- Limites de recursos para pools elásticos usando o modelo de compra baseado em DTU