Recuperação de desastre para um aplicativo SaaS multilocatário usando replicação geográfica do banco de dados
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Neste tutorial, você pode explorar um cenário de recuperação de desastre completo para um aplicativo SaaS multilocatário implementado usando o modelo de banco de dados por locatário. Para proteger o aplicativo contra uma interrupção, você deve usar replicação geográfica para criar réplicas para bancos de dados de catálogos e locatários em uma região de recuperação alternativa. Se ocorrer uma interrupção, você rapidamente fará failover para essas réplicas para retomar as operações normais de negócios. Durante um failover, os bancos de dados na região original se tornam as réplicas secundárias dos bancos de dados na região de recuperação. Quando essas réplicas voltam a ficar online, elas automaticamente atualizam o estado dos bancos de dados na região de recuperação. Após a interrupção ter sido resolvida, você não fará failback para os bancos de dados na região de produção original.
Este tutorial explora fluxos de trabalho de failover e failback. Você aprenderá a:
- Sincronizar as informações de configuração de pool elástico e de banco de dados no catálogo de locatário
- Configurar um ambiente de recuperação em uma região alternativa, que inclui aplicativos, servidores e pools
- Use replicação geográfica para replicar os bancos de dados do catálogos e locatários para a região de recuperação
- Fazer failover dos bancos de dados de aplicativos, catálogos e locatários para a região de recuperação
- Posteriormente, faça failover dos bancos de dados de aplicativos, catálogos e locatários de volta para a região original após a interrupção ter sido resolvida
- Atualizar o catálogo conforme cada banco de dados de locatário passar por failover para controlar o local principal de cada banco de dados do locatário
- Garantir que o banco de dados de aplicativos e de locatário primário estejam sempre co-localizados na mesma região do Azure para reduzir a latência
Antes de iniciar este tutorial, verifique se todos os pré-requisitos a seguir foram atendidos:
- O aplicativo de banco de dados SaaS Wingtip Tickets por locatário é implantado. Para implantá-lo em menos de cinco minutos, veja Implantar e explorar o aplicativo de banco de dados por locatário SaaS Wingtip Tickets
- O Azure PowerShell está instalado. Para obter detalhes, consulte Introdução ao Azure PowerShell
Introdução ao padrão de recuperação de replicação geográfica
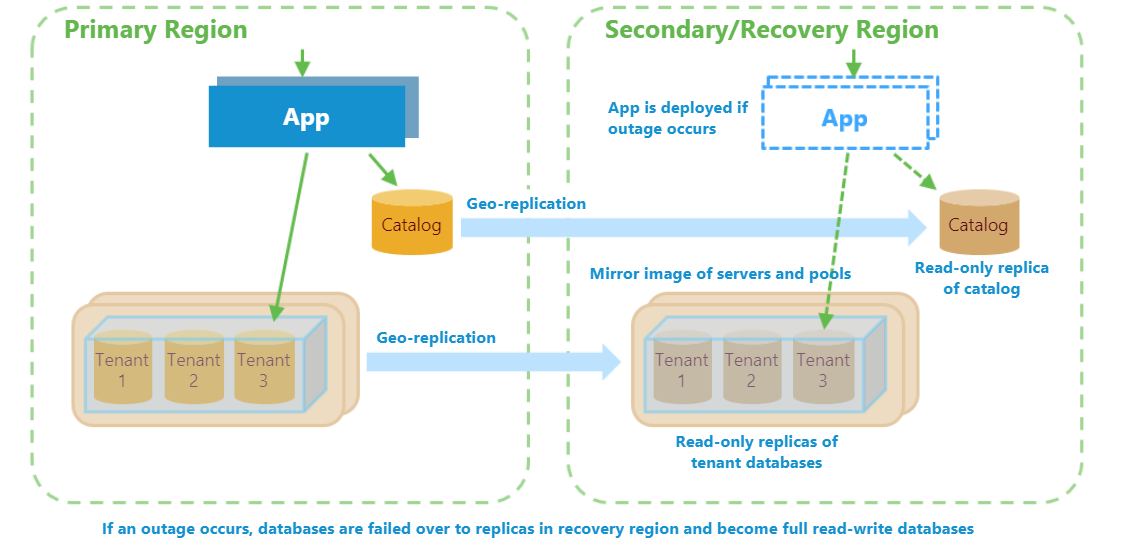
A recuperação de desastre (DR) é uma consideração importante para muitos aplicativos, seja por motivos de conformidade ou de continuidade de negócios. Se for necessária uma interrupção prolongada do serviço, um plano de recuperação de desastre bem preparado pode minimizar a interrupção dos negócios. Usar replicação geográfica fornece os menores RPO e RTO mantendo réplicas de banco de dados em uma região de recuperação que pode falhar em curto prazo.
Um plano de recuperação de desastre com base em replicação geográfica inclui três partes distintas:
- Instalação - criação e manutenção do ambiente de recuperação
- Recuperação - failover do aplicativo e bancos de dados para o ambiente de recuperação se ocorrer uma interrupção,
- Repatriação - failover do aplicativo e bancos de dados de volta à região original quando o aplicativo for resolvido
Todas as partes precisam ser consideradas com cuidado, especialmente se estiverem operando em escala. Em geral, o plano deve atingir várias metas:
- Configuração
- Estabelecer e manter um ambiente de imagem espelho da região de recuperação. Criar pools elásticos e replicar quaisquer bancos de dados nesse ambiente de recuperação reserva capacidade na região de recuperação. Manter esse ambiente inclui a replicação de novos bancos de dados de locatário conforme eles são provisionados.
- Recuperação
- Em que um ambiente de recuperação reduzido é usado para minimizar os custos diários, pools e bancos de dados precisam ser expandidos para adquirir capacidade completamente operacional na região de recuperação
- Habilitar novo provisionamento de locatário na região de recuperação assim que possível
- Ser otimizado para restauração de locatários em ordem de prioridade
- Ser otimizado para colocar os locatários online o mais rápido possível ao seguir as etapas em paralelo quando for prático
- Ser resiliente a falhas, reiniciável e idempotente
- Ser possível cancelar o processo em funcionamento se a região original ficar online novamente.
- Repatriação
- Failover de bancos de dados da região de recuperação para réplicas na região original com impacto mínimo para locatários: nenhuma perda de dados e o período mínimo offline por locatário.
Neste tutorial, esses desafios são resolvidos usando os recursos do Banco de Dados SQL do Azure e a plataforma Azure:
- Modelos do Azure Resource Manager para reservar toda a capacidade necessária assim que possível. Os modelos do Azure Resource Manager são usados para provisionar uma imagem espelho dos servidores de produção e pools elásticos na região de recuperação.
- Replicação geográfica para criar secundários replicados de forma assíncrona e somente leitura para todos os bancos de dados. Durante uma interrupção, você faz failover para as réplicas na região de recuperação. Após a interrupção ter sido resolvida, você não fará failback para os bancos de dados na região original sem perda de dados.
- Operações de failover assíncronas enviadas na ordem de prioridade de locatários, para minimizar o tempo de failover para um grande número de bancos de dados.
- Recursos de recuperação de gerenciamento de fragmentos para alterar as entradas de banco de dados no catálogo durante a recuperação e a repatriação. Esses recursos permitem que o aplicativo se conecte aos bancos de dados de locatário, independente do local sem precisar reconfigurar o aplicativo.
- Aliases DNS do SQL Server para habilitar o provisionamento contínuo de novos locatários, independente da região em que o aplicativo está operando. Aliases DNS também são usados para permitir que o processo de sincronização de catálogo se conecte ao catálogo ativo, independente de sua localização.
Obter os scripts de recuperação de desastre
Importante
Como todos os scripts de gerenciamento da Wingtip Tickets, os scripts de recuperação de desastre têm qualidade de exemplo e não devem ser usados em produção.
Os scripts de recuperação usados neste tutorial e o código-fonte do aplicativo Wingtip estão disponíveis no banco de dados SaaS Wingtip Tickets por repositório do GitHub. Confira as diretrizes gerais para obter as etapas a fim de baixar e desbloquear os scripts de gerenciamento do Wingtip Tickets.
Visão geral do tutorial
Neste tutorial, você primeiro usa replicação geográfica para criar réplicas dos seus bancos de dados e aplicativo Wingtip Tickets em uma região diferente. Em seguida, faz failover para essa região para simular a recuperação de uma interrupção. Ao concluir, o aplicativo estará totalmente funcional na região de recuperação.
Mais tarde, em uma etapa de repatriação separada, você faz failover dos bancos de dados de catálogo e locatário na região de recuperação para a região original. O aplicativo e os bancos de dados ficam disponíveis em toda a repatriação. Ao concluir, o aplicativo estará totalmente funcional na região original.
Observação
O aplicativo é recuperado para a região emparelhada da região em que o aplicativo é implantado. Para obter mais informações, consulte Regiões emparelhadas do Azure.
Examinar o estado de integridade do aplicativo
Antes de iniciar o processo de recuperação, examine o estado de integridade normal do aplicativo.
No navegador da Web, abra o Hub de Eventos da Wingtip Tickets (http://events.wingtip-dpt.<usuário>.trafficmanager.net – substitua <usuário> pelo valor de usuário da implantação).
- Role até a parte inferior da página e observe o nome do servidor de catálogo e a localização no rodapé. A localização é a região em que você implantou o aplicativo.
DICA: passe o mouse sobre o local para ampliar a exibição.

- Role até a parte inferior da página e observe o nome do servidor de catálogo e a localização no rodapé. A localização é a região em que você implantou o aplicativo.
DICA: passe o mouse sobre o local para ampliar a exibição.
Clique no locatário Contoso Concert Hall e abra sua página de eventos.
- No rodapé, observe o nome do servidor de locatário. A localização será igual à localização do servidor de catálogo.
No Portal do Azure, abra o grupo de recursos no qual o aplicativo foi implantado
- Observe a região na qual os servidores são implantados.
Sincronizar a configuração de locatário com o catálogo
Nesta tarefa, você inicia um processo que sincroniza a configuração dos servidores, dos pools elásticos e dos bancos e dados com o catálogo de locatário. O processo mantém essas informações atualizadas no catálogo. O processo funciona com o catálogo ativo, seja na região original ou na região de recuperação. As informações de configuração são usadas como parte do processo de recuperação para garantir que o ambiente de recuperação é consistente com o ambiente original e posteriormente, durante a repatriação para garantir que a região original seja tornada consistente com as alterações feitas no ambiente de recuperação. O catálogo também é usado para controlar o estado de recuperação de recursos de locatário
Importante
Para simplificar, o processo de sincronização e outros processos de recuperação e de repatriação de execução prolongada são implementados nesses tutoriais como trabalhos ou sessões locais do PowerShell executados em seu logon de usuário de cliente. Os tokens de autenticação emitidos quando seu logon expirar após várias horas e então os trabalhos falham. Em um cenário de produção, os processos de execução longa devem ser implementados como serviços do Azure confiáveis de algum tipo, em execução sob uma entidade de serviço. Consulte Usar o Azure PowerShell para criar uma entidade de serviço com um certificado.
No ISE do PowerShell, abra o arquivo ...\Learning Modules\UserConfig.psm1. Substitua
<resourcegroup>e<user>nas linhas 10 e 11 pelo valor usado quando você implantou o aplicativo. Salve o arquivo!No ISE do PowerShell, abra o script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e defina:
- $DemoScenario = 1, Iniciar um trabalho em segundo plano que sincroniza o servidor de locatário e informações de configuração do pool com o catálogo
Pressione F5 para executar o script de sincronização. Uma nova sessão do PowerShell é aberta para sincronizar a configuração de recursos de locatário.
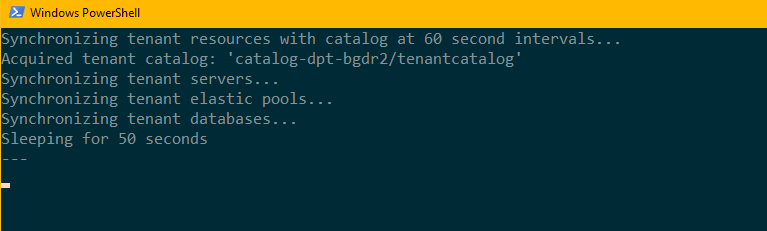
Deixe a janela do PowerShell em execução em segundo plano e prossiga com o restante do tutorial.
Observação
O processo de sincronização se conecta ao catálogo por um alias DNS. Esse alias é modificado durante a restauração e a repatriação para apontar para o catálogo ativo. O processo de sincronização mantém o catálogo atualizado com todas as alterações do banco de dados ou do pool feitas na região de recuperação. Durante a repatriação, essas alterações são aplicadas aos recursos equivalentes na região original.
Criar réplicas de banco de dados secundário na região de recuperação
Nesta tarefa, você inicia um processo que implanta uma instância de aplicativo duplicado e replica o catálogo e todos os bancos de dados de locatário para uma região de recuperação.
Observação
Este tutorial adiciona proteção de replicação geográfica ao aplicativo de exemplo Wingtip Tickets. Em um cenário de produção para um aplicativo que usa a replicação geográfica, cada locatário deve ser provisionado com um banco de dados replicado geograficamente desde o início. Consulte Criar serviços altamente disponíveis usando o Banco de Dados SQL do Azure
No ISE do PowerShell, abra o script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e defina os valores a seguir:
- $DemoScenario = 2, crie o ambiente de recuperação de imagem espelho e replique bancos de dados de catálogo e locatário
Pressione F5 para executar o script. Uma nova sessão do PowerShell é aberta para criar as réplicas.
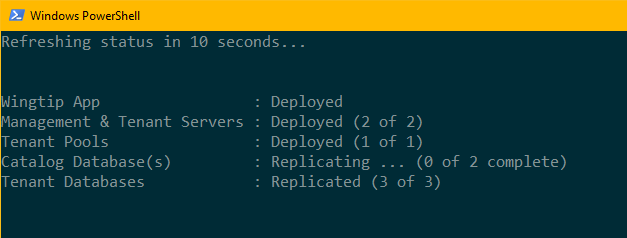
Examine o estado de aplicativo normal
Neste ponto, o aplicativo está sendo executado normalmente na região original e agora é protegido por replicação geográfica. Réplicas secundárias somente leitura, existem na região de recuperação para todos os bancos de dados.
No Portal do Azure, examine seus grupos de recursos e observe que um grupo de recursos foi criado com sufixo -recovery na região de recuperação.
Explore os recursos no grupo de recursos de descoberta.
Clique no banco de dados do Contoso Concert Hall no servidor tenants1-dpt-<user>-recovery. Clique na replicação geográfica no lado esquerdo.

No mapa de regiões do Azure, observe o link de replicação geográfica entre a primária na região original e a secundária na região de recuperação.
Failover do aplicativo para a área de recuperação
Visão geral do processo de recuperação de replicação geográfica
O script de recuperação executa as seguintes tarefas:
Desabilita o ponto de extremidade do Gerenciador de Tráfego para o aplicativo Web na região original. Desabilitar o ponto de extremidade impede que os usuários se conectem ao aplicativo em um estado inválido caso a região original fique online durante a recuperação.
Usa um failover forçado do banco de dados do catálogo na região de recuperação para torná-lo o banco de dados primário e atualiza o alias activecatalog para apontar para o servidor de catálogo de recuperação.
Atualiza o alias do novo locatário para apontar para o servidor de tenente na região de recuperação. A alteração desse alias garante que os bancos de dados para quaisquer novos locatários sejam provisionados na região de recuperação.
Marca todos os locatários existentes no catálogo de recuperação como offline para impedir o acesso a bancos de dados de locatário antes do failover.
Atualiza a configuração de todos os pools elásticos e bancos de dados individuais replicados na região de recuperação para espelhar a configuração na região original. (Essa tarefa é necessária somente se pools ou bancos de dados replicados no ambiente de recuperação forem reduzidos durante operações normais para reduzir os custos).
Habilita o ponto de extremidade do Gerenciador de Tráfego para o aplicativo Web na região de recuperação. Habilitar este ponto de extremidade permite que o aplicativo provisione novos locatários. Neste estágio, os locatários existentes ainda estão offline.
Envia os lotes de solicitações para forçar o failover de bancos de dados em ordem de prioridade.
- Os lotes são organizados para que os bancos de dados passem por failover em paralelo entre todos os pools.
- Solicitações de failover são enviadas usando operações assíncronas para que sejam enviadas rapidamente e várias solicitações possam ser processadas simultaneamente.
Observação
Em um cenário de interrupção, os bancos de dados primários na região original estão offline. Forçar o failover no secundário quebra a conexão com o primário sem tentar aplicar nenhuma transação residual em fila. Em um cenário de análise de recuperação de desastre como este tutorial, se não houver nenhuma atividade de atualização no momento do failover, pode haver perda de dados. Posteriormente, durante a repatriação, quando houver falha em bancos de dados na região de recuperação para a região original, um failover normal é usado para garantir que não haja nenhuma perda de dados.
Monitora o serviço para determinar quando os bancos de dados passam por failover. Quando um banco de dados de locatário passa por failover, ele atualiza o catálogo para registrar o estado de recuperação do banco de dados de locatário e marca o locatário como online.
- Os bancos de dados de locatário podem ser acessados pelo aplicativo assim que são marcados como online no catálogo.
- A soma dos valores de rowversion no banco de dados de locatário é armazenada no catálogo. Esse valor atua como uma impressão digital, que permite que o processo de repatriação determine se o banco de dados foi atualizado na região de recuperação.
Executar o script para fazer failover para a região de recuperação
Agora imagine que haja uma interrupção na região em que o aplicativo é implantado e execute o script de recuperação:
No ISE do PowerShell, abra o script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e defina os valores a seguir:
- $DemoScenario = 3, recupere o aplicativo em uma região de recuperação por failover para réplicas
Pressione F5 para executar o script.
- O script é aberto em uma nova janela do PowerShell e, em seguida, inicia uma série de trabalhos do PowerShell executados em paralelo. Esses trabalhos fazem failover de bancos de dados de locatário para a região de recuperação.
- A região de recuperação é a região emparelhada associada à região do Azure na qual você implantou o aplicativo. Para obter mais informações, consulte Regiões emparelhadas do Azure.
Monitore o status do processo de recuperação na janela do PowerShell.
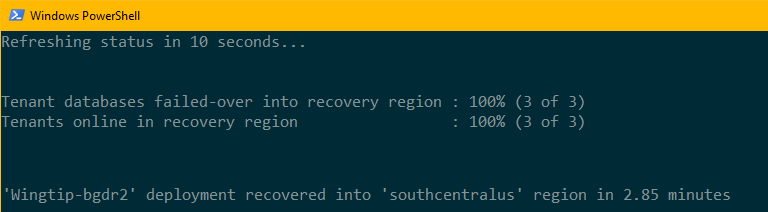
Observação
Para explorar o código para os trabalhos de recuperação, examine os scripts do PowerShell na pasta ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\RecoveryJobs.
Examinar o estado do aplicativo durante a recuperação
Enquanto o ponto de extremidade do aplicativo estiver desabilitado no Gerenciador de Tráfego, o aplicativo não estará disponível. Depois que é feito o failover do catálogo para a região de recuperação e todos os locatários são marcados como offline, o aplicativo é colocado online novamente. Embora o aplicativo esteja disponível, cada locatário aparece offline no hub de eventos até que seja feito o failover do seu banco de dados. É importante projetar seu aplicativo para que ele lide com bancos de dados de locatário offline.
- Assim que o banco de dados do catálogo tiver sido recuperado, atualize o Hub de Eventos da Wingtip Tickets no navegador da Web.
No rodapé, observe que o nome do servidor de catálogo agora tem um sufixo -recovery e está localizado na região de recuperação.
Observe que os locatários que ainda não foram restaurados estão marcados como offline e não são selecionáveis.
Observação
Com apenas alguns bancos de dados para recuperar, pode não ser possível atualizar o navegador antes de a recuperação ter sido concluída, portanto você pode não ver os locatários enquanto eles estiverem offline.
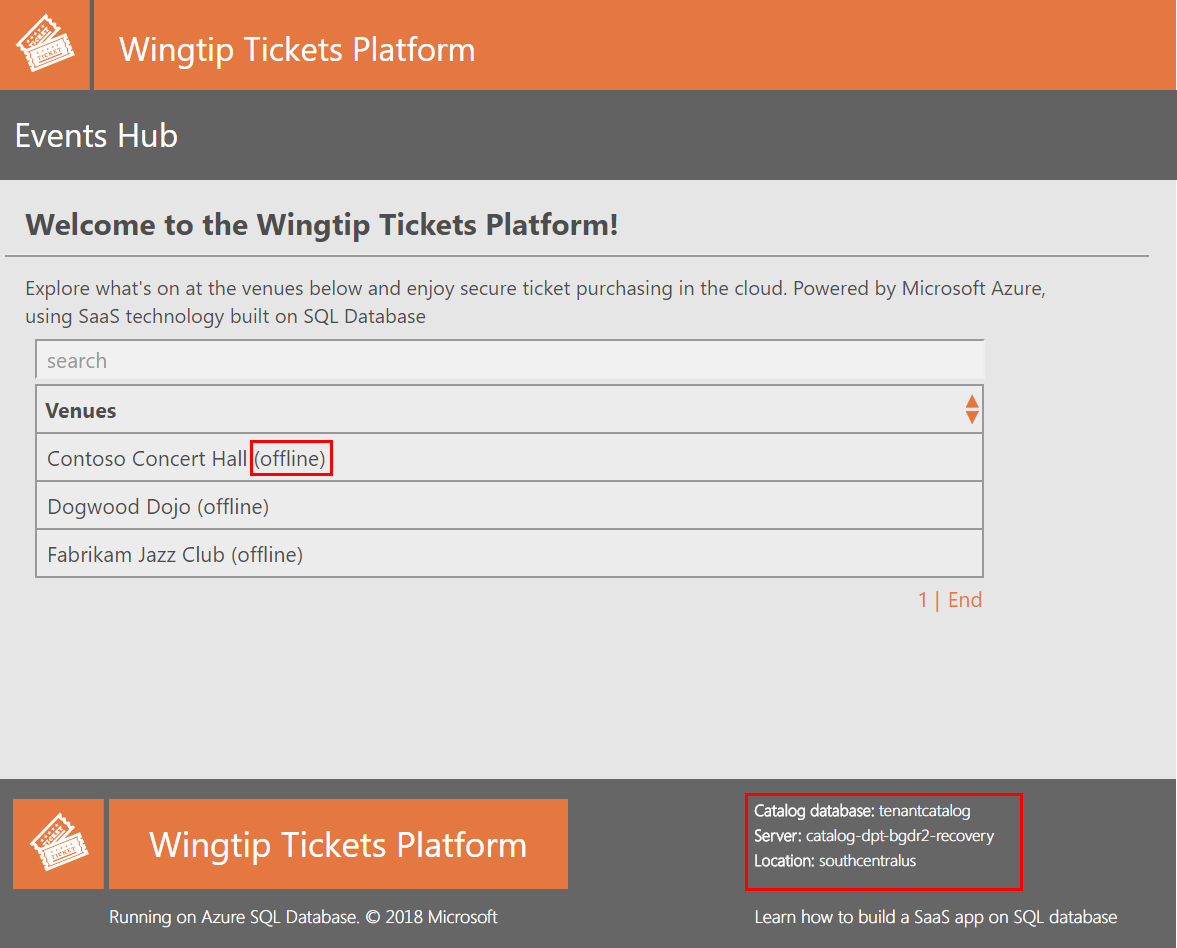
Se você abrir a página Eventos de um locatário offline diretamente, ela exibirá uma notificação de 'locatário offline'. Por exemplo, se Contoso Concert Hall estiver offline, tente abrir http://events.wingtip-dpt.<user>.trafficmanager.net/contosoconcerthall
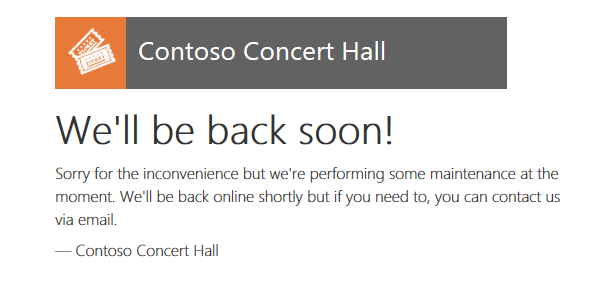
Provisionar um novo locatário na região de recuperação
Antes mesmo de todos os bancos de dados de locatário existentes terem passado por failover, você poderá provisionar novos locatários na região de recuperação.
No ISE do PowerShell, abra o script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1 e defina a propriedade a seguir:
- $DemoScenario = 4, provisione um novo locatário na região de recuperação
Pressione F5 para executar o script e provisionar o novo locatário.
A página de eventos de Hawthorn Hall abre no navegador quando ele é concluído. Observe no rodapé que o banco de dados Hawthorn Hall é provisionado na região de recuperação.

No navegador, atualize a página do Hub de Eventos da Wingtip Tickets para ver Hawthorn Hall incluído.
- Se você tiver provisionado Hawthorn Hall sem aguardar a restauração dos outros locatários, outros locatários ainda poderão estar offline.
Examinar o estado recuperado do aplicativo
Quando o processo de recuperação for concluída, o aplicativo e todos os locatários estarão totalmente funcionais na região de recuperação.
Depois que a exibição na janela do console do PowerShell indicar que todos os locatários foram recuperados, atualize o Hub de Eventos. Os locatários aparecerão online, inclusive o novo locatário, Hawthorn Hall.
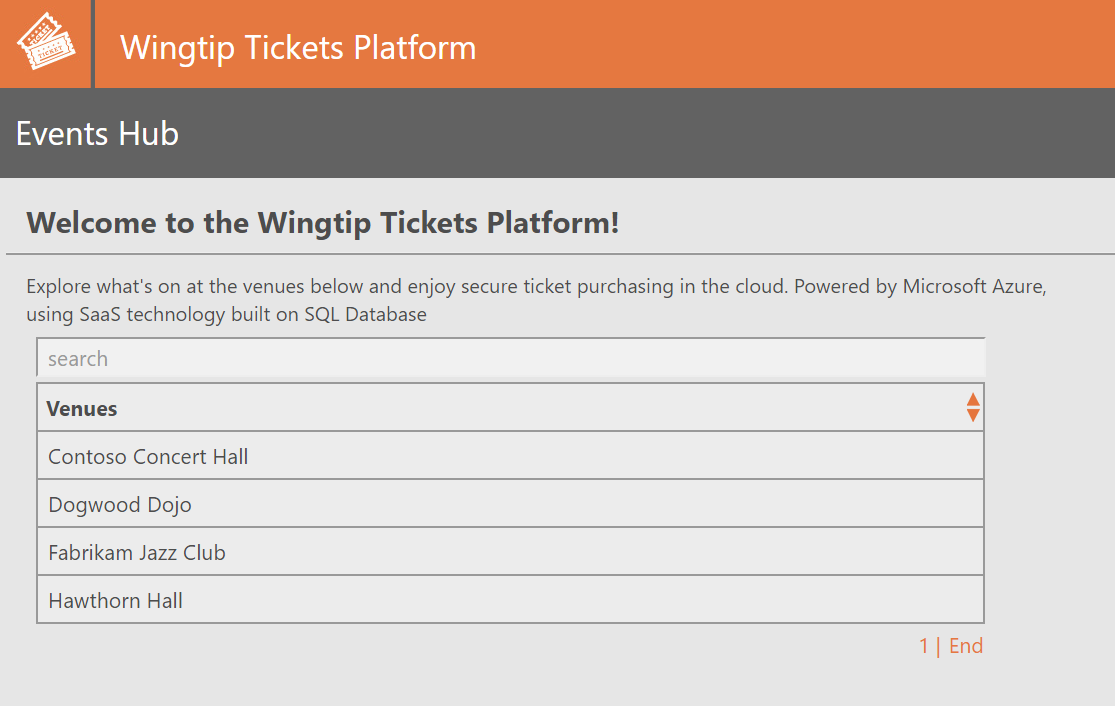
No Portal do Azure, abra a lista de grupos de recursos.
- Observe o grupo de recursos que você implantou, mais o grupo de recursos de recuperação, com o sufixo -recovery. O grupo de recursos de recuperação contém todos os recursos criados durante o processo de recuperação, além de novos recursos criados durante a interrupção.
Abra o grupo de recursos de recuperação e observe os seguintes itens:
As versões de recuperação dos servidores de catálogo e locatários1 com o sufixo -recovery. Os bancos de dados restaurados de catálogo e de locatário nesses servidores têm os nomes usados na região original.
O servidor SQL tenants2-dpt-<user>-recovery. Este servidor é usado para provisionar novos locatários durante a interrupção.
O Serviço de Aplicativo chamado events-wingtip-dpt-<recoveryregion>-<user>, que é a instância de recuperação do aplicativo Eventos.
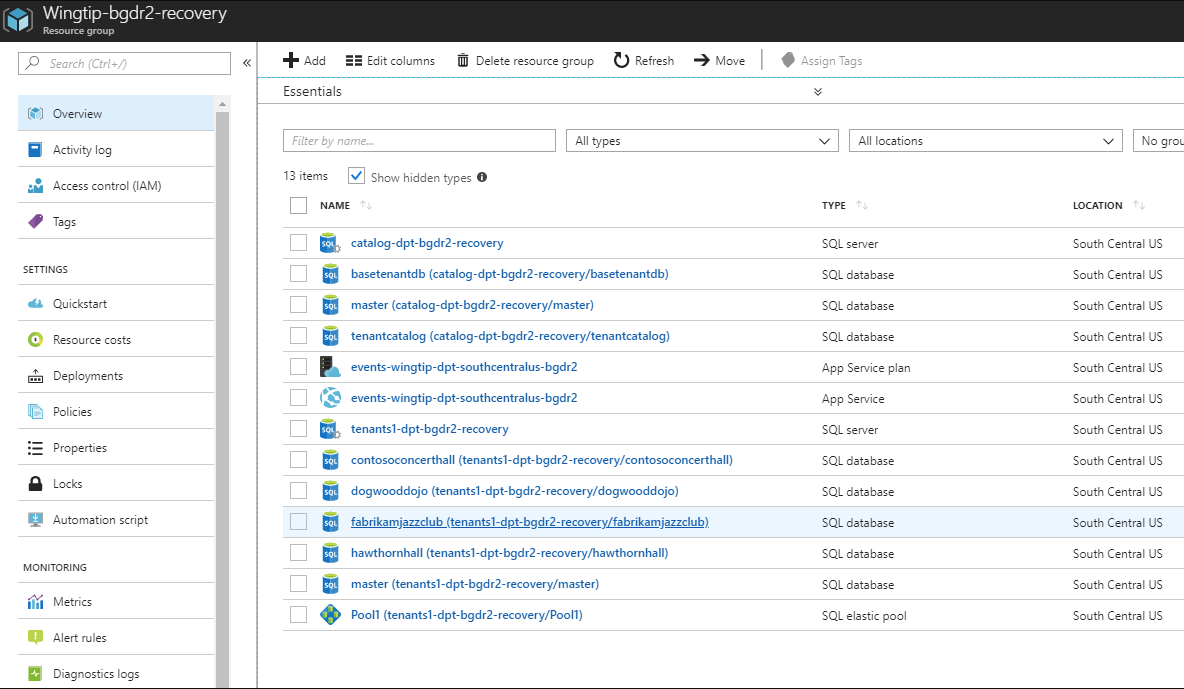
Abra o servidor SQL tenants2-dpt-<usuário>-recovery. Observe que ele contém o banco de dados hawthornhall e o pool elástico, Pool1. O banco de dados hawthornhall está configurado como um banco de dados elástico no pool elástico Pool1.
Navegue de volta para o grupo de recursos e clique no banco de dados do Contoso Concert Hall no servidor tenants1-dpt-<user>-recovery. Clique na replicação geográfica no lado esquerdo.
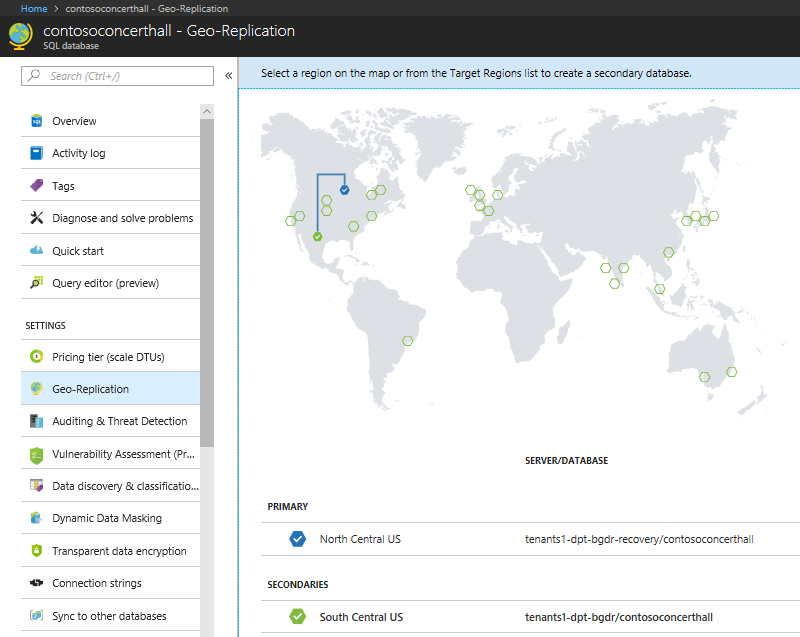
Alterar dados de locatário
Nesta tarefa, você atualiza um dos bancos de dados de locatário.
- No navegador, encontre a lista de eventos para o Contoso Concert Hall e anote o nome do último evento.
- No ISE do PowerShell, no script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1, defina o valor a seguir:
- $DemoScenario = 5 Exclua um evento de um locatário na região de recuperação
- Pressione F5 para executar o script
- Atualize a página de eventos do Contoso Concert Hall (http://events.wingtip-dpt.<usuário>.trafficmanager.net/contosoconcerthall – substitua <usuário> pelo valor de usuário da implantação) e observe que o último evento foi excluído.
Repatrie o aplicativo para sua região de produção original
Essa tarefa repatria o aplicativo para sua região original. Em um cenário real, você iniciaria a repatriação quando a interrupção fosse resolvida.
Visão geral do processo de repatriação
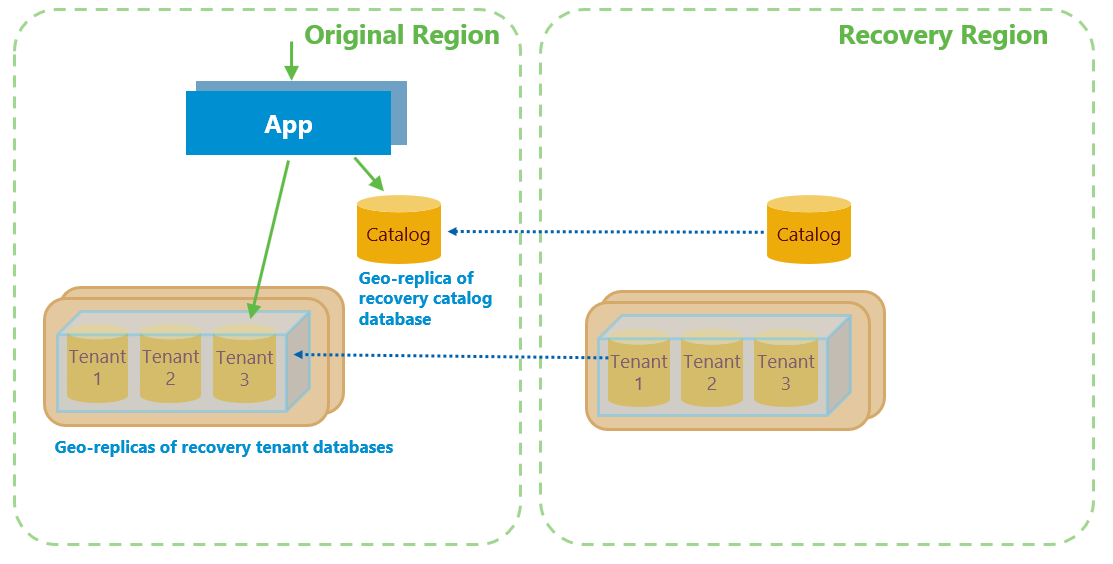
O processo de repatriação:
- Cancela qualquer solicitação de restauração de banco de dados em andamento ou pendente.
- Atualiza o alias do novo locatário para apontar para o servidor do tenente na região de origem. A alteração desse alias garante que os bancos de dados para quaisquer novos locatários agora serão provisionados na região de origem.
- Envia quaisquer dados de locatário alterados para a região original
- Faz failover de bancos de dados de locatário em ordem de prioridade.
O failover move de forma eficiente o banco de dados para a região original. Quando o banco de dados falha, todas as conexões abertas são descartadas e o banco de dados fica indisponível por alguns segundos. Aplicativos devem ser escritos com lógica de repetição para garantir que se conectem novamente. Embora essa breve desconexão geralmente não seja observada, você pode optar por repatriar bancos de dados fora do horário comercial.
Executar o script repatriação
Agora vamos imaginar que a interrupção foi resolvida e o script de repatriação está sendo executado.
No ISE do PowerShell, no script ...\Learning Modules\Business Continuity and Disaster Recovery\DR-FailoverToReplica\Demo-FailoverToReplica.ps1.
Verifique se o processo de Sincronização de Catálogo ainda está em execução em sua instância do PowerShell. Se necessário, reinicie-o ao definir:
- $DemoScenario = 1, Iniciar a sincronização do servidor locatário, o pool e informações de configuração do banco de dados para o catálogo
- Pressione F5 para executar o script.
Então, para iniciar o processo de repatriação, defina:
- $DemoScenario = 6, Repatrie o aplicativo para sua região original
- Pressione F5 para executar o script de recuperação em uma nova janela do PowerShell. A repatriação levará vários minutos e pode ser monitorada na janela do PowerShell.
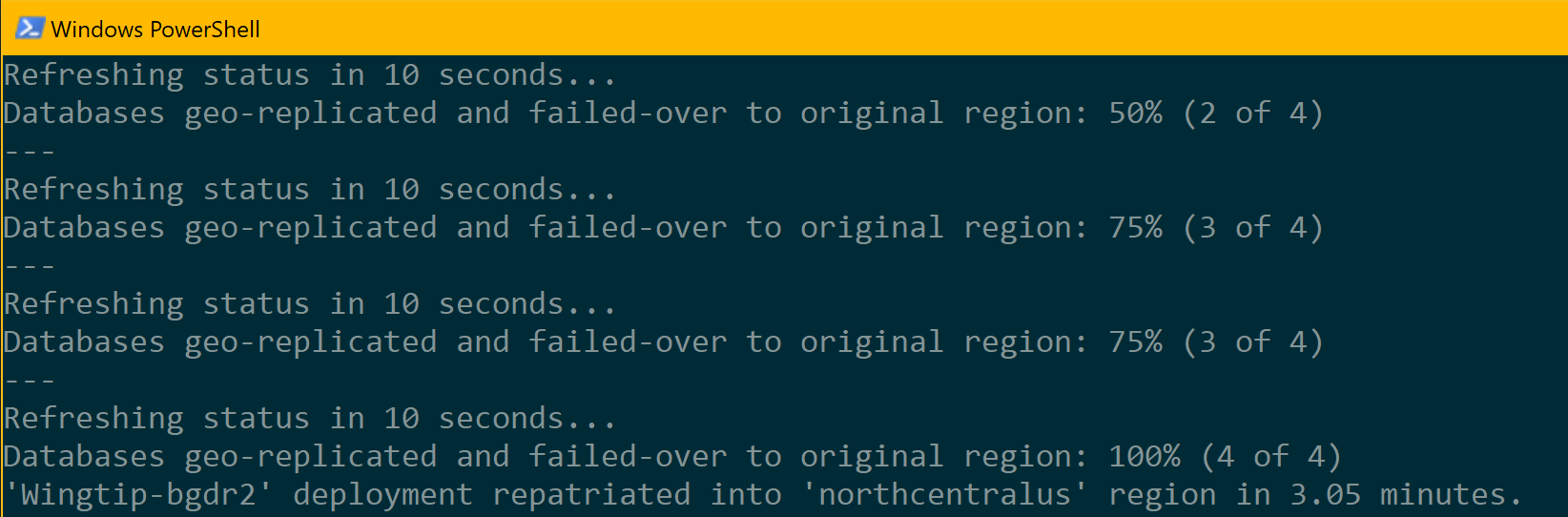
Durante a execução do script, atualize a página do Hub de Eventos (http://events.wingtip-dpt.<user>.trafficmanager.net)
- Observe que todos os locatários estão online e acessíveis durante este processo.
Depois que a repatriação for concluída, atualize o Hub de eventos e abra a página de eventos para Hawthorn Hall. Observe que esse banco de dados foi repatriado para a região original.
Como projetar o aplicativo para garantir que ele e o banco de dados sejam colocados
O aplicativo foi projetado para sempre se conectar de uma instância na mesma região do banco de dados de locatário. Esse design reduz a latência entre o aplicativo e o banco de dados. Essa otimização assume que a interação do aplicativo no banco de dados é mais ativa que a interação do usuário com o aplicativo.
Os bancos de dados de locatário podem ser distribuídos por regiões originais e de recuperação por algum tempo durante a repatriação. Para cada banco de dados, o aplicativo procura a região na qual o banco de dados está localizado, fazendo uma pesquisa de DNS no nome do servidor de locatário. No Banco de Dados SQL, o nome do servidor é um alias. O nome de servidor com alias contém o nome da região. Se o aplicativo não estiver na mesma região do que o banco de dados, ele redirecionará para a instância na mesma região que o servidor. Redirecionar a instância na mesma região que o banco de dados minimiza a latência entre o aplicativo e o banco de dados.
Próximas etapas
Neste tutorial, você aprendeu a:
- Sincronizar as informações de configuração de pool elástico e de banco de dados no catálogo de locatário
- Configurar um ambiente de recuperação em uma região alternativa, que inclui aplicativos, servidores e pools
- Use replicação geográfica para replicar os bancos de dados do catálogos e locatários para a região de recuperação
- Fazer failover dos bancos de dados de aplicativos, catálogos e locatários para a região de recuperação
- Faça failback dos bancos de dados de aplicativos, catálogos e locatários de volta para a região original após a interrupção ter sido resolvida
Você pode saber mais sobre as tecnologias que o Banco de Dados SQL do Azure fornece para permitir a continuidade dos negócios na documentação Visão geral de continuidade de negócios.