Considerações de design para plataformas de dados de autoatendimento
A malha de dados é uma nova abordagem interessante para o design e desenvolvimento da arquitetura de dados. Ao contrário da arquitetura de dados tradicional, a malha de dados separa a responsabilidade entre domínios de dados funcionais que se concentram na criação de produtos de dados e uma equipe de plataforma que se concentra em recursos técnicos. Essa separação de responsabilidades deve ser refletida na plataforma. Você deve encontrar um equilíbrio entre fornecer recursos independentes de domínio e permitir que as equipes de domínio modelem, processem e distribuam os dados em sua organização.
Não é fácil escolher o nível certo de granularidade de domínio e regras de desacoplamento usando plataformas. Este artigo contém vários cenários que fornecem diretrizes detalhadas.
Análise em escala de nuvem
Quando você deseja criar uma malha de dados com o Azure, é recomendável adotar a análise de escala de nuvem. Essa estrutura é uma arquitetura de referência implantável e vem com modelos de software livre e melhores práticas. A arquitetura de análise de escala de nuvem tem dois blocos de construção principais, que são fundamentais para todas as opções de implantação:
- Zona de destino de gerenciamento de dados: a base da arquitetura de dados. Ela contém todos os recursos críticos para o gerenciamento de dados, como catálogo de dados, linhagem de dados, catálogo de API, gerenciamento de dados mestre e assim por diante.
- Zonas de destino de dados: assinaturas que hospedam as soluções de análise e IA. Elas incluem os principais recursos para hospedar uma plataforma de análise.
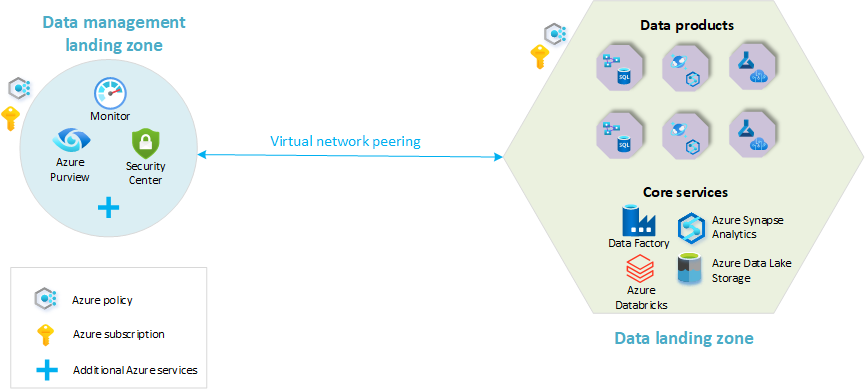
O diagrama a seguir fornece uma visão geral de uma plataforma de análise de escala de nuvem, com uma zona de destino de gerenciamento de dados e uma única zona de destino de dados. Nem todos os serviços do Azure são representados no diagrama. Ele foi simplificado para destacar os principais conceitos da organização dos recursos na arquitetura.
A estrutura de análise baseada em nuvem não é explícita sobre qual tipo exato de arquitetura de dados você deve provisionar. Você pode usá-la para muitas soluções comuns de análise de escala de nuvem, incluindo data warehouses (corporativos), data lakes, data lake houses e malhas de dados. Todas as soluções de exemplo neste artigo usam a arquitetura de malha de dados.
Entenda que todas as arquiteturas seguem os princípios da malha de dados: propriedade de domínio, dados como produto, plataforma de dados de autoatendimento e governança computacional federada. Caminhos diferentes podem levar a uma malha de dados. Não há uma única resposta certa ou errada. Você deve fazer as compensações certas de acordo com as necessidades da sua organização.
Zona de destino de dados única
O padrão de implantação mais simples para a criação de uma arquitetura de malha de dados envolve uma zona de destino de gerenciamento de dados e uma zona de destino de dados. A arquitetura de dados nesse cenário seria semelhante à seguinte:

Nesse modelo, todos os domínios de dados funcionais residem na mesma zona de destino de dados. Uma assinatura única contém um conjunto padrão de serviços. Os grupos de recursos separam diferentes domínios de dados e produtos de dados. Os serviços de dados padrão, como o Azure Data Lake Store, os Aplicativos Lógicos do Azure e o Azure Synapse Analytics, aplicam-se a todos os domínios.
Todos os domínios de dados seguem os princípios de malha de dados: os dados seguem a propriedade do domínio e os dados são tratados como produtos. A plataforma é totalmente de autoatendimento, embora haja variações limitadas de serviços. Todos os domínios devem aderir veementemente aos mesmos princípios de gerenciamento de dados e estar em conformidade com eles.
Essa opção de implantação pode ser útil para empresas menores ou projetos greenfield que desejam adotar a malha de dados, mas não querem complicar demais as coisas. Essa implantação também pode ser um ponto de partida para uma organização que planeja criar algo mais complexo. Nesse caso, planeje a expansão para várias zonas de destino no futuro.
Zonas de destino alinhadas ao sistema de origem e ao consumidor
No modelo anterior, não levamos em conta outras assinaturas ou aplicativos locais. Você pode alterar ligeiramente o modelo anterior, adicionando uma zona de destino alinhada ao sistema de origem para gerenciar todos os dados de entrada. A integração de dados é um processo difícil. Portanto, ter duas zonas de destino de dados é útil. A integração continua sendo uma das partes mais desafiadoras do uso de dados em geral. Muitas vezes, a integração também exige ferramentas adicionais para lidar com a integração, pois os desafios são diferentes dos da integração. Isso ajuda a distinguir entre o fornecimento e o consumo de dados.

Na arquitetura à esquerda desse diagrama, os serviços facilitam toda a integração de dados, como CDC, serviços para efetuar pull de APIs ou serviços de data lake para criar conjuntos de dados dinamicamente. Os serviços nessa plataforma podem extrair dados de ambientes locais, ambientes em nuvem ou fornecedores de SaaS. Normalmente, esse tipo de plataforma também tem mais sobrecarga, pois há mais acoplamento com aplicativos operacionais subjacentes. Convém tratar isso de forma diferente em relação ao uso de dados.
Na arquitetura à direita do diagrama, a organização é otimizada para consumo e tem serviços com foco em transformar dados em valor. Esses serviços podem incluir aprendizado de máquina, relatórios e assim por diante.
Esses domínios de arquitetura seguem todos os princípios da malha de dados. Os domínios se apropriam dos dados e têm permissão para distribuir dados diretamente para outros domínios.
Zonas de destino de dados especiais, genéricos e de hub
A próxima opção de implantação é outra iteração do design anterior. Essa implantação segue uma topologia de malha regida: os dados são distribuídos por meio de um hub central, em que os dados são particionados por domínio, logicamente isolados e não integrados. O hub desse modelo usa sua própria zona de destino de dados (independente de domínio) e pode pertencer a uma equipe central de governança de dados, que supervisiona quais dados são distribuídos para quais outros domínios. O hub também carrega serviços que facilitam a integração de dados.

Para domínios que exigem serviços padrão para consumir, usar, analisar e criar novos dados, use a zona de destino de dados genéricos. Essa assinatura única detém um conjunto padrão de serviços. Aplique também a virtualização de dados, pois a maioria dos produtos de dados já são persistentes no hub e você não precisa de mais duplicação de dados.
Essa implantação permite "zonas especiais": zonas de destino adicionais que você pode provisionar quando não é possível agrupar domínios logicamente. Elas podem ser necessárias quando os limites regionais ou legais se aplicam ou quando os domínios têm requisitos exclusivos e divergentes. Você também pode precisar delas nas situações em que uma governança subsidiária global robusta é aplicada, com exceções para atividades no exterior.
Se sua organização precisar controlar quais dados são distribuídos e consumidos por quais domínios, a implantação de hub é uma boa opção. Essa também será uma opção se você estiver lidando com preocupações de variante no tempo e não voláteis para consumidores de dados grandes. Você pode padronizar veementemente o design do produto de dados, o que permite que os domínios viajem no tempo e executem novas entregas. Esse modelo é especialmente comum no setor financeiro.
Zonas de destino de dados alinhadas à região e à função
O provisionamento de várias zonas de destino de dados pode ajudar a agrupar domínios funcionais com base na coesão e na eficiência para trabalhar e compartilhar dados. Todas as zonas de destino de dados seguem os mesmos controles e auditorias, mas você ainda pode ter alterações de flexibilidade e design entre diferentes zonas de destino de dados.

Determine os domínios de dados funcionais que você deseja agrupar logicamente para uma zona de aterrissagem de dados compartilhados. Por exemplo, você pode implementar os mesmos modelos se tiver limites regionais. A propriedade, a segurança ou os limites legais podem forçar você a separar domínios. A flexibilidade, o ritmo da mudança e a separação ou venda de suas capacidades também são fatores importantes a serem considerados.
Diretrizes e melhores práticas adicionais podem ser encontradas nos domínios de dados.
Diferentes zonas de destino não são independentes. Elas podem se conectar a data lakes hospedados em outras zonas. Isso permite que os domínios colaborem em toda a empresa. Você também pode aplicar persistência poliglota para misturar diferentes tecnologias de armazenamento de dados. A persistência poliglota permite que os domínios leiam os dados diretamente de outros domínios, sem duplicação de dados.
Ao implantar várias zonas de destino de dados, saiba que há uma sobrecarga de gerenciamento anexada a cada zona de destino de dados. Você deve aplicar o emparelhamento VNet entre todas as zonas de destino de dados. Você deve gerenciar os pontos de extremidade privados adicionais e assim por diante.
A implantação de várias zonas de destino de dados é uma boa opção, se a arquitetura de dados for grande. Você pode adicionar mais zonas de destino à arquitetura, para atender às necessidades comuns de vários domínios. Essas zonas de destino adicionais usam o emparelhamento de rede virtual para se conectar à zona de destino de gerenciamento de dados e a todas as outras zonas de destino. O emparelhamento permite que você compartilhe conjuntos de dados e recursos entre zonas de destino. A divisão de dados entre zonas separadas permite que você distribua cargas de trabalho entre as assinaturas e os recursos do Azure. Essa abordagem ajuda a implementar organicamente a malha de dados.
Empresa de grande porte que exige diferentes zonas de gerenciamento de dados
As empresas de grande porte que operam em escala global podem ter requisitos de gerenciamento de dados divergentes entre diferentes partes da organização. Você pode implantar várias zonas de destino de dados e de gerenciamento de dados para resolver esse problema. O seguinte diagrama mostra um exemplo desse tipo de arquitetura:

Várias zonas de destino de gerenciamento de dados devem justificar a sobrecarga e a complexidade de integração. Por exemplo, outra zona de destino de gerenciamento de dados pode fazer sentido para situações em que os (meta)dados da organização não devem ser vistos por ninguém fora da organização.
Conclusão
A transição para a malha de dados é uma mudança cultural que envolve nuances, compensações e considerações. Você pode usar a análise de escala de nuvem para obter as melhores práticas e os recursos executáveis. As arquiteturas de referência deste artigo oferecem pontos de partida para que você inicie a implementação.