Tarefa do Azure DevOps para o Azure Data Explorer
O Azure DevOps Services fornece ferramentas de colaboração de desenvolvimento, como pipelines de alto desempenho, repositórios Git privados gratuitos, quadros Kanban configuráveis e funcionalidades abrangentes de teste automatizadas e contínuas. O Azure Pipelines é uma funcionalidade do Azure DevOps que lhe permite gerenciar CI/CD a fim de implantar seu código com pipelines de alto desempenho que funcionam com qualquer linguagem, plataforma e nuvem. O Azure Data Explorer – Pipeline Tools é a tarefa do Azure Pipelines que lhe permite criar pipelines de lançamento e implantar as alterações de banco de dados nos seus bancos de dados do Azure Data Explorer. Ele está disponível gratuitamente no Visual Studio Marketplace. Essa extensão inclui as seguintes tarefas básicas:
Azure Data Explorer Command – Executa comandos de administrador em um cluster do Azure Data Explorer
Azure Data Explorer Query – Executa consultas em um cluster do Azure Data Explorer e analisa os resultados
Azure Data Explorer Query Server Gate – Tarefa sem agente para controlar lançamentos, dependendo do resultado da consulta
Este documento descreve um exemplo simples sobre o uso da tarefa Azure Data Explorer – Pipeline Tools para implantar as alterações de esquema no seu banco de dados. Para pipelines de CI/CD completos, confira a Documentação do Azure DevOps.
Pré-requisitos
- Uma assinatura do Azure. Criar uma conta gratuita do Azure.
- Um cluster e um banco de dados do Azure Data Explorer. Criar um cluster e um banco de dados.
- Configuração do Cluster do Azure Data Explorer:
- Criar um aplicativo do Microsoft Entra provisionando um aplicativo do Microsoft Entra.
- Conceda acesso ao Aplicativo Microsoft Entra no banco de dados do Azure Data Explorer gerenciando as permissões de banco de dados do Azure Data Explorer.
- Configuração do Azure DevOps:
- Instalação da extensão:
Se você for o proprietário da instância do Azure DevOps, instale a extensão do Marketplace. Caso contrário, entre em contato com oproprietário da instância do Azure DevOps e peça para instalá-la.

Preparar seu conteúdo para o lançamento
Você pode usar os seguintes métodos para executar comandos de administrador em um cluster dentro de uma tarefa:
Usar um padrão de pesquisa para obter vários arquivos de comando de uma pasta do agente local (fontes de build ou artefatos de lançamento)

Escreva os comandos de modo embutido
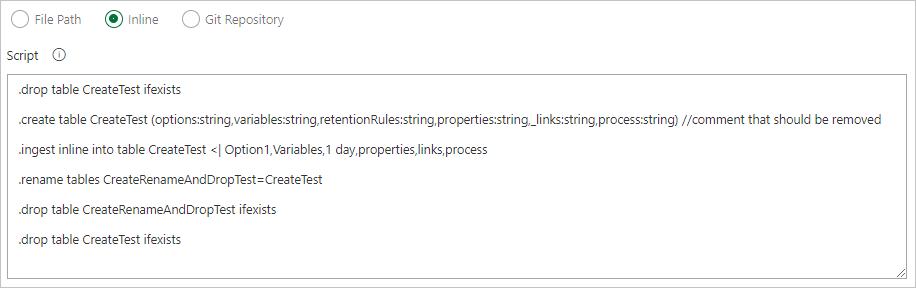
Especificar um caminho de arquivo para obter arquivos de comando diretamente do controle do código-fonte do Git (recomendado)
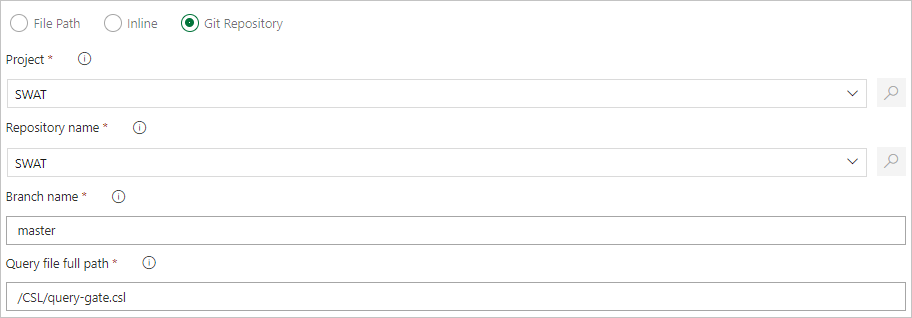
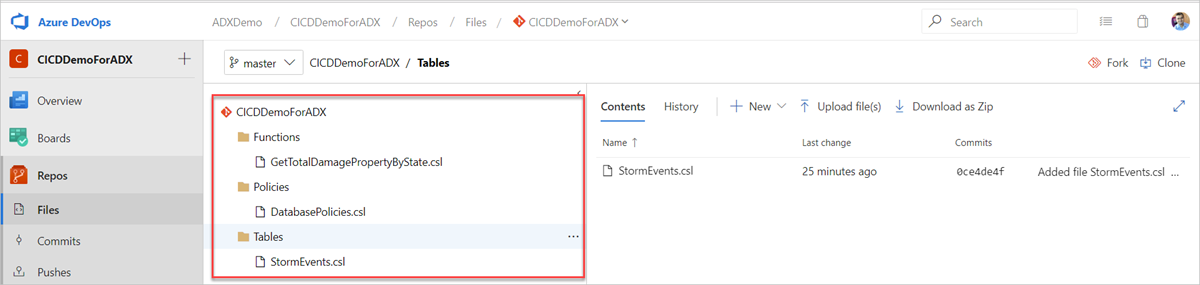
Crie as pastas de exemplo a seguir (Functions, Policies e Tables) em seu repositório do Git. Copie os arquivos do repositório de amostras para as respectivas pastas e confirme as alterações. Os arquivos de exemplo são fornecidos para executar o fluxo de trabalho a seguir.
Dica
Ao criar seu fluxo de trabalho, recomendamos tornar seu código idempotente. Por exemplo, use
.create-merge tableem vez de.create tablee use a função.create-or-alterem vez da função.create.
Criar um pipeline de lançamento
Entre na sua organização do Azure DevOps.
Selecione Pipelines>Releases (Pipelines > Lançamentos) no menu à esquerda e escolha New pipeline (Novo pipeline).
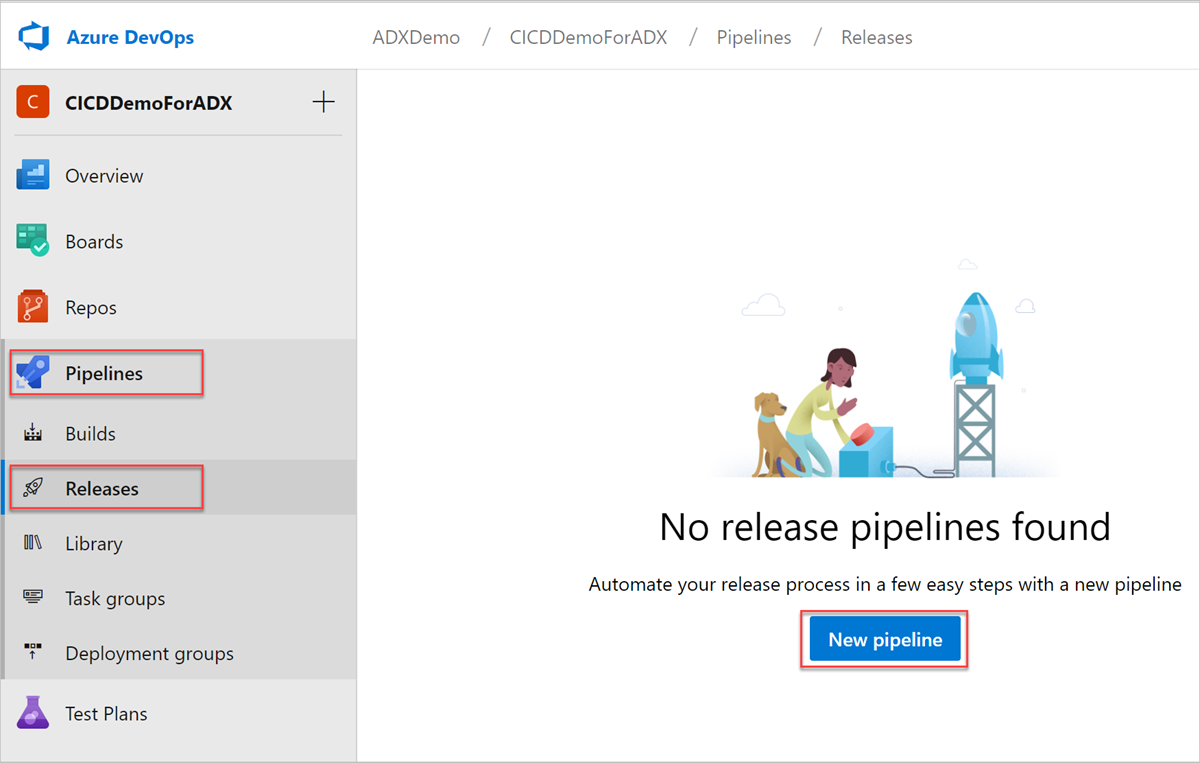
A janela New release pipeline (Novo pipeline de lançamento) é exibida. Na guia Pipelines, no painel Select a template (Selecionar um modelo), escolha Empty job (Trabalho vazio).
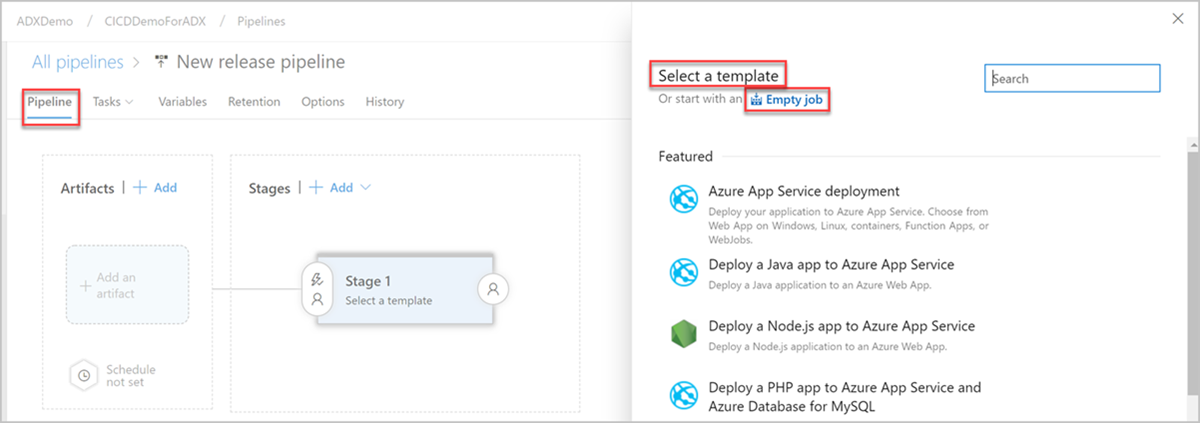
Selecione o botão Stage (Estágio). No painel Stage (Estágio), adicione o Stage name (Nome do estágio). Selecione Save (Salvar) para salvar seu pipeline.
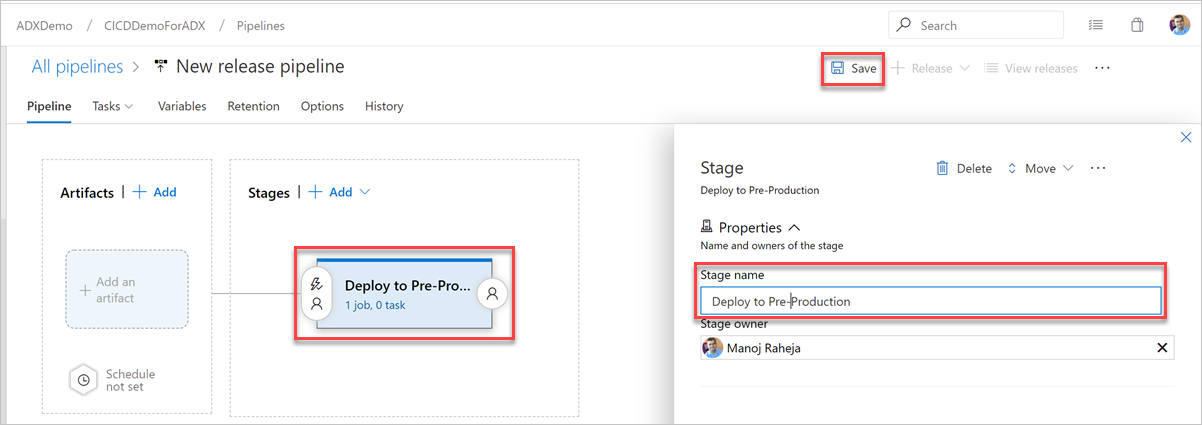
Selecione o botão Add an artifact (Adicionar um artefato). No painel Adicionar um artefato, selecione o repositório em que o código existe, preencha as informações relevantes e clique em Adicionar. Selecione Save (Salvar) para salvar seu pipeline.
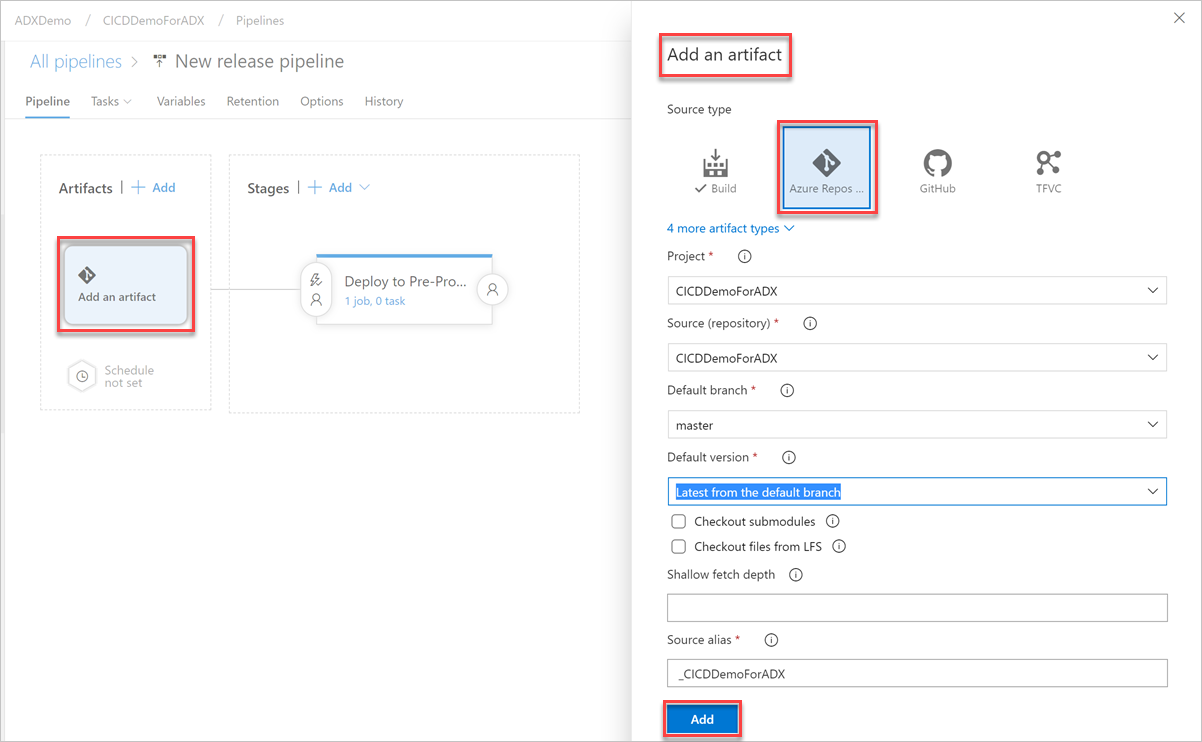
Na guia Variáveis, selecione + Adicionar para criar uma variável para a URL do ponto de extremidade que será usada na tarefa. Escreva o Name (Nome) e o Value (Valor) do ponto de extremidade. Selecione Save (Salvar) para salvar seu pipeline.
Para localizar a URL do ponto de extremidade, acesse a página de visão geral do cluster do Azure Data Explorer no portal do Azure e copie o URI do cluster. Construa o URI da variável no formato
https://<ClusterURI>?DatabaseName=<DBName>a seguir. Por exemplo, https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB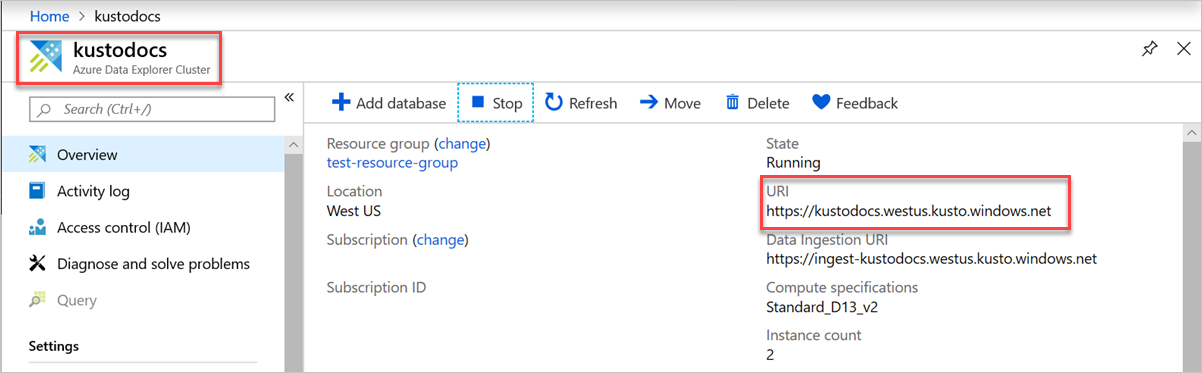
Criar uma tarefa para implantar as pastas
Na guia Pipeline, clique em 1 tranalho, 0 tarefa para adicionar tarefas.
Repita as seguintes etapas para criar tarefas de comando a fim de implantar arquivos das pastas Tables, Functions e Policies:
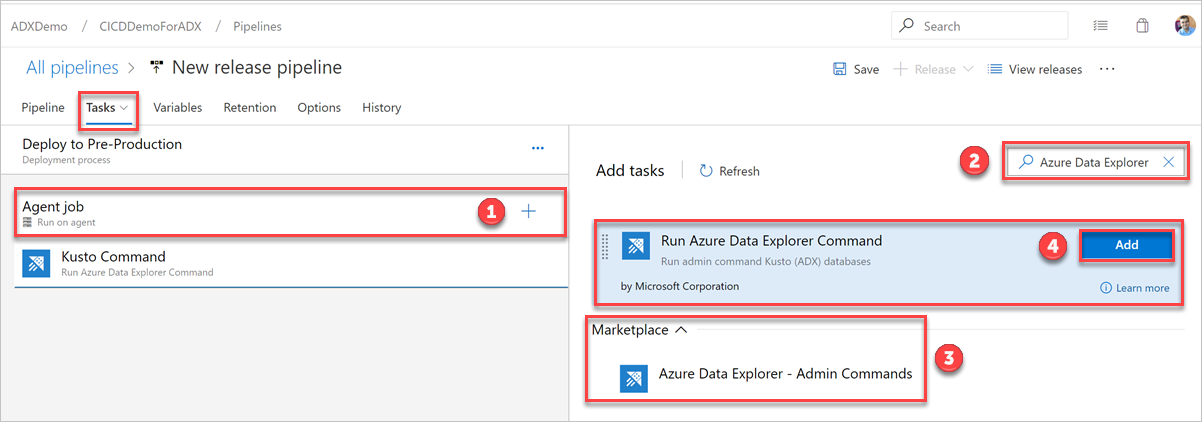
Na guia Tasks (Tarefas), selecione + por Agent job (Trabalho do Agente) e pesquise Azure Data Explorer.
Em Run Azure Data Explorer Command (Executar o Comando do Azure Data Explorer), selecione Add (Adicionar).
Selecione Kusto Command (Comando da Kusto) e atualize a tarefa com as seguintes informações:
Display name (Nome de exibição): nome da tarefa. Por exemplo,
Deploy <FOLDER>, em que<FOLDER>é o nome da pasta para a tarefa de implantação que você está criando.File path (Caminho do arquivo): para cada pasta, especifique o caminho como
*/<FOLDER>/*.csl, em que<FOLDER>é a pasta relevante para a tarefa.Endpoint URL (URL do ponto de extremidade): especifique as
EndPoint URLvariáveis criadas na etapa anterior.Use Service Endpoint (Usar o Ponto de Extremidade de Serviço): selecione esta opção.
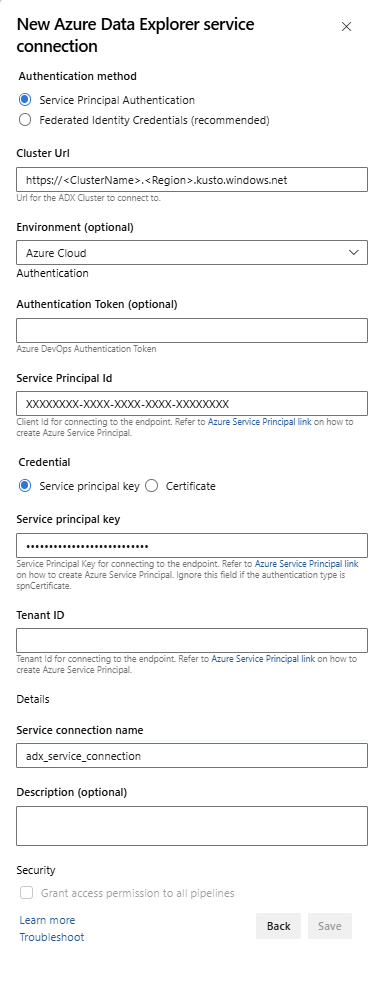
Service Endpoint (Ponto de Extremidade de Serviço): selecione um ponto de extremidade de serviço existente ou crie um do zero (+ New [+Novo]) fornecendo as seguintes informações na janela Add Azure Data Explorer service connection (Adicionar conexão de serviço do Azure Data Explorer):
Configuração Valor sugerido Método de autenticação Configure as Credenciais de Identidade Federadas (FIC) (recomendado) ou Selecione a Autenticação da Entidade de Serviço (SPA). Nome da conexão Insira um nome para identificar esse ponto de extremidade de serviço Cluster Url (URL do cluster) O valor pode ser encontrado na seção de visão geral do Cluster do Azure Data Explorer no portal do Azure Service Principal (ID da Entidade de Serviço) Insira a ID do Aplicativo Microsoft Entra (criada como pré-requisito) Service Principal App Key (Chave de Aplicativo da Entidade de Serviço) Insira a Chave do Aplicativo Microsoft Entra (criada como pré-requisito) ID de locatário do Microsoft Entra Insira seu locatário do Microsoft Entra (como microsoft.com ou contoso.com)
Selecione a caixa de seleção Allow all pipelines to use this connection (Permitir que todos os pipelines usem essa conexão) e escolha OK.
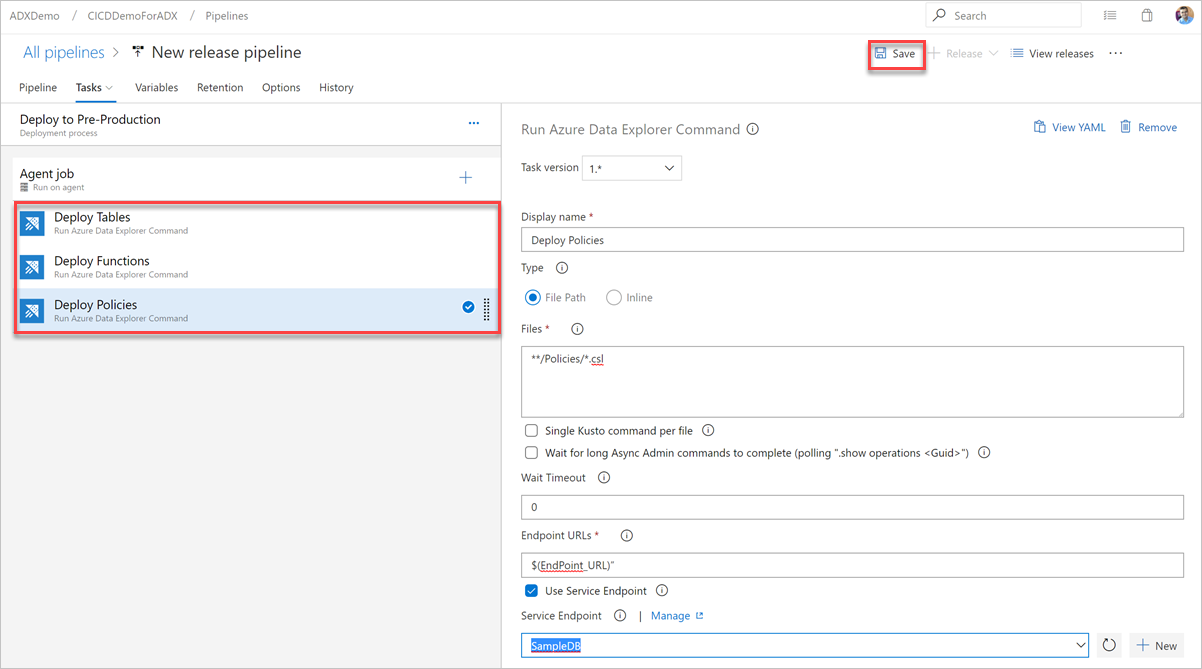
Selecione Save (Salvar) e, em seguida, na guia Tasks (Tarefas), verifique se há três tarefas: Deploy Tables (Implantar Tables), Deploy Functions (Implantar Functions) e Deploy Policies (Implantar Policies).
Criar uma tarefa de consulta
Se necessário, crie uma tarefa para executar uma consulta no cluster. A execução de consultas em um Pipeline de Build ou de Lançamento pode ser usada para validar um conjunto de dados e checar se uma etapa é bem-sucedida ou falha com base nos resultados da consulta. Os critérios de sucesso das tarefas podem ser baseados em um limite de contagem de linhas ou em apenas um valor, dependendo do retorno da consulta.
Na guia Tasks (Tarefas), selecione + por Agent job (Trabalho do Agente) e pesquise Azure Data Explorer.
Em Run Azure Data Explorer Query (Executar Azure Data Explorer Query), selecione Add (Adicionar).
Selecione Kusto Query (Consulta da Kusto) e atualize a tarefa com as seguintes informações:
- Display name (Nome de exibição): nome da tarefa. Por exemplo, Query cluster (Cluster de consulta).
- Type (Tipo): selecione Inline (Embutido).
- Query (Consulta): insira a consulta que deseja executar.
- Endpoint URL (URL do ponto de extremidade): especifique as variáveis
EndPoint URLcriadas anteriormente. - Use Service Endpoint (Usar o Ponto de Extremidade de Serviço): selecione esta opção.
- Service Endpoint (Ponto de extremidade de serviço): selecione um ponto de extremidade de serviço.
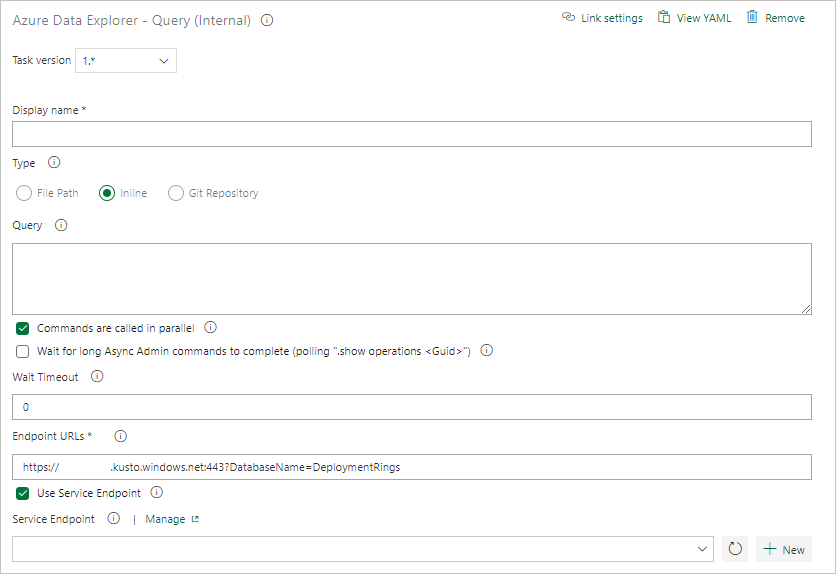
Em Task Results (Resultados da Tarefa), selecione os critérios de sucesso da tarefa com base nos resultados da consulta, da seguinte forma:
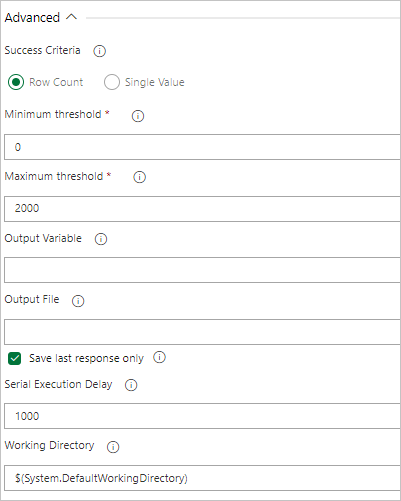
Se a consulta retornar linhas, selecione Row Count (Contagem de Linhas) e forneça os critérios necessários.
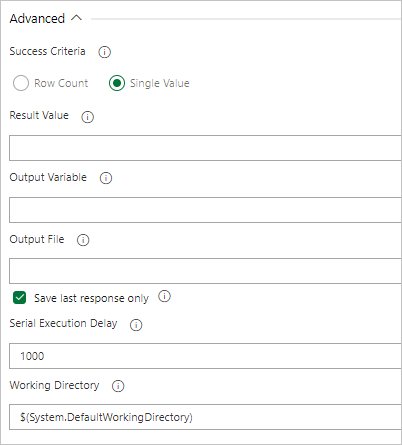
Se a consulta retornar um valor, selecione Single Value (Valor único) e forneça o resultado esperado.
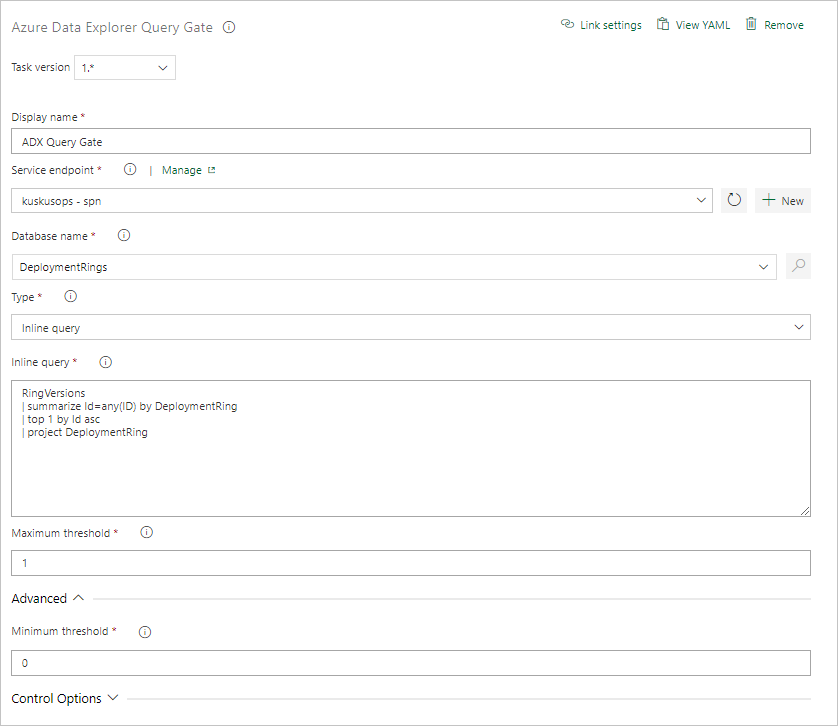
Criar uma tarefa Query Server Gate
Se necessário, crie uma tarefa para executar uma consulta em um cluster e controlar o andamento do lançamento pendente da Contagem de Linhas dos Resultados da Consulta. A tarefa Query Server Gate é um trabalho sem agente, o que significa que a consulta é executada diretamente no Azure DevOps Server.
Na guia Tasks (Tarefas), selecione + por Agentless job (Trabalho sem agente) e pesquise Azure Data Explorer.
Em Run Azure Data Explorer Query Server Gate (Executar Query Server Gate do Azure Data Explorer), selecione Add (Adicionar).
Selecione Kusto Query Server Gate (Query Server Gate da Kusto) e escolha Server Gate Test (Teste de Server Gate).
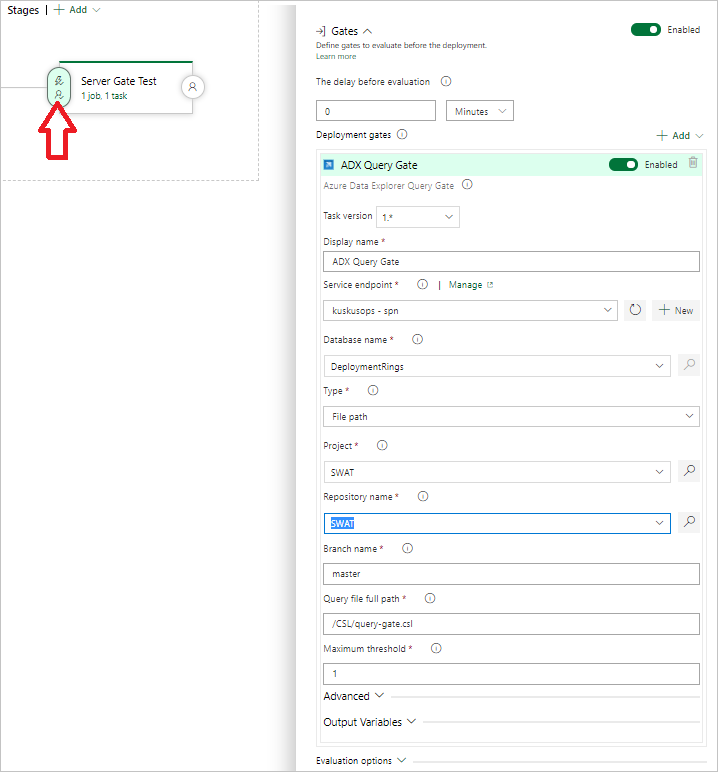
Configure a tarefa fornecendo as seguintes informações:
- Display name (Nome de exibição): nome do portão.
- Service Endpoint (Ponto de extremidade de serviço): selecione um ponto de extremidade de serviço.
- Database name (Nome do banco de dados): especifique o nome do banco de dados.
- Type (Tipo): selecione Inline query (Consulta embutida).
- Query (Consulta): insira a consulta que deseja executar.
- Maximum threshold (Limite máximo): especifique a contagem máxima de linhas para os critérios de sucesso da consulta.
Observação
Você deverá ver resultados como a seguir ao executar a versão.
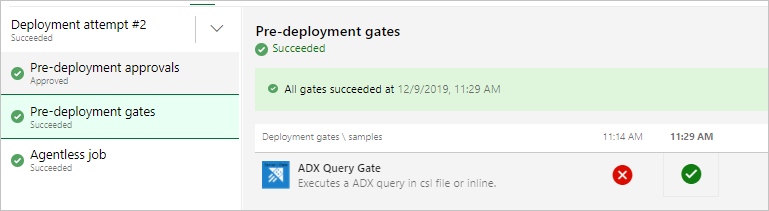
Executar a versão
Selecione + Release>Create release (+ Versão > Criar versão) para criar uma versão.
Na guia Logs, verifique se o status da implantação foi bem-sucedido.
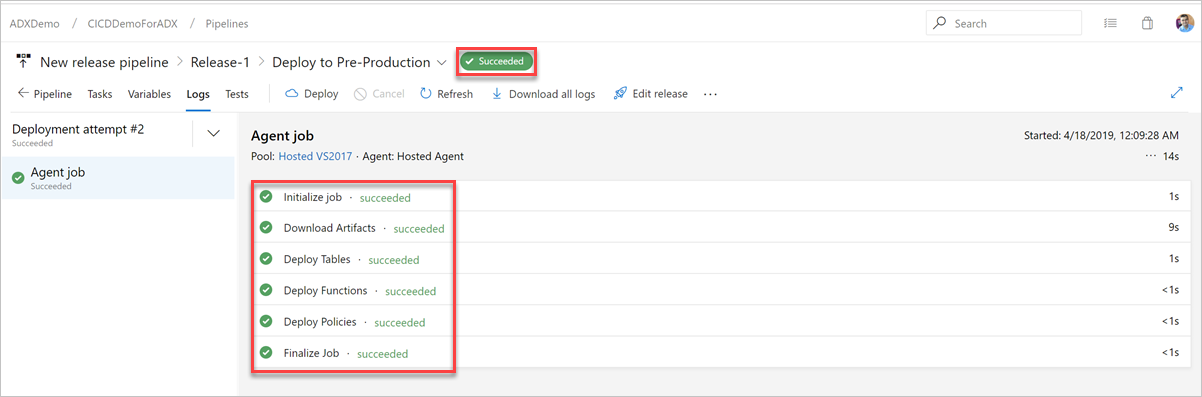
Agora, a criação de um pipeline de lançamento para implantação na pré-produção está concluída.
Suporte à autenticação sem chave para tarefas do DevOps do Azure Data Explorer
A extensão dá suporte à autenticação sem chave para clusters do Azure Data Explorer. A autenticação sem chave permite que você se autentique em clusters do Azure Data Explorer sem usar uma chave e é mais segura e fácil de gerenciar do que usar uma chave.
Usar a autenticação Credenciais de Identidade Federadas (FIC) em uma conexão de serviço do Azure Data Explorer
Em sua instância do DevOps, acesse Configurações de Projeto>Conexões de Serviço>Noca Conexão de Serviço>Azure Data Explorer.
Selecione Credenciais de Identidade Federadas e insira a URL do cluster, a ID da entidade de serviço, a ID do locatário, um nome de conexão de serviço e, em seguida, selecione Salvar.
No portal do Azure, abra o aplicativo Microsoft Entra para a entidade de serviço especificada.
Em Certificados e segredos, selecione Credenciais Federadas.
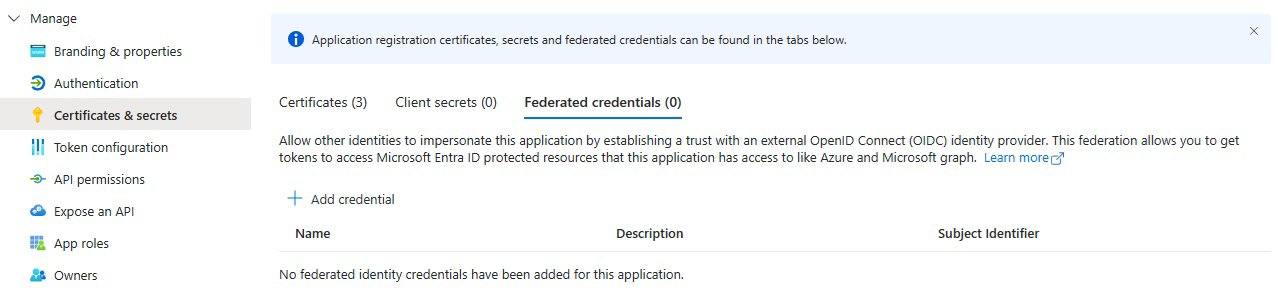
Selecione Adicionar credencial e, em seguida, para oCenário de credencial federada, selecione Outro emissor e preencha as configurações usando as seguintes informações:
Emissor:
<https://vstoken.dev.azure.com/{System.CollectionId}>em que{System.CollectionId}é a ID da coleção da sua organização do Azure DevOps. Você pode encontrar a ID da coleção das seguintes maneiras:- No pipeline de lançamento clássico do Azure DevOps, selecione Inicializar trabalho. A ID da coleção é exibida nos logs.
Identificador de assunto:
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>em que{DevOps_Org_name}é o nome da organização do Azure DevOps,{Project_Name}é o nome do projeto e{Service_Connection_Name}é o nome da conexão de serviço que você criou anteriormente.Observação
Se houver espaço no nome da conexão de serviço, você poderá usá-lo com espaço no campo. Por exemplo:
sc://MyOrg/MyProject/My Service Connection.Nome: insira um nome para a credencial.
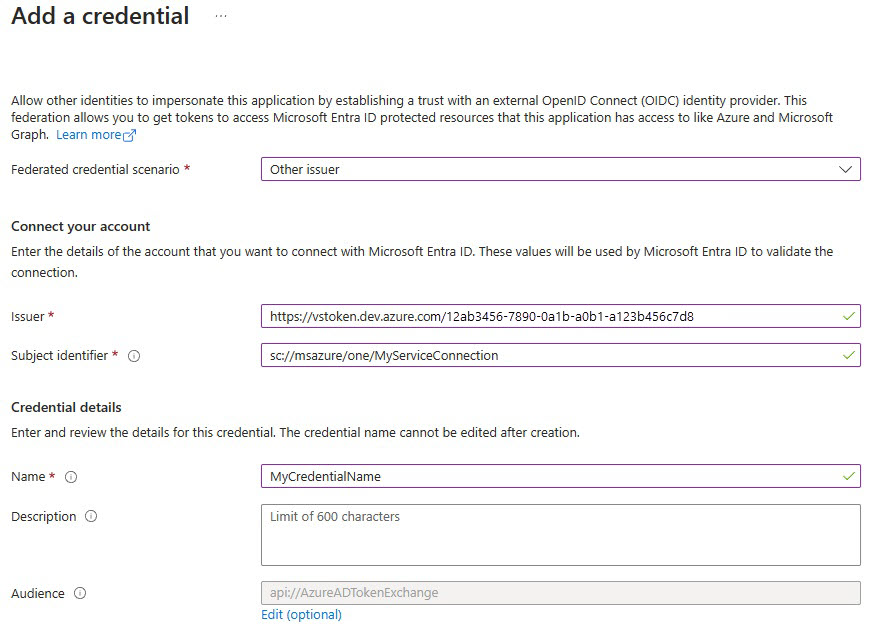
Selecione Adicionar.
Usar credenciais de identidade federadas ou identidade gerenciada em uma conexão de serviço do Azure Resource Manager (ARM)
Em sua instância do DevOps, acesse Configurações de Projeto>Conexões de Serviço>Nova conexão de serviço>Azure Resource Manager.
Em Método de Autenticação, selecione Federação de Identidade de Carga de Trabalho (automática). Como alternativa, você pode usar a opção manual Federação de Identidade de Carga de Trabalho (manual) para especificar os detalhes da Federação de Identidade de Carga de Trabalho ou usar a opção Identidade Gerenciada. Para obter mais informações sobre como configurar uma identidade gerenciada usando o Gerenciamento de Recursos do Azure, consulte Conexões de Serviço do Azure Resource Manager (ARM).
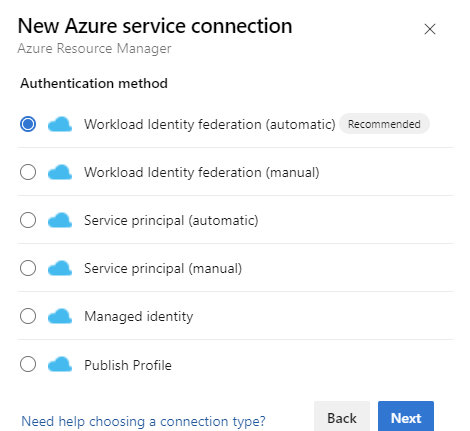
Preencha os detalhes necessários, selecione Verificar e, em seguida, selecione Salvar.
Configuração do pipeline do Yaml
As tarefas podem ser configuradas por meio da interface do usuário da Web do Azure DevOps e por meio de código Yaml, dentro do esquema de pipeline
Exemplo de uso de comando de administrador
steps:
- task: Azure-Kusto.PublishToADX.PublishToADX.PublishToADX@4
displayName: '<Task Name>'
inputs:
targetType: 'inline'
script: '<inline Script>'
waitForOperation: true
kustoUrls: '$(CONNECTIONSTRING):443?DatabaseName=""'
authType: 'armserviceconn'
connectedServiceARM: '<ARM Service Endpoint Name>'
serialDelay: 1000
continueOnError: true
condition: ne(variables['ProductVersion'], '') ## Custom condition Sample
Exemplo de uso da consulta
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@4
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DataBaneName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true