Modo de depuração do fluxo de dados de mapeamento
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Visão geral
O modo de depuração do fluxo de dados de mapeamento do Azure Data Factory e do Synapse Analytics permite que você visualize de forma interativa a transformação da forma de dados enquanto constrói e depura seus fluxos de dados. A sessão de depuração pode ser usada em sessões de design do Fluxo de Dados e durante a execução de depuração de pipeline de fluxos de dados. Para ativar o modo de depuração, use o botão Depuração de Fluxo de Dados na barra superior da tela do fluxo de dados ou do pipeline quando tiver atividades de fluxo de dados.
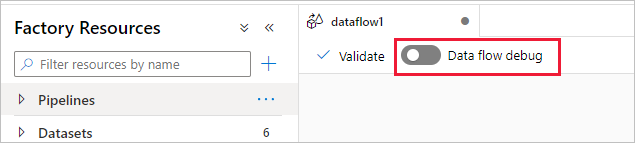

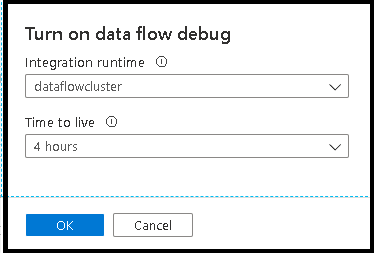
Depois de ativar o controle deslizante, será solicitado que você selecione qual configuração de runtime de integração você deseja usar. Se AutoResolveIntegrationRuntime for escolhido, um cluster com oito núcleos de computação geral com um padrão de vida útil de 60 minutos será rotacionado. Se você quiser permitir mais equipe ociosa antes que sua sessão expire, poderá escolher uma configuração de TTL mais alta. Para obter mais informações sobre runtimes de integração de fluxo de dados, veja Desempenho do Integration Runtime.
Quando o modo de depuração estiver ativado, você criará interativamente o seu fluxo de dados com um cluster do Spark ativo. A sessão será fechada quando você desativar a depuração. Você deve estar ciente das cobranças por hora incorridas pelo Data Factory durante o tempo em que a sessão de depuração está ativa.
Na maioria dos casos, recomenda-se criar seus fluxos de dados no modo de depuração para que você possa validar sua lógica de negócios e visualizar as transformações de dados antes de publicar seu trabalho. Use o botão "Depurar" no painel de pipeline para testar o fluxo de dados em um pipeline.
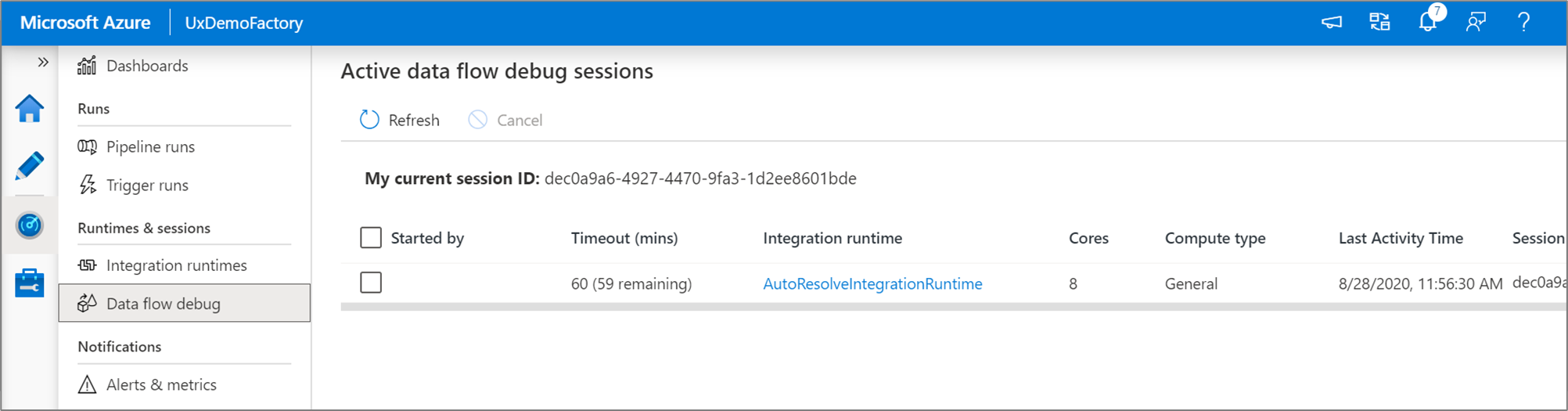
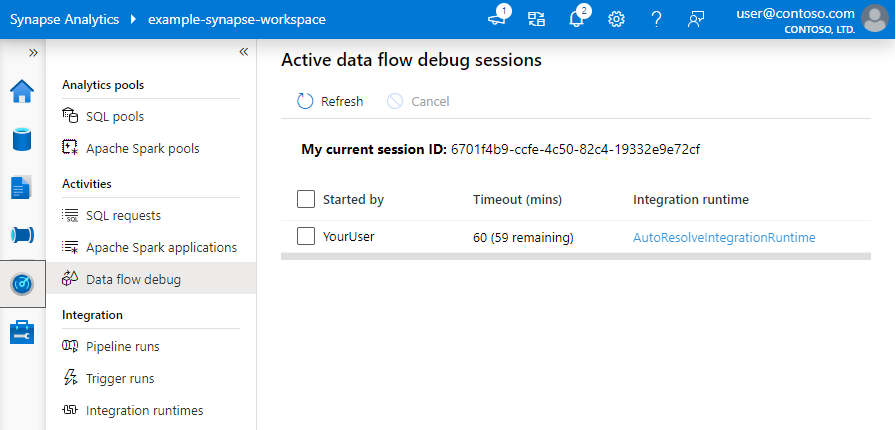
Observação
Cada sessão de depuração que um usuário inicia da interface do usuário do navegador é uma nova sessão com o próprio cluster do Spark. Você pode usar o modo de exibição de monitoramento em sessões de depuração mostradas nas imagens anteriores para exibir e gerenciar sessões de depuração. Você é cobrado por cada hora que cada sessão de depuração está executando, incluindo o tempo de TTL.
Este videoclipe exibe dicas, truques e boas práticas do modo de depuração de fluxo de dados.
Status do cluster
O indicador de status de cluster na parte superior da superfície de design que fica verde quando o cluster está pronto para depuração. Se o seu cluster já estiver em espera passiva, o indicador verde aparecerá quase que instantaneamente. Se o cluster ainda não estava em execução quando você inseriu o modo de depuração, o cluster do Spark executará uma inicialização a frio. O indicador gira até que o ambiente esteja pronto para depuração interativa.
Quando terminar de usar a depuração, desative a opção de depuração para que o cluster do Spark possa ser encerrado, assim você não será mais cobrado pela atividade de depuração.
Configurações de depuração
Depois de ativar o modo de depuração, você poderá editar como um fluxo de dados visualiza os dados. Para editar as configurações de depuração, clique em "Configurações de depuração" na barra de ferramentas da tela Fluxo de dados. Você pode selecionar o limite de linha ou a fonte de arquivo a usar para cada uma das transformações de Fonte aqui. Os limites de linha nessa configuração são apenas para a sessão de depuração atual. Você também pode selecionar o serviço vinculado de preparo a ser usado para uma fonte do Azure Synapse Analytics.
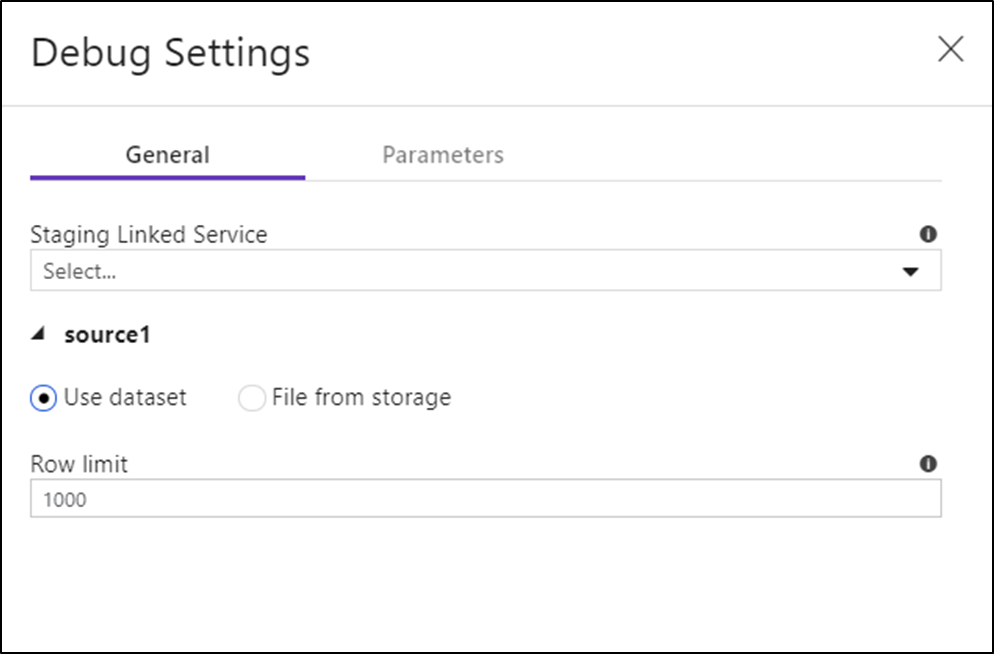
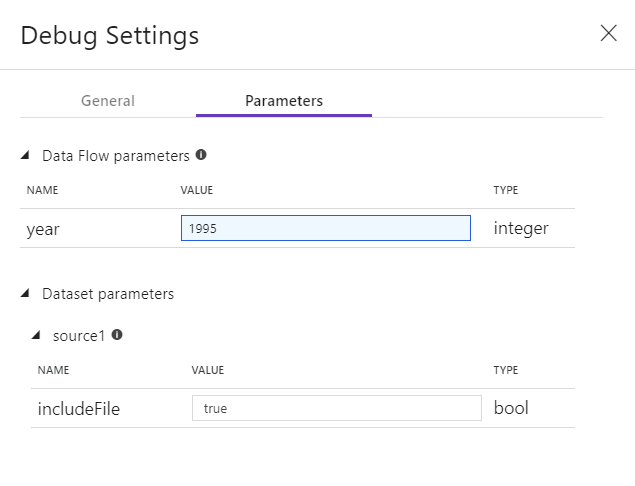
Se você tiver parâmetros em seu Fluxo de Dados ou em qualquer um de seus conjuntos de dados referenciados, poderá especificar quais valores usar durante a depuração selecionando a guia Parâmetros.
Use as configurações de amostragem aqui para apontar para exemplos de arquivos ou exemplos de tabelas de dados, de modo que você não precise alterar os conjuntos de dados de origem. Usando um arquivo ou tabela de exemplo aqui, você pode manter as mesmas configurações de lógica e propriedade no fluxo de dados durante o teste em um subconjunto de dados.
O IR padrão usado para o modo de depuração em fluxos de dados é um pequeno nó de trabalho único de 4 núcleos com um nó de driver único de 4 núcleos. Isso funciona bem com amostras menores de dados ao se testar a lógica de fluxo de dados. Se você expandir os limites de linha nas configurações de depuração durante a pré-visualização de dados ou definir um número maior de linhas de amostra na origem durante a depuração do pipeline, então é aconselhável considerar a definição de um ambiente de computação maior em um novo Azure Integration Runtime. Em seguida, você poderá reiniciar a sessão de depuração usando o ambiente de computação maior.
Visualização dos dados
Com a depuração ativa, a guia Pré-visualização de dados fica iluminada no painel inferior. Sem o modo de depuração ativo, o Fluxo de Dados mostra apenas os metadados atuais dentro e fora de cada uma de suas transformações na guia Inspecionar. A pré-visualização de dados consultará apenas o número de linhas definidas como seu limite nas configurações de depuração. Clique em Atualizar para atualizar a pré-visualização de dados com base em suas transformações atuais. Se os dados de origem tiverem sido alterados, selecione Atualizar > Buscar novamente na origem.
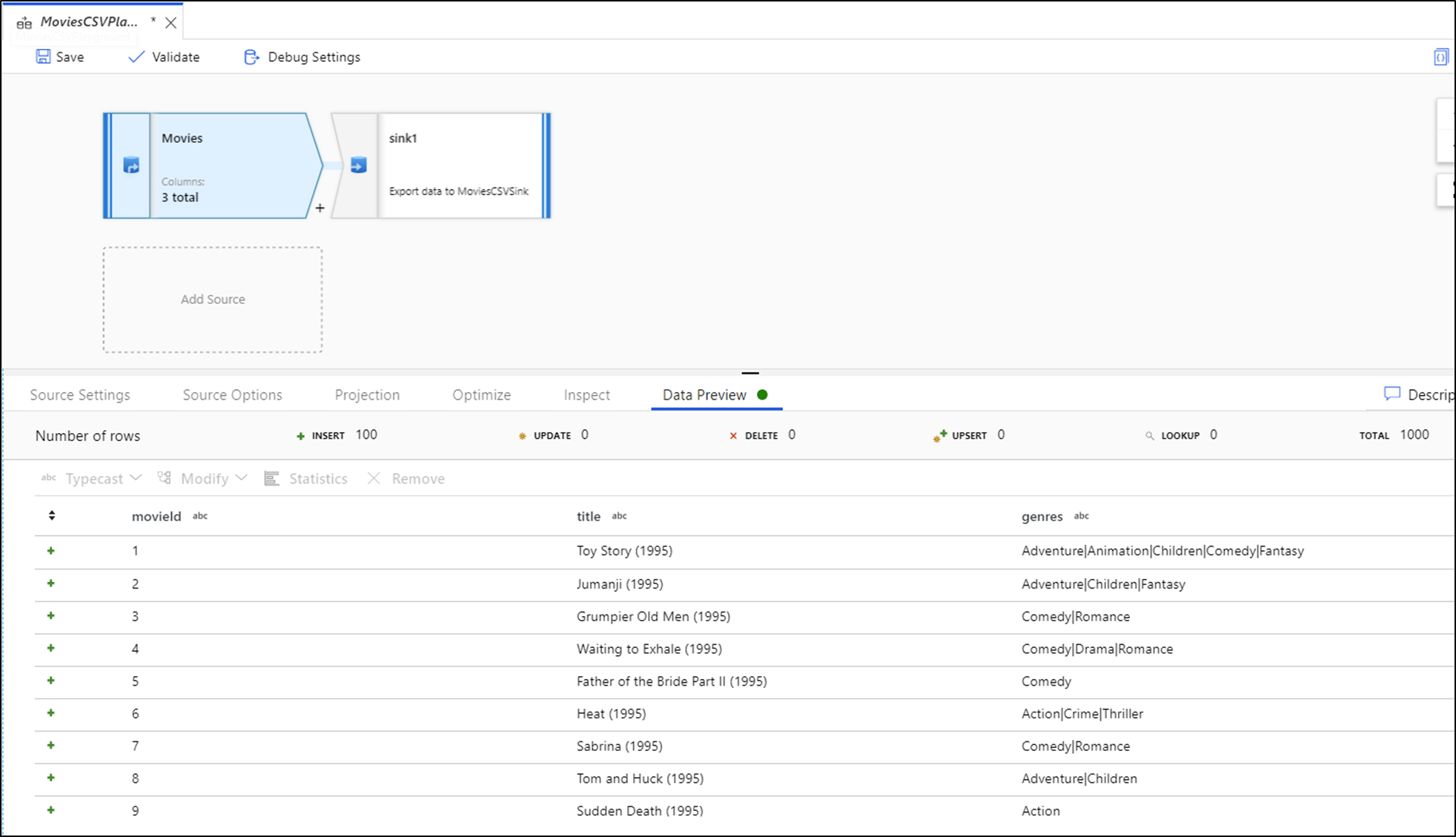
Você pode classificar as colunas na visualização de dados e reorganizar as colunas usando arrastar e soltar. Além disso, há um botão de exportação na parte superior do painel de pré-visualização de dados que você pode usar para exportar os dados de pré-visualização para um arquivo CSV a fim de fazer a exploração de dados offline. Esse recurso pode ser usado para exportar até 1.000 linhas de dados de visualização.
Observação
As fontes de arquivo limitam apenas as linhas que você vê, não as linhas que estão sendo lidas. Para conjuntos de dados muito grandes, é recomendado que você pegue uma pequena parte desse arquivo e a use para o seu teste. Você pode selecionar um arquivo temporário nas configurações de depuração para cada fonte que seja um tipo de conjunto de dados de arquivo.
Ao executar no modo de depuração no Fluxo de Dados, seus dados não são gravados na transformação de Coletor. Uma sessão de depuração destina-se a servir como um agente de teste para suas transformações. Os coletores não são necessários durante a depuração e são ignorados no fluxo de dados. Se você quer testar a gravação dos dados em seu Coletor, execute o Fluxo de Dados de um pipeline e use a execução da Depuração de um pipeline.
A visualização de dados é um instantâneo dos dados transformados usando limites de linha e amostragem de dados de quadros de dados na memória do Spark. Portanto, os drivers de coletor não são utilizados nem testados nesse cenário.
Observação
A Visualização de Dados exibe a hora de acordo com a configuração de localidade do navegador.
Testando condições de junção
Ao fazer teste de unidade de transformações de Junções, Exists ou Pesquisa, use um pequeno conjunto de dados conhecidos para o teste. Você pode usar a opção Configurações de depuração descritos anteriormente para definir um arquivo temporário a ser usado para o teste. Isso é necessário porque, ao limitar ou fazer amostragem de linhas de um grande conjunto de dados, não é possível prever quais linhas e quais chaves serão lidas no fluxo para o teste. O resultado é não determinístico e isso significa que suas condições de junção podem falhar.
Ações rápidas
Depois de ver a visualização de dados, você poderá gerar uma transformação rápida para conversão, remoção ou modificação em uma coluna. Clique no cabeçalho da coluna e selecione uma das opções da barra de ferramentas de pré-visualização de dados.
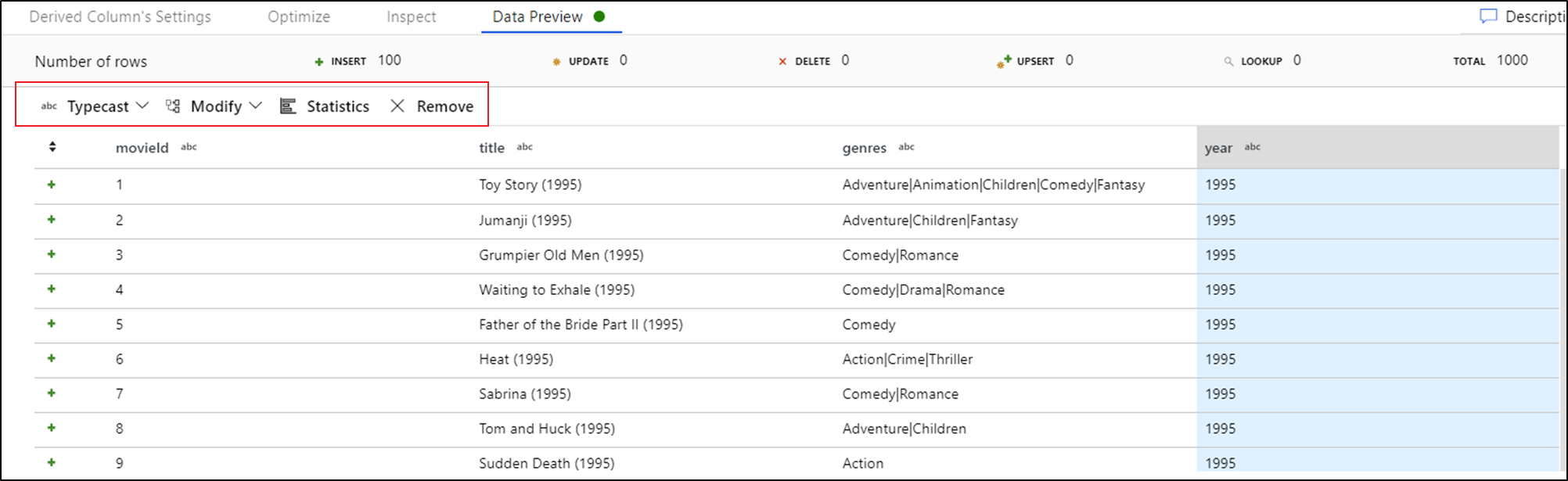
Depois de selecionar uma modificação, a visualização de dados será atualizada imediatamente. Selecione Confirmar no canto superior direito para gerar uma nova transformação.
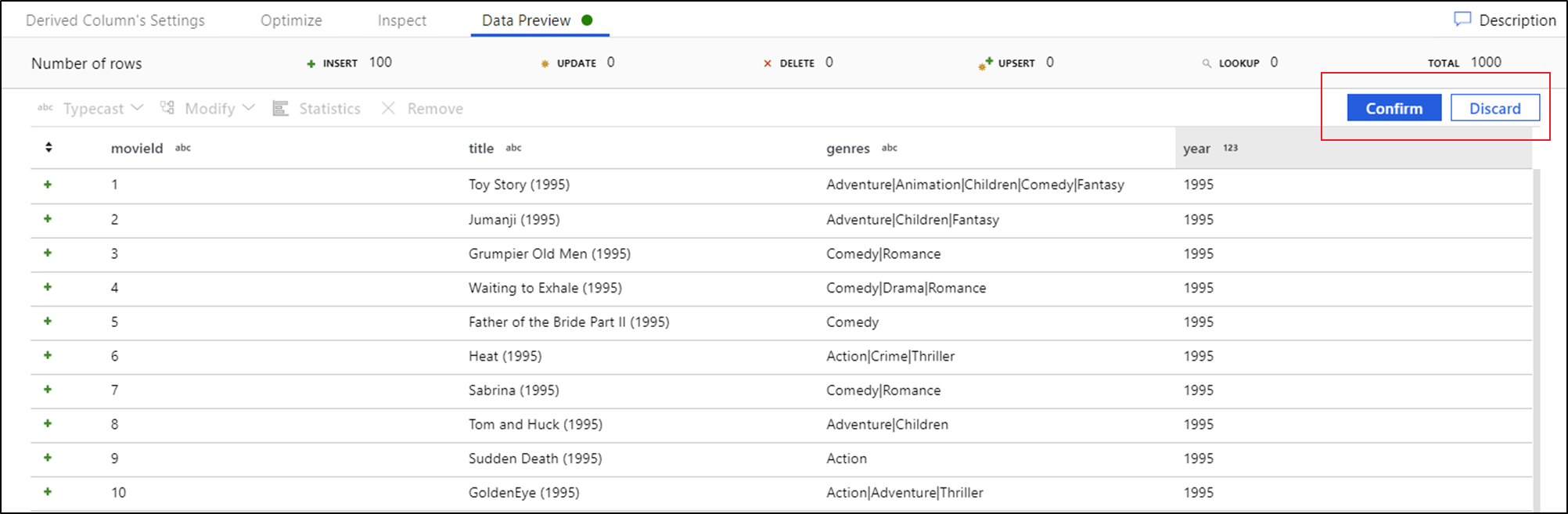
Typecast e Modify geram uma transformação de coluna derivada e Remove gera uma transformação Select.
Observação
Se você editar o fluxo de dados, precisará buscar novamente a visualização de dados antes de adicionar uma transformação rápida.
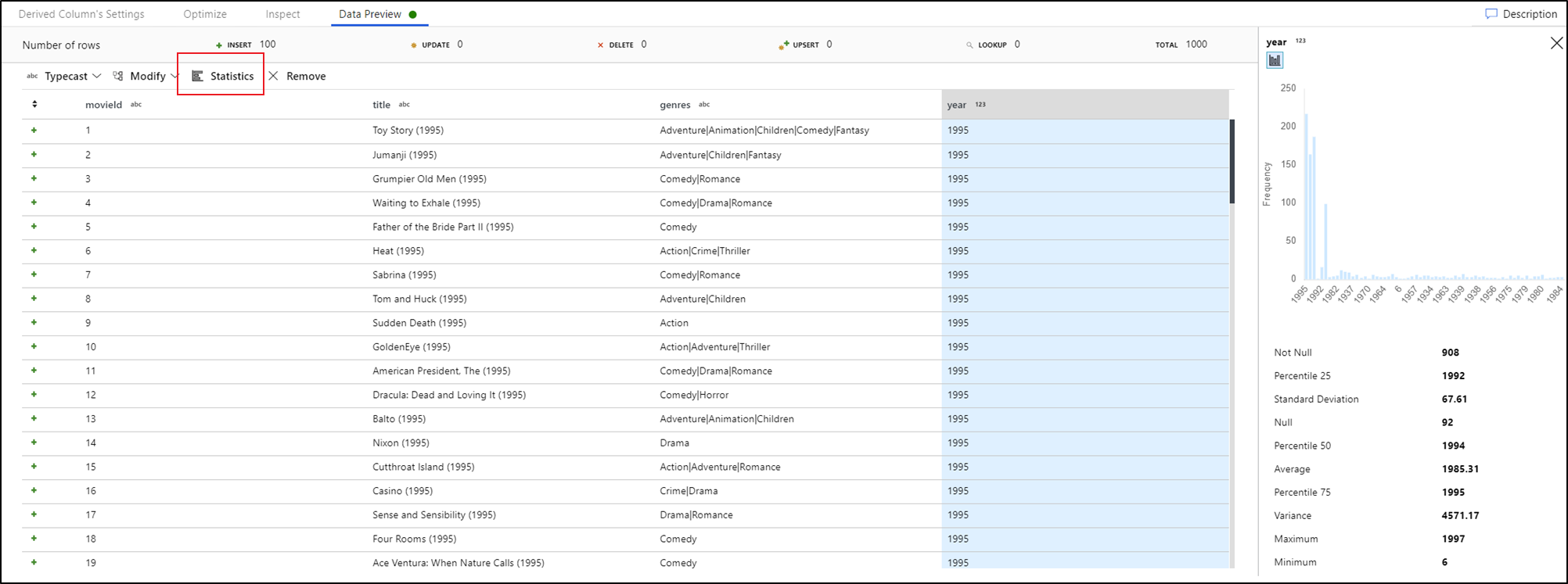
Criação de perfil de dados
Selecionar uma coluna na guia Pré-visualização de dados e clicar em Estatísticas na barra de ferramentas de pré-visualização de dados exibirá um gráfico mais à direita da grade de dados com estatísticas detalhadas sobre cada campo. O serviço toma uma decisão com base na amostragem de dados do tipo de gráfico a ser exibido. Os campos de cardinalidade alta são padronizados para gráficos NULO/NÃO NULO, enquanto os dados categóricos e numéricos com baixa cardinalidade exibem gráficos de barras mostrando a frequência do valor dos dados. Você também verá o comprimento mín./máx. dos campos de cadeias de caracteres, valores mín./máx. dos campos numéricos, desvio padrão, percentuais, contagens e média.
Conteúdo relacionado
- Depois de concluir a criação e a depuração do fluxo de dados, execute-o em um pipeline.
- Ao testar o pipeline com um fluxo de dados, use a opção Depurar a execução do pipeline.