Copiar dados do Amazon RDS para Oracle usando o Azure Data Factory ou o Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade Copy no Azure Data Factory para copiar dados de um banco de dados do Amazon RDS para Oracle. Ele se baseia na Visão geral da atividade Copy.
Funcionalidades com suporte
Há suporte para o conector do Amazon RDS para Oracle para as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/-) | 6/6 |
| Atividade de pesquisa | 6/6 |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Para obter uma lista de armazenamentos de dados que têm suporte como fontes ou coletores da atividade de cópia, confira a tabela Armazenamentos de dados com suporte.
Especificamente, esse conector do Amazon RDS para Oracle dá suporte a:
- As seguintes versões de um banco de dados do Amazon RDS para Oracle:
- Amazon RDS para Oracle 19c R1 (19.1) e versões superiores
- Amazon RDS para Oracle 18c R1 (18.1) e versões superiores
- Amazon RDS para Oracle 12c R1 (12.1) e versões superiores
- Amazon RDS para Oracle 11g R1 (11.1) e versões superiores
- Cópia paralela de uma fonte do Amazon RDS para Oracle. Confira a seção Cópia paralela do Amazon RDS para Oracle para obter detalhes.
Observação
Não há suporte para o servidor proxy do Amazon RDS para Oracle.
Pré-requisitos
Se o armazenamento de dados estiver localizado dentro de uma rede local, em uma rede virtual do Azure ou na Amazon Virtual Private Cloud, você precisará configurar um runtime de integração auto-hospedada para se conectar a ele.
Se o armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Azure Integration Runtime. Se o acesso for restrito aos IPs que estão aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de runtime de integração da rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um runtime de integração auto-hospedada.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções compatíveis com o Data Factory, consulte Estratégias de acesso a dados.
O runtime de integração fornece um driver interno do Amazon RDS para Oracle. Portanto, você não precisa instalar manualmente um driver quando você copia dados do Amazon RDS para Oracle.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
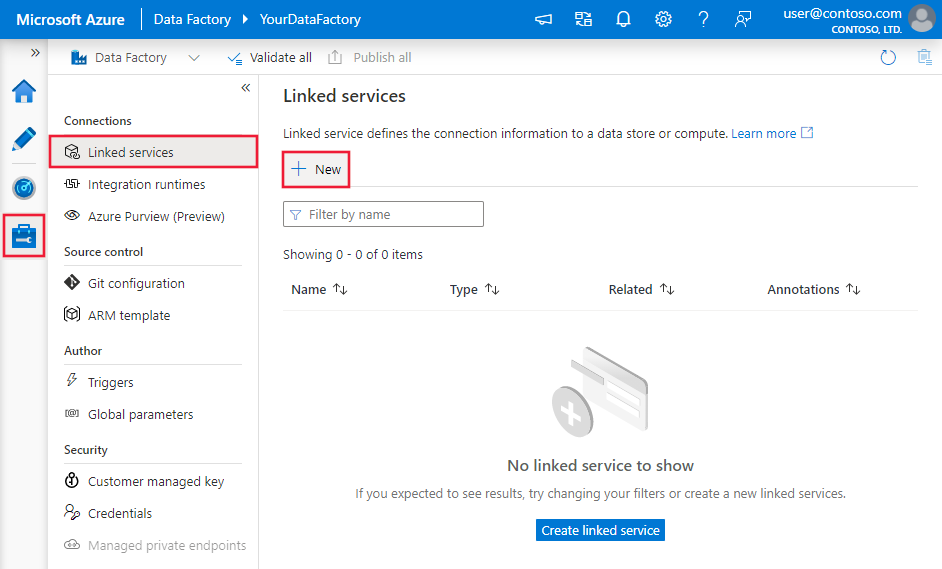
Criar um serviço vinculado ao Amazon RDS para Oracle usando a interface do usuário
Use as etapas abaixo para criar um serviço vinculado ao Amazon RDS para Oracle na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar no workspace do Azure Data Factory ou do Synapse e selecione Serviços Vinculados. Depois, clique em Novo:
Pesquise Amazon RDS para Oracle e selecione o conector do Amazon RDS para Oracle.

Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.


Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades específicas do conector do Amazon RDS para Oracle.
Propriedades do serviço vinculado
O serviço vinculado do Amazon RDS para Oracle dá suporte às seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type precisa ser definida como: AmazonRdsForOracle. | Sim |
| connectionString | Especifica as informações necessárias para se conectar à instância do Amazon RDS para Oracle Database. Você também pode colocar uma senha no Azure Key Vault e extrair a configuração password da cadeia de conexão. Veja os exemplos a seguir e Armazenar credenciais no Azure Key Vault para obter mais detalhes. Tipo de conexão com suporte: você pode usar a SID do Amazon RDS para Oracle ou o Nome do Serviço do Amazon RDS para Oracle para identificar o banco de dados: -Se você usar a SID: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;-Se você usar Service Name: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;Para opções de avançadas de conexão nativa do Amazon RDS para Oracle, você pode optar por adicionar uma entrada no arquivo TNSNAMES.ORA no servidor do Amazon RDS para Oracle e, no serviço vinculado do Amazon RDS para Oracle, escolher usar o tipo de conexão do Nome do Serviço do Amazon RDS para Oracle e configurar o nome do serviço correspondente. |
Sim |
| connectVia | O runtime de integração a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos. Se não especificado, o Azure Integration Runtime padrão será usado. | Não |
Se tiver várias instâncias do Amazon RDS para Oracle para o cenário de failover, você poderá criar o serviço vinculado do Amazon RDS para Oracle e preencher o host primário, a porta, o nome de usuário, a senha etc., e adicionar novas “Propriedades de conexão adicionais” com o nome de propriedade sendo AlternateServers e o valor sendo (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>). Preste atenção aos colchetes e aos dois pontos (:) como separador. Por exemplo, o seguinte valor de servidores alternativos define dois servidores de banco de dados alternativos para failover de conexão: (HostName=AccountingAmazonRdsForOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Mais propriedades de conexão que você pode definir na cadeia de conexão de acordo com o caso:
| Propriedade | Descrição | Valores permitidos |
|---|---|---|
| ArraySize | O número de bytes que o conector pode buscar em uma única viagem de ida e volta na rede. Por exemplo, ArraySize=10485760.Valores mais altos aumentam a taxa de transferência, reduzindo o número de vezes para buscar dados na rede. Valores mais baixos aumentam o tempo de resposta, pois a espera para o servidor transmitir dados é mais curta. |
Um inteiro de 1 a 4294967296 (4 GB). O valor padrão é 60000. O valor 1 não define o número de bytes, mas indica alocar espaço para exatamente uma linha de dados. |
Para habilitar a criptografia na conexão do Amazon RDS para Oracle, há duas opções:
Para usar a criptografia 3DES (DES triplo) e a criptografia AES (Advanced Encryption Standard) , no lado do servidor do Amazon RDS para OAS (Oracle Advanced Security) e defina as configurações de criptografia. Para obter detalhes, veja esta documentação da Oracle. O conector ADF (Application Development Framework) do Amazon RDS para Oracle negocia automaticamente o método de criptografia para usar aquele que você configura no OAS ao estabelecer a conexão com o Amazon RDS para Oracle.
Para usar o TLS:
Obtenha as informações do certificado TLS/SSL. Obtenha as informações de certificado codificado em DER (Distinguished Encoding Rules) do certificado TLS/SSL e salve a saída (----- Begin Certificate … End Certificate -----) como um arquivo de texto.
openssl x509 -inform DER -in [Full Path to the DER Certificate including the name of the DER Certificate] -textExemplo: extrair informações de certificado de DERcert.cer; em seguida, salvar a saída em cert.txt.
openssl x509 -inform DER -in DERcert.cer -text Output: -----BEGIN CERTIFICATE----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXX -----END CERTIFICATE-----Crie o
keystoreou otruststore. O comando a seguir cria o arquivotruststore, com ou sem uma senha no formato PKCS-12.openssl pkcs12 -in [Path to the file created in the previous step] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -nokeys -exportExemplo: crie um arquivo
truststore, PKCS12 denominado MyTrustStoreFile com uma senha.openssl pkcs12 -in cert.txt -out MyTrustStoreFile -passout pass:ThePWD -nokeys -exportColoque o arquivo
truststoreno computador IR auto-hospedado. Por exemplo, coloque o arquivo em C:\MyTrustStoreFile.No serviço, configure a cadeia de conexão do Amazon RDS para Oracle com
EncryptionMethod=1e o valor correspondente deTrustStore/TrustStorePassword. Por exemplo,Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Exemplo:
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: armazenar a senha no Azure Key Vault
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Esta seção fornece uma lista das propriedades com suporte do conjunto de dados do Amazon RDS para Oracle. Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira Conjuntos de dados.
Para copiar dados do Amazon RDS para Oracle, defina a propriedade type do conjunto de dados como AmazonRdsForOracleTable. Há suporte para as seguintes propriedades.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como AmazonRdsForOracleTable. |
Sim |
| esquema | Nome do esquema. | Não |
| tabela | Nome da tabela/exibição. | No |
| tableName | Nome da tabela/exibição com esquema. Essa propriedade é compatível com versões anteriores. Para uma nova carga de trabalho, use schema e table. |
Não |
Exemplo:
{
"name": "AmazonRdsForOracleDataset",
"properties":
{
"type": "AmazonRdsForOracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Amazon RDS for Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade de cópia
Esta seção fornece uma lista das propriedades com suporte da fonte do Amazon RDS para Oracle. Para obter uma lista completa das seções e propriedades disponíveis para definir as atividades, veja Pipelines.
Amazon RDS para Oracle como origem
Dica
Para carregar dados do Amazon RDS para Oracle com eficiência usando o particionamento de dados, saiba mais na seção Cópia paralela do Amazon RDS para Oracle.
Para copiar dados do Amazon RDS para Oracle, defina o tipo de fonte na atividade Copy como AmazonRdsForOracleSource. As propriedades a seguir têm suporte na seção source da atividade de cópia.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade Copy deve ser definida como AmazonRdsForOracleSource. |
Sim |
| oracleReaderQuery | Utiliza a consulta SQL personalizada para ler os dados. Um exemplo é "SELECT * FROM MyTable".Ao habilitar a carga particionada, você precisa vincular todos os parâmetros de partição internos correspondentes na consulta. Para obter exemplos, confira a seção Cópia paralela do Amazon RDS para Oracle. |
No |
| partitionOptions | Especifica as opções de particionamento de dados usadas para carregar dados do Amazon RDS para Oracle. Os valores permitidos são: None (padrão), PhysicalPartitionsOfTable e DynamicRange. Quando uma opção de partição está habilitada (ou seja, não None), o grau de paralelismo para carregar dados simultaneamente de um banco de dados do Amazon RDS para Oracle é controlado pela configuração parallelCopies na atividade Copy. |
Não |
| partitionSettings | Especifique o grupo de configurações para o particionamento de dados. Aplicar quando a opção de partição não for None. |
No |
| partitionNames | A lista de partições físicas que precisam ser copiadas. Aplicar quando a opção de partição for PhysicalPartitionsOfTable. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfTabularPartitionName na cláusula WHERE. Para obter um exemplo, confira a seção Cópia paralela do Amazon RDS para Oracle. |
Não |
| partitionColumnName | Especifique o nome da coluna de origem no tipo de inteiro que será usado pelo particionamento de intervalo para cópia paralela. Se não especificado, a chave primária da tabela será detectada automaticamente e usada como a coluna de partição. Aplicar quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfRangePartitionColumnName na cláusula WHERE. Para obter um exemplo, confira a seção Cópia paralela do Amazon RDS para Oracle. |
Não |
| partitionUpperBound | O valor máximo da coluna de partição para copiar dados. Aplicar quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfRangePartitionUpbound na cláusula WHERE. Para obter um exemplo, confira a seção Cópia paralela do Amazon RDS para Oracle. |
Não |
| partitionLowerBound | O valor mínimo da coluna de partição para copiar dados. Aplicar quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?AdfRangePartitionLowbound na cláusula WHERE. Para obter um exemplo, confira a seção Cópia paralela do Amazon RDS para Oracle. |
No |
Exemplo: copiar dados usando uma consulta básica sem partição
"activities":[
{
"name": "CopyFromAmazonRdsForOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForOracleSource",
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Cópia paralela do Amazon RDS para Oracle
O conector do Amazon RDS para Oracle fornece particionamento de dados interno para copiar dados do Oracle em paralelo. Você pode encontrar opções de particionamento de dados na guia Origem da atividade de cópia.

Quando você habilita a cópia particionada, o serviço executa consultas paralelas com relação à sua fonte do Amazon RDS para Oracle para carregar dados por partições. O grau paralelo é controlado pela configuração do parallelCopies na atividade de cópia. Por exemplo, se você definir parallelCopies como quatro, o serviço gerará e executará simultaneamente quatro consultas com base na opção de partição especificada e nas configurações e cada consulta recuperará uma parte dos dados do banco de dados do Amazon RDS para Oracle.
É recomendável habilitar a cópia paralela com o particionamento de dados, especialmente quando você carrega grandes quantidades de dados do banco de dados do Amazon RDS para Oracle. Veja a seguir as configurações sugeridas para cenários diferentes. Ao copiar dados para o armazenamento de dados baseado em arquivo, recomendamos gravá-los em uma pasta como vários arquivos (apenas especifique o nome da pasta) para obter um desempenho melhor do que gravar em um arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carregamento completo de uma tabela grande com partições físicas. | Opção de partição: partições físicas da tabela. Durante a execução, o serviço detecta automaticamente as partições físicas e copia os dados por partição. |
| Carregamento completo de uma tabela grande, sem partições físicas e com uma coluna de inteiro ou para o particionamento de dados. | Opções de partição: partição de intervalo dinâmico. Coluna de partição: especifique a coluna usada para particionar dados. Se não for especificada, a coluna de chave primária será usada. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, com partições físicas. | Opção de partição: partições físicas da tabela. Consulta: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>.Nome da partição: especifique os nomes de partição dos quais copiar dados. Se não for especificado, o serviço detectará automaticamente as partições físicas na tabela que você especificou no conjunto de dados do Amazon RDS para Oracle. Durante a execução, o serviço substitui ?AdfTabularPartitionName pelo nome real da partição e envia ao Amazon RDS para Oracle. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, sem partições físicas, com uma coluna de inteiro para o particionamento de dados. | Opções de partição: partição de intervalo dinâmico. Consulta: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Coluna de partição: especifique a coluna usada para particionar dados. Você pode particionar em relação à coluna com tipo de dados Integer. Limite superior da partição e Limite inferior da partição: especifique se quiser filtrar a coluna de partição para recuperar dados somente entre os intervalos inferior e superior. Durante a execução, o serviço substitui ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound e ?AdfRangePartitionLowbound pelo nome real da coluna e os intervalos de valores de cada partição e envia ao Amazon RDS para Oracle. Por exemplo, se a coluna de partição "ID" for definida com o limite inferior de 1 e o limite superior de 80, com a cópia paralela definida como 4, o serviço recuperará dados por 4 partições. Suas IDs estão entre [1, 20], [21, 40], [41, 60] e [61, 80], respectivamente. |
Dica
Ao copiar dados de uma tabela não particionada, você pode usar a opção de partição “Intervalo dinâmico” para particionar em uma coluna de inteiros. Se os dados de origem não tiverem esse tipo de coluna, você poderá aproveitar a função ORA_HASH na consulta de origem para gerar uma coluna e usá-la como coluna de partição.
Exemplo: consulta com partições físicas
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Exemplo: consulta com a partição do intervalo dinâmico
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Pesquisar propriedades de atividades
Para saber detalhes sobre as propriedades, verifique Pesquisar atividade.
Conteúdo relacionado
Para obter uma lista dos armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os Armazenamentos de dados com suporte.