Copiar dados para um índice do Azure AI Search usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade de cópia nos pipelines do Azure Data Factory ou do Azure Synapse Analytics para copiar dados de um banco de dados do Sybase no índice do Azure AI Search. Ele amplia o artigo Visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Funcionalidades com suporte
Esse conector do Azure AI Search é compatível com as seguintes funcionalidades:
| Funcionalidades com suporte | IR | Ponto de extremidade privado gerenciado |
|---|---|---|
| Atividade de cópia (-/coletor) | ① ② | ✓ |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Você pode copiar dados de qualquer armazenamento de dados de origem com suporte para o índice do pesquisa. Para obter uma lista de armazenamentos de dados com suporte como origens/coletores da atividade de cópia, confira a tabela Armazenamentos de dados com suporte.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Azure Search usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Azure Search na interface do usuário do portal do Microsoft Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou do Synapse e selecione Serviços Vinculados, em seguida, clique em Novo:
Pesquise por Search e selecione o conector do Azure Search.
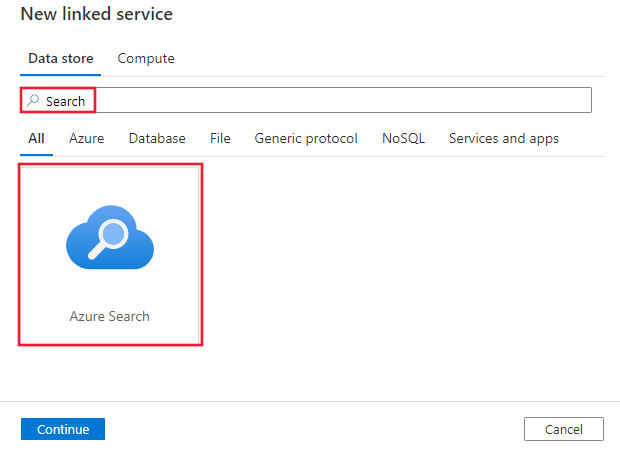
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
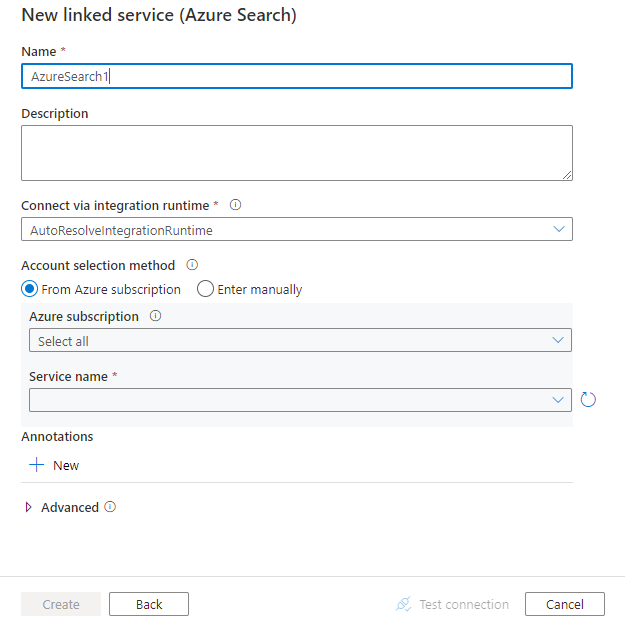
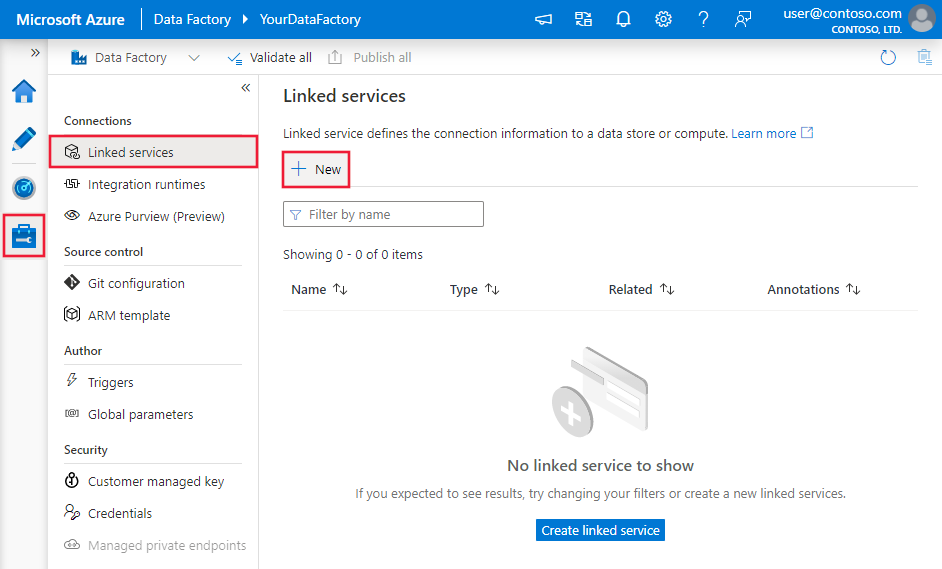

Detalhes da configuração do conector
As seções que se seguem fornecem detalhes sobre as propriedades que são usadas para definir entidades do Data Factory específicas ao conector do Azure AI Search.
Propriedades do serviço vinculado
O serviço vinculado do Azure AI Search dá suporte às seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como: AzureSearch | Sim |
| url | URL para o serviço de pesquisa. | Sim |
| chave | Chave de administrador para o serviço de pesquisa. Marque este campo como um SecureString para armazená-lo com segurança ou referencie um segredo armazenado no Azure Key Vault. | Sim |
| connectVia | O Integration Runtime a ser usado para se conectar ao armazenamento de dados. Você pode usar o Integration Runtime do Azure ou o Integration Runtime auto-hospedado (se o armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usa o Integration Runtime padrão do Azure. | Não |
Importante
Ao copiar dados de um armazenamento de dados de nuvem para o índice de pesquisa, você precisa, no serviço vinculado do Azure AI Search, referenciar um Azure Integration Runtime com região explícita no connectVia. Defina a região como aquela na qual o serviço de pesquisa reside. Aprenda mais do Azure Integration Runtime.
Exemplo:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre conjuntos de dados. Esta seção fornece uma lista das propriedades compatíveis com o conjunto de dados do Azure AI Search.
Para copiar dados para o Azure AI Search, há suporte às seguintes propriedades:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como: AzureSearchIndex | Sim |
| indexName | Nome do índice de pesquisa. O serviço não cria o índice. O índice precisa existir no Azure AI Search. | Sim |
Exemplo:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades compatíveis com a fonte do Azure AI Search.
Azure AI Search como coletor
Para copiar dados no Azure AI Search, defina o tipo de fonte na atividade de cópia como AzureSearchIndexSink. As propriedades a seguir têm suporte na seção sink da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como: AzureSearchIndexSink | Sim |
| writeBehavior | Especifica se deve mesclar ou substituir quando já existe um documento no índice. Veja a propriedade WriteBehavior. Os valores permitidos são: Merge (padrão) e Upload. |
Não |
| writeBatchSize | Carrega dados no índice de pesquisa quando o tamanho do buffer atinge writeBatchSize. Veja a propriedade WriteBatchSize para obter detalhes. Os valores permitidos são: inteiros de 1 a 1.000; o valor padrão é 1.000. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas com o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando desejar limitar as conexões simultâneas. | No |
Propriedade WriteBehavior
Upsert do AzureSearchSink ao gravar dados. Em outras palavras, ao escrever um documento, se a chave do documento já existe no índice de pesquisa, o Azure AI Search atualiza o documento existente em vez de lançar uma exceção de conflito.
O AzureSearchSink fornece estes dois comportamentos de upsert (usando o SDK da AzureSearch):
- Mesclar: combine todas as colunas no novo documento com a existente. Para colunas com valor nulo no novo documento, o valor existente é preservado.
- Carregar: o novo documento substituirá o existente. Para colunas não especificadas no novo documento, o valor será definido como nulo se houver um valor não nulo no documento existente ou não.
O comportamento padrão é Mesclar.
Propriedade WriteBatchSize
O serviço do Azure AI Search dá suporte à redação de documentos como um lote. Um lote pode conter de 1 a 1.000 ações. Uma ação manipula um documento para executar a operação de carregamento/mesclagem.
Exemplo:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
Suporte do tipo de dados
A tabela a seguir especifica se um tipo de dados do Azure AI Search é compatível ou não.
| Tipo de dados do Azure AI Search | Suporte no coletor do Azure AI Search |
|---|---|
| String | S |
| Int32 | S |
| Int64 | S |
| Double | S |
| Boolean | S |
| DataTimeOffset | S |
| Matriz de cadeia de caracteres | N |
| GeographyPoint | N |
Atualmente não há suporte para outros tipos de dados, como por exemplo, complexType. Para obter uma lista completa de tipos de dados compatíveis com o Azure AI Search, consulte Tipos de dados com suporte (Azure AI Search).
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os armazenamentos de dados com suporte.