Mapeamento de esquema e de tipo de dados na atividade de cópia
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como a atividade de cópia do Azure Data Factory executa o mapeamento do esquema e o mapeamento do tipo de dados dos dados de origem para os dados do coletor.
Mapeamento de esquema
Mapeamento padrão
Por padrão, a atividade de cópia mapeia os dados de origem para coletor por nomes de coluna de maneira que diferencia maiúsculas de minúsculas. Se o coletor não existir, por exemplo, a gravação em arquivo(s), os nomes de campo de origem serão persistentes como nomes de coletor. Se o coletor já existir, ele deverá conter todas as colunas que estão sendo copiadas da origem. Esse mapeamento padrão dá suporte a esquemas flexíveis e descompasso de esquema da origem para o coletor da execução para a execução – todos os dados retornados pelo armazenamento de dados de origem podem ser copiados para o coletor.
Se sua origem for um arquivo de texto sem linha de cabeçalho, o mapeamento explícito será necessário, pois a origem não contém nomes de coluna.
Mapeamento explícito
Você também pode especificar o mapeamento explícito para personalizar o mapeamento de coluna/campo da origem para o coletor com base em sua necessidade. Com o mapeamento explícito, você pode copiar apenas dados de origem parciais para o coletor ou mapear dados de origem para o coletor com nomes diferentes ou remodelar dados tabular/hierárquicos. Atividade de cópia:
- Lê os dados da origem e determina o esquema de origem.
- Aplica seu mapeamento definido.
- Grava os dados no coletor.
Saiba mais sobre:
- Origem tabular para o coletor tabular
- Origem hierárquica para o coletor tabular
- Origem tabular/hierárquica para o coletor hierárquico
Você pode configurar o mapeamento na interface do usuário de criação -> atividade de cópia -> guia de mapeamento ou especificar de forma programática o mapeamento na atividade de cópia ->translator propriedade. As seguintes propriedades são suportadas em translator ->mappings matriz -> objetos ->source e sink, quais pontos para a coluna/campo específico para mapear dados.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| name | Nome da coluna/campo de origem ou do coletor. Aplicar para origem tabular e o coletor. | Sim |
| ordinal | Índice da coluna. Iniciar no 1. Aplicar e necessário ao usar texto delimitado sem linha de cabeçalho. |
Não |
| caminho | A expressão de caminho JSON para cada campo para extrair e mapear. Aplique para fonte e coletor hierárquicos, por exemplo, conectores Azure Cosmos DB, MongoDB ou REST. Para campos sob o objeto raiz, o caminho JSON começa com root $; para campos dentro da matriz escolhida por collectionReference propriedade, o caminho JSON é iniciado a partir do elemento de matriz sem $. |
Não |
| type | Tipo de dados provisórios da coluna de origem ou do coletor. Em geral, você não precisa especificar ou alterar essa propriedade. Saiba mais sobre mapeamento de tipo de dados. | Não |
| culture | Cultura da coluna de origem ou do coletor. Aplicar quando o tipo for Datetime ou Datetimeoffset. O padrão é en-us.Em geral, você não precisa especificar ou alterar essa propriedade. Saiba mais sobre mapeamento de tipo de dados. |
Não |
| format | O formato de cadeia de caracteres a ser usado quando o tipo for Datetime ou Datetimeoffset. Consulte Data personalizada e cadeias de caracteres de formato de hora sobre como formatar a data e hora. Em geral, você não precisa especificar ou alterar essa propriedade. Saiba mais sobre mapeamento de tipo de dados. |
Não |
As propriedades a seguir têm suporte em translator além de mappings:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| collectionReference | Aplique ao copiar dados de uma fonte hierárquica, como conectores Azure Cosmos DB, MongoDB ou REST. Se você quiser fazer uma iteração e extrair dados de objetos dentro de um campo de matriz com o mesmo padrão e converter para por linha por objeto, especifique o caminho JSON da matriz para realizar a aplicação cruzada. |
Não |
Origem tabular para o coletor tabular
Por exemplo, para copiar dados do Salesforce para o banco de dados SQL do Azure e mapear explicitamente três colunas:
Na guia atividade de cópia -> guia de mapeamento, clique no botão Importar esquemas para importar os esquemas de origem e de coletor.
Mapeie os campos necessários e exclua/apague o restante.

O mesmo mapeamento pode ser configurado como o seguinte na carga da atividade de cópia (consulte translator):
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Para copiar dados de arquivo(s) de texto delimitado(s) sem linha de cabeçalho, as colunas são representadas por ordinal em vez de nomes.
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
Origem hierárquica para o coletor tabular
Ao copiar dados da origem hierárquica para o coletor tabular, a atividade de cópia dá suporte aos seguintes recursos:
- Extrair dados de objetos e matrizes.
- A aplicação cruzada de vários objetos com o mesmo padrão de uma matriz, nesse caso, para converter um objeto JSON em vários registros em resultado tabular.
Para uma transformação hierárquica para tabular mais avançada, você pode usar Fluxo de Dados.
Por exemplo, se você tiver o documento MongoDB com o seguinte conteúdo:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
E você deseja copiá-lo para um arquivo de texto no formato a seguir com linha de cabeçalho, ao nivelar os dados de dentro da matriz (order_pd e order_price) e fazer uma união cruzada com as informações de raiz comuns (número, data e cidade) :
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Você pode definir esse mapeamento na interface do usuário de criação do Data Factory:
Na guia atividade de cópia -> guia de mapeamento, clique no botão Importar esquemas para importar os esquemas de origem e de coletor. Como o serviço toma amostras dos principais objetos ao importar o esquema, se qualquer campo não aparecer, você poderá adicioná-lo à camada correta na hierarquia – passe o cursor sobre um nome de campo existente e opte por adicionar um nó, um objeto ou uma matriz.
Selecione a matriz da qual você deseja iterar e extrair dados. Ela será preenchida automaticamente como Referência de coleção. Observe que há suporte apenas para uma única matriz para essa operação.
Mapear os campos necessários para o coletor. O serviço determina automaticamente os caminhos JSON correspondentes para o lado hierárquico.
Observação
Para registros em que a matriz marcada como referência de coleção está vazia e a caixa de seleção está marcada, todo o registro é ignorado.
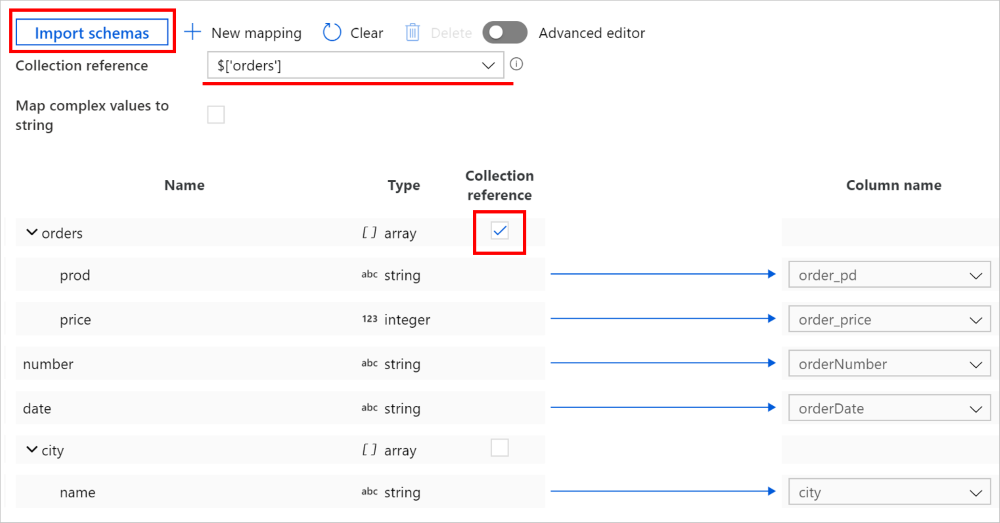
Você também pode alternar para Editor avançado. Nesse caso, você pode ver e editar diretamente os caminhos JSON dos campos. Se você optar por adicionar novo mapeamento nessa exibição, especifique o caminho JSON.
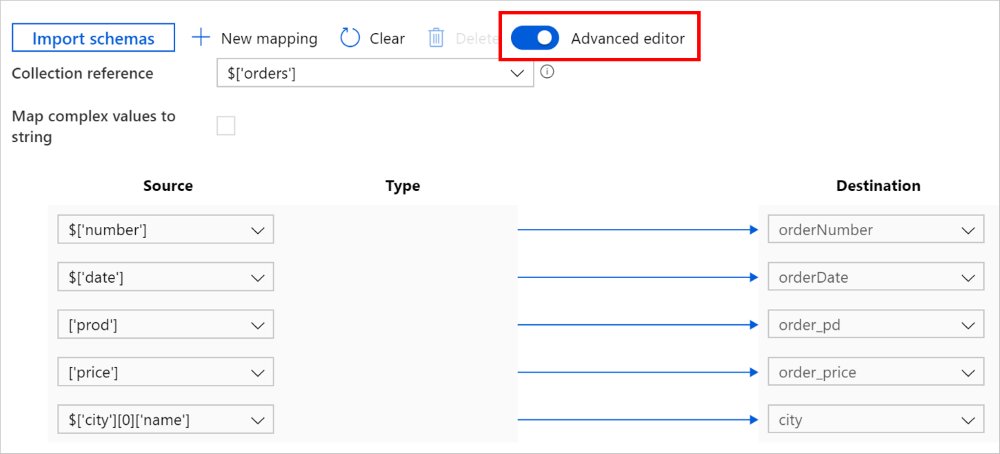
O mesmo mapeamento pode ser configurado como o seguinte na carga da atividade de cópia (consulte translator):
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
Origem tabular/hierárquica para o coletor hierárquico
O fluxo de experiência do usuário é semelhante ao Coletor hierárquico de origem para tabular.
Ao copiar dados da origem tabular para coletor hierárquico, não há suporte para gravar na matriz dentro do objeto.
Ao copiar dados da origem hierárquica para o coletor hierárquico, você também pode preservar a hierarquia inteira da camada, selecionando o objeto/matriz e mapeando para o coletor sem tocar nos campos internos.
Para uma transformação remodelação de dados mais avançada, você pode usar o Fluxo de dados.
Parametrizar mapeamento
Se você quiser criar um pipeline modelado para copiar um grande número de objetos dinamicamente, determine se você pode aproveitar o mapeamento padrão ou se precisa definir o mapeamento explícito para os respectivos objetos.
Se o mapeamento explícito for necessário, você poderá:
Definir um parâmetro com o tipo de objeto no nível do pipeline, por exemplo,
mapping.Parametrizar o mapeamento: na guia atividade de cópia -> mapeamento, escolha adicionar conteúdo dinâmico e selecione o parâmetro acima. A carga da atividade seria a seguinte:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }Construir o valor a ser passado para o parâmetro de mapeamento. Deve ser o objeto inteiro de
translatordefinição, consulte a seção exemplos na seção mapeamento explícito. Por exemplo, para a origem tabular para a cópia de coletor tabular, o valor deve ser{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}.
Mapeamento de tipo de dados
A atividade de cópia executa o mapeamento dos tipos de origem para os tipos de coletor com o seguinte fluxo:
- Converter tipos de dados nativos de origem em tipos de dados provisórios usados pelos pipelines do Azure Data Factory e do Synapse.
- Converter automaticamente o tipo de dados provisórios conforme necessário para corresponder aos tipos de coletor correspondentes, aplicáveis ao mapeamento padrão e ao mapeamento explícito.
- Converter tipos de dados provisórios em tipos de dados nativos do coletor.
Atualmente, a atividade de cópia dá suporte aos seguintes tipos de dados provisórios: Boolean, Byte, Matriz de bytes, DateTime, DatetimeOffset, Decimal, Double, GUID, Int16, Int32, Int64, SByte, Single, String, TimeSpan, UInt16, UInt32 e UInt64.
As conversões de tipo de dados a seguir têm suporte entre os tipos provisórios da origem para o coletor.
| Origem/Coletor | Boolean | Matriz de bytes | Data/hora | Decimal | Ponto flutuante | GUID | Inteiro | String | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| Boolean | ✓ | ✓ | ✓ | ✓ | |||||
| Matriz de bytes | ✓ | ✓ | |||||||
| Data/Hora | ✓ | ✓ | |||||||
| Decimal | ✓ | ✓ | ✓ | ✓ | |||||
| Ponto flutuante | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| Integer | ✓ | ✓ | ✓ | ✓ | |||||
| String | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) Data/Hora inclui DateTime e DateTimeOffset.
(2) Ponto flutuante inclui Single e Double.
(3) Inteiro inclui SByte, Byte, Int16, UInt16, Int32, UInt32, Int64 e UInt64.
Observação
- Atualmente, há suporte para essa conversão de tipo de dados durante a cópia entre dados tabular. Não há suporte para fontes/coletores hierárquicos, o que significa que não há nenhuma conversão de tipo de dados definida pelo sistema entre os tipos intermediários de origem e de coletor.
- Esse recurso funciona com o modelo de conjunto de dados mais recente. Se não encontrar essa opção na interface do usuário, tente criar um novo conjunto de dados.
As propriedades a seguir têm suporte na atividade de cópia para conversão de tipo de dados (na seção translator para a autorização programática):
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| typeConversion | Habilita a nova experiência de conversão de tipo de dados. O valor padrão é false devido à compatibilidade com backward. Para novas atividades de cópia criadas por meio da interface do usuário de criação do Data Factory desde o final de junho de 2020, essa conversão de tipo de dados é habilitada por padrão para a melhor experiência e você pode ver as seguintes configurações de conversão de tipo na guia atividade de cópia -> mapeamento para cenários aplicáveis. Para criar o pipeline programaticamente, você precisa definir explicitamente a typeConversion propriedade como true para habilitá-la.Para as atividades de cópia existentes criadas antes do lançamento desse recurso, você não verá opções de conversão do tipo na interface do usuário de criação para compatibilidade com versões anteriores. |
Não |
| typeConversionSettings | Um grupo de configurações de conversão de tipo. Use quando typeConversion estiver definido como true. As propriedades a seguir estão todas neste grupo. |
Não |
Em typeConversionSettings |
||
| allowDataTruncation | Permitir truncamento de dados ao converter dados de origem para coletor com tipo diferente durante a cópia, por exemplo, de decimal para inteiro, de DatetimeOffset em Datetime. O valor padrão é true. |
Não |
| treatBooleanAsNumber | Trate boolianas como números, por exemplo, true como 1. O valor padrão é false. |
Não |
| dateTimeFormat | Formatar cadeia de caracteres ao converter entre datas sem deslocamento de fuso horário e cadeias de caracteres, por exemplo, yyyy-MM-dd HH:mm:ss.fff. Consulte Cadeias de caracteres de formato de data e hora personalizadas para obter informações detalhadas. |
Não |
| dateTimeOffsetFormat | Cadeia de caracteres de formato ao converter entre datas com deslocamento e cadeias de caracteres de fuso horário, por exemplo, yyyy-MM-dd HH:mm:ss.fff zzz. Consulte Cadeias de caracteres de formato de data e hora personalizadas para obter informações detalhadas. |
Não |
| timeSpanFormat | Cadeia de formato ao converter entre períodos de tempo e cadeias de caracteres, por exemplo, dd\.hh\:mm. Consulte Cadeias de caracteres de formato TimeSpan personalizadas para obter informações detalhadas. |
Não |
| culture | Informações de cultura a serem usadas ao converter tipos, por exemplo, en-us ou fr-fr. |
Não |
Exemplo:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
Modelos herdados
Observação
Os modelos a seguir para mapear colunas/campos de origem para o coletor ainda têm suporte como são para compatibilidade com backward. Sugerimos usar o novo modelo mencionado no mapeamento de esquema. A interface do usuário de criação mudou para gerar o novo modelo.
Coluna alternativa - mapeamento (modelo herdado)
Você pode especificar a atividade de cópia ->translator ->columnMappings para mapear entre dados com formato tabular. Nesse caso, a seção "structure" é necessária para os conjuntos de dados de entrada e de saída. O mapeamento de coluna dá suporte ao mapeamento de todas as colunas ou de um subconjunto de colunas na “structure” do conjunto de dados de origem para todas as colunas na “structure” do conjunto de dados do coletor. Veja a seguir condições de erro que resultam em uma exceção:
- O resultado da consulta do armazenamento de dados de origem não tem um nome de coluna especificado na seção “structure” do conjunto de dados de entrada.
- O armazenamento de dados do coletor (se estiver com o esquema predefinido) não tem um nome de coluna especificado na seção “structure” do conjunto de dados de saída.
- Menos colunas ou mais colunas na seção "structure" do conjunto de dados do coletor do que o especificado no mapeamento.
- Mapeamento duplicado.
No exemplo a seguir, o conjunto de dados de entrada tem uma estrutura e ele aponta para uma tabela em um banco de dados Oracle local.
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
Nessa amostra, o conjunto de dados de saída tem uma estrutura e aponta para uma tabela no Salesforce.
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
O JSON a seguir define uma atividade de cópia em um pipeline. As colunas da origem são mapeadas na origem para colunas no coletor usando a propriedade tradutor ->columnMappings.
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
Se você está utilizando a sintaxe de "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" para especificar o mapeamento de coluna, ainda há suporte no estado em que se encontra.
Esquema alternativo – mapeamento (modelo herdado)
Você pode especificar a atividade de cópia – >translator – >schemaMapping para mapear entre dados em formato hierárquico e dados em forma de tabela, por exemplo, copie do MongoDB/REST para o arquivo de texto e copie do Oracle para o Azure Cosmos DB for MongoDB. As propriedades a seguir têm suporte na seção translator da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do tradutor da atividade de cópia deve ser definida como: TabularTranslator | Sim |
| schemaMapping | Uma coleção de pares de valores-chave, que representa a relação de mapeamento do lado de origem para o lado do coletor. - Chave: representa a origem. Para fonte tabular, especifique o nome da coluna conforme definido na estrutura do conjunto de dados; para fonte hierárquica, especifique a expressão de caminho JSON para cada campo a ser extraído e mapeado. - Valor: representa o coletor. Para o coletor de tabela, especifique o nome da coluna conforme definido na estrutura do conjunto de dados; para coletor hierárquico, especifique a expressão de caminho JSON para cada campo a ser extraído e mapeado. No caso de dados hierárquicos, para campos no objeto raiz, o caminho JSON é iniciado com raiz $ para campos dentro da matriz escolhidos por propriedade collectionReference, o caminho JSON inicia do elemento de matriz. |
Sim |
| collectionReference | Se você quiser fazer uma iteração e extrair dados de objetos dentro de um campo de matriz com o mesmo padrão e converter para por linha por objeto, especifique o caminho JSON da matriz para realizar a aplicação cruzada. Essa propriedade só terá suporte quando os dados hierárquicos forem a origem. | Não |
Exemplo: copiar do MongoDB para o Oracle:
Por exemplo, se você tiver o documento do MongoDB com o seguinte conteúdo:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
e você deseja copiá-lo para uma tabela do Azure SQL no formato a seguir, ao nivelar os dados de dentro da matriz (order_pd e order_price) e fazer uma união cruzada com as informações de raiz comuns (número, data e cidade):
| orderNumber | orderDate | order_pd | order_price | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | Seattle |
| 01 | 20170122 | P2 | 13 | Seattle |
| 01 | 20170122 | P3 | 231 | Seattle |
Configure a regra de mapeamento de esquema como o seguinte exemplo JSON de atividade de cópia:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
Conteúdo relacionado
Consulte os outros artigos sobre atividade de cópia: