Copiar incrementalmente os dados do Banco de Dados SQL do Azure para o Armazenamento de Blobs usando o controle de alterações no portal do Azure
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Em uma solução de integração de dados, o carregamento incremental de dados depois de uma carga de dados inicial é um cenário amplamente usado. Os dados alterados dentro de um período no armazenamento de dados de origem podem ser facilmente fatiados (por exemplo, LastModifyTime, CreationTime). Mas, em alguns casos, não há uma forma explícita de identificar os dados delta da última vez que você processou os dados. Use a tecnologia de controle de alterações com suporte dos armazenamentos de dados, como o Banco de Dados SQL do Azure e SQL Server, para identificar os dados delta.
Este tutorial descreve como usar o Azure Data Factory com o controle de alterações a fim de carregar incrementalmente os dados delta do Banco de Dados SQL do Azure no Armazenamento de Blobs do Azure. Para obter mais informações sobre o controle de alterações, confira Controle de alterações no SQL Serve.
Neste tutorial, você realizará os seguintes procedimentos:
- Prepare o armazenamento de dados de origem.
- Criar um data factory.
- Criar serviços vinculados.
- Crie conjuntos de dados de origem, coletor e de controle de alterações.
- Crie, execute e monitore o pipeline de cópia completa.
- Adicione ou atualize os dados na tabela de origem.
- Crie, execute e monitore o pipeline de cópia incremental.
Solução de alto nível
Neste tutorial, você cria dois pipelines que executam as operações a seguir.
Observação
Este tutorial usa o Banco de Dados SQL do Azure como o armazenamento de dados de origem. Você também pode usar o SQL Server.
Carregamento inicial de histórico de dados: crie um pipeline com uma atividade de cópia que copia todos os dados de armazenamento de dados de origem (Banco de Dados SQL do Azure) para o armazenamento de dados de destino (Armazenamento de Blobs do Azure):
- Habilite a tecnologia de controle de alterações no banco de dados de origem no Banco de Dados SQL do Azure.
- Obtenha o valor inicial de
SYS_CHANGE_VERSIONno banco de dados como a linha de base para capturar os dados alterados. - Carregue todos os dados do banco de dados de origem na conta de Armazenamento de Blobs do Azure.

Carregamento incremental de dados delta em um agendamento: crie um pipeline com as seguintes atividades e execute-o periodicamente:
Crie duas atividades de pesquisa para obter os valores
SYS_CHANGE_VERSIONnovos e antigos do Banco de Dados SQL do Azure.Crie uma atividade de cópia para copiar os dados inseridos, atualizados ou excluídos (os dados delta) entre os dois valores
SYS_CHANGE_VERSIONdo Banco de Dados SQL do Azure para o Armazenamento de Blobs do Azure.Carregue os dados delta unindo as chaves primárias de linhas alteradas (entre dois valores
SYS_CHANGE_VERSION) desys.change_tracking_tablescom os dados na tabela de origem e, em seguida, mova os dados delta para o destino.Crie uma atividade de procedimento armazenado para atualizar o valor de
SYS_CHANGE_VERSIONpara a próxima execução do pipeline.

Pré-requisitos
- Assinatura do Azure. Se você não tiver uma, crie uma conta gratuita antes de começar.
- Banco de dados SQL do Azure. Você usa um banco de dados no Banco de Dados SQL do Azure como o armazenamento de dados deorigem. Se você não tiver um, confira Criar um banco de dados no Banco de Dados SQL do Azure para saber as etapas para criá-lo.
- Conta de Armazenamento do Azure. Você usa o Armazenamento de Blobs como um armazenamento de dados de coletor. Se você não tiver uma conta de armazenamento do Azure, consulte Criar uma conta de armazenamento para obter as etapas para criá-la. Crie um contêiner denominado adftutorial.
Observação
Recomendamos que você use o módulo Az PowerShell do Azure para interagir com o Azure. Para começar, consulte Instalar o Azure PowerShell. Para saber como migrar para o módulo Az PowerShell, confira Migrar o Azure PowerShell do AzureRM para o Az.
Criar uma tabela de fonte de dados no Banco de Dados SQL do Azure
Abra o SQL Server Management Studio e conecte-se ao Banco de Dados SQL.
No Gerenciador de Servidores, clique com o botão direito do mouse no banco de dados e selecione Nova Consulta.
Execute o comando SQL a seguir no banco de dados para criar uma tabela chamada
data_source_tablecomo o armazenamento de dados de origem:create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Habilite o controle de alterações no seu banco de dados e na tabela de origem (
data_source_table) executando a consulta SQL a seguir.Observação
- Substitua
<your database name>pelo nome do banco de dados no Banco de Dados SQL do Azure que possuidata_source_table. - Os dados alterados são mantidos por dois dias no exemplo atual. Se você carregar os dados alterados a cada três dias ou mais, alguns dados alterados não serão incluídos. Você precisa alterar o valor de
CHANGE_RETENTIONpara um número maior ou garantir que o período para carregar os dados alterados seja dentro de dois dias. Para saber mais, consulte Habilitar o controle de alterações de um banco de dados.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Substitua
Crie uma nova tabela e armazene chamadas
ChangeTracking_versioncom um valor padrão executando a consulta a seguir:create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Observação
Se os dados não forem alterados após a habilitar o controle de alterações para o Banco de Dados SQL, o valor da versão do controle de alterações será
0.Execute a consulta a seguir para criar um procedimento armazenado em seu banco de dados. O pipeline chama esse procedimento armazenado para atualizar a versão do controle de alteração na tabela criada na etapa anterior.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Criar uma data factory
Abra o navegador da Web Microsoft Edge ou Google Chrome. Atualmente, somente esses navegadores da Web dão suporte à UI (interface do usuário) do Data Factory.
No portal do Azure, no menu à esquerda, selecione Criar um recurso.
Selecione Integração>Data Factory.
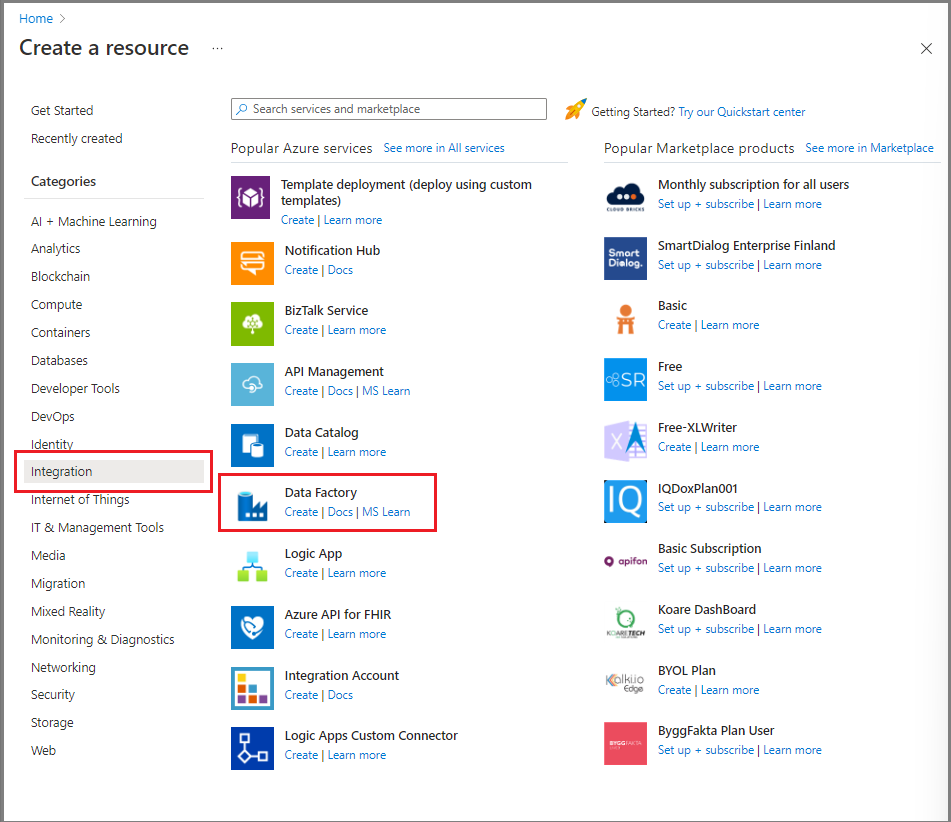
Na página Novo data factory, insira ADFTutorialDataFactory no campo nome.
O nome do data factory deve ser globalmente exclusivo. Se você receber um erro informando que o nome escolhido não está disponível, altere o nome (por exemplo, para yournameADFTutorialDataFactory) e tente criar o data factory novamente. Para obter mais informações, confira as regras de nomenclatura do Azure Data Factory.
Selecione a assinatura do Azure na qual deseja criar o data factory.
Em Grupo de Recursos, use uma das seguintes etapas:
- Selecione Usar existentee, em seguida, selecione um grupo de recursos existente na lista suspensa.
- Selecione Criar novo e insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, consulte Usando grupos de recursos para gerenciar recursos do Azure.
Para Versão, selecione V2.
Em Região, selecione a região para o data factory.
A lista suspensa exibe apenas os locais com suporte. Os armazenamentos de dados (por exemplo, Armazenamento do Microsoft Azure e Banco de Dados SQL do Azure) e os serviços de computação (por exemplo, Azure HDInsight) que um data factory usa podem estar em outras regiões.
Selecione Próximo: configuração do Git. Configure o repositório seguindo as instruções em Método de configuração 4: durante a criação do data factory ou marque a caixa de seleção Configurar o Git posteriormente.
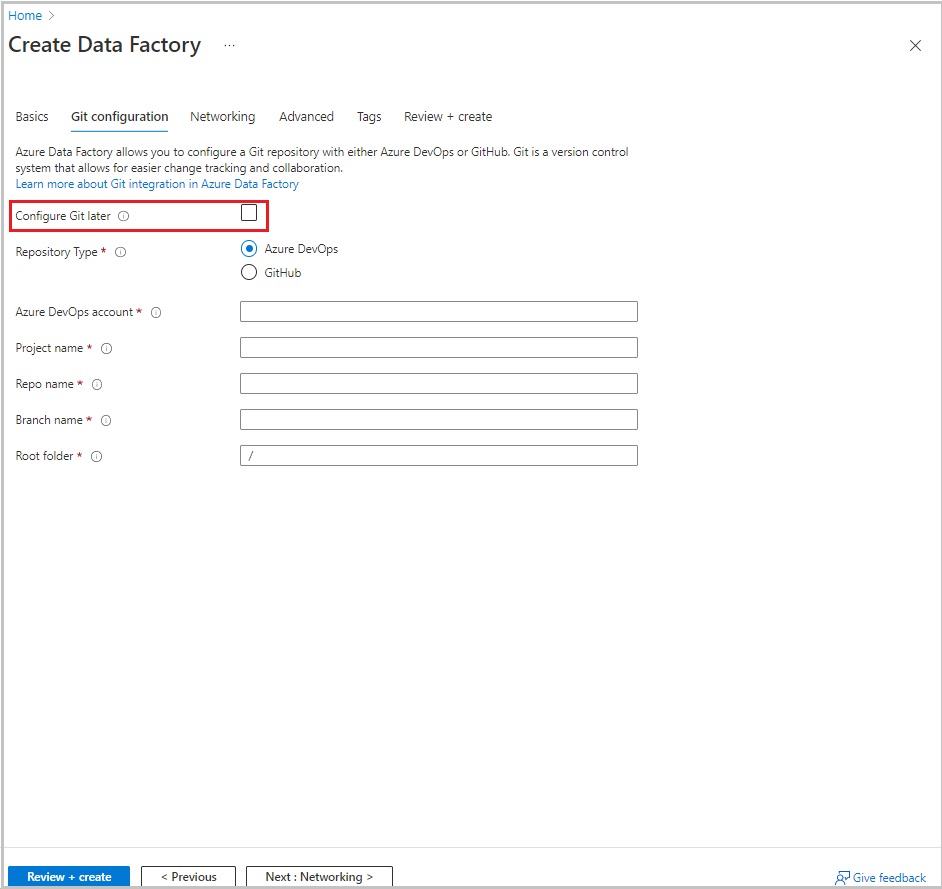
Selecione Examinar + criar.
Selecione Criar.
No painel, o bloco Implantando o Data Factory mostra o status.

Após a criação, a página do Data Factory é exibida. Selecione o bloco Iniciar estúdio para abrir a interface do usuário do Azure Data Factory em uma guia separada.
Criar serviços vinculados
Os serviços vinculados são criados em um data factory para vincular seus armazenamentos de dados e serviços de computação ao data factory. Nesta seção, você cria serviços vinculados para sua conta de armazenamento do Azure e o banco de dados no Banco de Dados SQL do Azure.
Criar um serviço vinculado do Armazenamento do Azure
Para vincular sua conta de armazenamento ao data factory:
- Na interface do usuário do Data Factory, na guia Gerenciar, em Conexões, selecione Serviços vinculados. Em seguida, selecione + Novo ou o botão Criar serviço vinculado.
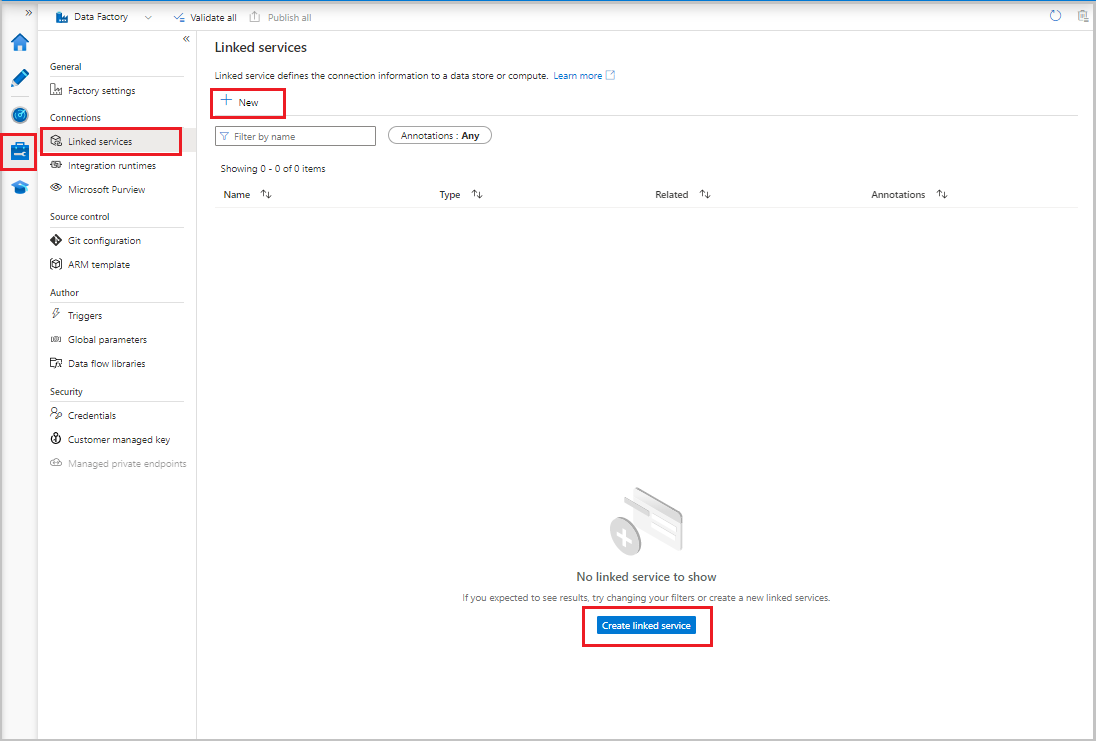
- Na janela Novo Serviço Vinculado, selecione Armazenamento de Blobs do Azure e selecione Continuar.
- Insira as seguintes informações:
- Para o campo Nome, insira AzureStorageLinkedService.
- Em Conectar por meio do runtime de integração, selecione o runtime de integração.
- Em Tipo de autenticação, selecione um método de autenticação.
- Em Nome da conta de armazenamento, selecione sua conta de armazenamento do Azure.
- Selecione Criar.
Criar um serviço vinculado do Banco de Dados SQL do Azure
Para vincula seu banco de dados ao data factory:
Na interface do usuário do Data Factory, na guia Gerenciar, em Conexões, selecione Serviços vinculados. Em seguida, selecione + Novo.
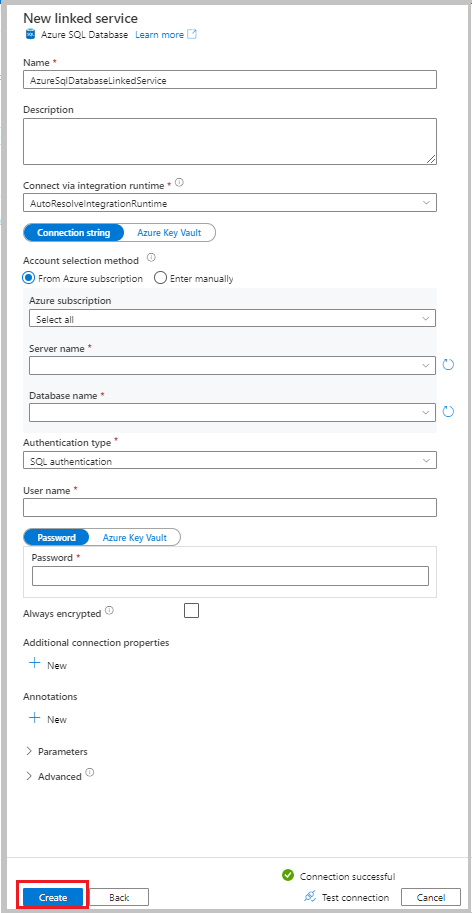
Na janela Novo Serviço Vinculado, selecione Banco de Dados SQL do Azure e, em seguida, selecione Continuar.
Insira as seguintes informações:
- Em Nome, insira AzureSqlDatabaseLinkedService.
- Em Nome do servidor, selecione seu serviço.
- Em Nome do banco de dados, selecione seu banco de dados.
- Em Tipo de autenticação, selecione um método de autenticação. Este tutorial usa a autenticação SQL para demonstração.
- Em Nome de usuário, insira o nome do usuário.
- Em Senha, insira uma senha do usuário. Ou forneça as informações para o Azure Key Vault – serviço vinculado do AKV, Nome do segredo e Versão secreta.
Selecione Testar conectividade para testar a conexão.
Selecione Criar para criar o serviço vinculado.
Criar conjuntos de dados
Nesta seção, você cria conjuntos de dados para representar a fonte de dados e o destino de dados, junto com o local para armazenar os valores SYS_CHANGE_VERSION.
Criar um conjunto de dados para representar dados de origem
Na interface do usuário do Data Factory, na guia Autor, selecione o sinal de adição (+). Em seguida, selecione Conjunto de dados ou selecione as reticências para ações do conjunto de dados.
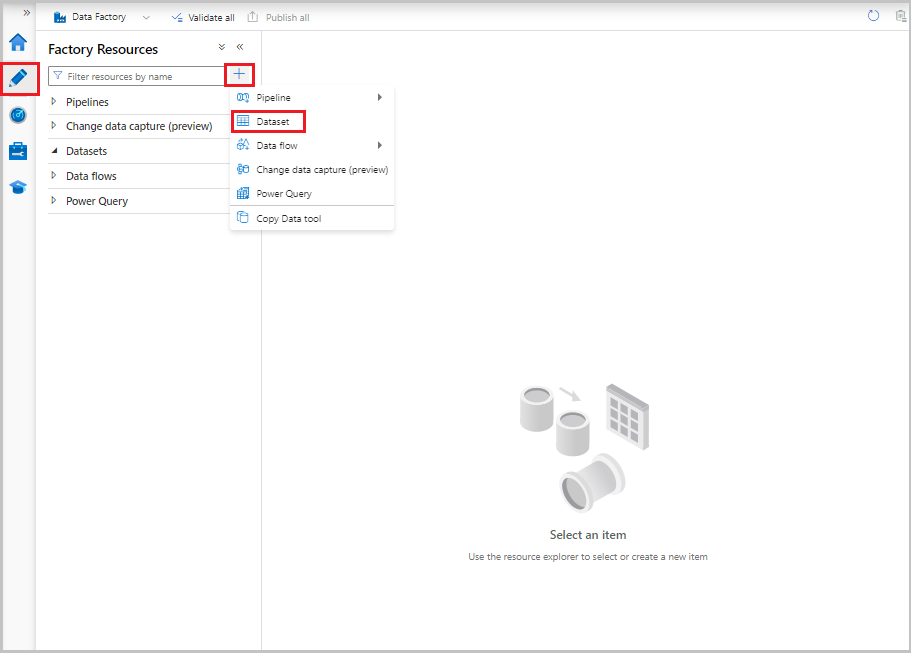
Selecione Banco de Dados SQL do Azure e Continuar.
Na janela Definir Propriedades, execute as etapas a seguir:
- Em Nome, insira SourceDataset.
- Em Serviço vinculado, selecione AzureSqlDatabaseLinkedService.
- Em Nome da tabela, selecione dbo.data_source_table.
- Em Importar esquema, selecione a opção De conexão/repositório.
- Selecione OK.

Criar um conjunto de dados para representar os dados copiados para o armazenamento de dados do coletor
No procedimento a seguir, você cria um conjunto de dados para representar os dados que são copiados do armazenamento de dados de origem. Você cria o contêiner adftutorial no Armazenamento de Blobs do Azure como parte dos pré-requisitos. Crie o contêiner caso ele não exista ou defina-o com o nome de um contêiner existente. Neste tutorial, o nome do arquivo de saída é gerado dinamicamente a partir da expressão @CONCAT('Incremental-', pipeline().RunId, '.txt').
Na interface do usuário do Data Factory, na guia Autor, selecione +. Em seguida, selecione Conjunto de dados ou selecione as reticências para ações do conjunto de dados.
Selecione Armazenamento de Blobs do Azure e depois selecione Continuar.
Selecione o formato do tipo de dados como DelimitedText e, em seguida, selecione Continuar.
Na janela Definir propriedades, execute as etapas a seguir:
- Em Nome, insira SinkDataset.
- Em Serviço vinculado, selecione AzureBlobStorageLinkedService.
- Para Caminho do arquivo, insira adftutorial/incchgtracking.
- Selecione OK.
Depois que o conjunto de dados aparecer no modo de exibição de árvore, acesse a guia Conexão e selecione a caixa de texto Nome do arquivo. Quando a opção Adicionar conteúdo dinâmico for exibida, selecione-a.
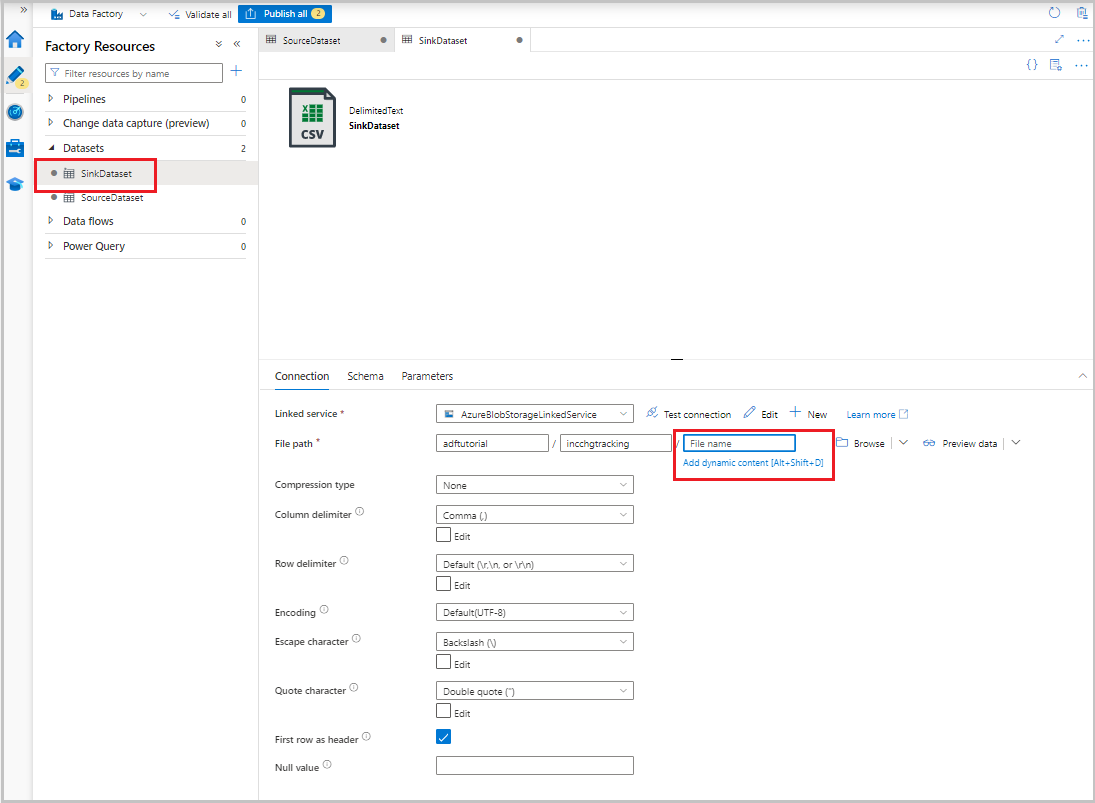
A janela Construtor de expressões de pipeline é exibida. Cole
@concat('Incremental-',pipeline().RunId,'.csv')na caixa de texto.Selecione OK.
Criar um conjunto de dados para representar dados de controle de alterações
No procedimento a seguir, você cria um conjunto de dados para armazenar a versão do controle de alterações. Você criou a tabela table_store_ChangeTracking_version como parte dos pré-requisitos.
- Na interface do usuário do Data Factory, na guia Autor, selecione + e, em seguida, selecione Conjunto de dados.
- Selecione Banco de Dados SQL do Azure e Continuar.
- Na janela Definir Propriedades, execute as etapas a seguir:
- Em Nome, insira ChangeTrackingDataset.
- Em Serviço vinculado, selecione AzureSqlDatabaseLinkedService.
- Em Nome da tabela, selecione dbo.table_store_ChangeTracking_version.
- Em Importar esquema, selecione a opção De conexão/repositório.
- Selecione OK.
Criar um pipeline para a cópia completa
No procedimento a seguir, crie um pipeline com uma atividade de cópia que copia todos os dados de armazenamento de dados de origem (Banco de Dados SQL do Azure) para o armazenamento de dados de destino (Armazenamento de Blobs do Azure):
Na interface do usuário do Data Factory, na guia Autor, selecione + e, em seguida, selecione Pipeline de >Pipeline.
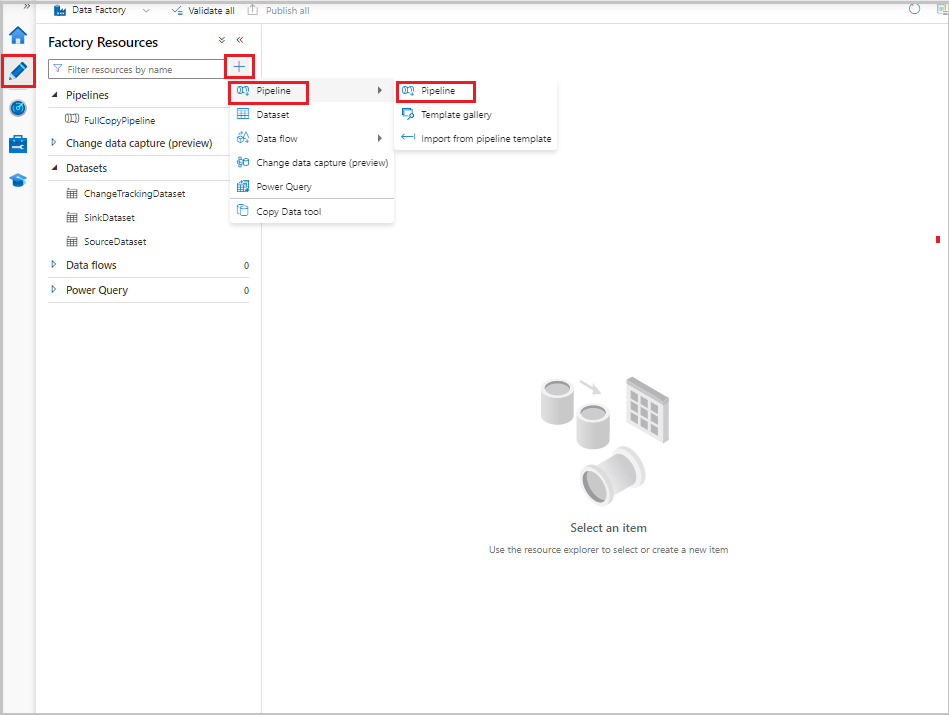
Uma nova guia é exibida para a configuração do pipeline. O pipeline também aparece no modo de exibição de árvore. Na janela Propriedades, altere o nome do pipeline para FullCopyPipeline.
Na caixa de ferramentas Atividades, expanda Mover e transformar. Siga uma destas etapas:
- Arraste a atividade de cópia para a superfície do designer de pipeline.
- Na barra de pesquisa em Atividades, pesquise a atividade copiar dados e defina o nome como FullCopyActivity.
Alterne para a guia Origem. Em Conjunto de Dados de Origem, selecione SourceDataset.
Alterne para a guia Coletor. Em Conjunto de Dados do Coletor, selecione SinkDataset.
Para validar a definição do pipeline, selecione Validar na barra de ferramentas. Confirme se não houver nenhum erro de validação. Feche a saída de validação do pipeline.
Para publicar entidades (serviços vinculados, conjuntos de dados e pipelines), selecione Publicar tudo. Aguarde até que você veja a mensagem Publicado com êxito.
Para ver as notificações, selecione o botão Mostrar Notificações.
Executar o pipeline de cópia completa
Na interface do usuário do Data Factory, na barra de ferramentas do pipeline, selecione Adicionar gatilho e, em seguida, selecione Disparar agora.
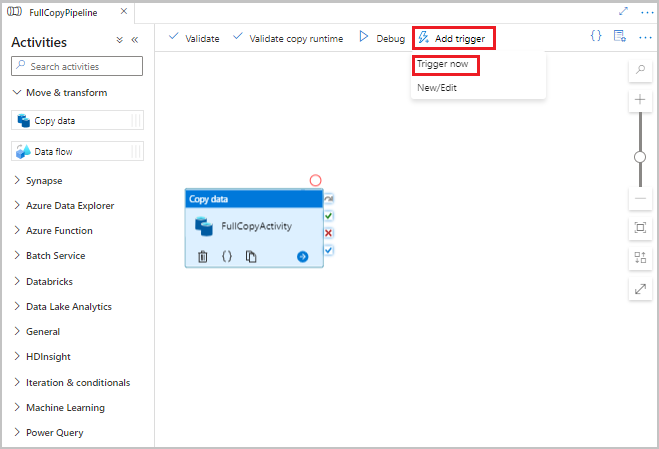
Na janela Executar pipeline selecione OK.

Monitorar o pipeline de cópia completa
Na interface do usuário do Data Factory, selecione a guia Monitorar. A execução do pipeline e seu status aparecem na lista. Para atualizar a lista, selecione Atualizar. Passe o mouse sobre a execução do pipeline para obter a opção Executar novamente ou Consumo.
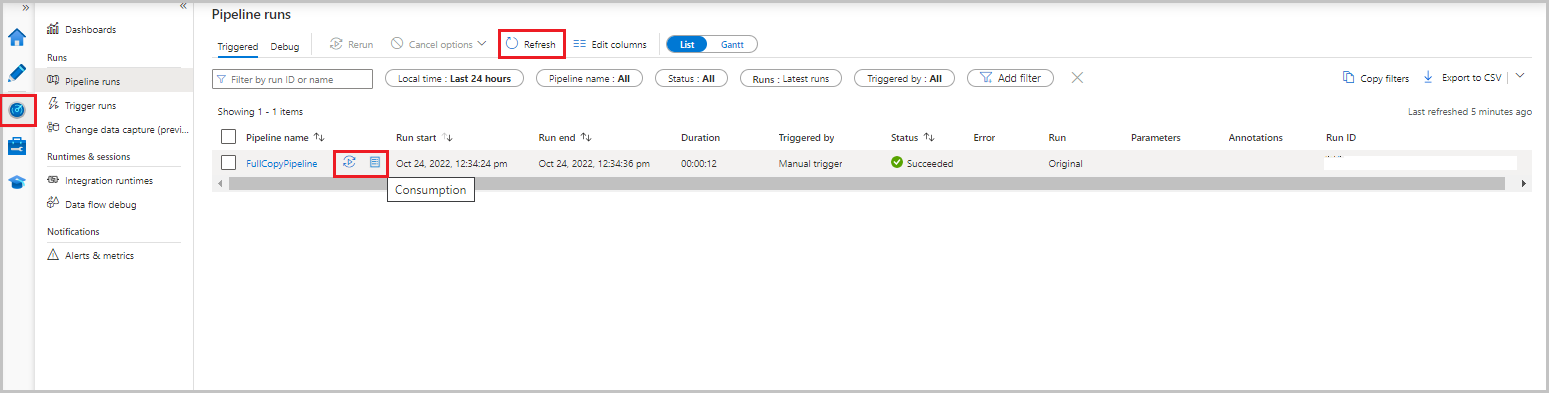
Para exibir as execuções de atividade associadas à execução de pipeline, selecione o nome do pipeline na coluna Nome do pipeline. Há apenas uma atividade no pipeline, portanto, há apenas uma entrada na lista. Para voltar à exibição das execuções de pipeline, selecione o link Todos os pipelines são executados na parte superior.
Revise os resultados
A pasta incchgtracking do contêiner adftutorial inclui um arquivo chamado incremental-<GUID>.csv.
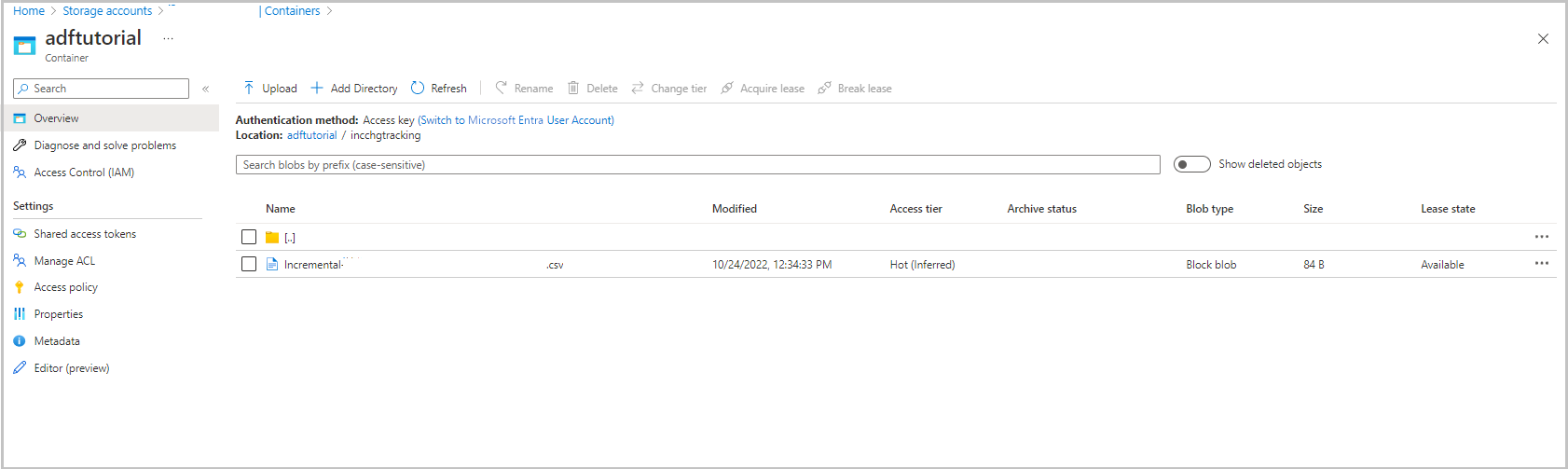
O arquivo deve ter os dados do seu banco de dados:
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Adicionar mais dados à tabela de origem
Execute a consulta a seguir no banco de dados para adicionar uma linha e atualizar uma linha:
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Criar um pipeline para a cópia delta
No procedimento a seguir, você cria um pipeline com as atividades e execute-o periodicamente. Ao executar o pipeline:
- As atividades de pesquisa obtêm os valores
SYS_CHANGE_VERSIONnovo e antigo do Banco de Dados SQL do Azure e os passam para a atividade de cópia. - A atividade de cópia copia os dados inseridos, atualizados ou excluídos entre os dois valores
SYS_CHANGE_VERSIONdo Banco de Dados SQL do Azure para o Armazenamento de Blobs do Azure. - A atividade de procedimento armazenado atualiza o valor de
SYS_CHANGE_VERSIONpara a próxima execução do pipeline.
Na interface do usuário do Data Factory, alterne para a guia Autor. Selecione + e, em seguida, selecione Pipeline de >Pipeline.
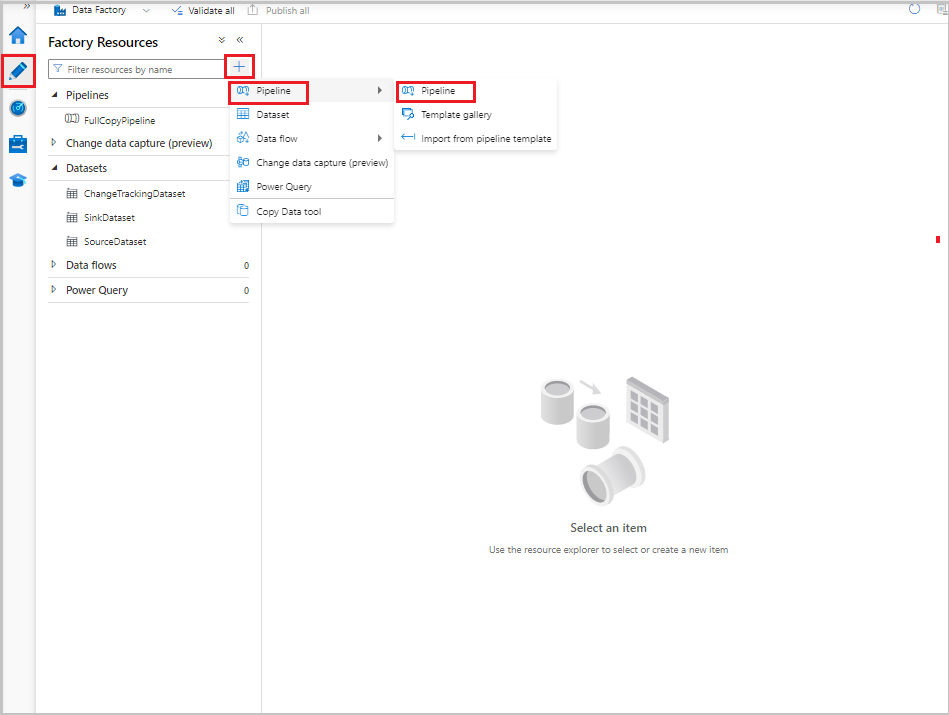
Uma nova guia é exibida para a configuração do pipeline. O pipeline também aparece no modo de exibição de árvore. Na janela Propriedades, altere o nome do pipeline para IncrementalCopyPipeline.
Expanda a opção Geral na caixa de ferramentas Atividades. Arraste a atividade de pesquisa para a superfície do designer de pipeline ou pesquise na caixa Pesquisar atividades. Defina o nome da atividade como LookupLastChangeTrackingVersionActivity. Essa atividade obtém a versão de controle de alterações usada na última operação de cópia armazenada na tabela
table_store_ChangeTracking_version.Alterne para a guia Configurações na janela Propriedades. Em Conjunto de Dados de Origem, selecione ChangeTrackingDataset.
Arraste a atividade de pesquisa da caixa de ferramentas Atividades para a superfície do designer do pipeline. Defina o nome da atividade como LookupCurrentChangeTrackingVersionActivity. Essa atividade obtém a versão atual de controle de alterações.
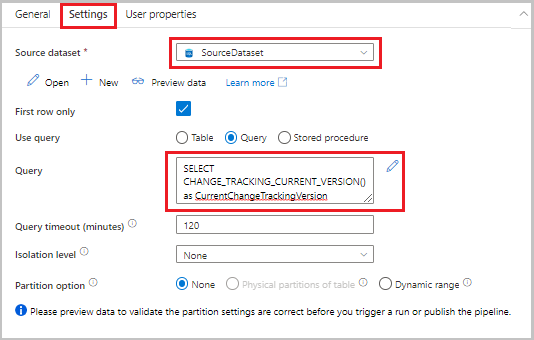
Alterne para a guia Configurações na janela Propriedades e execute as etapas a seguir:
Em Conjunto de dados de origem, selecione SourceDataset.
Em Usar consulta, selecione Consulta.
Em Consulta, insira a seguinte consulta SQL:
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
Na caixa de ferramentas Atividades, expanda Mover e transformar. Arraste a atividade de dados de cópia para a superfície do designer de pipeline. Defina o nome da atividade como IncrementalCopyActivity. Esta atividade copia os dados entre a última versão de controle de alterações e a versão atual de controle de alterações para o armazenamento de dados de destino.
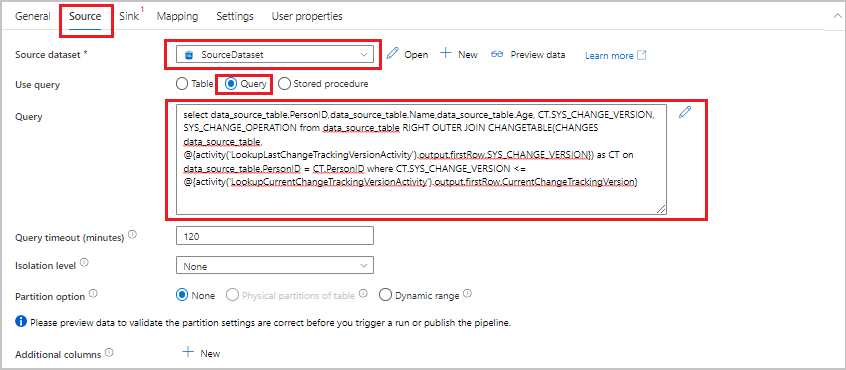
Alterne para a guia Origem na janela Propriedades e execute as etapas a seguir:
Em Conjunto de dados de origem, selecione SourceDataset.
Em Usar consulta, selecione Consulta.
Em Consulta, insira a seguinte consulta SQL:
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
Alterne para a guia Coletor. Em Conjunto de Dados do Coletor, selecione SinkDataset.
Conecte ambas as atividades de pesquisa à atividade de cópia, uma por uma. Arraste o botão verde que está anexado à atividade de pesquisa para a atividade de cópia.
Arraste a atividade de procedimento armazenado da caixa de ferramentas Atividades para a superfície do designer de pipeline. Defina o nome da atividade como StoredProceduretoUpdateChangeTrackingActivity. Essa atividade atualiza a versão de controle de alterações na tabela
table_store_ChangeTracking_version.Alterne para a guia Configurações e execute as etapas a seguir:
- Em Serviço vinculado, selecione AzureSqlDatabaseLinkedService.
- Para o Nome do procedimento armazenado, selecione Update_ChangeTracking_Version.
- Selecione Importar.
- Na seção Parâmetros de procedimento armazenado, especifique os seguintes valores para os parâmetros:
Nome Tipo Valor CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}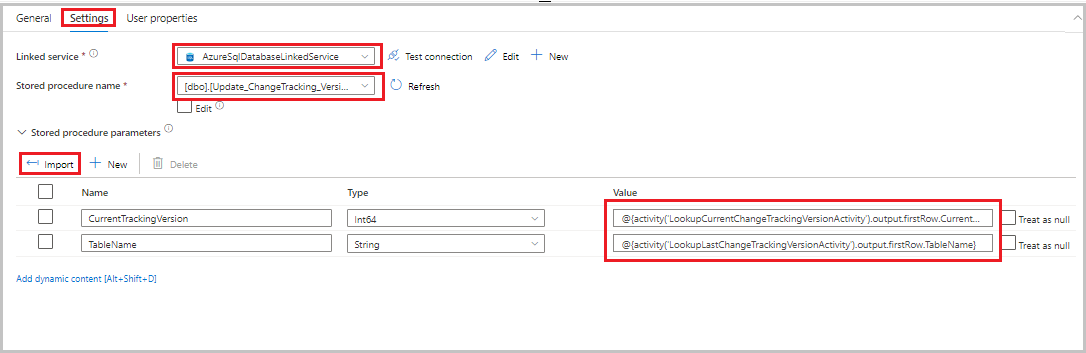
Conecte a atividade de cópia à atividade de procedimento armazenado. Arraste o botão verde que está anexado à atividade de cópia para a atividade de procedimento armazenado.
Selecione Validar na barra de ferramentas. Confirme se não houver nenhum erro de validação. Feche a janela Relatório de validação do pipeline.
Publique as entidades (serviços vinculados, conjuntos de dados e pipelines) para o serviço do Data Factory selecionando o botão Publicar tudo. Aguarde até que a mensagem Publicado com êxito seja exibida.
Executar o pipeline de cópia incremental
Selecione Adicionar gatilho na barra de ferramentas do pipeline e selecione Disparar agora.
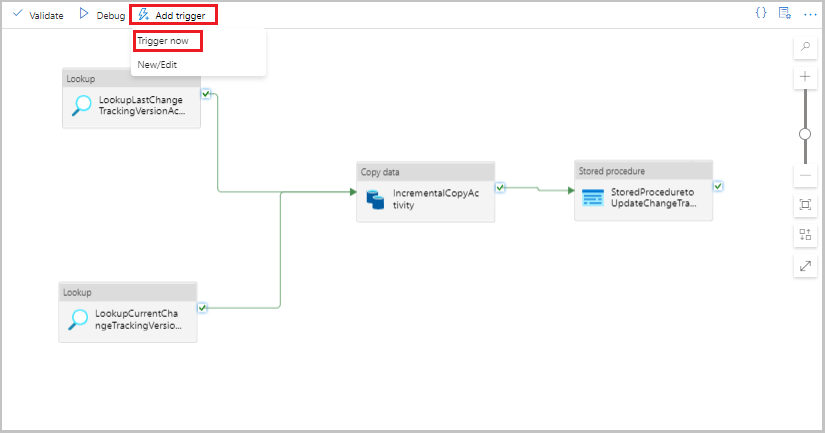
Na janela Executar Pipeline selecione OK.
Monitorar o pipeline de cópia incremental
Selecione a guia Monitorar. A execução do pipeline e seu status aparecem na lista. Para atualizar a lista, selecione Atualizar.
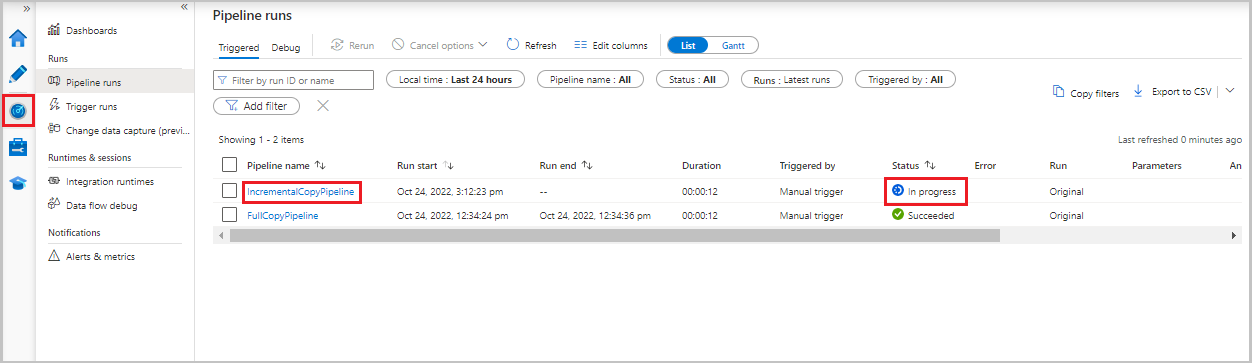
Para exibir as execuções de atividade associadas à execução do pipeline, selecione o link IncrementalCopyPipeline na coluna Nome do pipeline. As execuções de atividade aparecem em uma lista.

Revise os resultados
O segundo arquivo aparece na pasta incchgtracking do contêiner adftutorial.

O arquivo deve ter apenas os dados delta do seu banco de dados. O registro com U é a linha atualizada no banco de dados, e I é aquele adicionado à linha.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
As três primeiras colunas são dados alterados do data_source_table. As duas últimas colunas são os metadados da tabela para o sistema de controle de alterações. A quarta coluna é o valor SYS_CHANGE_VERSION de cada linha alterada. A quinta coluna é a operação: U = atualização, I = inserir. Para obter detalhes sobre as informações de controle de alterações, consulte CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Conteúdo relacionado
Avance para o tutorial seguinte para saber mais sobre como copiar somente arquivos novos e alterados, com base na LastModifiedDate: