Copiar novos arquivos de forma incremental com base no nome do arquivo particionado por tempo usando a ferramenta Copiar Dados
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você pode usar o portal do Azure para criar um Data Factory. Em seguida, você usa a ferramenta Copiar Dados para criar um pipeline que copia novos arquivos de forma incremental com base no nome do arquivo particionado por tempo do armazenamento de Blob do Azure para o armazenamento de Blob do Azure.
Observação
Se estiver se familiarizando com o Azure Data Factory, confira Introdução ao Azure Data Factory.
Neste tutorial, você executa as seguintes etapas:
- Criar um data factory.
- Usar a ferramenta Copy Data para criar um pipeline.
- Monitore as execuções de pipeline e de atividade.
Pré-requisitos
- Assinatura do Azure: Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Conta de armazenamento do Azure: use o armazenamento de Blob como o armazenamento de dados de origem e coletor. Se você não tiver uma conta de armazenamento do Azure, confira as instruções em Criar uma conta de armazenamento.
Criar dois contêineres no armazenamento de Blob
Prepare seu armazenamento de Blob para o tutorial seguindo estas etapas.
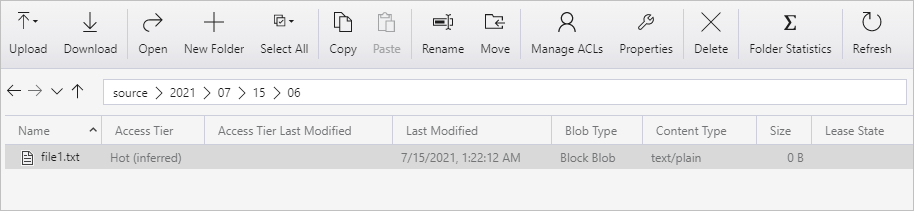
Crie um contêiner chamado origem. Crie um caminho de pasta como 2021/07/15/06 em seu contêiner. Crie um arquivo de texto vazio e nomeie-o file1.txt. Carregue o file1.txt no caminho da pasta origem/2021/07/15/06 em sua conta de armazenamento. É possível usar várias ferramentas para executar essas tarefas, como o Azure Storage Explorer.
Observação
Ajuste o nome da pasta com a sua hora UTC. Por exemplo, se a hora UTC atual for 6:10 em 15 de julho de 2021, você poderá criar o caminho da pasta como origem/2021/07/15/06/ pela regra de origem/{Ano}/{Mês}/{Dia}/{Hora}/ .
Crie um contêiner chamado destino. É possível usar várias ferramentas para executar essas tarefas, como o Azure Storage Explorer.
Criar uma data factory
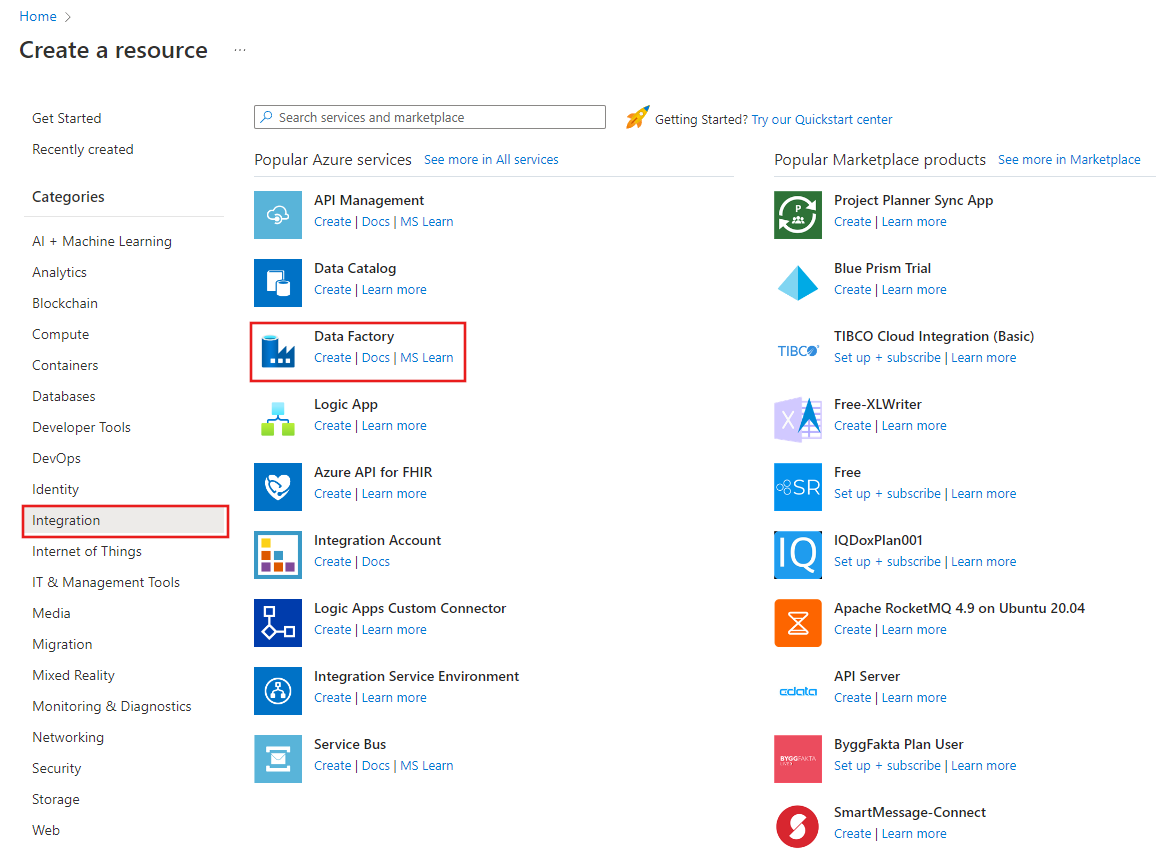
No menu à esquerda, selecione Criar um recurso>Integração>Data Factory:
Na página Novo data factory, em Nome, insira ADFTutorialDataFactory.
O nome do seu data factory deve ser globalmente exclusivo. Você deve ver a seguinte mensagem de erro:
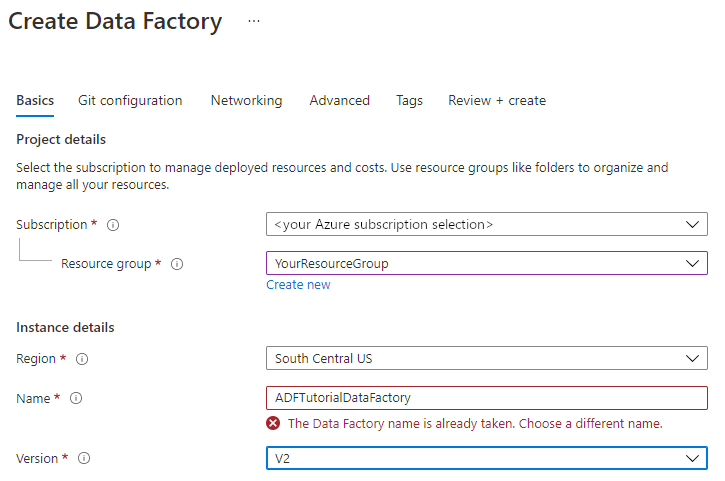
Se você receber uma mensagem de erro sobre o valor do nome, insira um nome diferente para o data factory. Por exemplo, use o nome seunomeADFTutorialDataFactory. Para ver as regras de nomenclatura de artefatos do Data Factory, confira Regras de nomenclatura do Data Factory.
Selecione a assinatura do Azure na qual deseja criar o novo data factory.
Em Grupo de Recursos, use uma das seguintes etapas:
a. Selecione Usar existentee selecione um grupo de recursos existente na lista suspensa.
b. Selecione Criar novoe insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, confira Usar grupos de recursos para gerenciar recursos do Azure.
Em versão, selecione V2 para a versão.
Em local, selecione o local para o data factory. Somente os locais com suporte são exibidos na lista suspensa. Os armazenamentos de dados (por exemplo, Armazenamento do Azure e Banco de Dados SQL) e os serviços de computação (por exemplo, Azure HDInsight) usados pelo seu data factory podem estar em outros locais e regiões.
Selecione Criar.
Depois de finalizada a criação, a home page do Data Factory é exibida.
Para iniciar a interface do usuário (IU) do Azure Data Factory em uma guia separada, selecione Abrir no bloco Open Azure Data Factory Studio.

Usar a ferramenta Copy Data para criar um pipeline
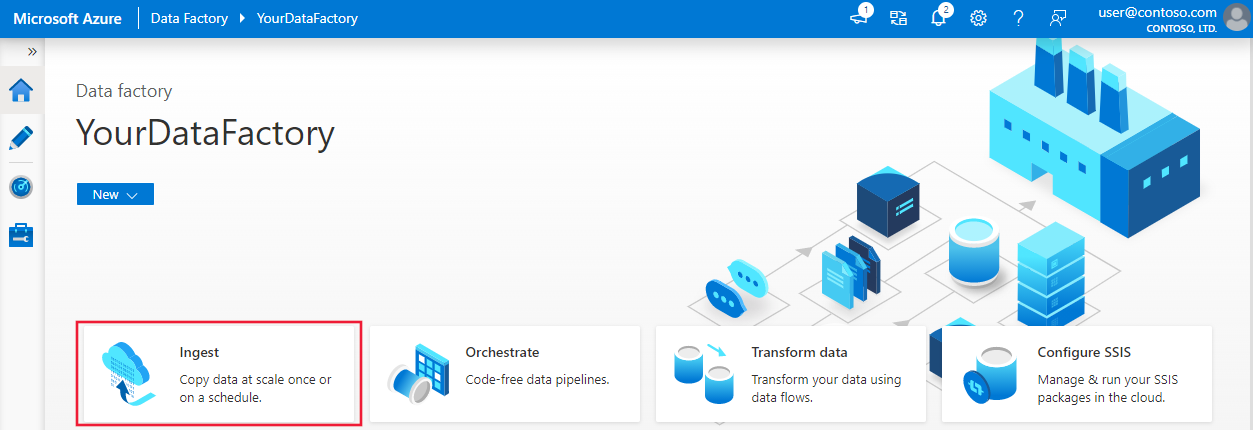
Na página inicial do ADF (Azure Data Factory), selecione Ingerir para iniciar a ferramenta Copiar Dados.
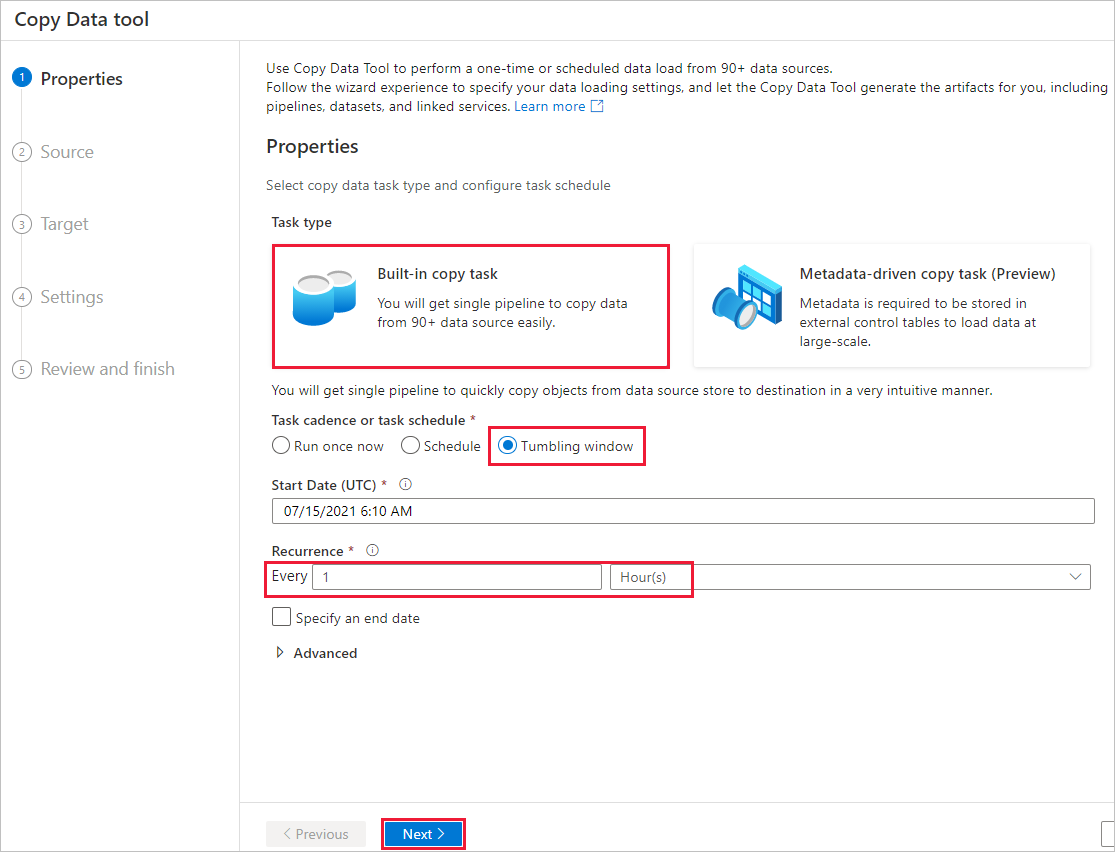
Na página Propriedades, execute as seguintes etapas:
Em Tipo de tarefa, selecione Tarefa de cópia interna.
Em Cadência da tarefa ou Agendamento da tarefa, selecione Janela em cascata.
Em Recorrência, insira 1 hora(s) .
Selecione Avançar.
Na página Configurações do armazenamento de dados, conclua as seguintes etapas:
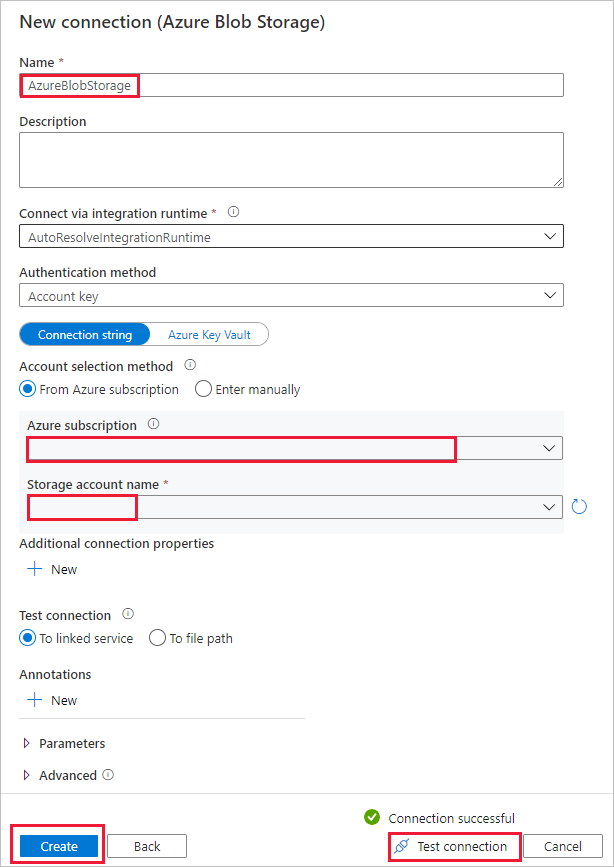
a. Selecione + Criar conexão para adicionar uma conexão.
b. Selecione Armazenamento de Blobs do Azure na galeria e, em seguida, selecione Continuar.
c. Na página Nova conexão (Armazenamento de Blobs do Azure) , especifique um nome para a conexão. Selecione a assinatura do Azure e a conta de armazenamento na lista Nome da conta de armazenamento. Teste a conexão e, em seguida, selecione Concluir.
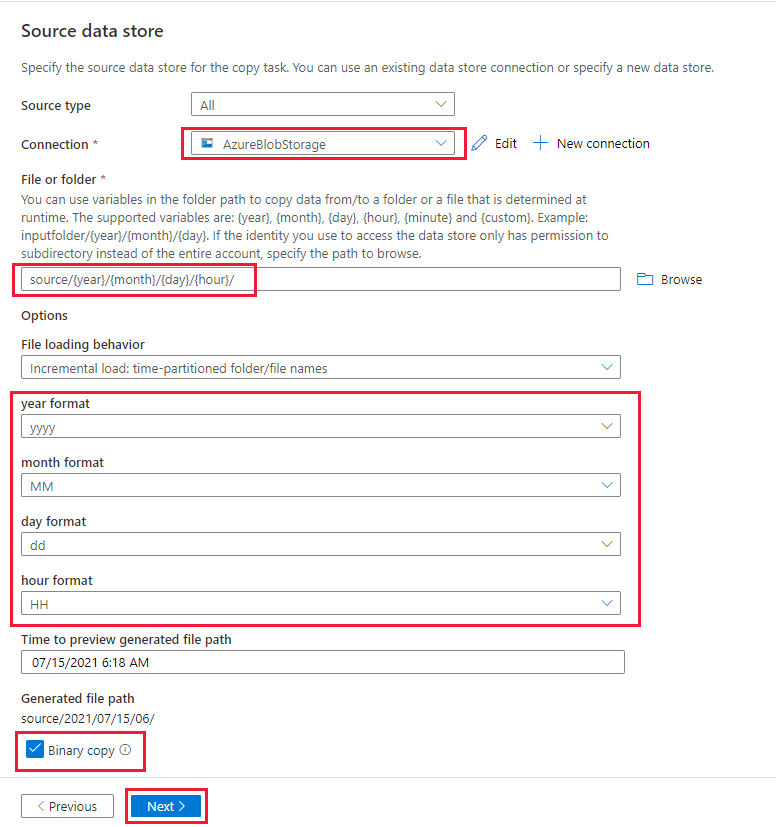
d. Na página Armazenamento de dados de origem, selecione a conexão criada recentemente na seção Conexão.
e. Na seção Arquivo ou pasta, procure e selecione o contêiner de origem e selecione OK.
f. Em Comportamento de carregamento de arquivo, selecione Carga incremental: nomes da pasta/arquivo particionados por tempo.
g. Grave o caminho da pasta dinâmica como origem/{ano}/{mês}/{dia}/{hora}/ e altere o formato, conforme mostrado na captura de tela a seguir.
h. Marque Cópia binária e clique em Avançar.
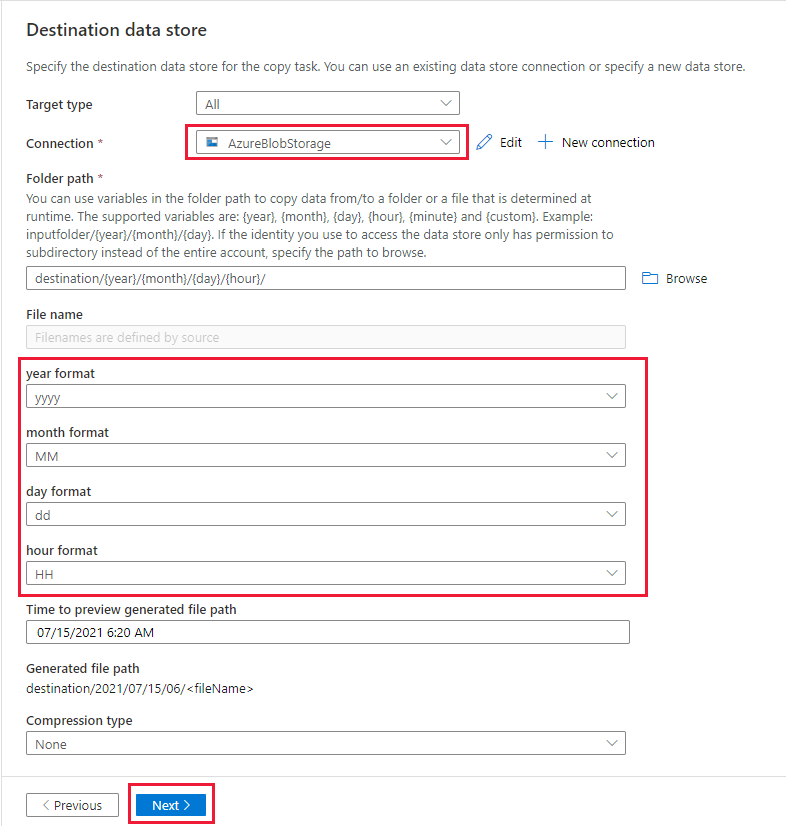
Na página Armazenamento de dados de destino, conclua as etapas a seguir:
Selecione AzureBlobStorage, que é a mesma conta de armazenamento do armazenamento de fonte de dados.
Procure e selecione a pasta de destino e clique em OK.
Grave o caminho da pasta dinâmica como origem/{ano}/{mês}/{dia}/{hora}/ e altere o formato, conforme mostrado na captura de tela a seguir.
Selecione Avançar.
Na página Configurações, em Nome da tarefa, insira DeltaCopyFromBlobPipeline e selecione Avançar. A interface do usuário do Data Factory cria um pipeline com o nome especificado da tarefa.
Na página Resumo, analise as configurações e selecione Avançar.
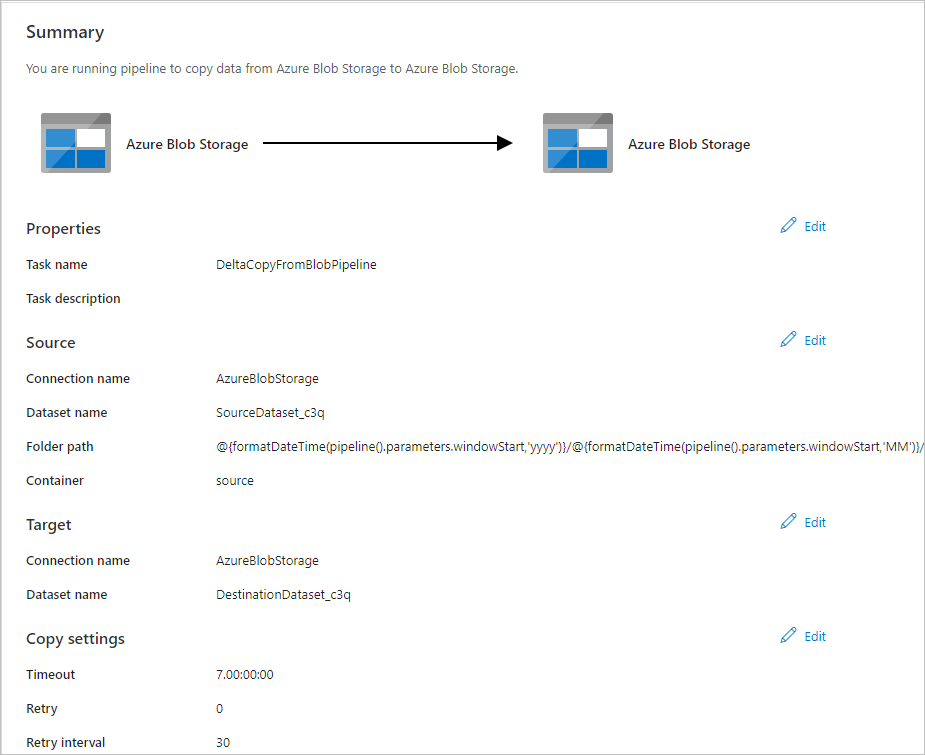
Na página Implantação, selecione Monitorar para monitorar o pipeline (tarefa).
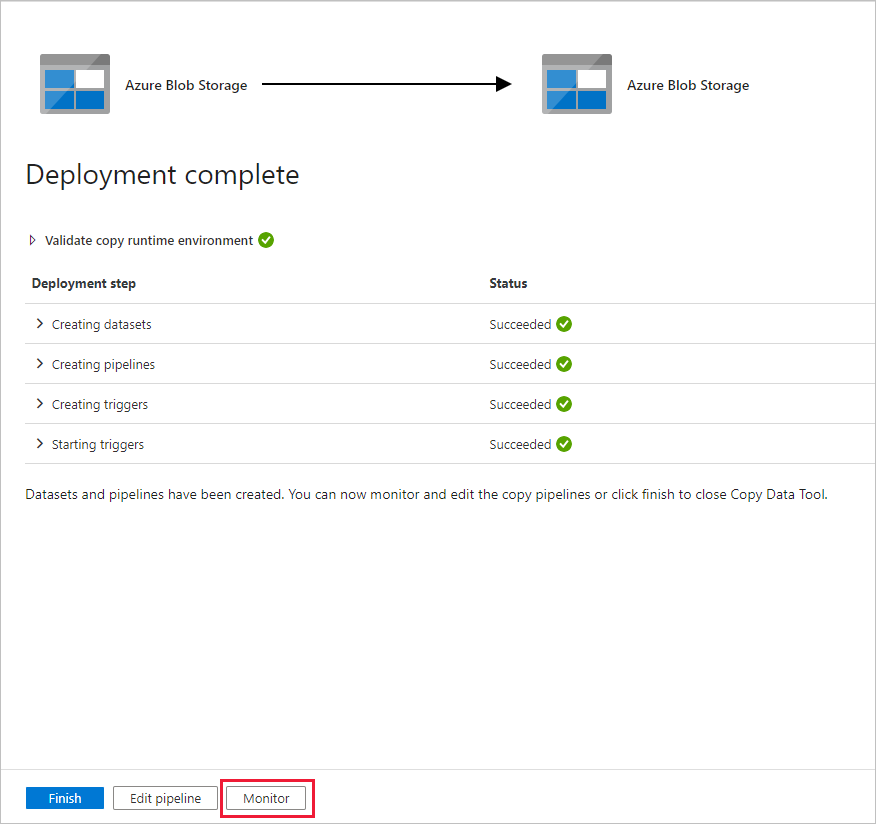
Observe que a guia Monitor à esquerda é selecionada automaticamente. Você precisa aguardar a execução do pipeline quando ele for disparado automaticamente (cerca de uma hora). Quando ele for executado, clique no link do nome do pipeline DeltaCopyFromBlobPipeline para exibir os detalhes da execução da atividade ou execute novamente o pipeline. Selecione Atualizar para atualizar a lista.
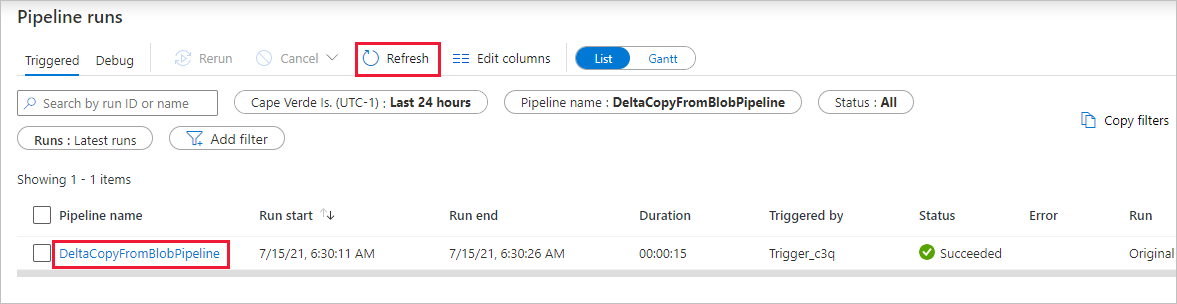
Há apenas uma atividade (atividade de cópia) no pipeline. Assim, você vê apenas uma entrada. Ajuste a largura das colunas de Origem e de Destino (se necessário) para exibir mais detalhes. Você pode ver que o arquivo de origem (file1.txt) foi copiado de origem/2021/07/15/06/ para destino/2021/07/15/06/ com o mesmo nome de arquivo.
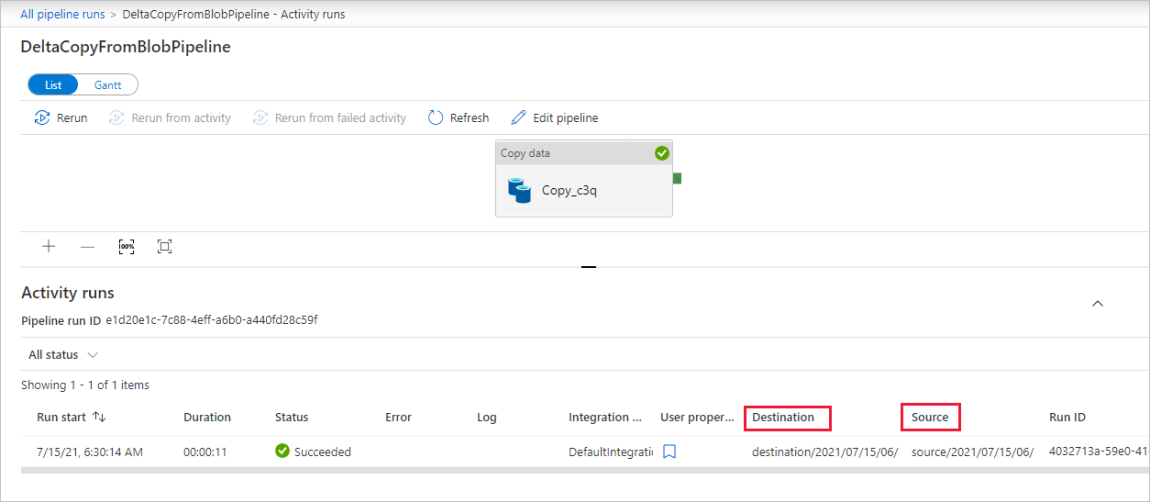
Você também pode verificar o mesmo usando o Gerenciador de Armazenamento do Azure (https://storageexplorer.com/) para verificar os arquivos.
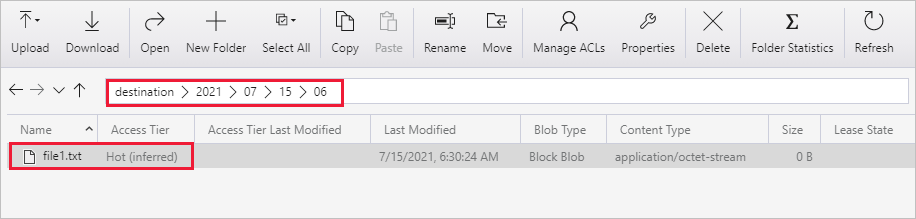
Crie outro arquivo de texto vazio com o novo nome como file2.txt. Carregue o arquivo file2.txt no caminho da pasta origem/2021/07/15/07 em sua conta de armazenamento. É possível usar várias ferramentas para executar essas tarefas, como o Azure Storage Explorer.
Observação
Você deve estar ciente de que um novo caminho de pasta deve ser criado. Ajuste o nome da pasta com a sua hora UTC. Por exemplo, se a hora UTC atual for 7:30 em 15 de julho de 2021, você poderá criar o caminho da pasta como origem/2021/07/15/07/ pela regra de {ano}/{mês}/{dia}/{hora}/ .
Para voltar à exibição Execução de pipeline, selecione Todas as execuções de pipeline e aguarde até que o mesmo pipeline seja disparado novamente automaticamente após outra hora.
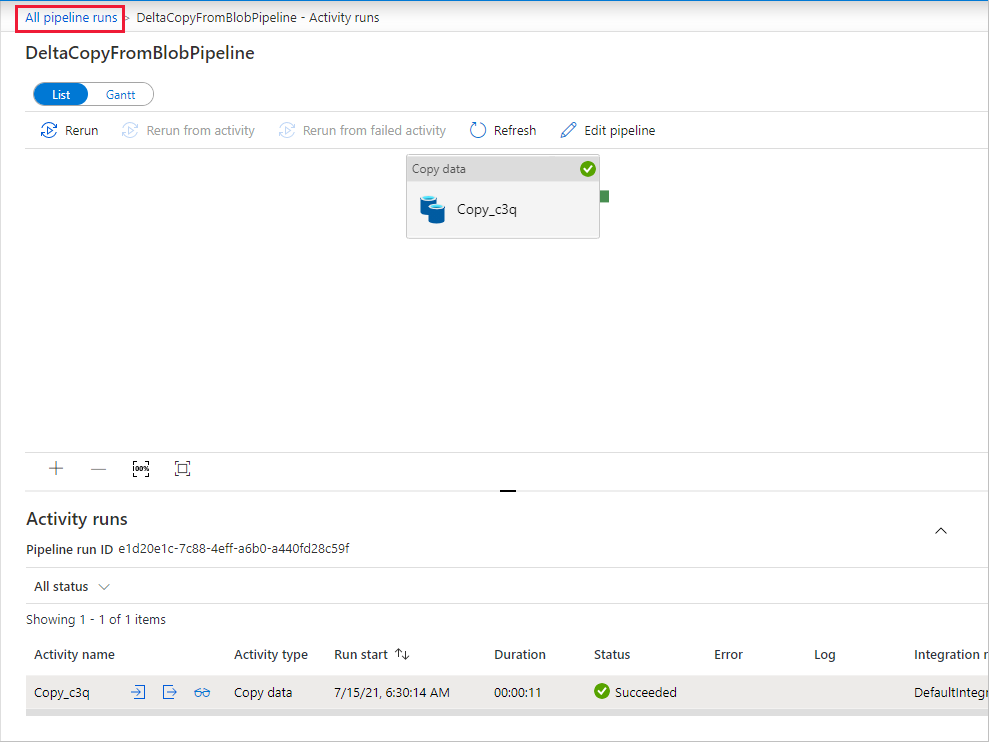
Selecione o novo link DeltaCopyFromBlobPipeline para a segunda execução de pipeline quando ele chegar e faça o mesmo para revisar os detalhes. Você verá que o arquivo de origem (file2.txt) foi copiado de origem/2021/07/15/07/ para destino/2021/07/15/07/ com o mesmo nome de arquivo. Você também pode verificar o mesmo usando o Gerenciador de Armazenamento do Azure (https://storageexplorer.com/) para verificar os arquivos no contêiner de destino.
Conteúdo relacionado
Avance para o tutorial a seguir para saber mais sobre como transformar dados usando um cluster Spark no Azure: