Comece a usar: Consultar e visualizar os dados de um notebook
Este artigo de introdução orienta você no uso de um notebook do Azure Databricks para consultar dados de amostra armazenados no Catálogo do Unity usando SQL, Python, Scala e R e, em seguida, visualizar os resultados da consulta no notebook.
Requisitos
Para concluir as tarefas neste artigo, você deve atender aos seguintes requisitos:
- Seu espaço de trabalho deve ter o Catálogo do Unity habilitado. Para obter informações sobre como começar a usar o Catálogo do Unity, consulte Configurar e gerenciar o Catálogo do Unity.
- Você deve ter permissão para usar um recurso de computação existente ou criar um recurso de computação. Consulte Introdução ao Azure Databricks ou entre em contato com o administrador do Databricks.
Etapa 1: Criar um notebook
Para criar um bloco de notas na sua área de trabalho, clique em ![]() Novo na barra lateral e, em seguida, clique em Notebook. Um notebook em branco é aberto no workspace.
Novo na barra lateral e, em seguida, clique em Notebook. Um notebook em branco é aberto no workspace.
Para saber mais sobre como criar e gerenciar notebooks, consulte Gerenciar notebooks.
Etapa 2: Consultar uma tabela
Consulte a tabela samples.nyctaxi.trips no Catálogo do Unity usando o idioma de sua preferência.
Copie e cole o código a seguir na nova célula vazia do notebook. Esse código exibe os resultados da consulta da tabela
samples.nyctaxi.tripsno Catálogo do Unity.SQL
SELECT * FROM samples.nyctaxi.tripsPython
display(spark.read.table("samples.nyctaxi.trips"))Scala
display(spark.read.table("samples.nyctaxi.trips"))R
library(SparkR) display(sql("SELECT * FROM samples.nyctaxi.trips"))Pressione
Shift+Enterpara executar a célula e depois mova para a próxima célula.Os resultados da consulta aparecem no notebook.
Etapa 3: Exibir os dados
Exiba o valor da tarifa média por distância de viagem, agrupada pelo código postal da coleta.
Ao lado da guia Tabela, clique + e, em seguida, clique em Visualização.
O editor de visualização é exibido.
Na lista suspensa Tipo de Visualização, verifique se a Barra está selecionada.
Selecione
fare_amountpara a coluna X.Selecione
trip_distancepara a coluna Y.Selecione
Averagecomo o tipo de agregação.Selecione
pickup_zipcomo a coluna Agrupar por.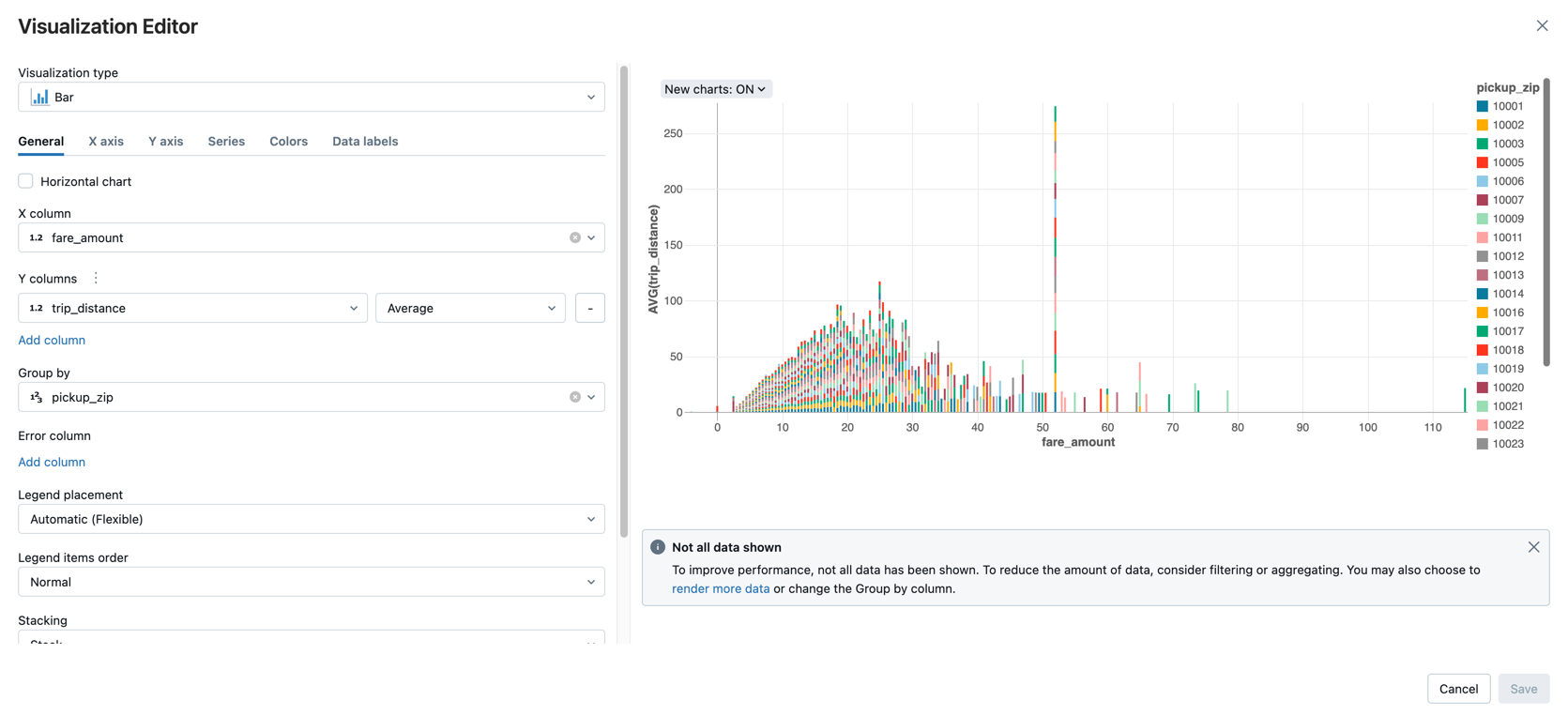
Clique em Save (Salvar).
Próximas etapas
- Para saber mais sobre como adicionar dados do arquivo CSV ao Catálogo do Unity e visualizar dados, veja Primeiros passos: importar e visualizar dados CSV de um notebook.
- Para saber como carregar dados no Databricks usando o Apache Spark, consulte Tutorial: Carregar e transformar dados usando o Apache Spark DataFrames.
- Para saber mais sobre a ingestão de dados no Databricks, consulte Ingerir dados em um Databricks Lakehouse.
- Para saber mais sobre como consultar dados com o Databricks, consulte Dados de consulta.
- Para saber mais sobre visualizações, consulte Visualizações em notebooks do Databricks.