Configurar computação para trabalhos
Este artigo contém recomendações e recursos para configurar a computação para trabalhos do Databricks.
Importante
As limitações da computação sem servidor para trabalhos incluem o seguinte:
- Não há suporte para agendamento contínuo.
- Não há suporte para gatilhos de intervalo padrão ou baseados em tempo no Streaming estruturado.
Para ver mais limitações, confira Limitações da computação sem servidor.
Cada trabalho pode ter uma ou mais tarefas. Você define recursos de computação para cada tarefa. Várias tarefas definidas para o mesmo trabalho podem usar o mesmo recurso de computação.
Qual é a computação recomendada para cada tarefa?
A tabela a seguir indica os tipos de computação recomendados e com suporte para cada tipo de tarefa.
Observação
A computação sem servidor para trabalhos tem limitações e não dá suporte a todas as cargas de trabalho. Confira Limitações de computação sem servidor.
| Tarefa | Computação recomendada | Computação com suporte |
|---|---|---|
| Notebooks | Trabalhos sem servidor | Trabalhos sem servidor, trabalhos clássica, clássica para todas as finalidades |
| Script Python | Trabalhos sem servidor | Trabalhos sem servidor, trabalhos clássica, clássica para todas as finalidades |
| Wheel Python | Trabalhos sem servidor | Trabalhos sem servidor, trabalhos clássica, clássica para todas as finalidades |
| SQL | SQL warehouse sem servidor | SQL warehouse sem servidor, SQL warehouse profissional |
| Pipeline do Delta Live Tables | Pipeline sem servidor | Pipeline sem servidor, pipeline clássico |
| dbt | SQL warehouse sem servidor | SQL warehouse sem servidor, SQL warehouse profissional |
| Comandos de CLI do dbt | Trabalhos sem servidor | Trabalhos sem servidor, trabalhos clássica, clássica para todas as finalidades |
| JAR | Trabalhos clássica | Trabalhos clássica, clássica para todas as finalidades |
| Spark Submit | Trabalhos clássica | Trabalhos clássica |
O preço dos trabalhos está vinculado à computação usada para executar tarefas. Para mais detalhes, confira Preços do Databricks.
Como configurar a computação para trabalhos?
A computação de trabalhos clássica é configurada diretamente na interface do usuário de trabalhos do Databricks e essas configurações fazem parte da definição de trabalho. Todos os outros tipos de computação disponíveis armazenam suas configurações com outros ativos de workspace. A tabela a seguir apresenta mais detalhes:
| Tipo de computação | Detalhes |
|---|---|
| Computação de trabalhos clássica | Você configura a computação de trabalhos clássica usando a mesma interface do usuário e as configurações disponíveis para computação para todas as finalidades. Consulte Referência de configuração de computação. |
| Computação sem servidor para trabalhos | A computação sem servidor para trabalhos é o padrão para todas as tarefas que dão suporte a ela. O Databricks gerencia as configurações de computação para computação sem servidor. Confira Executar seu trabalho do Azure Databricks com computação sem servidor para fluxos de trabalho. nn Um administrador de workspace deve habilitar a computação sem servidor para que essa opção fique visível. Confira Habilitar a computação sem servidor. |
| SQL warehouses | Os SQL warehouses sem servidor e profissional são configurados por administradores de workspace ou usuários com privilégios irrestritos de criação de cluster. Você configura tarefas para execução em SQL warehouses existentes. Confira Conectar-se a um depósito SQL. |
| Computação de pipeline do Delta Live Tables | Você define as configurações de computação para pipelines do Delta Live Tables durante a configuração do pipeline. Consulte Configurar a computação para um pipeline do Delta Live Tables. nn O Azure Databricks gerencia recursos de computação para pipelines do Delta Live Tables sem servidor. Consulte Configurar um pipeline do Delta Live Tables sem servidor. |
| Computação para todas as finalidades | Opcionalmente, você pode configurar tarefas usando a computação clássica para todas as finalidades. O Databricks não recomenda essa configuração para trabalhos de produção. Confira Referência de configuração de computação e A computação para todas as finalidades deve ser usada para trabalhos?. |
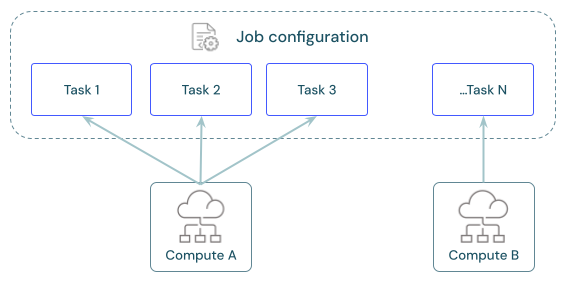
Compartilhar computação entre tarefas
Configure tarefas para usar os mesmos recursos de computação de trabalhos a fim de otimizar o uso de recursos com trabalhos que orquestram várias tarefas. O compartilhamento de computação entre tarefas pode reduzir a latência associada aos tempos de inicialização.
Você pode usar um único recurso de computação de trabalhos para executar todas as tarefas que façam parte do trabalho ou vários recursos de trabalho otimizados para cargas de trabalho específicas. Qualquer computação de trabalhos configurada como parte de um trabalho está disponível para todas as outras tarefas no trabalho.
A tabela a seguir destaca as diferenças entre a computação de trabalho configurada para uma única tarefa e a computação de trabalho compartilhada entre tarefas:
| Tarefa única | Compartilhado entre tarefas | |
|---|---|---|
| Iniciar | Quando a execução da tarefa começa. | Quando a primeira execução de tarefa configurada para usar o recurso de computação começa. |
| Encerrar | Após a execução da tarefa. | Após a execução da última tarefa configurada para usar o recurso de computação. |
| Computação ociosa | Não aplicável. | A computação permanece ativada e ociosa enquanto as tarefas que não usam o recurso de computação são executadas. |
Um cluster de trabalho compartilhado tem como escopo uma única execução de trabalho e não pode ser usado por outros trabalhos ou execuções do mesmo trabalho.
As bibliotecas não podem ser declaradas em uma configuração de cluster de trabalho compartilhado. Você precisa adicionar bibliotecas dependentes usando as configurações da tarefa.
Revisar, configurar e trocar computação de trabalhos
A seção Computação no painel Detalhes do trabalho lista todas as computações configuradas para tarefas no trabalho atual.
As tarefas configuradas para usar um recurso de computação são realçadas no gráfico de tarefas quando você passa o mouse sobre a especificação de computação.
Use o botão Trocar para alterar a computação de todas as tarefas associadas a um recurso de computação.
Os recursos de computação de trabalhos clássica têm uma opção Configurar. Outros recursos de computação oferecem opções para exibir e modificar detalhes de configuração de computação.
Recomendações para configurar a computação de trabalhos clássica
Esta seção se concentra em recomendações gerais sobre recursos e configurações que podem beneficiar alguns fluxos de trabalho. As recomendações específicas para configurar o tamanho e os tipos de recursos de computação variam de acordo com a carga de trabalho.
O Databricks recomenda habilitar o Photon Acceleration, usar versões recentes do Databricks Runtime e usar a computação configurada para o Catálogo do Unity.
A computação sem servidor para trabalhos gerencia toda a infraestrutura, com exceção dos seguintes fatores. Confira Executar seu trabalho do Azure Databricks com computação sem servidor para fluxos de trabalho.
Observação
Os fluxos de trabalho de Streaming estruturado têm recomendações específicas. Confira Considerações de produção para o Streaming estruturado.
Usar o modo de acesso compartilhado
O Databricks recomenda usar o modo de acesso compartilhado para trabalhos. Consulte Modos de acesso.
Observação
O modo de acesso compartilhado não dá suporte a algumas cargas de trabalho e recursos. O Databricks recomenda o modo de acesso de usuário individual para essas cargas de trabalho. Confira Limitações do modo de acesso de computação para o Catálogo do Unity.
Usar políticas de cluster
O Databricks recomenda que os administradores de workspace definam políticas de cluster para trabalhos e apliquem essas políticas para todos os usuários que configuram trabalhos.
As políticas de cluster permitem que os administradores do workspace definam controles de custo e limitem as opções de configuração dos usuários. Para obter detalhes sobre a configuração de políticas de cluster, confira Criar e gerenciar políticas de computação.
O Azure Databricks fornece uma política padrão configurada para trabalhos. Os administradores podem disponibilizar essa política para outros usuários do workspace. Confira Computação de trabalho.
Usar dimensionamento automático
Configure o dimensionamento automático para que as tarefas de longa duração possam adicionar e remover dinamicamente nós de trabalho durante as execuções de trabalho. Veja Habilitar escalonamento automático.
Usar um pool para reduzir os tempos de inicialização do cluster
Os pools de computação permitem que você reserve recursos de computação do seu provedor de nuvem. Os pools são benéficos para diminuir o tempo de início do novo cluster de trabalho e garantir a disponibilidade do recurso de computação. Confira Referência de configuração de pools.
Usar instâncias spot
Configure instâncias spot para cargas de trabalho que têm requisitos de latência flexíveis a fim de otimizar os custos. Confira Instâncias spot.
Devo usar a computação para todas as finalidades para trabalhos?
Há vários motivos pelos quais o Databricks recomenda não usar computação para todas as finalidades em trabalhos, incluindo o seguinte:
- O Azure Databricks cobra pela computação para todas as finalidades uma tarifa diferente da computação de trabalhos.
- A computação de trabalhos é encerrada automaticamente após a conclusão de uma execução de trabalho. A computação para todas as finalidades dá suporte ao encerramento automático, que está vinculado à inatividade e não ao fim de uma execução de trabalho.
- A computação para todas as finalidades é geralmente compartilhada entre equipes de usuários. Os trabalhos agendados em relação à computação para todas as finalidades geralmente têm uma maior latência devido à competição por recursos de computação.
- Muitas recomendações para otimizar a configuração de computação de trabalhos não são adequadas para o tipo de consultas ocasionais e cargas de trabalho interativas executadas em computação para todas as finalidades.
Veja a seguir os casos de uso em que você pode optar por usar a computação para todas as finalidades em trabalhos:
- Você está desenvolvendo ou testando novos trabalhos iterativamente. Os tempos de inicialização da computação de trabalhos podem tornar o desenvolvimento iterativo tedioso. A computação para todas as finalidades permite que você aplique alterações e execute seu trabalho rapidamente.
- Você tem trabalhos de curta duração que devem ser executados com frequência ou segundo um cronograma específico. Não há tempo de inicialização associado à computação para todas as finalidades em execução. Considere os custos associados ao tempo ocioso se estiver usando esse padrão.
A computação sem servidor para trabalhos é a substituta recomendada para a maioria dos tipos de tarefas que você considere executar em relação à computação para todas as finalidades.