Databricks Runtime para Machine Learning
O Databricks Runtime for Machine Learning (Databricks Runtime ML) automatiza a criação de um cluster com infraestrutura pré-construída de aprendizado de máquina e aprendizado profundo, incluindo as bibliotecas de ML e DL mais comuns. Para obter a lista completa de bibliotecas em cada versão do Databricks Runtime ML, consulte as notas de versão.
Nota
Para acessar dados no Unity Catalog para fluxos de trabalho de aprendizado de máquina, o modo de acesso para o cluster deve ser de usuário único (atribuído). Os clusters compartilhados não são compatíveis com o Databricks Runtime for Machine Learning. Além disso, o Databricks Runtime ML não é suportado em clusters TableACLs ou clusters com spark.databricks.pyspark.enableProcessIsolation config definido como true.
Criar um cluster usando o Databricks Runtime ML
Ao criar um cluster, selecione uma versão do Databricks Runtime ML no menu suspenso Databricks runtime version . Os tempos de execução de ML habilitados para CPU e GPU estão disponíveis.
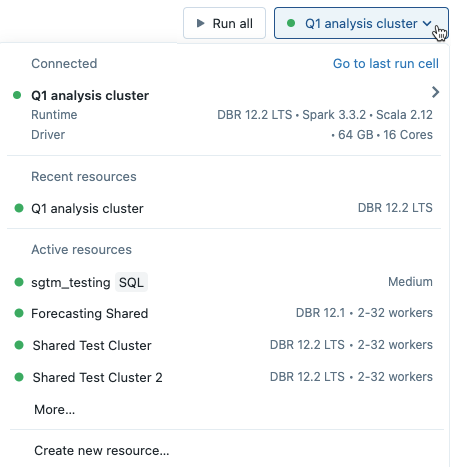
Se você selecionar um cluster no menu suspenso do bloco de anotações, a versão do Databricks Runtime aparecerá à direita do nome do cluster:
Se você selecionar um tempo de execução de ML habilitado para GPU, será solicitado que você selecione um tipo de driver e um tipo de trabalhador compatíveis. Os tipos de instância incompatíveis ficam acinzentados no menu suspenso. Os tipos de instância habilitados para GPU estão listados sob o rótulo acelerado por GPU. Para obter informações sobre como criar clusters de GPU do Azure Databricks, consulte Computação habilitada para GPU. O Databricks Runtime ML inclui controladores de hardware de GPU e bibliotecas da NVIDIA, como a CUDA.
ML de tempo de execução de Photon e Databricks
Ao criar um cluster de CPU executando o Databricks Runtime 15.2 ML ou superior, você pode optar por habilitar o Photon. Photon melhora o desempenho para aplicativos que usam Spark SQL, Spark DataFrames, engenharia de recursos, GraphFrames e xgboost4j. Não se espera que melhore o desempenho em aplicativos que usam RDDs Spark, UDFs Pandas e linguagens não-JVM, como Python. Assim, pacotes Python como XGBoost, PyTorch e TensorFlow não verão uma melhoria com o Photon.
As APIs do Spark RDD e o Spark MLlib têm compatibilidade limitada com o Photon. Ao processar grandes conjuntos de dados usando o Spark RDD ou o Spark MLlib, você pode enfrentar problemas de memória do Spark. Consulte Problemas de memória do Spark.
Bibliotecas incluídas no Databricks Runtime ML
O Databricks Runtime ML inclui uma variedade de bibliotecas de ML populares. As bibliotecas são atualizadas a cada versão para incluir novos recursos e correções.
O Databricks designou um subconjunto das bibliotecas suportadas como bibliotecas de camada superior. Para essas bibliotecas, o Databricks fornece uma cadência de atualização mais rápida, atualizando para as versões de pacotes mais recentes a cada versão de tempo de execução (excluindo conflitos de dependência). O Databricks também fornece suporte avançado, testes e otimizações incorporadas para bibliotecas de nível superior.
Para obter uma lista completa de bibliotecas de nível superior e outras bibliotecas fornecidas, consulte as notas de versão do Databricks Runtime ML.
Você pode instalar bibliotecas adicionais para criar um ambiente personalizado para seu bloco de anotações ou cluster.
- Para disponibilizar uma biblioteca para todos os blocos de anotações em execução em um cluster, crie uma biblioteca de cluster. Você também pode usar um script init para instalar bibliotecas em clusters durante a criação.
- Para instalar uma biblioteca que está disponível apenas para uma sessão específica do bloco de anotações, use bibliotecas Python com escopo de bloco de anotações.