Exemplo de Registro de Modelos do Workspace
Observação
Esta documentação aborda o Registro de Modelo do Workspace. O Azure Databricks recomenda o uso de Modelos no Catálogo do Unity. Os modelos no Catálogo do Unity fornecem governança de modelo centralizada, acesso entre workspaces, linhagem e implantação. O Registro de Modelo de Workspace será preterido no futuro.
Esse exemplo ilustra como usar o Registro de Modelo do Espaço de Trabalho para criar um aplicativo de machine learning que prevê a saída de energia diária de um parque eólico. O exemplo mostra como:
- Rastrear e registrar modelos com o MLflow
- Registrar modelos no Registro de Modelo
- Descrever modelos e tornar transições de estágio de versão do modelo
- Integrar modelos registrados com aplicativos de produção
- Pesquisar e descobrir modelos no Registro de Modelo
- Arquivar e excluir modelos
O artigo descreve como executar essas etapas usando as interfaces do usuário MLflow Tracking, MLflow Model e APIs.
Para um bloco de anotações que executa todas essas etapas usando as APIs de registro e acompanhamento de MLflow, consulte o exemplo de bloco de anotações de Registro de Modelo.
Carregar conjunto de dados, treinar modelo e acompanhar com acompanhamento de MLflow
Antes de poder registrar um modelo no registro de modelo, você deve primeiro treinar e registrar o modelo durante uma execução de experimento. Esta seção mostra como carregar o conjunto de registros do farm de vento, treinar um modelo e registrar em log a execução do treinamento em MLflow.
Carregar conjunto de dados
O código a seguir carrega um conjunto de dados que contém informações de tempo e de saída de energia para um farm de vento no Estados Unidos. O conjunto de resultados contémwind direction, wind speed e air temperature. Os recursos são amostrados a cada seis horas (uma vez às 00:00, uma vez às 08:00 e uma vez às 16:00), bem como a saída de energia de agregação diária (power), em vários anos.
import pandas as pd
wind_farm_data = pd.read_csv("https://github.com/dbczumar/model-registry-demo-notebook/raw/master/dataset/windfarm_data.csv", index_col=0)
def get_training_data():
training_data = pd.DataFrame(wind_farm_data["2014-01-01":"2018-01-01"])
X = training_data.drop(columns="power")
y = training_data["power"]
return X, y
def get_validation_data():
validation_data = pd.DataFrame(wind_farm_data["2018-01-01":"2019-01-01"])
X = validation_data.drop(columns="power")
y = validation_data["power"]
return X, y
def get_weather_and_forecast():
format_date = lambda pd_date : pd_date.date().strftime("%Y-%m-%d")
today = pd.Timestamp('today').normalize()
week_ago = today - pd.Timedelta(days=5)
week_later = today + pd.Timedelta(days=5)
past_power_output = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(today)]
weather_and_forecast = pd.DataFrame(wind_farm_data)[format_date(week_ago):format_date(week_later)]
if len(weather_and_forecast) < 10:
past_power_output = pd.DataFrame(wind_farm_data).iloc[-10:-5]
weather_and_forecast = pd.DataFrame(wind_farm_data).iloc[-10:]
return weather_and_forecast.drop(columns="power"), past_power_output["power"]
Treinar um modelo
O código a seguir treina uma rede neural usando TensorFlow Keras para prever a saída de energia com base nos recursos meteorológicos do conjunto de resultados. O MLflow é usado para rastrear os hiperparâmetros do modelo, as métricas de desempenho, o código-fonte e os artefatos.
def train_keras_model(X, y):
import tensorflow.keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(100, input_shape=(X_train.shape[-1],), activation="relu", name="hidden_layer"))
model.add(Dense(1))
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=100, batch_size=64, validation_split=.2)
return model
import mlflow
X_train, y_train = get_training_data()
with mlflow.start_run():
# Automatically capture the model's parameters, metrics, artifacts,
# and source code with the `autolog()` function
mlflow.tensorflow.autolog()
train_keras_model(X_train, y_train)
run_id = mlflow.active_run().info.run_id
Registrar e gerenciar o modelo usando a interface do usuário do MLflow
Nesta seção:
- Criar um novo modelo registrado
- Explorar a interface do usuário do Registro de Modelos
- Adicionar descrições de modelo
- Faça a transição de uma versão de modelo
Criar um novo modelo registrado
Navegue até a barra lateral de Execuções de Experimentos do MLflow clicando no ícone de Experimento
 na interface do usuário do bloco de anotações do Azure Databricks.
na interface do usuário do bloco de anotações do Azure Databricks.
Localize a Execução do MLflow correspondente à sessão de treinamento do modelo TensorFlow Keras e abra-a na interface do usuário de Execução do MLflow, clicando no ícone Exibir Detalhe da Execução.
Na interface do usuário do MLflow, role para baixo até a seção Artefatos e clique no diretório chamado Modelo. Clique no botão Registrar modelo que aparece.

Selecione Criar novo modelo no menu suspenso e insira o seguinte nome de modelo:
power-forecasting-model.Clique em Registrar. Isso registra um novo modelo chamado
power-forecasting-modele cria uma nova versão de modelo:Version 1.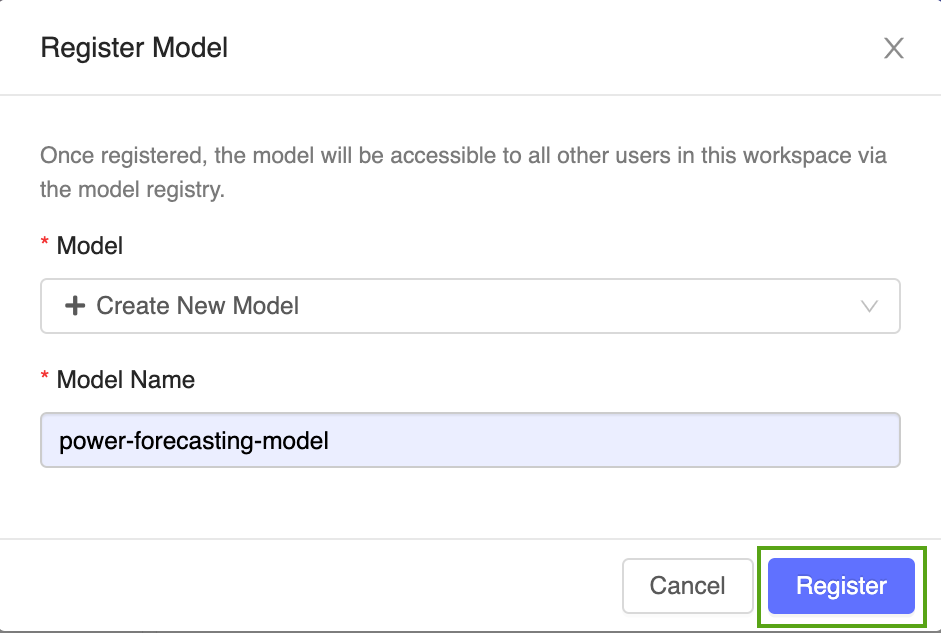
Após alguns momentos, a interface do usuário do MLflow exibe um link para o novo modelo registrado. Clique no link para abrir a nova versão do modelo na interface do usuário do Registro de Modelos do MLflow.
Explorar a interface do usuário do Registro de Modelos
A página versão do modelo na interface do usuário do registro do modelo MLflow fornece informações sobre Version 1 do modelo de previsão registrado, incluindo seu autor, hora de criação e seu estágio atual.
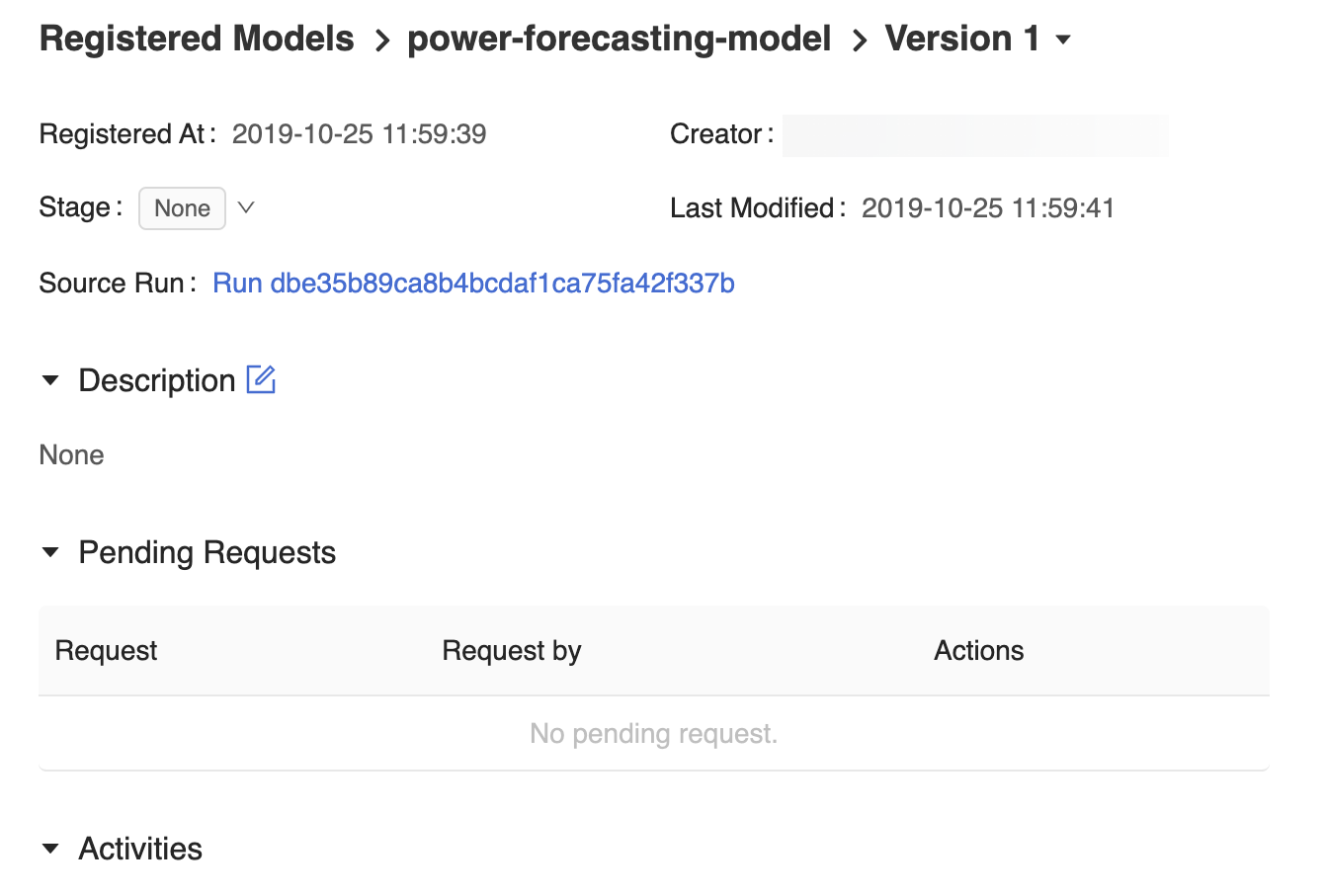
A página versão do modelo também fornece um link de execução de origem, que abre a execução MLflow que foi usada para criar o modelo na interface do usuário de execução do MLflow. Na interface do usuário de execução do MLflow, você pode acessar o link do bloco de anotações de Origem para exibir um instantâneo do Azure Databricks bloco de anotações que foi usado para treinar o modelo.


Para navegar de volta para o Registro de Modelo do MLflow, clique em ![]() Modelos na barra lateral.
Modelos na barra lateral.
A página inicial do registro de modelo do MLflow resultante exibe uma lista de todos os modelos registrados em seu espaço de trabalho do Azure Databricks, incluindo suas versões e estágios.
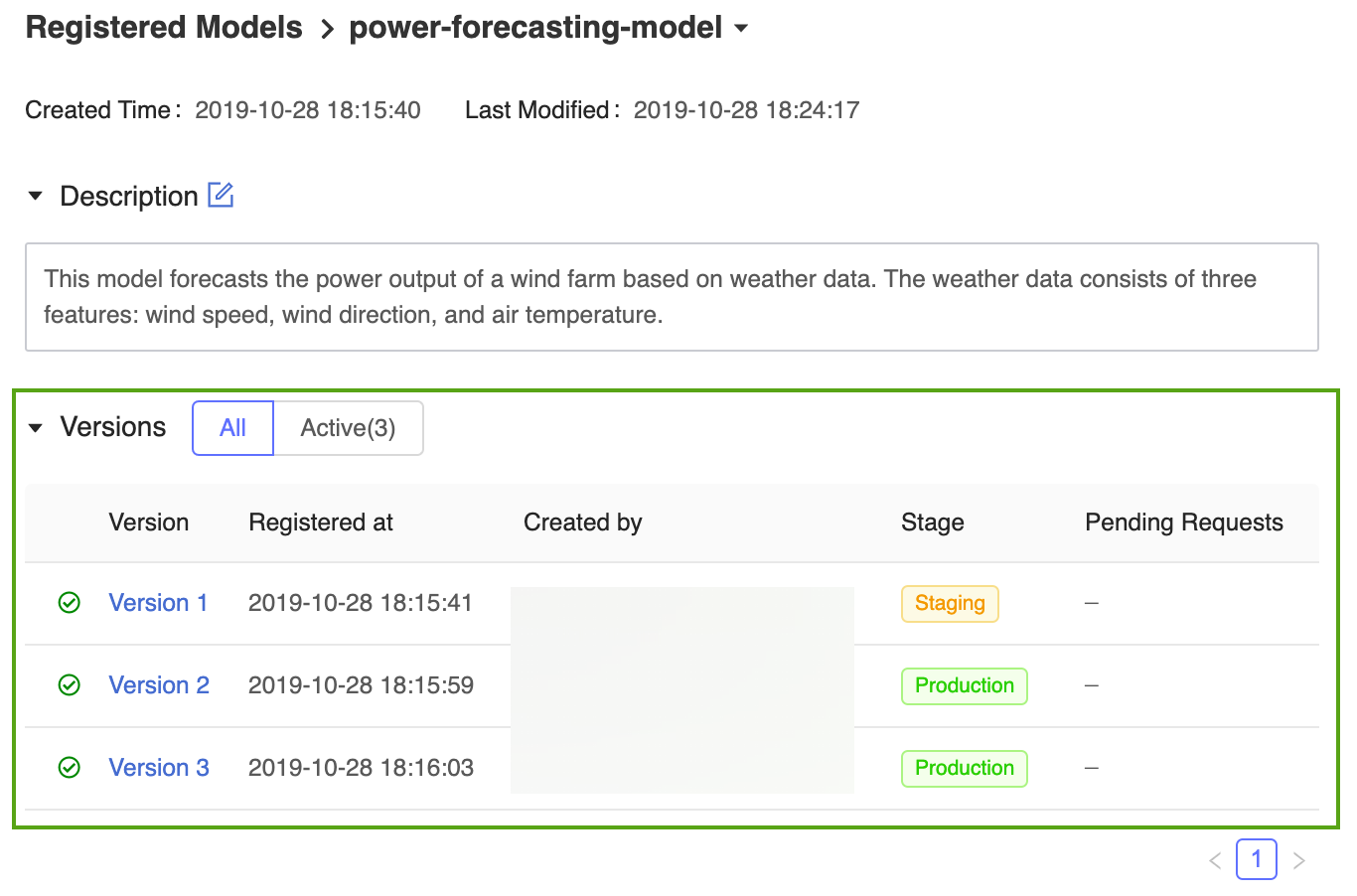
Clique no link power-forecasting-model para abrir a página do modelo registrado, que exibe todas as versões do modelo de previsão.
Adicionar descrições de modelo
Você pode adicionar descrições a modelos registrados e versões de modelo. Descrições de modelo registrado são úteis para registrar informações que se aplicam a várias versões de modelo (por exemplo, uma visão geral do problema de modelagem e do conjunto de dados). Descrições de versão de modelo são úteis para detalhar os atributos exclusivos de uma versão de modelo específica (por exemplo, a metodologia e o algoritmo usados para desenvolver o modelo).
Adicione uma descrição de alto nível ao modelo de previsão de energia registrado. Clique no ícone
 e insira a seguinte descrição:
e insira a seguinte descrição:This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature.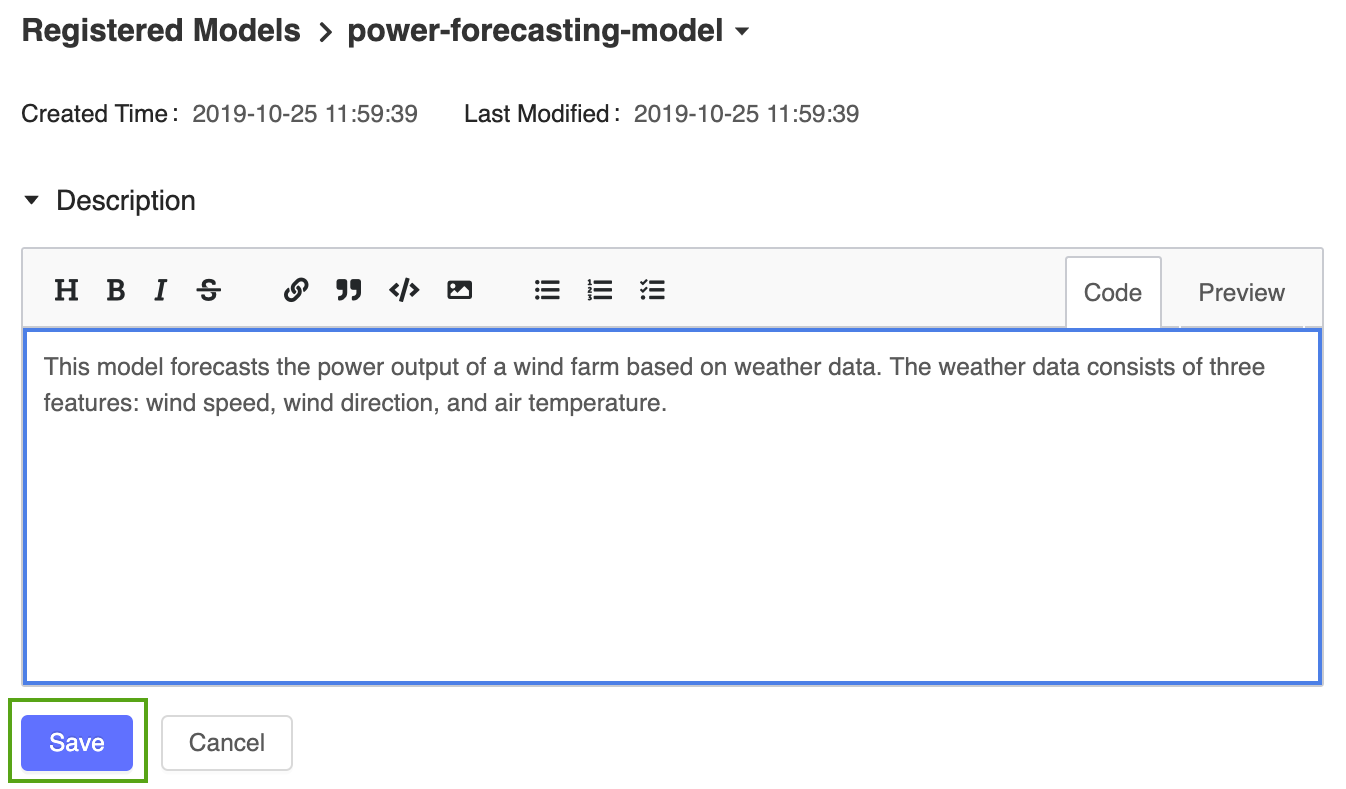
Clique em Save (Salvar).
Clique no link Versão 1 da página modelo registrado para navegar de volta para a página versão do modelo.
Clique no ícone
e insira a seguinte descrição:This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer.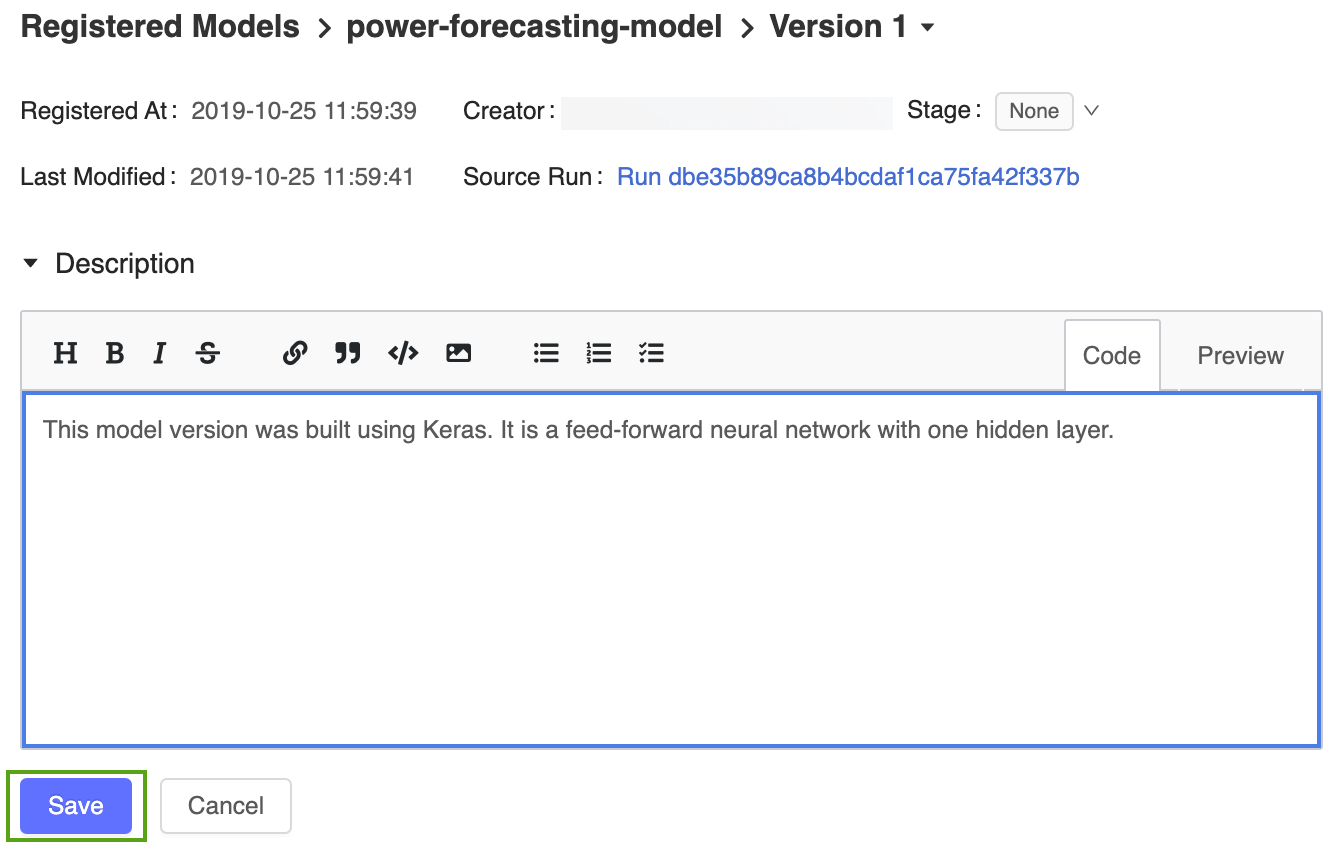
Clique em Save (Salvar).
Faça a transição de uma versão de modelo
O registro do modelo MLflow define vários estágios de modelo: Nenhum, Processo de preparo, Produção e Archived. Cada estágio tem um significado exclusivo. Por exemplo, o Processo de preparo destina-se a testes dos modelos, enquanto a fase de Produção é para os modelos que concluíram os processos de teste ou análise e foram implantados em aplicativos.
Clique no botão Estágio para exibir a lista de estágios de modelo disponíveis e suas opções de transição de estágio disponíveis.
Selecione Transição para- > Produção e pressione OK na janela confirmação de transição do estágio para fazer a transição do modelo para Produção.

Após a transição da versão do modelo para Produção, o estágio atual é exibido na interface do usuário e uma entrada é adicionada ao log de atividades para refletir a transição.


O registro do modelo MLflow permite que várias versões de modelo compartilhem o mesmo estágio. Ao fazer referência a um modelo por estágio, o registro de modelo usa a versão mais recente do modelo (a versão do modelo com a ID de versão maior). A página modelo registrado exibe todas as versões de um modelo específico.
Registrar e gerenciar o modelo usando a API do MLflow
Nesta seção:
- Definir o nome do modelo programaticamente
- Registre o modelo
- Adicionar descrições de modelo e versão de modelo usando a API
- Fazer a transição de uma versão do modelo e recuperar detalhes usando a API
Definir o nome do modelo programaticamente
Agora que o modelo foi registrado e transferido para a Produção, você pode fazer referência a ele usando APIs programáticas do MLflow. Defina o nome do modelo registrado da seguinte maneira:
model_name = "power-forecasting-model"
Registre o modelo
model_name = get_model_name()
import mlflow
# The default path where the MLflow autologging function stores the TensorFlow Keras model
artifact_path = "model"
model_uri = "runs:/{run_id}/{artifact_path}".format(run_id=run_id, artifact_path=artifact_path)
model_details = mlflow.register_model(model_uri=model_uri, name=model_name)
import time
from mlflow.tracking.client import MlflowClient
from mlflow.entities.model_registry.model_version_status import ModelVersionStatus
# Wait until the model is ready
def wait_until_ready(model_name, model_version):
client = MlflowClient()
for _ in range(10):
model_version_details = client.get_model_version(
name=model_name,
version=model_version,
)
status = ModelVersionStatus.from_string(model_version_details.status)
print("Model status: %s" % ModelVersionStatus.to_string(status))
if status == ModelVersionStatus.READY:
break
time.sleep(1)
wait_until_ready(model_details.name, model_details.version)
Adicionar descrições de modelo e versão de modelo usando a API
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.update_registered_model(
name=model_details.name,
description="This model forecasts the power output of a wind farm based on weather data. The weather data consists of three features: wind speed, wind direction, and air temperature."
)
client.update_model_version(
name=model_details.name,
version=model_details.version,
description="This model version was built using TensorFlow Keras. It is a feed-forward neural network with one hidden layer."
)
Fazer a transição de uma versão do modelo e recuperar detalhes usando a API
client.transition_model_version_stage(
name=model_details.name,
version=model_details.version,
stage='production',
)
model_version_details = client.get_model_version(
name=model_details.name,
version=model_details.version,
)
print("The current model stage is: '{stage}'".format(stage=model_version_details.current_stage))
latest_version_info = client.get_latest_versions(model_name, stages=["production"])
latest_production_version = latest_version_info[0].version
print("The latest production version of the model '%s' is '%s'." % (model_name, latest_production_version))
Carregar versões do modelo registrado usando a API
O componente de modelos MLflow define funções para carregar modelos de várias estruturas de aprendizado de máquina. Por exemplo, mlflow.tensorflow.load_model() é usado para carregar modelos TensorFlow que foram salvos no formato MLflow e mlflow.sklearn.load_model() é usado para carregar modelos scikit-learn que foram salvos no formato MLflow.
Essas funções podem carregar modelos do registro do modelo MLflow.
import mlflow.pyfunc
model_version_uri = "models:/{model_name}/1".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_version_uri))
model_version_1 = mlflow.pyfunc.load_model(model_version_uri)
model_production_uri = "models:/{model_name}/production".format(model_name=model_name)
print("Loading registered model version from URI: '{model_uri}'".format(model_uri=model_production_uri))
model_production = mlflow.pyfunc.load_model(model_production_uri)
Prever a saída de energia com o modelo de produção
Nesta seção, o modelo de produção é usado para avaliar os dados de previsão do tempo para o farm de vento. O aplicativo forecast_power() carrega a versão mais recente do modelo de previsão do estágio especificado e a usa para prever a produção de energia nos próximos cinco dias.
def plot(model_name, model_stage, model_version, power_predictions, past_power_output):
import pandas as pd
import matplotlib.dates as mdates
from matplotlib import pyplot as plt
index = power_predictions.index
fig = plt.figure(figsize=(11, 7))
ax = fig.add_subplot(111)
ax.set_xlabel("Date", size=20, labelpad=20)
ax.set_ylabel("Power\noutput\n(MW)", size=20, labelpad=60, rotation=0)
ax.tick_params(axis='both', which='major', labelsize=17)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
ax.plot(index[:len(past_power_output)], past_power_output, label="True", color="red", alpha=0.5, linewidth=4)
ax.plot(index, power_predictions.squeeze(), "--", label="Predicted by '%s'\nin stage '%s' (Version %d)" % (model_name, model_stage, model_version), color="blue", linewidth=3)
ax.set_ylim(ymin=0, ymax=max(3500, int(max(power_predictions.values) * 1.3)))
ax.legend(fontsize=14)
plt.title("Wind farm power output and projections", size=24, pad=20)
plt.tight_layout()
display(plt.show())
def forecast_power(model_name, model_stage):
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version = client.get_latest_versions(model_name, stages=[model_stage])[0].version
model_uri = "models:/{model_name}/{model_stage}".format(model_name=model_name, model_stage=model_stage)
model = mlflow.pyfunc.load_model(model_uri)
weather_data, past_power_output = get_weather_and_forecast()
power_predictions = pd.DataFrame(model.predict(weather_data))
power_predictions.index = pd.to_datetime(weather_data.index)
print(power_predictions)
plot(model_name, model_stage, int(model_version), power_predictions, past_power_output)
Criar uma nova versão de modelo
As técnicas clássicas de aprendizado de máquina também são eficazes para a previsão de energia. O código a seguir treina um modelo de floresta aleatório usando scikit-Learn e registra-o com o registro de modelo MLflow por meio da função mlflow.sklearn.log_model().
import mlflow.sklearn
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
with mlflow.start_run():
n_estimators = 300
mlflow.log_param("n_estimators", n_estimators)
rand_forest = RandomForestRegressor(n_estimators=n_estimators)
rand_forest.fit(X_train, y_train)
val_x, val_y = get_validation_data()
mse = mean_squared_error(rand_forest.predict(val_x), val_y)
print("Validation MSE: %d" % mse)
mlflow.log_metric("mse", mse)
# Specify the `registered_model_name` parameter of the `mlflow.sklearn.log_model()`
# function to register the model with the MLflow Model Registry. This automatically
# creates a new model version
mlflow.sklearn.log_model(
sk_model=rand_forest,
artifact_path="sklearn-model",
registered_model_name=model_name,
)
Buscar a nova ID de versão do modelo usando a pesquisa de registro do modelo MLflow
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
model_version_infos = client.search_model_versions("name = '%s'" % model_name)
new_model_version = max([model_version_info.version for model_version_info in model_version_infos])
wait_until_ready(model_name, new_model_version)
Adicionar uma descrição à nova versão do modelo
client.update_model_version(
name=model_name,
version=new_model_version,
description="This model version is a random forest containing 100 decision trees that was trained in scikit-learn."
)
Fazer a transição da nova versão do modelo para preparo e testar o modelo
Antes de implantar um modelo em um aplicativo de produção, geralmente é recomendável testá-lo em um ambiente de preparo. O código a seguir faz a transição da nova versão do modelo para Preparo e avalia seu desempenho.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="Staging",
)
forecast_power(model_name, "Staging")
Implantar a nova versão do modelo na produção
Depois de verificar se a nova versão do modelo tem um bom desempenho no preparo, o código a seguir faz a transição do modelo para Produção e usa exatamente o mesmo código do aplicativo da Previsão de saída de energia com a seção modelo de produção para produzir uma previsão de energia.
client.transition_model_version_stage(
name=model_name,
version=new_model_version,
stage="production",
)
forecast_power(model_name, "production")
Agora há duas versões de modelo do modelo de previsão no estágio de Produção : a versão do modelo treinada no modelo Keras e a versão treinada em scikit-learn.

Observação
Ao fazer referência a um modelo por estágio, o registro de modelo de modelo MLflow automaticamente usa a versão de produção mais recente. Isso permite que você atualize seus modelos de produção sem alterar nenhum código de aplicativo.
Arquivar e excluir modelos
Quando uma versão de modelo não estiver mais sendo usada, você poderá arquivá-la ou excluí-la. Você também pode excluir um modelo registrado inteiro; isso remove todas as suas versões de modelo associadas.
Arquivo Version 1 do modelo de previsão de energia
Arquivo Version 1 do modelo de previsão de energia porque ele não está mais sendo usado. Você pode arquivar modelos na interface do usuário do Registro de Modelo do MLflow ou por meio da API do MLflow.
Arquivar Version 1 na interface do usuário do MLflow
Para o arquivo Version 1 do modelo de previsão de energia:
Abra a página de versão do modelo correspondente na interface do usuário do Registro de Modelo do MLflow:

Clique no botão Estágio e selecione Transição para –> Arquivado:
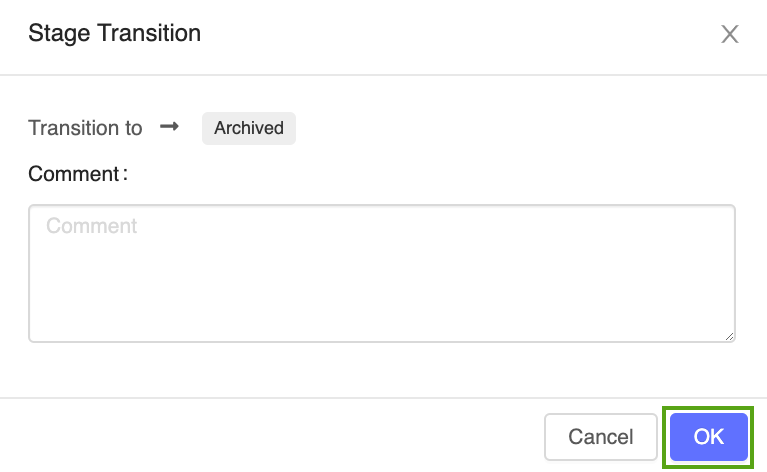
Pressione OK na janela de confirmação de transição de estágio.

Arquivar Version 1 usando a API do MLflow
O código a seguir usa a MlflowClient.update_model_version() função para arquivar Version 1 o modelo de previsão de energia.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=1,
stage="Archived",
)
Excluir Version 1 do modelo de previsão de energia
Você também pode usar a interface do usuário do MLflow ou a API do MLflow para excluir versões de modelo.
Aviso
A exclusão é permanente, e não pode ser desfeita.
Excluir Version 1 na interface do usuário do MLflow
Para excluir Version 1 do modelo de previsão de energia:
Abra a página de versão do modelo correspondente na interface do usuário do Registro de Modelo do MLflow.
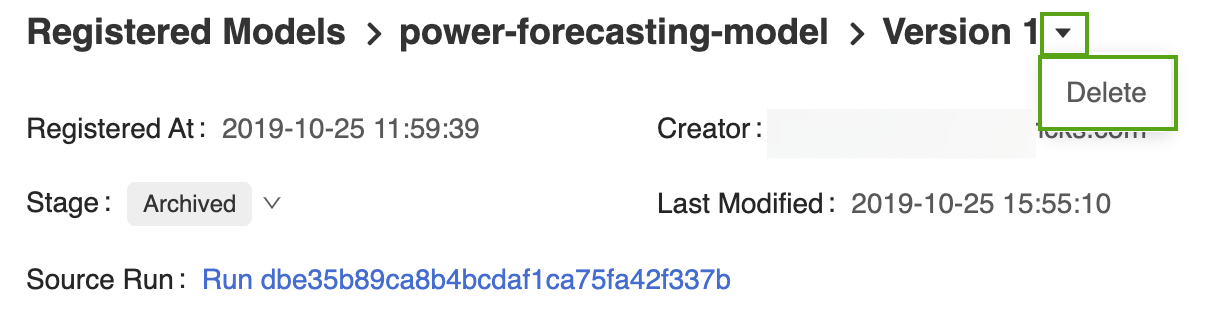
Selecione a seta para baixo ao lado do identificador de versão e clique em Excluir.
Excluir Version 1 usando a API do MLflow
client.delete_model_version(
name=model_name,
version=1,
)
Excluir o modelo usando a API do MLflow
Primeiro, você deve fazer a transição de todos os estágios restantes da versão do modelo para Nenhum ou Arquivado.
from mlflow.tracking.client import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=2,
stage="Archived",
)
client.delete_registered_model(name=model_name)