Executar um notebook do Databricks por meio de outro notebook
Importante
Para orquestração de notebook, use os Trabalhos do Databricks. Para cenários de modularização de código, use arquivos do workspace. Você só deve usar as técnicas descritas neste artigo quando seu caso de uso não puder ser implementado usando um trabalho do Databricks, como em casos de execução de notebooks em loop com um conjunto dinâmico de parâmetros ou se você não tiver acesso a arquivos do workspace. Para saber mais, confira Programar e orquestrar fluxos de trabalho e compartilhar código.
Comparação de %run e dbutils.notebook.run()
O comando %run permite que você inclua outro notebook em um notebook. Você pode usar %run para modularizar seu código. Por exemplo, colocando funções de suporte em um notebook separado. Você também pode usá-lo para concatenar notebooks que implementam as etapas em uma análise. Quando você usa %run, o notebook chamado é executado imediatamente e as funções e variáveis definidas nele ficam disponíveis no notebook de chamada.
A API dbutils.notebook é um complemento para %run porque permite passar parâmetros para um notebook e retornar valores dele. Dessa maneira, você cria fluxos de trabalho e pipelines complexos com dependências. Por exemplo, você pode obter uma lista de arquivos em um diretório e passar os nomes para outro notebook, o que não é possível com %run. Você também pode criar fluxos de trabalho if-then-else com base em valores de retorno ou chamar outros notebooks usando caminhos relativos.
Ao contrário do %run, o método dbutils.notebook.run() inicia um novo trabalho para executar o notebook.
Esses métodos, como todas as APIs de dbutils, estão disponíveis apenas em Python e Scala. No entanto, você pode usar dbutils.notebook.run() para invocar um notebook R.
Usar %run para importar um notebook
Nesse exemplo, o primeiro notebook define uma função, reverse, que fica disponível no segundo notebook depois que você usa o magic %run para executar shared-code-notebook.
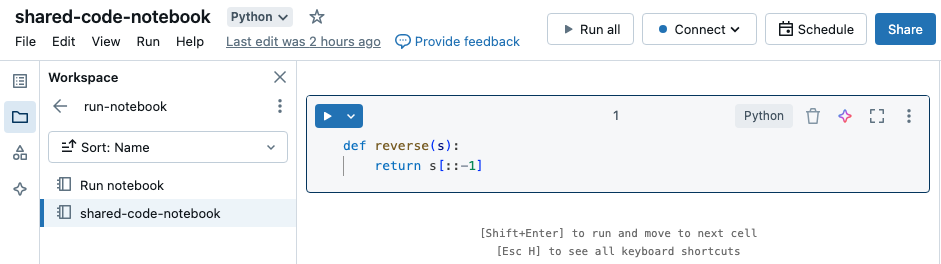
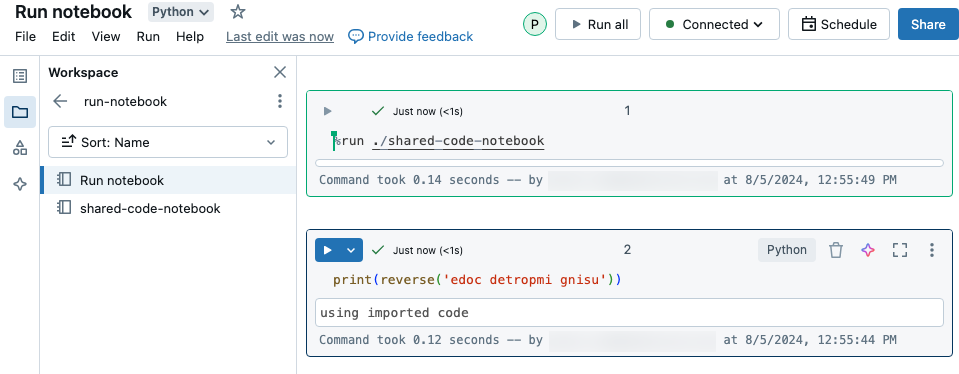
Como esses dois notebooks estão no mesmo diretório no workspace, use o prefixo ./ em ./shared-code-notebook para indicar que o caminho deve ser resolvido em relação ao notebook em execução no momento. Você pode organizar os notebooks em diretórios, como %run ./dir/notebook, ou usar um caminho absoluto, como %run /Users/username@organization.com/directory/notebook.
Observação
%rundeve estar em uma célula sozinha, pois ele executa o notebook inteiro embutido.- Você não pode usar
%runpara executar um arquivo Python eimportas entidades definidas nesse arquivo em um notebook. Para importar de um arquivo Python, consulte Modularizar seu código usando arquivos. Ou empacote o arquivo em uma biblioteca Python, crie uma biblioteca do Azure Databricks por meio dessa biblioteca Python e instale a biblioteca no cluster que você usa para executar o notebook. - Se você usar
%runpara executar um notebook que contenha widgets, por padrão, o notebook especificado será executado com os valores padrão do widget. Também é possível passar valores para os widgets. Confira Usar widgets do Databricks com %run.
dbutils.notebook API
Os métodos disponíveis na API dbutils.notebook são run e exit. Os parâmetros e os valores de retorno devem ser cadeias de caracteres.
run(path: String, timeout_seconds: int, arguments: Map): String
Executar um notebook e retornar o valor de saída. O método inicia um trabalho efêmero que é executado imediatamente.
O parâmetro timeout_seconds controla o tempo limite da execução (0 significa que não há tempo limite): a chamada para run lançará uma exceção se não terminar no tempo especificado. Se o Azure Databricks ficar inoperante por mais de 10 minutos, a execução do notebook falhará, independentemente de timeout_seconds.
O parâmetro arguments define valores de widget do notebook de destino. Especificamente, se o notebook que estiver executando tiver um widget chamado A e você passar um par chave-valor ("A": "B") como parte do parâmetro de argumentos para a chamada run(), a recuperação do valor do widget A retornará "B". Veja instruções para criar e trabalhar com widgets no artigo Widgets do Databricks.
Observação
- O parâmetro
argumentsaceita apenas caracteres latinos (conjunto de caracteres ASCII). O uso de caracteres não ASCII retorna um erro. - Os trabalhos criados usando a API
dbutils.notebookdevem ser concluídos em 30 dias ou menos.
runUso
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Exemplo run
Suponhamos que você tenha um notebook chamado workflows com um widget chamado foo que imprima o valor do widget:
dbutils.widgets.text("foo", "fooDefault", "fooEmptyLabel")
print(dbutils.widgets.get("foo"))
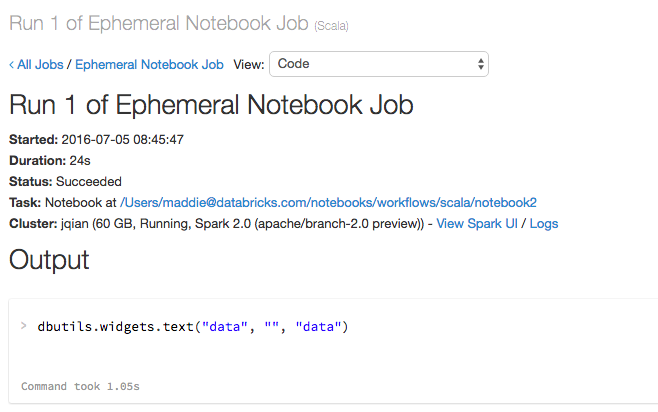
A execução de dbutils.notebook.run("workflows", 60, {"foo": "bar"}) gera estes resultados:
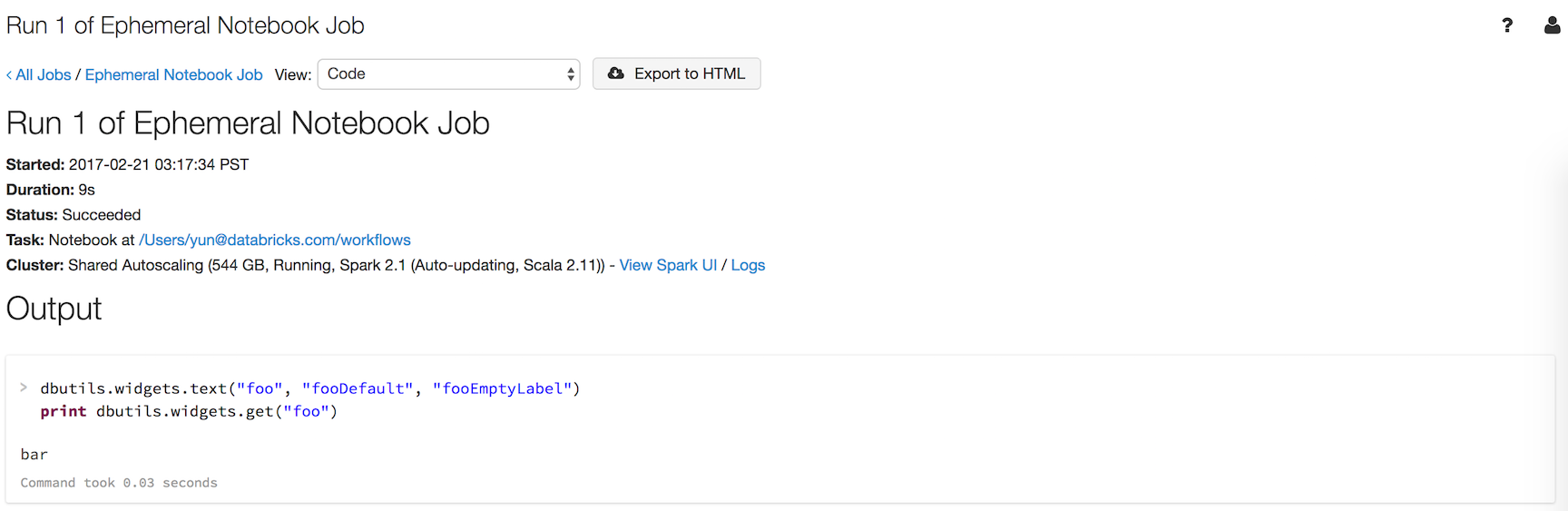
O widget tinha o valor passado com o uso de dbutils.notebook.run(), "bar", em vez de o padrão.
exit(value: String): void Sair de um notebook com um valor. Se você chamar um notebook usando o método run, esse será o valor retornado.
dbutils.notebook.exit("returnValue")
Chamar dbutils.notebook.exit em um trabalho faz com que o notebook seja concluído com êxito. Para fazer com que o trabalho falhe, lance uma exceção.
Exemplo
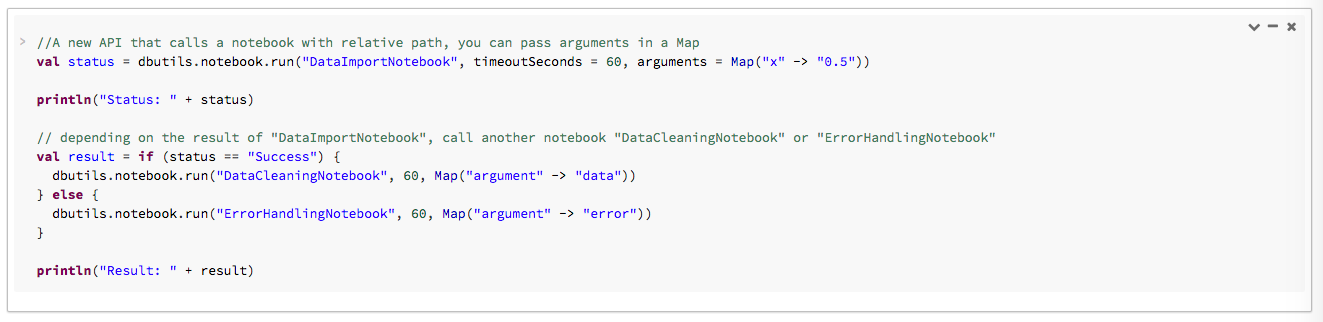
No exemplo a seguir, você passa argumentos para DataImportNotebook e executa notebooks diferentes (DataCleaningNotebook ou ErrorHandlingNotebook) com base no resultado de DataImportNotebook.
Quando o código é executado, uma tabela aparece contendo um link para o notebook em execução:

Para exibir os detalhes da execução, clique no link Hora de início na tabela. Se a execução for concluída, você também poderá exibir os detalhes da execução clicando no link Hora de término.
Passar dados estruturados
Esta seção ilustra como passar dados estruturados entre notebooks.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Tratar erros
Esta seção ilustra como manipular erros.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Executar vários notebooks simultaneamente
Você pode executar vários notebooks ao mesmo tempo usando constructos padrão do Scala e do Python, como Threads (Scala, Python) e Futuros (Scala, Python). Os notebooks de exemplo demonstram como usar esses constructos.
- Baixe os quatro notebooks a seguir. Os notebooks são escritos em Scala.
- Importe os notebooks para uma única pasta no workspace.
- Execute o notebook Executar simultaneamente .