Limites e perguntas frequentes sobre a integração do Git com pastas Git do Databricks
A integração entre pastas Git do Databricks e o Git tem limites especificados nas seções a seguir. Para obter informações gerais, confira Limites do Databricks.
Ir para:
- Limites de arquivos e repositórios
- Tipos de ativos compatíveis com pastas Git
- Perguntas frequentes: configuração da pasta Git
Limites de arquivos e repositórios
O Azure Databricks não impõe limite para o tamanho de um repositório. No entanto:
- As ramificações de trabalho são limitadas a 1 gigabyte (GB).
- Os arquivos maiores que 10 MB não podem ser exibidos na interface do usuário do Azure Databricks.
- Arquivos de workspace individuais estão sujeitos a um limite de tamanho separado. Para obter mais detalhes, leia Limitações.
O Databricks recomenda que, em um repositório:
- O número total de todos ativos de workspaces e arquivos não exceda 20.000.
Para qualquer operação do Git, o uso de memória é limitado a 2 GB e as gravações em disco são limitadas a 4 GB. Como o limite é por operação, você receberá uma falha se tentar clonar um repositório Git de 5 GB no tamanho atual. No entanto, se você clonar um repositório Git com 3 GB de tamanho em uma operação e adicionar 2 GB a ele mais tarde, a próxima operação de pull terá êxito.
Você poderá receber uma mensagem de erro se o repositório exceder esses limites. Você também pode receber um erro de tempo limite ao clonar o repositório, mas a operação pode ser concluída em segundo plano.
Para trabalhar com repositórios maiores do que os limites de tamanho, tente o check-out esparso.
Se você precisar gravar arquivos temporários que não deseja manter depois do cluster ser desligado, gravar os arquivos temporários em $TEMPDIR evita exceder os limites de tamanho do branch e produz melhor desempenho do que gravar no diretório de trabalho atual (CWD) se o CWD estiver no sistema de arquivos do workspace. Para obter mais informações, confira Onde devo gravar arquivos temporários no Azure Databricks?.
Número máximo de pastas Git por workspace
Você pode ter no máximo 2.000 pastas Git por workspace. Se você precisar de mais, entre em contato com o suporte do Databricks.
Recuperando arquivos excluídos de pastas do Git em seu workspace
As ações do espaço de trabalho nas pastas do Git variam na capacidade de recuperação de arquivos. Algumas ações permitem a recuperação por meio da pasta Lixeira , enquanto outras não. Os arquivos confirmados anteriormente e enviados por push para um branch remoto podem ser restaurados usando o histórico de confirmação do Git para o repositório Git remoto. Esta tabela descreve o comportamento e a capacidade de recuperação de cada ação:
| Ação | O arquivo é recuperável? |
|---|---|
| Excluir arquivo com o navegador do espaço de trabalho | Sim, da pasta Lixeira |
| Descartar um novo arquivo com a caixa de diálogo da pasta Git | Sim, da pasta Lixeira |
| Descartar um arquivo modificado com a caixa de diálogo da pasta Git | Não, o arquivo sumiu |
reset (difícil) para modificações de arquivo não confirmadas |
Não, as modificações de arquivo desapareceram |
reset (difícil) para arquivos recém-criados e não confirmados |
Não, as modificações de arquivo desapareceram |
| Alternar branches com a caixa de diálogo da pasta Git | Sim, do repositório Git remoto |
| Outras operações do Git (Commit & Push, etc.) da caixa de diálogo da pasta Git | Sim, do repositório Git remoto |
PATCH operações atualizadas /repos/id da API Repos |
Sim, do repositório Git remoto |
Os arquivos excluídos de uma pasta Git por meio de operações do Git da interface do usuário do workspace podem ser recuperados do histórico do branch remoto usando a linha de comando do Git (ou outras ferramentas do Git) se esses arquivos tiverem sido confirmados anteriormente e enviados por push para o repositório remoto. As ações do espaço de trabalho variam na capacidade de recuperação de arquivos. Algumas ações permitem a recuperação através do lixo, enquanto outras não. Os arquivos confirmados anteriormente e enviados por push para um branch remoto podem ser restaurados por meio do histórico de confirmação do Git. A tabela abaixo descreve o comportamento e a capacidade de recuperação de cada ação:
Suporte a mono repositório
O Databricks recomenda que você não crie pastas Git apoiadas por monorepos, em que um monorepo é um repositório Git grande e de organização única com muitos milhares de arquivos em muitos projetos.
Tipos de ativos compatíveis com pastas Git
Apenas determinados tipos de ativos do Azure Databricks são aceitos pelas pastas Git. Um tipo de ativo com suporte pode ser serializado, controlado por versão e enviado por push para o repositório Git de suporte.
Atualmente, os tipos de ativos de dados aceitos são:
| Tipo de ativo | Detalhes |
|---|---|
| Arquivo | Os arquivos são dados serializados e podem incluir qualquer coisa, de bibliotecas a binários, código e imagens. Para obter mais informações, leia O que são arquivos de workspace? |
| Notebook | Os notebooks são especificamente os formatos de arquivo de bloco de anotações suportados pelo Databricks. Os notebooks são considerados um tipo de ativo separado do Azure Databricks dos arquivos porque eles não são serializados. As pastas Git determinam um bloco de anotações pela extensão de arquivo (como .ipynb) ou por extensões de arquivo combinadas com um marcador especial no conteúdo do arquivo (por exemplo, um # Databricks notebook source comentário no início dos arquivos de .py origem). |
| Pasta | Uma pasta é uma estrutura específica do Azure Databricks que representa informações serializadas sobre um agrupamento lógico de arquivos no Git. Como esperado, o usuário experimenta isso como uma "pasta" ao exibir uma pasta Git do Azure Databricks ou acessá-la com a CLI do Azure Databricks. |
Os tipos de ativo do Azure Databricks que atualmente não têm suporte em pastas Git incluem o seguinte:
- Consultas DBSQL
- Alertas
- Painéis (incluindo painéis herdados)
- Testes
- Espaços de gênio
Ao trabalhar com seus ativos no Git, observe as seguintes limitações de nomenclatura de arquivo:
- Uma pasta não pode conter um notebook com o mesmo nome de outro bloco de anotações, arquivo ou pasta no mesmo repositório Git, mesmo que a extensão de arquivo seja diferente. (Para notebooks de formato de origem, a extensão é
.pypara Python,.scalapara Scala,.sqlpara SQL e.rpara R. Para notebooks no formato IPYNB, a extensão é.ipynb.) Por exemplo, você não pode usar um notebook de formato de origem nomeadotest1.pye um bloco de anotações IPYNB nomeadotest1na mesma pasta Git porque o arquivo de notebook do Python no formato de origem (test1.py) será serializado comotest1e ocorrerá um conflito. - Não há suporte para o caractere
/em nomes de arquivo. Por exemplo, você não pode ter um arquivo nomeadoi/o.pyem sua pasta Git.
Se você tentar executar operações Git em arquivos que têm nomes que têm esses padrões, receberá uma mensagem "Erro ao buscar o status do Git". Se você receber este erro inesperadamente, examine os nomes de arquivo dos ativos em seu repositório Git. Se você encontrar arquivos com nomes que tenham esses padrões conflitantes, renomeie-os e tente executar a operação novamente.
Observação
Você pode mover ativos sem suporte existentes para uma pasta Git, mas não pode fazer commit das alterações desses ativos de volta para o repositório. Você não pode criar novos ativos sem suporte em uma pasta Git.
Formatos de notebook
O Databricks considera dois tipos de formatos de notebook de alto nível, específicos do Databricks: "origem" e "ipynb". Quando um usuário confirma um notebook no formato "origem", a plataforma Azure Databricks confirma um arquivo simples com um sufixo de linguagem, como .py, .sql, .scala, ou .r. Um notebook em formato de "origem" contém apenas o código-fonte e não contém saídas, como exibições de tabelas e visualizações que são os resultados da execução do notebook.
O formato "ipynb", no entanto, tem saídas associadas a ele, e esses artefatos são automaticamente enviados para o repositório Git que faz o backup da pasta Git ao enviar por push o notebook .ipynb que os gerou. Se você quiser confirmar as saídas junto com o código, use o formato de notebook "ipynb" e defina a configuração para permitir que um usuário confirme todas as saídas geradas. Como resultado, o "ipynb" também dá suporte a uma melhor experiência de exibição no Databricks para os notebooks enviados para repositórios Git remotos por meio de pastas Git.
| Formato de fonte de notebook | Detalhes |
|---|---|
| origem | Pode ser qualquer arquivo de código com um sufixo de arquivo padrão que sinalize a linguagem do código, como .py, .scala, .r e .sql. Os notebooks de "origem" são tratados como arquivos de texto e não incluirão nenhuma saída associada quando confirmados novamente em um repositório Git. |
| ipynb | Os arquivos "ipynb" terminam com .ipynb e podem, se configurados, enviar resultados (como visualizações) da pasta Git do Databricks para o repositório Git de backup. Um notebook .ipnynb pode conter código em qualquer linguagem compatível com os notebooks do Databricks (apesar da parte py de .ipynb). |
Se quiser que as saídas sejam enviadas de volta ao seu repositório após a execução de um notebook, use um notebook .ipynb (Jupyter). Se você quiser apenas executar o notebook e gerenciá-lo no Git, use um formato "origem" como .py.
Para obter mais detalhes sobre os formatos de notebook com suporte, leia Exportar e importar notebooks do Databricks.
Observação
O que são "outputs"?
As saídas são os resultados da execução de um notebook na plataforma Databricks, incluindo exibições de tabelas e visualizações.
Como fazer para informar qual formato um notebook está usando, além da extensão do arquivo?
Na parte superior de um notebook gerenciado pelo Databricks, geralmente há um comentário de uma única linha que indica o formato. Por exemplo, para um .py notebook "origem", você verá uma linha semelhante a esta:
# Databricks notebook source
Para arquivos .ipynb, o sufixo do arquivo é usado para indicar que se trata do formato de notebook "ipynb".
Notebooks IPYNB em pastas Git do Databricks
O suporte para notebooks Jupyter (arquivos .ipynb) está disponível nas pastas Git. Você pode clonar repositórios com .ipynb notebooks, trabalhar com eles no Azure Databricks e, em seguida, confirmá-los e enviá-los por push como .ipynb notebooks. Os metadados, como o painel do notebook, são preservados. Os administradores podem controlar se as saídas podem ser confirmadas ou não.
Permitir commit da saída do notebook .ipynb
Por padrão, a configuração de administrador para pastas Git não permite que seja feito commit da saída do notebook .ipynb. Os administradores do workspace podem alterar essa configuração:
Vá para as configurações Configurações do administrador > Workspace.
Em Pastas Git > Permitir que pastas Git exportem saídas IPYNB, selecione Permitir: saídas IPYNB podem ser ativadas.

Importante
Quando as saídas são incluídas, as configurações de visualização e dashboard são preservadas com o formato de arquivo .ipynb.
Controlar as confirmações de artefatos de saída do notebook do IPYNB
Quando você confirma um arquivo .ipynb, o Databricks cria um arquivo de configuração que permite controlar como você confirma as saídas: .databricks/commit_outputs.
Se você tiver um arquivo de notebook
.ipynb, mas nenhum arquivo de configuração em seu repositório, abra o modal Status do Git.Na caixa de diálogo de notificação, clique em Criar arquivo commit_outputs.
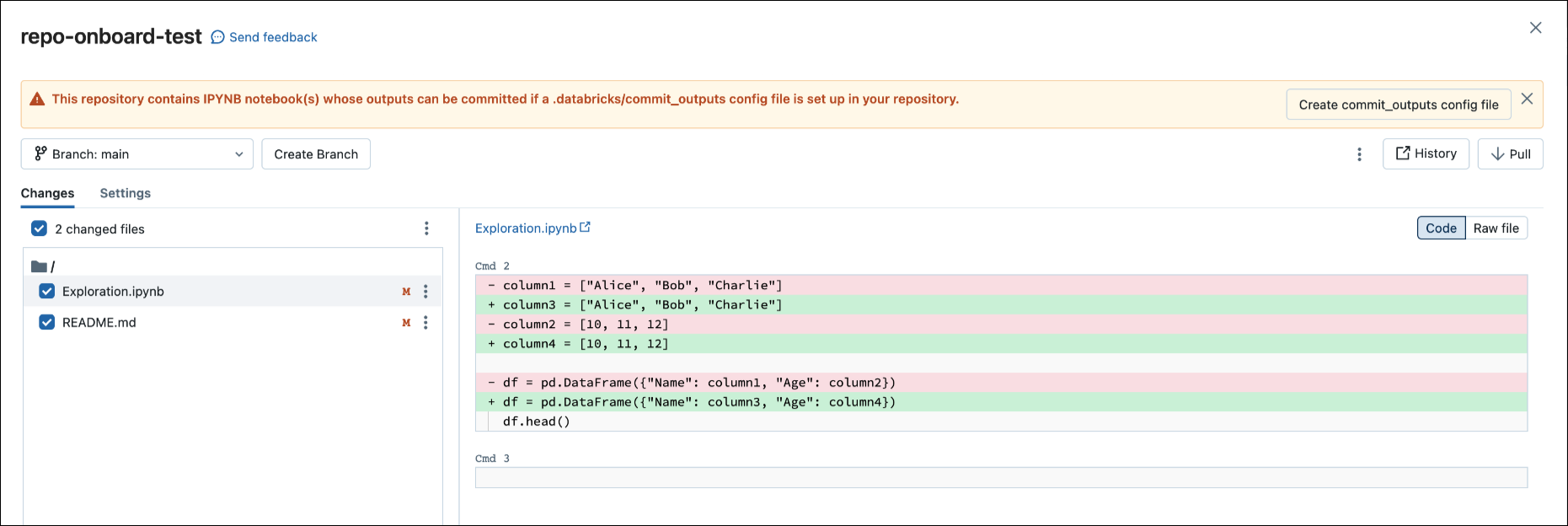
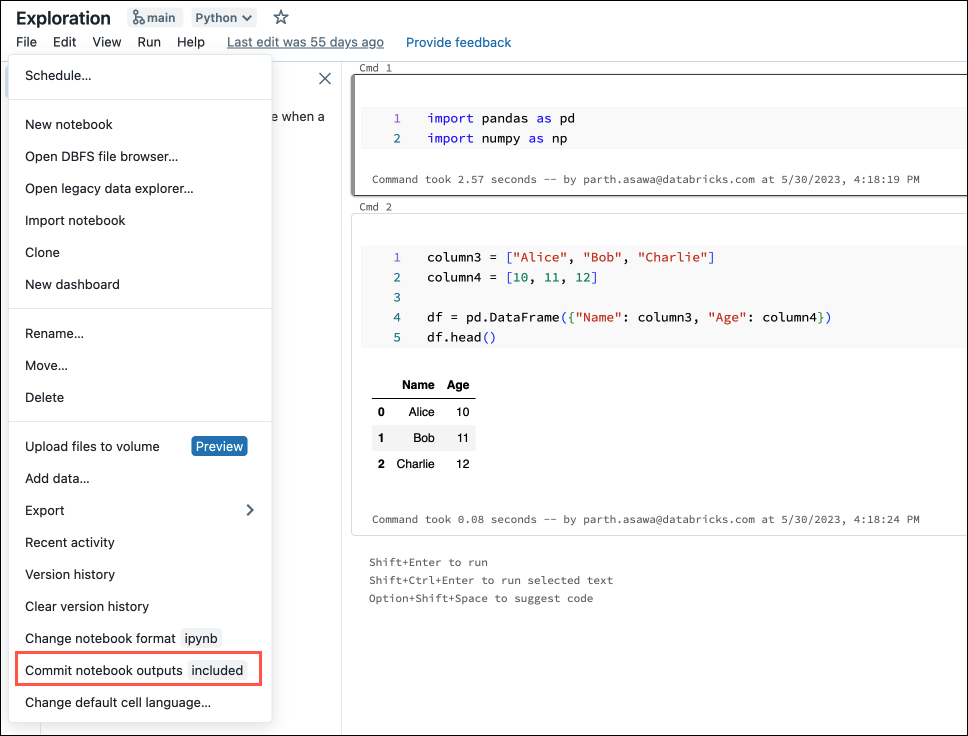
Você também pode gerar arquivos de configuração no menu Arquivo. O menu Arquivo tem um controle que permite atualizar automaticamente o arquivo de configuração para especificar a inclusão ou exclusão de saídas para um notebook específico.
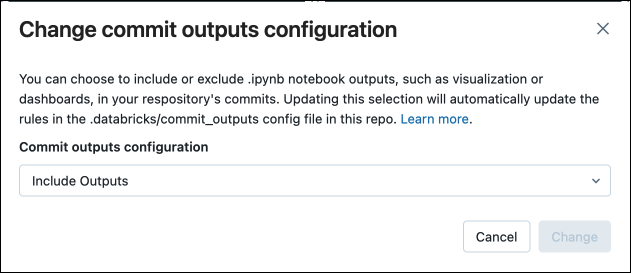
No menu Arquivo, selecione Confirmar saídas de notebooks.
Na caixa de diálogo, confirme sua escolha para confirmar as saídas do notebook.
Converter um notebook de origem em IPYNB
Você pode converter um notebook de origem existente em uma pasta Git em um notebook IPYNB por meio da interface do usuário do Azure Databricks.
Abra um bloco de anotações de origem em seu workspace.
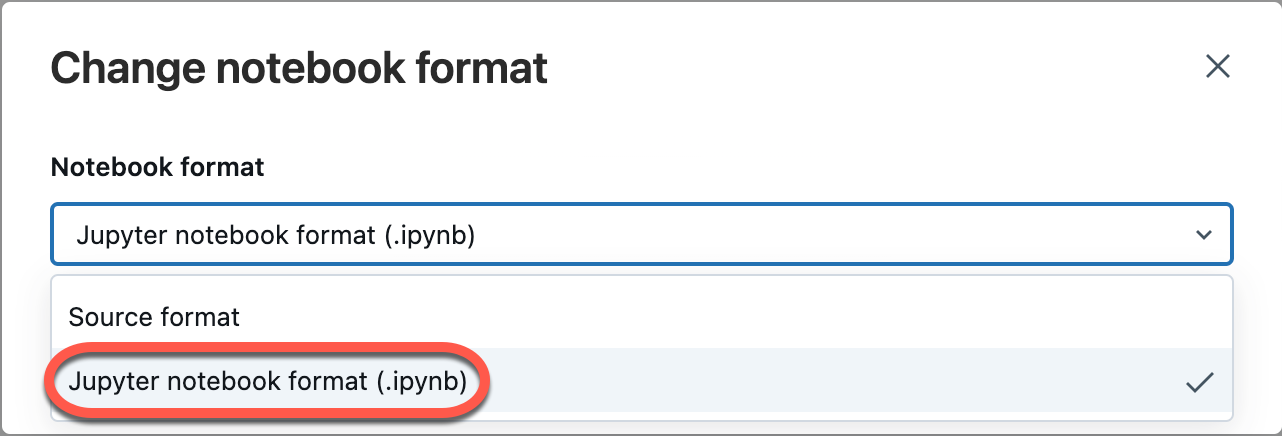
Selecione Arquivo no menu do workspace e selecione Alterar formato do notebook [origem]. Se o notebook já estiver no formato IPYNB, a [origem] será [ipynb] no elemento de menu.
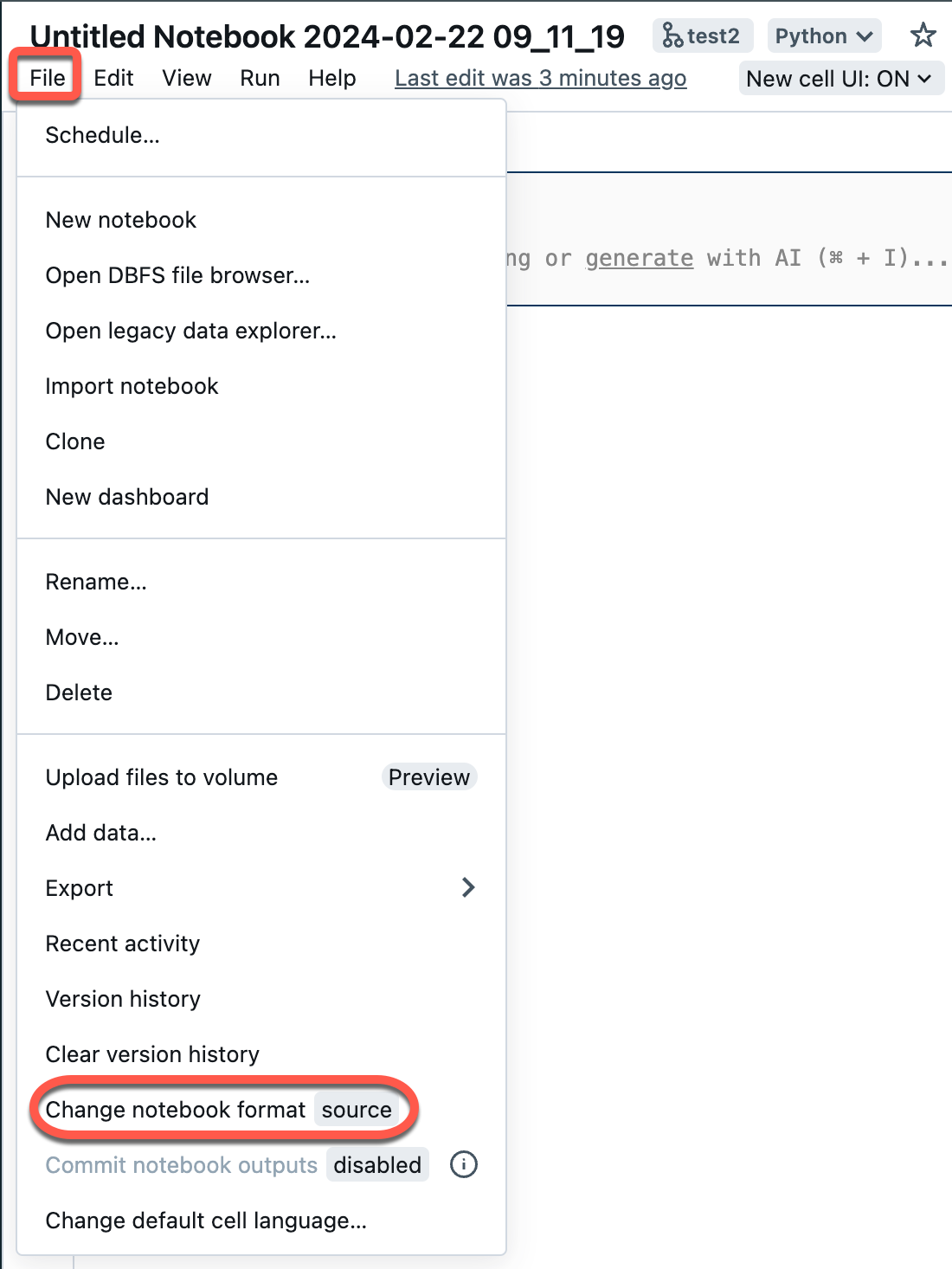
Na caixa de diálogo modal, selecione "Formato do notebook Jupyter (.ipynb)" e clique em Alterar.
Também é possível:
- Criar novos notebooks
.ipynb. - Exiba as diferenças como Diferença de código (alterações de código nas células) ou Diferença bruta (alterações de código apresentadas como sintaxe JSON, que inclui saídas de notebook como metadados).
Para obter mais informações sobre os tipos de notebooks com suporte no Azure Databricks, leia Exportar e importar notebooks do Databricks.
Perguntas frequentes: Configuração da pasta Git
Onde o conteúdo do repositório do Azure Databricks é armazenado?
O conteúdo de um repositório é clonado temporariamente em disco no plano de controle. Os arquivos de notebook do Azure Databricks são armazenados no banco de dados do plano de controle, assim como os notebooks no workspace principal. Os arquivos que não são de notebook são armazenados em disco por até 30 dias.
As pastas Git dão suporte a servidores do Git auto-hospedados ou locais?
As pastas Git do Databricks dão suporte a GitHub Enterprise, Bitbucket Server, Azure DevOps Server e integração autogerenciada GitLab, se o servidor está acessível pela Internet. Para obter detalhes sobre a integração de pastas Git com um servidor Git local, leia Git Proxy Server for pastas Git.
Para se integrar a um Bitbucket Server, um GitHub Enterprise Server ou uma instância de assinatura autogerenciada do GitLab que não possa ser acessada pela Internet, entre em contato com sua equipe de conta do Azure Databricks.
Quais tipos de ativos do Databricks são compatíveis com pastas Git?
Para obter detalhes sobre os tipos de ativos compatíveis, leia Tipos de ativos compatíveis com pastas Git.
As pastas Git dão suporte a arquivos .gitignore?
Sim. Se você adicionar um arquivo ao repositório e não quiser que ele seja rastreado pelo Git, crie um arquivo .gitignore ou use um clonado do repositório remoto e adicione o nome do arquivo, incluindo a extensão.
.gitignore funciona apenas para arquivos que ainda não foram rastreados pelo Git. Se você adicionar um arquivo que já esteja acompanhado pelo Git a um arquivo .gitignore, o arquivo ainda será acompanhado pelo Git.
Posso criar pastas de nível superior que não são pastas de usuário?
Sim, os administradores podem criar pastas de nível superior para uma única profundidade. As pastas Git não dão suporte a níveis de pasta adicionais.
As pastas Git dão suporte a submódulos Git?
Não. É possível clonar um repositório que contém submódulos do Git, mas o submódulos não é clonado.
O ADF (Azure Data Factory) dá suporte a pastas Git?
Sim.
Gerenciamento de fonte
Por que os painéis do notebook desaparecem quando eu efetuo pull ou check-out de uma ramificação diferente?
Atualmente, isso é uma limitação porque os arquivos de origem do notebook do Azure Databricks não armazenam informações do painel do notebook.
Se você deseja preservar os painéis no repositório Git, altere o formato do notebook para .ipynb (o formato Jupyter do notebook). Por padrão, .ipynb suporta definições de painel e visualização. Se você deseja preservar os dados do gráfico (pontos de dados), precisa confirmar o notebook com as saídas.
Para saber mais sobre o commit de saídas de notebooks .ipynb, consulte Permitir o commit de saídas de notebooks .ipynb.
As pastas Git dão suporte à mesclagem de branch?
Sim. Você também pode criar uma solicitação pull e mesclar através do seu provedor Git.
Posso excluir uma ramificação de um repositório do Azure Databricks?
Não. Para excluir uma ramificação, você deve trabalhar em seu provedor do Git.
Se uma biblioteca estiver instalada em um cluster e uma biblioteca com o mesmo nome estiver incluída em uma pasta dentro de um repositório, qual biblioteca será importada?
A biblioteca no repositório é importada. Para obter mais informações sobre a precedência da biblioteca no Python, consulte Precedência da biblioteca Python.
Posso extrair a versão mais recente de um repositório do Git antes de executar um trabalho sem depender de uma ferramenta de orquestração externa?
Não. Normalmente, você pode integrá-lo como um pré-commit no servidor do Git para que cada push para uma ramificação (principal/prod) atualize o repositório de Produção.
Posso exportar um repositório?
Você pode exportar notebooks, pastas ou um repositório inteiro. Não é possível exportar arquivos que não sejam de notebook. Caso exporte um repositório inteiro, arquivos que não sejam de notebook não serão incluídos. Para exportar, use o comando workspace export na CLI do Databricks ou use a API do Espaço de Trabalho.
Segurança, autenticação e tokens
Problema com uma política de acesso condicional (CAP) para o Microsoft Entra ID
Quando você tenta clonar um repositório, pode receber uma mensagem de erro de "acesso negado":
- O Azure Databricks está configurado para usar o Azure DevOps com a autenticação do Microsoft Entra ID.
- Você habilitou uma política de acesso condicional no Azure DevOps e uma política de acesso condicional no Microsoft Entra ID.
Para resolver isso, adicione uma exclusão à política de acesso condicional (CAP) para o endereço IP ou usuários do Azure Databricks.
Para obter mais informações, confira Políticas de acesso condicional.
Lista de permissões com tokens do Azure AD
Se você usar o AAD (Azure Active Directory) para autenticação no Azure DevOps, a lista de permissões padrão restringirá as URLs do Git a:
dev.azure.comvisualstudio.com
Para obter mais informações, confira Listas de permissão que restringem o uso do repositório remoto.
O conteúdo de pastas Git do Azure Databricks é criptografado?
O conteúdo de pastas Git do Azure Databricks é criptografado pelo Azure Databricks usando uma chave padrão. Não há suporte para criptografia usando chaves gerenciadas pelo cliente, exceto ao criptografar suas credenciais do Git.
Como e onde os tokens do GitHub são armazenados no Azure Databricks? Quem teria acesso a partir do Azure Databricks?
- Os tokens de autenticação são armazenados no Azure Databricks de controle e um funcionário do Azure Databricks pode obter acesso apenas por meio de uma credencial temporária auditada.
- O Azure Databricks registra em logs a criação e a exclusão desses tokens, mas não seu uso. O log do Azure Databricks que rastreia as operações do Git que podem ser usadas para auditar o uso dos tokens pelo aplicativo do Azure Databricks.
- O GitHub Enterprise audita o uso do token. Os outros serviços do Git também podem ter auditoria do servidor do Git.
As pastas Git dão suporte à assinatura GPG de commits?
Não.
As pastas Git dão suporte a SSH?
Não, somente HTTPS.
Erro ao conectar o Azure Databricks a um repositório do Azure DevOps em uma locação diferente
Ao tentar conectar-se ao DevOps em uma locação separada, você pode receber a mensagem Unable to parse credentials from Azure Active Directory account. Se o projeto do Azure DevOps estiver em uma locação do Microsoft Entra ID diferente do Azure Databricks, você precisará usar um token de acesso do Azure DevOps. Consulte Conectar-se ao Azure DevOps usando um token DevOps.
CI/CD e MLOps
As alterações de entrada apagam o estado do notebook
As operações do Git que alteram o código-fonte do notebook resultam na perda do estado do notebook, incluindo saídas de célula, comentários, histórico de versão e widgets. Por exemplo, git pull pode alterar o código-fonte de um notebook. Nesse caso, as pastas Git do Databricks precisam substituir o notebook existente para importar as alterações. git commit e push ou a criação de uma nova ramificação não afetam o código-fonte do notebook, portanto, o estado do notebook é preservado nessas operações.
Importante
Os experimentos do MLflow não funcionam em pastas Git com o DBR 14.x ou versões inferiores.
É possível criar um experimento de MLflow em um repositório?
Existem dois tipos de experimentos do MLflow: workspace e notebook. Para obter detalhes sobre os dois tipos de experimentos do MLflow, confira Organizar execuções de treinamento com experimentos do MLflow.
Em pastas Git, você pode chamar mlflow.set_experiment("/path/to/experiment") para um experimento do MLflow de um dos dois tipos e suas execuções de log, mas esse experimento e as execuções associadas não serão verificados no controle do código-fonte.
Experimentos do MLflow de workspace
Você não pode criar experimentos de MLflow de workspace em uma pasta do Git do Databricks (pasta Git). Se vários usuários usarem pastas do Git separadas para colaborar no mesmo código de ML, registre em log as execuções do MLflow de um experimento do MLflow criado em uma pasta regular do workspace.
Experimentos do MLflow de notebook.
Você pode criar experimentos de notebook em uma pasta do Git do Databricks. Se fizer commit do seu notebook no controle do código-fonte como um arquivo .ipynb, você poderá registrar as execuções do MLflow em um experimento MLflow criado e associado automaticamente. Para obter mais detalhes, leia sobre como criar experimentos de notebook.
Evitar a perda de dados em experimentos do MLflow
Os experimentos de MLflow no notebook criados usando Trabalhos do Databricks com código-fonte em um repositório remoto são armazenados em um local de armazenamento temporário. Esses experimentos persistem inicialmente após a execução do fluxo de trabalho, mas correm o risco de exclusão posterior durante a remoção agendada de arquivos no armazenamento temporário. O Databricks recomenda o uso de experimentos de MLflow no espaço de trabalho com os Trabalhos e as fontes remotas do Git.
Aviso
Sempre que você alternar para um branch que não contenha o notebook, você corre o risco de perder os dados do experimento do MLflow associados a ele. Essa perda se tornará permanente se o branch anterior não for acessado dentro de 30 dias.
Para recuperar dados ausentes do experimento antes do vencimento do prazo de 30 dias, renomeie o notebook retornando ao nome original, abra o notebook, clique no ícone "experimento" no painel do lado direito (isso também, efetivamente, chama a API mlflow.get_experiment_by_name()) e você poderá ver o experimento e as execuções recuperados. Após 30 dias, todos os experimentos de MLflow órfãos serão eliminados para cumprir as políticas de conformidade do RGPD.
Para evitar essa situação, o Databricks recomenda que você evite totalmente renomear notebooks no repos ou, se você vier a renomear um notebook, que você clique no ícone "experimento" no painel do lado direito imediatamente após renomear um notebook.
O que acontece se um trabalho de notebook estiver em execução em um workspace enquanto uma operação Git estiver em andamento?
A qualquer momento enquanto uma operação do Git estiver em andamento, alguns notebooks no repositório poderão ter sido atualizados enquanto outros não. Isso pode causar um comportamento imprevisível.
Por exemplo, suponha que notebook A chame notebook Z usando um comando %run. Se um trabalho durante uma operação do Git iniciar a versão mais recente de notebook A, mas notebook Z ainda não tiver sido atualizado, o comando %run no bloco de notas A poderá iniciar a versão mais antiga de notebook Z.
Durante a operação do Git, os estados do notebook não são previsíveis e o trabalho pode falhar ou executar notebook A e notebook Z a partir de commits diferentes.
Para evitar essa situação, use trabalhos baseados em Git (em que a origem é um provedor Git e não um caminho de workspace). Para obter mais detalhes, leia Usar o Git com trabalhos.
Recursos
Para obter detalhes sobre arquivos de workspace do Databricks, confira O que são arquivos de workspace?.