Implantar manualmente um aplicativo Java com o JBoss EAP em um cluster do Red Hat OpenShift no Azure
Este artigo mostra como implantar um aplicativo EAP (Red Hat JBoss Enterprise Application Platform) em um cluster do Red Hat OpenShift no Azure. O exemplo é um aplicativo Java apoiado por um banco de dados SQL. O aplicativo é implantado usando gráficos do Helm do JBoss EAP.
Neste guia, você aprenderá a:
- Prepare um aplicativo JBoss EAP para OpenShift.
- Crie uma única instância de banco de dados do Banco de Dados SQL do Azure.
- Como a Identidade de Carga de Trabalho do Azure ainda não é compatível com o Azure OpenShift, este artigo ainda usa nome de usuário e senha para autenticação de banco de dados em vez de usar conexões de banco de dados sem senha.
- Implantar o aplicativo em um cluster do Red Hat OpenShift no Azure usando o JBoss Helm Charts e o Console Web do OpenShift
O aplicativo de exemplo é um aplicativo com estado que armazena informações em uma sessão HTTP. Ele usa os recursos de clustering JBoss EAP e usa as seguintes tecnologias Jakarta EE e MicroProfile:
- Jakarta Server Faces
- Jakarta Enterprise Beans
- Persistência do Jakarta
- MicroProfile Health
Este artigo é uma orientação manual passo a passo para executar o aplicativo JBoss EAP em um cluster do Red Hat OpenShift no Azure. Para obter uma solução mais automatizada que acelera sua jornada para o cluster do Red Hat OpenShift no Azure, consulte Início Rápido: Implantar o JBoss EAP no Red Hat OpenShift no Azure usando o portal do Azure.
Se você estiver interessado em fornecer comentários ou trabalhar em estreita colaboração em seu cenário de migração com a equipe de engenharia que desenvolve o JBoss EAP em soluções do Azure, preencha esta breve pesquisa sobre a migração do JBoss EAP e inclua suas informações de contato. A equipe de gerentes de programas, arquitetos e engenheiros entrará em contato prontamente com você para dar início a uma estreita colaboração.
Importante
Este artigo implanta um aplicativo usando Pacotes do Helm do JBoss EAP. No momento da redação, esse recurso ainda é oferecido como uma versão prévia da tecnologia. Antes de optar por implantar aplicativos com Pacotes do Helm do JBoss EAP em ambientes de produção, verifique se esse recurso é um recurso compatível com a sua versão do produto JBoss EAP/XP.
Importante
Enquanto o Red Hat e o Microsoft Azure co-desenvolvem, operam e dão suporte ao Azure Red Hat OpenShift para fornecer uma experiência de suporte integrada, o software que você executa sobre o Azure Red Hat OpenShift, incluindo o descrito neste artigo, está sujeito a seus próprios termos de suporte e licença. Para obter detalhes sobre o suporte do Red Hat OpenShift no Azure, consulte Ciclo de vida do suporte do Red Hat OpenShift 4 no Azure. Para obter detalhes sobre o suporte do software descrito neste artigo, confira as páginas principais desse software, conforme listado no artigo.
Pré-requisitos
Observação
O Red Hat OpenShift no Azure requer um mínimo de 40 núcleos para criar e executar um cluster do OpenShift. A cota de recursos padrão do Azure para uma nova assinatura do Azure não atende a esse requisito. Para solicitar um aumento no limite de recursos, confira Cota Standard: Aumentar limites por série de VM. A assinatura de avaliação gratuita não está qualificada para um aumento de cota. Atualize para uma assinatura paga conforme o uso antes de solicitar um aumento de cota.
Prepare uma máquina local com um sistema operacional semelhante ao Unix suportado pelos vários produtos instalados - como Ubuntu, macOS ou Windows Subsystem for Linux.
Instale uma implementação Java Standard Edition (SE). As etapas de desenvolvimento local neste artigo foram testadas com o Java Development Kit (JDK) 17 do build do OpenJDK da Microsoft.
Instale o Maven 3.8.6 ou posterior.
Instale a CLI do Azure 2.40 ou posterior.
Clone o código deste aplicativo de demonstração (lista de pendências) para o sistema local. O aplicativo de demonstração está no GitHub.
Siga as instruções em Criar um cluster do Red Hat OpenShift 4 no Azure.
Embora a etapa "Obter um segredo de pull do Red Hat" seja rotulada como opcional, ela é necessária para este artigo. O segredo de pull permite que o cluster do Red Hat OpenShift no Azure encontre as imagens do aplicativo JBoss EAP.
Se você planeja executar aplicativos com uso intensivo de memória no cluster, especifique o tamanho adequado da máquina virtual para os nós de trabalho usando o parâmetro
--worker-vm-size. Para saber mais, veja:Conecte-se ao cluster seguindo as etapas em Conectar-se a um cluster do Red Hat OpenShift 4 no Azure.
- Siga as etapas em "Instalar a CLI do OpenShift"
- Conectar-se a um cluster do Red Hat OpenShift no Azure usando a CLI do OpenShift com o usuário
kubeadmin
Execute o seguinte comando para criar o projeto OpenShift para este aplicativo de demonstração:
oc new-project eap-demoExecute o comando a seguir para adicionar a função de exibição à conta de serviço padrão. Essa função é necessária para que o aplicativo possa descobrir outros pods e configurar um cluster com eles:
oc policy add-role-to-user view system:serviceaccount:$(oc project -q):default -n $(oc project -q)
Preparar o aplicativo
Clone o aplicativo de exemplo usando o seguinte comando:
git clone https://github.com/Azure-Samples/jboss-on-aro-jakartaee
Você clonou o aplicativo de demonstração Todo-list e seu repositório local está na ramificação principal. O aplicativo de demonstração é um aplicativo Java simples que cria, lê, atualiza e exclui registros no SQL do Azure. Você pode implantar este aplicativo como ele está em um servidor JBoss EAP instalado em sua máquina local. Você só precisa configurar o servidor com o driver de banco de dados e a fonte de dados necessários. Você também precisa de um servidor de banco de dados acessível em seu ambiente local.
No entanto, quando você está direcionando o OpenShift, você pode querer cortar os recursos do seu servidor JBoss EAP. Por exemplo, talvez você queira reduzir a exposição à segurança do servidor provisionado e reduzir o volume geral. Talvez você também queira incluir algumas especificações do MicroProfile para tornar seu aplicativo mais adequado para execução em um ambiente do OpenShift. Quando você usa o JBoss EAP, uma maneira de realizar essa tarefa é empacotando seu aplicativo e seu servidor em uma única unidade de implantação conhecida como JAR inicializável. Vamos fazer isso adicionando as alterações necessárias ao nosso aplicativo de demonstração.
Navegue até o repositório local do seu aplicativo de demonstração e altere a ramificação para bootable-jar.
## cd jboss-on-aro-jakartaee
git checkout bootable-jar
Vamos rever rapidamente o que alteramos nesse branch:
- Adicionamos o
wildfly-jar-mavenplug-in para provisionar o servidor e o aplicativo em um único arquivo JAR executável. A unidade de implantação do OpenShift é o nosso servidor com o nosso aplicativo. - No plug-in Maven, especificamos um conjunto de camadas do Galeão. Essa configuração nos permite ajustar os recursos do servidor apenas para o que precisamos. Para ver a documentação completa no Galleon, confira a documentação do WildFly.
- Nosso aplicativo usa Jakarta Faces com solicitações Ajax, o que significa que há informações armazenadas na sessão HTTP. Não queremos perder essas informações caso um pod seja removido. Poderíamos salvar essas informações no cliente e enviá-las de volta em cada solicitação. No entanto, há casos em que você pode decidir não distribuir determinadas informações para os clientes. Para esta demonstração, optamos por replicar a sessão em todas as réplicas de pod. Para fazer isso, adicionamos
<distributable />ao web.xml. Isso, juntamente com os recursos de clustering de servidor, torna a sessão HTTP distribuível em todos os pods. - Adicionamos duas verificações de integridade do MicroProfile que permitem identificar quando o aplicativo está ativo e pronto para receber solicitações.
Executar o aplicativo localmente
Antes de implantar o aplicativo no OpenShift, vamos executá-lo localmente para verificar como ele funciona. As etapas a seguir pressupõem que você tenha o SQL do Azure em execução e disponível em seu ambiente local.
Para criar o banco de dados, siga as etapas no Início Rápido: criar um banco de dados individual do Banco de Dados SQL do Azure, mas use as seguintes substituições.
- Para Grupo de recursos , use o grupo de recursos que você criou anteriormente.
- Para Nome do banco de dados, use
todos_db. - Em Logon do administrador do servidor, use
azureuser. - Para Senha, use
Passw0rd!. - Na seção Regras de firewall, alterne Permitir que serviços e recursos do Azure acessem este servidor para Sim.
Todas as outras configurações podem ser usadas com segurança no artigo vinculado.
Na página Configurações adicionais, você não precisa escolher a opção de preencher previamente o banco de dados com dados de exemplo, mas não há mal nenhum em fazer isso.
Depois de criar o banco de dados, obtenha o valor do nome do servidor na página de visão geral. Passe o mouse sobre o valor do campo Nome do servidor e selecione o ícone de cópia que aparece ao lado do valor. Salve esse valor de lado para uso posterior (definimos uma variável chamada MSSQLSERVER_HOST para esse valor).
Observação
Para manter os custos monetários baixos, o Início Rápido orienta o leitor a selecionar a camada de computação sem servidor. Esta camada se ajusta a zero quando não há atividade. Quando isso acontece, o banco de dados não responde imediatamente. Se, em algum momento, ao executar as etapas neste artigo, você observar problemas de banco de dados, considere desabilitar a pausa automática. Para saber como, pesquise Pausa automática em Banco de Dados SQL do Azure sem servidor. No momento da gravação, o seguinte comando da CLI do Azure desabilita a pausa automática para o banco de dados configurado neste artigo: az sql db update --resource-group $RESOURCEGROUP --server <Server name, without the .database.windows.net part> --name todos_db --auto-pause-delay -1
Siga as etapas abaixo para criar e executar o aplicativo localmente.
Crie o JAR inicializável. Como estamos usando o banco de dados com o
eap-datasources-galleon-packMS SQL Server, devemos especificar a versão do driver de banco de dados que queremos usar com essa variável de ambiente específica. Para obter mais informações sobre o e oeap-datasources-galleon-packMS SQL Server, consulte a documentação da Red Hatexport MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 mvn clean packageInicie o JAR inicializável usando os comandos a seguir.
Você deve garantir que o banco de dados SQL do Azure permita o tráfego de rede do host no qual esse servidor está sendo executado. Como você selecionou Adicionar endereço IP do cliente atual ao executar as etapas no Início Rápido: criar um banco de dados único do Banco de Dados SQL do Azure, se o host no qual o servidor está em execução for o mesmo host do qual seu navegador está se conectando ao portal do Azure, o tráfego de rede deverá ser permitido. Se o host no qual o servidor está sendo executado for algum outro host, você precisará consultar Usar o portal do Azure para gerenciar regras de firewall IP no nível do servidor.
Quando estamos iniciando o aplicativo, precisamos passar as variáveis de ambiente necessárias para configurar a fonte de dados:
export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:runSe você quiser saber mais sobre o runtime subjacente usado por essa demonstração, a documentação Pack de Recursos do Galleon para integrar fontes de dados tem uma lista completa de variáveis de ambiente disponíveis. Para obter detalhes sobre o conceito de feature-pack, confira a documentação do WildFly.
Se você receber um erro com texto semelhante ao exemplo a seguir:
Cannot open server '<your prefix>mysqlserver' requested by the login. Client with IP address 'XXX.XXX.XXX.XXX' is not allowed to access the server.Essa mensagem indica que suas etapas para garantir que o tráfego de rede seja permitido não funcionaram. Verifique se o endereço IP da mensagem de erro está incluído nas regras de firewall.
Se você receber uma mensagem com texto semelhante ao exemplo a seguir:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: There is already an object named 'TODOS' in the database.Essa mensagem indica que os dados de exemplo já estão no banco de dados. Você pode ignorar esta mensagem.
(Opcional) Se você quiser verificar os recursos de clustering, também poderá iniciar mais instâncias do mesmo aplicativo passando o argumento
jboss.node.namepara o JAR inicializável e, para evitar conflitos com os números de porta, deslocando os números de porta usandojboss.socket.binding.port-offset. Por exemplo, para iniciar uma segunda instância que representa um novo pod no OpenShift, você pode executar o seguinte comando em uma nova janela de terminal:export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:run -Dwildfly.bootable.arguments="-Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000"Se o cluster estiver funcionando, você poderá ver no log do console do servidor um rastreamento semelhante ao seguinte:
INFO [org.infinispan.CLUSTER] (thread-6,ejb,node) ISPN000094: Received new cluster view for channel ejbObservação
Por padrão, o JAR inicializável configura o subsistema JGroups para usar o protocolo UDP e envia mensagens para descobrir outros membros do cluster para o endereço multicast 230.0.0.4. Para verificar corretamente os recursos de clustering em seu computador local, seu sistema operacional deve ser capaz de enviar e receber datagramas multicast e encaminhá-los para o IP 230.0.0.4 por meio de sua interface ethernet. Se você vir avisos relacionados ao cluster nos logs do servidor, verifique sua configuração de rede e verifique se ela dá suporte a multicast nesse endereço.
Abra http://localhost:8080/ no navegador para visitar a home page do aplicativo. Se você criou mais instâncias, poderá acessá-las mudando o número da porta, por exemplo, http://localhost:9080/. O aplicativo deve ser semelhante à imagem a seguir:
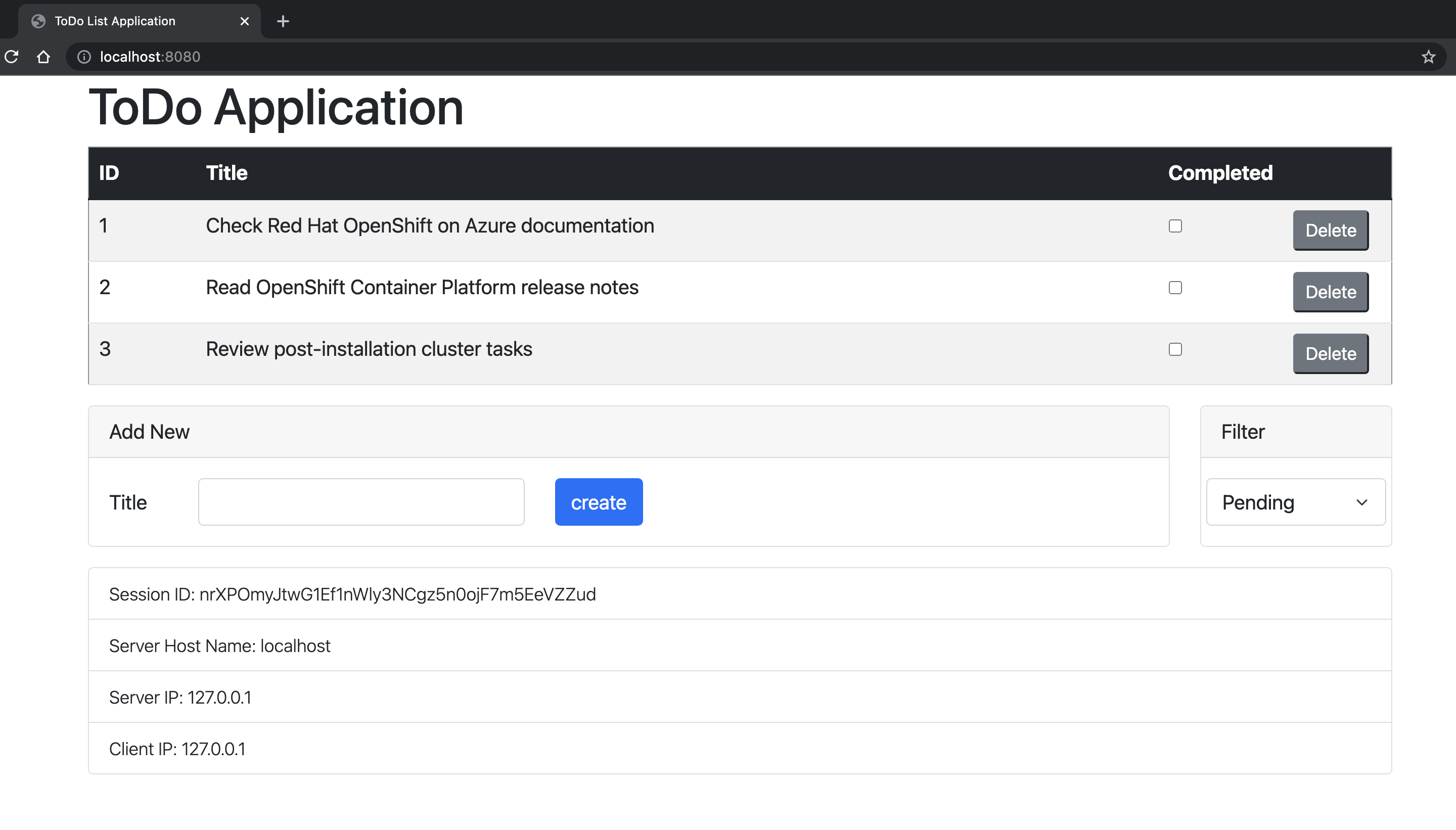
Verifique as investigações de disponibilidade e preparação para o aplicativo. O OpenShift usa esses endpoints para verificar quando o pod está ativo e pronto para receber solicitações do usuário.
Para verificar o status de disponibilidade, execute:
curl http://localhost:9990/health/liveVocê deverá ver este resultado:
{"status":"UP","checks":[{"name":"SuccessfulCheck","status":"UP"}]}Para verificar o status de prontidão, execute:
curl http://localhost:9990/health/readyVocê deverá ver este resultado:
{"status":"UP","checks":[{"name":"deployments-status","status":"UP","data":{"todo-list.war":"OK"}},{"name":"server-state","status":"UP","data":{"value":"running"}},{"name":"boot-errors","status":"UP"},{"name":"DBConnectionHealthCheck","status":"UP"}]}Pressione Ctrl+ C para interromper o aplicativo.
Implantar no OpenShift
Para implantar o aplicativo, usaremos os gráficos do Helm do JBoss EAP já disponíveis no Red Hat OpenShift no Azure. Também precisamos fornecer a configuração desejada, por exemplo, o usuário do banco de dados, a senha do banco de dados, a versão do driver que desejamos usar e as informações de conexão usadas pela fonte de dados. As etapas a seguir pressupõem que você tenha o SQL do Azure em execução e acessível no cluster do OpenShift e armazenou o nome de usuário, a senha, o nome do host, a porta e o nome do banco de dados do banco de dados em um objeto OpenShift OpenShift Secret chamado mssqlserver-secret.
Vá para o repositório local da sua aplicação de demonstração e altere o branch atual para bootable-jar-openshift:
git checkout bootable-jar-openshift
Vamos fazer uma rápida revisão sobre o que mudamos neste branch:
- Adicionamos um novo perfil Maven chamado
bootable-jar-openshiftque prepara o JAR inicializável com uma configuração específica para executar o servidor na nuvem. Por exemplo, ele permite que o subsistema JGroups use solicitações de rede para descobrir outros pods usando o protocolo KUBE_PING. - Adicionamos um conjunto de arquivos de configuração no diretório jboss-on-aro-jakartaee/deployment . Nesse diretório, você pode encontrar os arquivos de configuração para implantar o aplicativo.
Implantar o aplicativo no OpenShift
As próximas etapas explicam como você pode implantar o aplicativo com um gráfico do Helm usando o console Web OpenShift. Evite codificar valores confidenciais em seu gráfico do Helm usando um recurso chamado "segredos". Um segredo é simplesmente uma coleção de pares nome-valor, em que os valores são especificados em algum lugar conhecido antes de serem necessários. Em nosso caso, o gráfico de Helm usa dois segredos, com os seguintes pares name-value de cada um.
mssqlserver-secretdb-hosttransmite o valor deMSSQLSERVER_HOST.db-nametransmite o valor deMSSQLSERVER_DATABASEdb-passwordtransmite o valor deMSSQLSERVER_PASSWORDdb-porttransmite o valor deMSSQLSERVER_PORT.db-usertransmite o valor deMSSQLSERVER_USER.
todo-list-secretapp-cluster-passwordtransmite uma senha arbitrária especificada pelo usuário para que os nós de cluster possam se formar com mais segurança.app-driver-versiontransmite o valor deMSSQLSERVER_DRIVER_VERSION.app-ds-jnditransmite o valor deMSSQLSERVER_JNDI.
Crie
mssqlserver-secret.oc create secret generic mssqlserver-secret \ --from-literal db-host=${MSSQLSERVER_HOST} \ --from-literal db-name=${MSSQLSERVER_DATABASE} \ --from-literal db-password=${MSSQLSERVER_PASSWORD} \ --from-literal db-port=${MSSQLSERVER_PORT} \ --from-literal db-user=${MSSQLSERVER_USER}Crie
todo-list-secret.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 oc create secret generic todo-list-secret \ --from-literal app-cluster-password=mut2UTG6gDwNDcVW \ --from-literal app-driver-version=${MSSQLSERVER_DRIVER_VERSION} \ --from-literal app-ds-jndi=${MSSQLSERVER_JNDI}Abra o console do OpenShift e navegue até a exibição de desenvolvedor. Você pode descobrir a URL do console do cluster do OpenShift executando este comando. Entre com o nome de usuário
kubeadmine a senha obtidos em uma etapa anterior.az aro show \ --name $CLUSTER \ --resource-group $RESOURCEGROUP \ --query "consoleProfile.url" \ --output tsvSelecione a <perspectiva /> Desenvolvedor no menu suspenso na parte superior do painel de navegação.
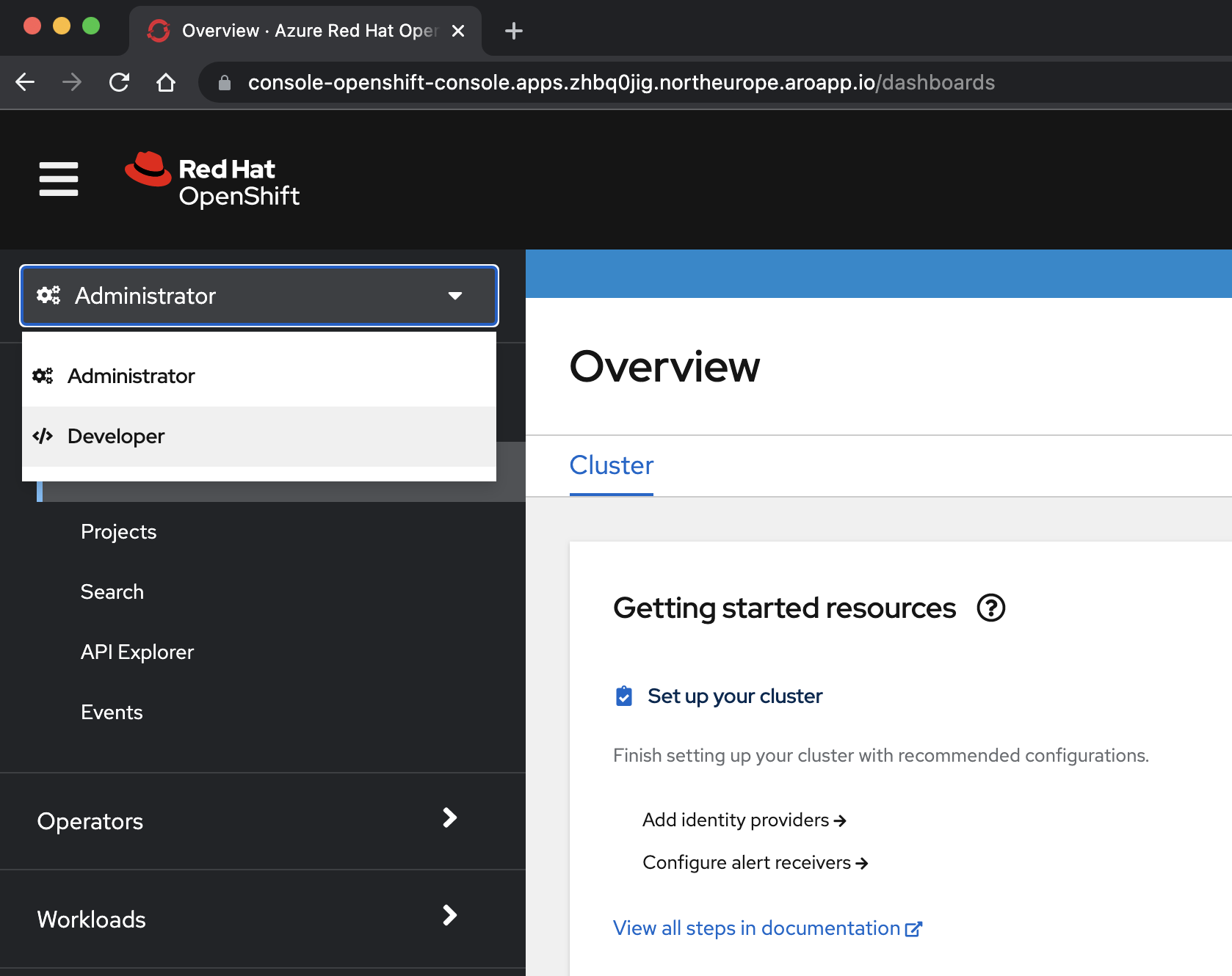
Na perspectiva /< Developer, selecione o > no menu suspenso Projeto.
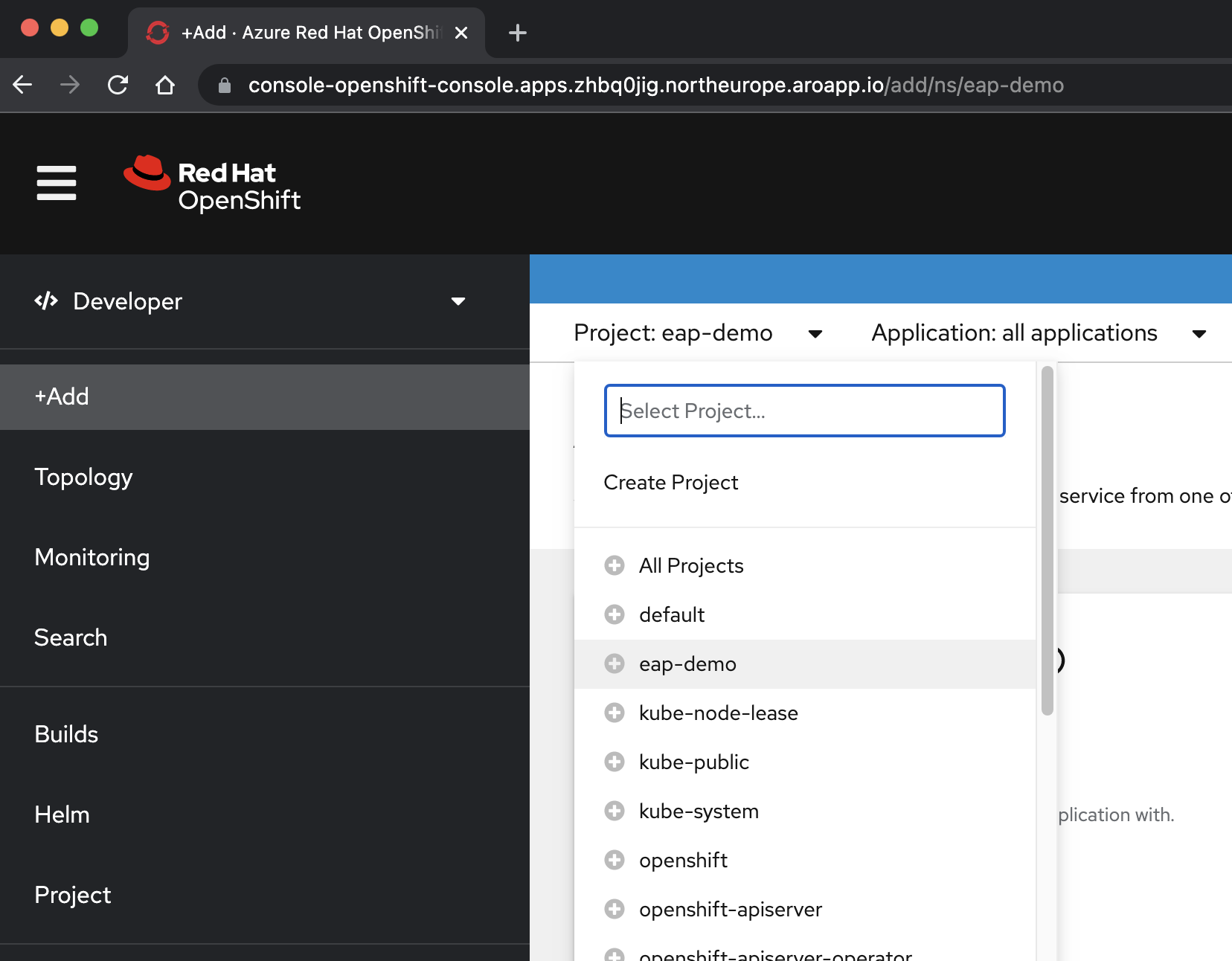
Selecione +Adicionar. Na seção Catálogo de Desenvolvedores, selecione Gráfico do Helm. Você chega ao catálogo do Helm Chart disponível no cluster do Red Hat OpenShift no Azure. Na caixa Filtrar por palavra-chave, digite eap. Você deve ver várias opções, conforme mostrado aqui:
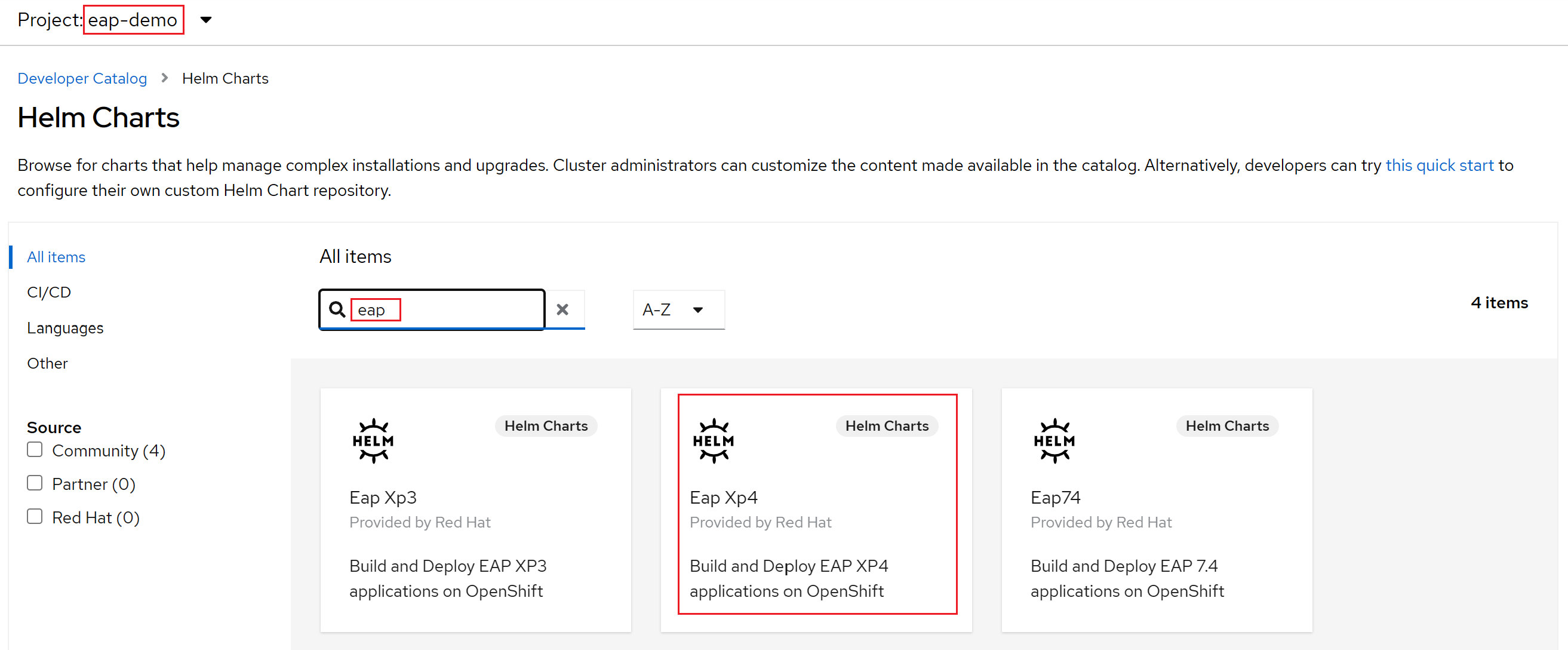
Como nosso aplicativo usa recursos de MicroProfile, selecionamos o Gráfico de Helm para EAP Xp. O "Xp" significa Pacote de Expansão. Com o pacote de expansão do JBoss Enterprise Application Platform, os desenvolvedores podem usar APIs (interfaces de programação de aplicativo) do Eclipse MicroProfile para criar e implantar aplicativos baseados em microsserviços.
Selecione o gráfico do JBoss EAP XP 4 Helm e, em seguida, selecione Instalar gráfico do Helm.
Neste ponto, precisamos configurar o pacote para criar e implantar o aplicativo:
Altere o nome da versão para eap-todo-list-demo.
Podemos configurar o Pacote do Helm usando uma Exibição de Formulário ou uma Exibição YAML. Na seção rotulada Configurar por meio de, selecione Exibição YAML.
Altere o conteúdo YAML para configurar o Pacote do Helm copiando e colando o conteúdo do arquivo do Pacote do Helm disponível em deployment/application/todo-list-helm-chart.yaml em vez do conteúdo existente:

Este conteúdo faz referências aos segredos que você definiu anteriormente.
Por fim, selecione Instalar para iniciar a implantação do aplicativo. Essa ação abre a visualização Topologia com uma representação gráfica da versão do Helm (chamada eap-todo-list-demo) e seus recursos associados.
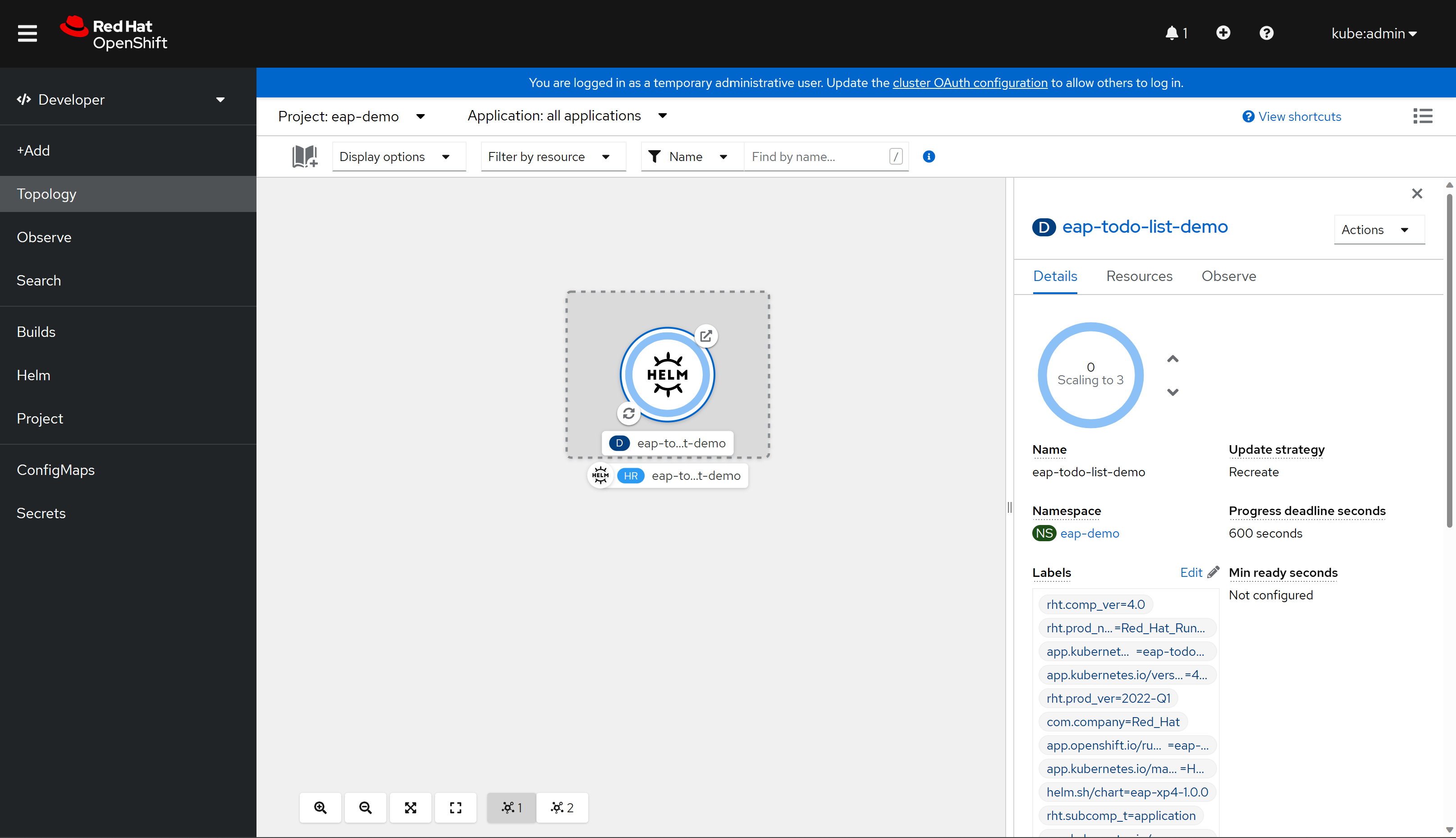
A Versão do Helm (abreviada como HR) é denominada eap-todo-list-demo. Ela inclui um recurso de implantação (abreviado como D) também chamado eap-todo-list-demo.
Se você selecionar o ícone com duas setas em um círculo no canto inferior esquerdo da caixa D , será levado para o painel Logs . Aqui você pode observar o progresso do build. Para retornar ao modo de exibição de topologia, selecione Topologia no painel de navegação esquerdo.
Quando o build for concluído, o ícone inferior esquerdo exibirá uma marca de verificação verde.
Quando a implantação é concluída, o contorno do círculo é azul escuro. Se você passar o mouse sobre o azul escuro, verá uma mensagem informando algo semelhante a
3 Running. Ao ver essa mensagem, você pode ir para a URL do aplicativo (usando o ícone superior direito) da rota associada à implantação.
O aplicativo é aberto no navegador, pronto para ser usado, com aparência semelhante à seguinte imagem:
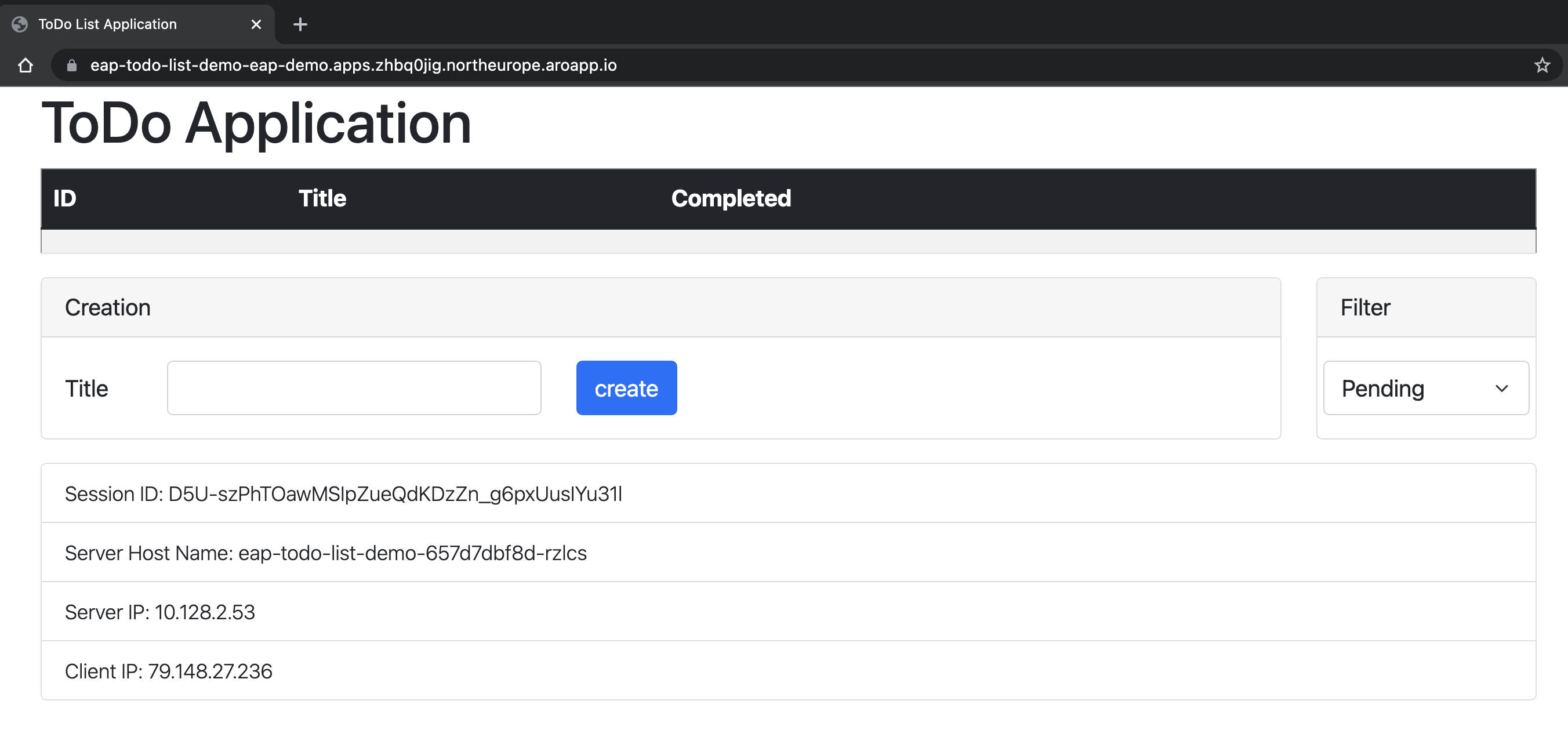
O aplicativo mostra o nome do pod que fornece as informações. Para verificar recursos de agrupamento, você pode adicionar alguns itens Todo. Em seguida, exclua o pod com o nome indicado no campo Nome do host do servidor que aparece no aplicativo usando
oc delete pod <pod-name>. Depois de excluir o pod, crie um novo Todo na mesma janela do aplicativo. Você pode ver que o novo Todo é adicionado por meio de uma solicitação Ajax e o campo nome do servidor host agora mostra um nome diferente. Nos bastidores, o balanceador de carga do OpenShift despachou a nova solicitação e a entregou a um pod disponível. A exibição do Jakarta Faces é restaurada da cópia da sessão HTTP armazenada no pod que está processando a solicitação. De fato, você pode ver que o campo ID da sessão não foi alterado. Se a sessão não for replicada em seus pods, você obterá um Jakarta FacesViewExpiredExceptione seu aplicativo não funcionará conforme o esperado.

Limpar os recursos
Excluir o aplicativo
Se você quiser apenas excluir seu aplicativo, poderá abrir o console do OpenShift e, na exibição do desenvolvedor, navegar até a opção de menu Helm. Nesse menu, você pode ver todas as versões do Helm Chart instaladas no cluster.

Localize o Gráfico de Helm eap-todo-list-demo. No final da linha, selecione os pontos verticais da árvore para abrir a entrada de menu contextual de ação.
Selecione Desinstalar a Versão do Helm para remover o aplicativo. Observe que o objeto secreto usado para fornecer a configuração do aplicativo não faz parte do gráfico. Você precisará removê-lo separadamente se não precisar mais dele.
Execute o seguinte comando se você quiser excluir o segredo que contém a configuração do aplicativo:
$ oc delete secrets/todo-list-secret
# secret "todo-list-secret" deleted
Excluir o projeto OpenShift
Você também pode excluir toda a configuração criada para esta demonstração excluindo o projeto eap-demo. Para fazer isso, execute o seguinte comando:
$ oc delete project eap-demo
# project.project.openshift.io "eap-demo" deleted
Excluir o cluster do Red Hat OpenShift no Azure
Exclua o cluster do Red Hat OpenShift no Azure seguindo as etapas em Tutorial: excluir um cluster do Red Hat OpenShift 4 no Azure.
Exclua o grupo de recursos
Se você quiser excluir todos os recursos criados pelas etapas anteriores, exclua o grupo de recursos criado para o cluster do Red Hat OpenShift no Azure.
Próximas etapas
Você pode saber mais sobre as referências usadas neste guia:
- Red Hat JBoss Enterprise Application Platform
- Red Hat OpenShift no Azure
- Pacotes do Helm do JBoss EAP
- JAR inicializável do JBoss EAP
Continue a explorar as opções para executar o JBoss EAP no Azure.