Confiabilidade no namespace da Grade de Eventos do Azure e da Grade de Eventos
Este artigo contém informações detalhadas sobre a resiliência regional do namespace da Grade de Eventos do Azure e da Grade de Eventos com zonas de disponibilidade e recuperação de desastre entre regiões e continuidade dos negócios.
Para ter uma visão geral arquitetônica da confiabilidade no Azure, confira Confiabilidade do Azure.
Suporte à zona de disponibilidade
As zonas de disponibilidade do Azure são pelo menos três grupos de datacenters separados fisicamente em cada região do Azure. Os datacenters dentro de cada zona são equipados com energia, resfriamento e infraestrutura de rede independentes. Em caso de falha de uma zona local, as zonas de disponibilidade foram projetadas de modo que, se uma zona é afetada, os serviços regionais, a capacidade e a alta disponibilidade têm suporte nas duas zonas restantes.
As falhas podem variar de falhas de software e hardware a eventos como terremotos, inundações e incêndios. A tolerância a falhas é obtida devido à redundância e ao isolamento lógico dos serviços do Azure. Para obter informações detalhadas sobre as zonas de disponibilidade no Azure, confira Regiões e zonas de disponibilidade.
Os serviços habilitados para zonas de disponibilidade do Azure foram projetados para fornecer o nível ideal de resiliência e flexibilidade. Eles podem ser configurados de duas maneiras. Eles podem ter redundância de zona, com replicação automática entre zonas, ou podem ser zonais, com instâncias fixadas em uma zona específica. Você também pode combinar essas abordagens. Para obter mais informações sobre a arquitetura zonal versus com redundância de zona, confira Recomendações para usar zonas e regiões de disponibilidade.
As definições de recursos da Grade de Eventos para tópicos, tópicos do sistema, domínios e assinaturas de eventos e dados de eventos são replicadas automaticamente em três zonas de disponibilidade. Quando há uma falha regional em uma das zonas de disponibilidade, os recursos da Grade de Eventos fazem failover automático para outra zona de disponibilidade sem qualquer intervenção humana. Atualmente, não é possível controlar (habilitar ou desabilitar) esse recurso. Quando uma região existente começa a dar suporte a zonas de disponibilidade, os recursos existentes da Grade de Eventos sofrem failover automático para aproveitar esse recurso. Não é necessária nenhuma ação do cliente.
O namespace da Grade de Eventos do Azure também obtém alta disponibilidade intrarregional usando zonas de disponibilidade.
Pré-requisitos
Para obter suporte à zona de disponibilidade, os recursos da Grade de Eventos devem estar em uma região que dê suporte a zonas de disponibilidade. Para revisar quais regiões dão suporte a zonas de disponibilidade, confira a lista de regiões com suporte.
Preços
Como a Grade de Eventos dá suporte a zonas de disponibilidade automaticamente em regiões que dão suporte a zonas de disponibilidade, não há alterações no preço.
Criar um recurso com zonas de disponibilidade habilitadas
Como a Grade de Eventos dá suporte a zonas de disponibilidade automaticamente em regiões que dão suporte a zonas de disponibilidade, nenhuma definição de configuração é necessária.
Migrar para o suporte às zonas de disponibilidade
Se você realocar os recursos da Grade de Eventos para uma região que dá suporte a zonas de disponibilidade, você receberá automaticamente o suporte à zona de disponibilidade. Para saber como realocar seus recursos para outra região que dá suporte a zonas de disponibilidade, confira o seguinte:
- Realocar tópicos do sistema da Grade de Eventos do Azure para outra região
- Realocar tópicos personalizados da Grade de Eventos do Azure para outra região
- Realocar domínios da Grade de Eventos do Azure para outra região
Recuperação de desastre entre regiões e continuidade dos negócios
A DR (recuperação de desastre) trata da recuperação após eventos de alto impacto, como desastres naturais ou implantações com falha, que resultam em tempo de inatividade e perda de dados. Seja qual for a causa, a melhor solução para um desastre é um plano de DR bem definido e testado e um design de aplicativo que dê suporte ativo à DR. Antes de começar a pensar em criar seu plano de recuperação de desastre, confira Recomendações para criar uma estratégia de recuperação de desastre.
Quando o assunto é DR, a Microsoft usa o modelo de responsabilidade compartilhada. Em um modelo de responsabilidade compartilhada, a Microsoft garante que a infraestrutura de linha de base e os serviços de plataforma estejam disponíveis. Ao mesmo tempo, muitos serviços do Azure não replicam dados automaticamente nem retornam de uma região com falha para a replicação cruzada em outra região habilitada. Para esses serviços, você é responsável por configurar um plano de recuperação de desastre que funcione para sua carga de trabalho. A maioria dos serviços executados nas ofertas de PaaS (plataforma como serviço) do Azure fornece recursos e diretrizes para dar suporte à DR. Além disso, você pode usar recursos específicos do serviço para dar suporte a uma recuperação rápida, a fim de ajudar a desenvolver seu plano de DR.
A recuperação de desastre geralmente envolve a criação de um recurso de backup para evitar interrupções quando uma região se torna não íntegra. Durante esse processo, uma região primária e secundária de recursos da Grade de Eventos do Azure será necessária na carga de trabalho.
Há diferentes maneiras de se recuperar de uma perda grave de funcionalidade do aplicativo. Nesta seção, descreveremos a lista de verificação que você precisará seguir para preparar seu cliente para se recuperar de uma falha devido a uma região ou um recurso não íntegro.
A Grade de Eventos dá suporte à GeoDR (recuperação de desastre geográfico) manual e automática no lado do servidor. Você ainda poderá implementar a lógica de recuperação de desastre do lado do cliente se quiser um controle maior sobre o processo de failover. Para obter detalhes sobre GeoDR automático, veja Recuperação de desastre geográfico do lado do servidor na Grade de Eventos do Azure. Para obter detalhes sobre como implementar a recuperação de desastres do lado do cliente, veja Implementação de failover do lado do cliente no Azure Event Grid.
A tabela a seguir ilustra o failover do lado do cliente e o suporte à recuperação de desastre geográfico na Grade de Eventos.
| Recurso da Grade de Eventos | Suporte a failover do lado do cliente | Suporte à GeoDR (recuperação de desastre geográfico) |
|---|---|---|
| Tópicos personalizados | Com suporte | Entre áreas geográficas/regional |
| Tópicos do sistema | Sem suporte | Habilitado automaticamente |
| Domínios | Com suporte | Entre áreas geográficas/regional |
| Namespaces de parceiro | Com suporte | Sem suporte |
| Namespaces | Com suporte | Incompatível |
Namespace da Grade de Eventos
O namespace da Grade de Eventos não dá suporte à recuperação de desastre entre regiões. No entanto, você pode obter alta disponibilidade entre regiões por meio da implementação de failover do lado do cliente criando namespaces primários e secundários.
Com uma implementação de failover do lado do cliente, você pode:
Implementar um processo personalizado (manual ou automatizado) para replicar o namespace, as identidades do cliente e outras configurações**, incluindo certificados de CA, grupos de clientes, espaços de tópico, associações de permissão e roteamento entre as regiões primárias e secundárias.
Implementar um serviço de concierge que forneça aos clientes pontos de extremidade primários e secundários executando uma verificação de integridade nos pontos de extremidade. O serviço de concierge pode ser um aplicativo Web que é replicado e acessível usando técnicas de redirecionamento de DNS, por exemplo, usando o Gerenciador de Tráfego do Azure.
Obter uma solução de DR ativo-ativo replicando os metadados e equilibrando a carga entre os namespaces. Uma solução de recuperação de desastre Ativa-Passiva pode ser obtida replicando os metadados para manter pronto o namespace secundário para que, quando o namespace primário estiver indisponível, o tráfego possa ser direcionado para o namespace secundário.
Configurar recuperação de desastre
Para regiões emparelhadas, a Grade de Eventos oferece uma capacidade de fazer failover do tráfego de publicação para a região emparelhada para tópicos personalizados, tópicos do sistema e domínios. Nos bastidores, a Grade de Eventos sincroniza automaticamente as definições de recursos de tópicos, tópicos do sistema, domínios e assinaturas de eventos para a região emparelhada. No entanto, os dados do evento não são replicados para a região emparelhada. No estado normal, os eventos são armazenados na região selecionada para esse recurso. Quando há uma interrupção na região e a Microsoft inicia o failover, novos eventos começam a fluir para a região emparelhada geograficamente e são despachados de lá sem nenhuma intervenção sua. Os eventos publicados e aceitos na região original são enviados de lá depois que a interrupção é atenuada.
Você pode escolher entre duas opções de failover, failover iniciado pela Microsoft e iniciado pelo cliente. Para obter etapas detalhadas sobre como definir ambas as configurações, confira Configurar a residência de dados.
O failover iniciado pela Microsoft é um recurso raramente usado pela Microsoft para realizar o failover de recursos da Grade de Eventos da região afetada para a região geográfica emparelhada correspondente. A Microsoft se reserva o direito de determinar quando essa opção será exercida. Esse mecanismo não envolve o consentimento do usuário para a realização do failover do tráfego do usuário.
Habilite essa funcionalidade atualizando a configuração para seu tópico ou domínio. Selecione Entre áreas geográficas (padrão) para habilitar o failover iniciado pela Microsoft.
O failover iniciado pelo cliente é definido pelo seu plano de recuperação de desastre personalizado para tópicos e domínios da Grade de Eventos do Azure, e nenhum dado de qualquer tipo é replicado para outra região pela Microsoft. Embora essa opção de failover exija um pouco mais de esforço, ela permite failover mais rápido e você controla a escolha de regiões secundárias. Caso deseje implementar a recuperação de desastre do lado do cliente para tópicos da Grade de Eventos do Azure, confira Criar sua própria recuperação de desastre do lado do cliente para tópicos da Grade de Eventos do Azure.
Existem alguns motivos pelos quais talvez você queira desabilitar o recurso de failover iniciado pela Microsoft:
- O failover iniciado pela Microsoft é feito do melhor modo possível.
- Alguns pares geográficos não atendem aos requisitos de residência de dados da sua organização.
Habilite essa funcionalidade atualizando a configuração para seu tópico ou domínio. Selecione Regional.
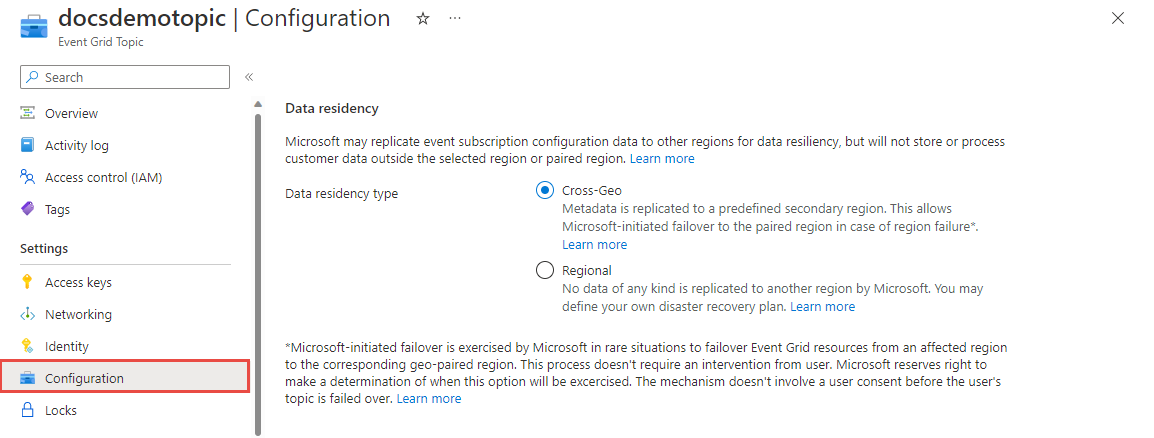
Se você usar uma região não emparelhada, independentemente da configuração de residência de dados selecionada, os metadados serão replicados apenas na região.
Experiência de failover de recuperação de desastre
A recuperação de desastre é medida com duas métricas, RPO (Objetivo de Ponto de Recuperação) e RTO (Objetivo de Tempo de Recuperação).
O failover automático da Grade de Eventos tem diferentes RPOs e RTOs para seus metadados (tópicos, domínios, assinaturas de eventos) e dados (eventos). Se precisar de uma especificação diferente das seguintes, você ainda poderá implementar seu próprio failover no lado do cliente usando as APIs de integridade do tópico.
RPO (Objetivo de Ponto de Recuperação)
RPO de metadados: zero minutos. Para recursos aplicáveis, quando um recurso é criado/atualizado/excluído, a definição de recurso é replicada de modo síncrono para o par geográfico. Quando ocorre um failover, nenhum metadado é perdido.
RPO de dados: quando ocorre um failover, novos dados são processados da região emparelhada. Assim que a interrupção for mitigada para a região afetada, os eventos não processados serão despachados de lá. Se a recuperação da região exigir mais tempo do que o valor de vida útil definido em eventos, os dados poderão ser descartados. Para atenuar essa perda de dados, recomendamos que você configure um destino de mensagens mortas para uma assinatura de evento. Se a região afetada for perdida e não puder ser recuperada, haverá alguma perda de dados. Na melhor das hipóteses, o assinante está acompanhando a taxa de publicação e apenas alguns segundos de dados são perdidos. O pior cenário será quando o assinante não estiver processando eventos ativamente. Com um tempo máximo de vida útil de 24 horas, a perda de dados pode ser de até 24 horas.
RTO (Objetivo de Tempo de Recuperação)
RTO de metadados: a tomada de decisão de failover baseia-se em fatores como a capacidade disponível na região emparelhada e pode durar em um intervalo de 60 minutos ou mais. Uma vez iniciado o failover, dentro de 5 minutos, a Grade de Eventos começa a aceitar chamadas de criação/atualização/exclusão de tópicos e assinaturas.
RTO de Dados: igual às informações acima.
Importante
- No caso de uma recuperação de desastre no lado do servidor, se a região emparelhada não tiver capacidade extra para assumir o tráfego adicional, a Grade de Eventos não poderá iniciar o failover. A recuperação é feita do melhor modo possível.
- Não há cobrança pelo uso desse recurso.
- Não há suporte para recuperação de desastre geográfico para namespaces e tópicos de parceiro.