Replicação geográfica (Visualização Pública)
Há dois recursos que fornecem recuperação de desastres geográficos nos Hubs de Eventos do Azure.
- Recuperação de Desastre Geográfico (DR de metadados), que fornece apenas a replicação de apenas metadados.
- Replicação geográfica (visualização pública), que fornece a replicação de metadados e dados.
Esses recursos não devem ser confundidos com as zonas de disponibilidade. Os recursos de recuperação geográfica fornecem resiliência entre regiões do Azure, como Leste dos EUA e Oeste dos EUA. O suporte à zona de disponibilidade oferece resiliência dentro de uma região geográfica específica, como Leste dos EUA. Para obter mais informações sobre as Zonas de Disponibilidade, consulte Suporte à Zona de Disponibilidade dos Hubs de Eventos.
Importante
- Esse recurso está atualmente em visualização pública e não deve ser usado em cenários de produção.
- No momento, há suporte para as seguintes regiões na visualização pública.
| EUA | Europa | APAC |
|---|---|---|
| EUA Central EUAP | Norte da Itália | Austrália Central |
| Canadá Central | Espanha Central | Leste da Austrália |
| Leste do Canadá | Leste da Noruega |
Recuperação de desastres de metadados vs. Replicação geográfica de metadados e dados
O recurso de DR de metadados replica as informações de configuração de um namespace de um namespace primário para um namespace secundário. Ele dá suporte apenas a um failover único para a região secundária. Durante o failover iniciado pelo cliente, o nome do alias para o namespace é redirecionado para o namespace e, em seguida, o emparelhamento é interrompido. Nenhum dado é replicado além das informações de configuração, nem as atribuições de permissão são replicadas.
O recurso mais recente de replicação geográfica replica as informações de configuração e todos os dados de um namespace primário para um ou mais namespaces secundários. Quando um failover é executado, a região secundária selecionada se torna a região primária e a região primária anterior se torna uma região secundária. Quando desejado, os usuários podem executar um failover de volta para a região primária original.
O restante deste artigo se concentra no recurso de replicação geográfica. Para obter detalhes sobre o recurso de DR de metadados, consulte Hubs de Eventos da Recuperação de Desastre Geográfico para metadados.
Replicação geográfica
A visualização pública do recurso de replicação geográfica é compatível com namespaces em clusters dedicados de dimensionamento de autoatendimento dos Hubs de Eventos. Você pode usar o recurso com namespaces novos ou existentes em clusters de autoatendimento dedicados. Não há suporte para os seguintes recursos com replicação geográfica:
- Chaves gerenciadas pelo cliente (CMK)
- Identidade gerenciada para captura
- Recursos de rede virtual (pontos de extremidade de serviço ou pontos de extremidade privados)
- Suporte a mensagens grandes (agora em visualização pública)
- Transações do Kafka (agora em visualização pública)
Alguns dos principais aspectos da visualização pública da replicação de dados geográficos são:
- Modelo de replicação primário-secundário: A replicação geográfica é construída no modelo de replicação primário-secundário, no qual, em um determinado momento, há apenas um namespace primário que atende os produtores e consumidores de eventos.
- Os Hubs de Eventos executam a replicação byte a byte totalmente gerenciada de metadados, dados de eventos e deslocamento do consumidor entre os secundários com os níveis de consistência configurados.
- Nome de domínio totalmente qualificado (FQDN) do namespace estável - O FQDN não precisa ser alterado quando a promoção é realizada.
- Consistência de replicação – Há duas configurações de consistência de replicação, síncrona e assíncrona.
- Promoção gerenciada pelo usuário de uma região secundária para ser a nova região primária.
A alteração de uma região secundária para ser uma nova região primária é feita de duas maneiras:
- Planejado: uma promoção da secundária para a primária em que o tráfego não é processado até que a nova primária recupere todos os dados mantidos pela instância primária anterior.
- Forçado: como um failover em que o secundário se torna primário o mais rápido possível. O recurso de replicação geográfica replica todos os dados e metadados da região primária para as regiões secundárias selecionadas. O FQDN do namespace sempre aponta para a região primária.
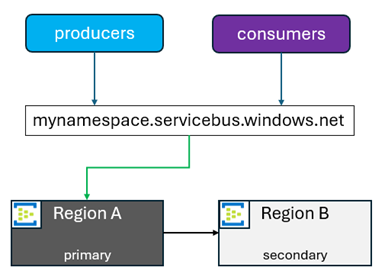
Quando você inicia a promoção de um secundário, o FQDN aponta para a região selecionada para ser o novo primário. A região primária antiga se torna uma região secundária. Você pode promover sua região secundária para ser a nova primária por outros motivos diferentes de um failover. Esses motivos podem incluir atualizações de aplicativos, testes de failover ou várias outras coisas. Nessas situações, é comum reverter a promoção quando essas atividades são concluídas.
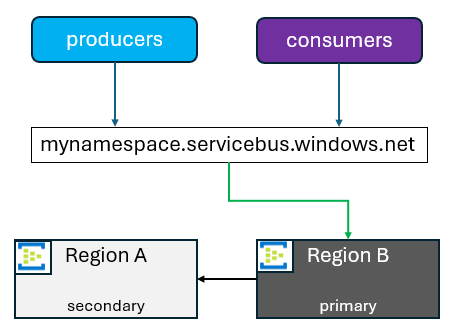
Regiões secundárias são adicionadas ou removidas a critério do cliente. Atualmente, há algumas limitações que devem ser ressaltadas:
- Não há capacidade de dar suporte a exibições somente leitura em regiões secundárias.
- Não há nenhuma funcionalidade de promoção/failover automático. Todas as promoções são iniciadas pelo cliente.
- As regiões secundárias devem ser diferentes da região primária. Não é possível selecionar outro cluster dedicado na mesma região.
- Há suporte a apenas uma região secundária para visualização pública.
Consistência de replicação
Há duas configurações de consistência de replicação, síncrona e assíncrona. É importante saber as diferenças entre as duas configurações, pois elas têm um impacto sobre seus aplicativos e sua consistência de dados.
Replicação assíncrona
Com a replicação assíncrona habilitada, todas as mensagens são confirmadas na região primária e enviadas para a região secundária. Os usuários podem configurar um tempo de retardo aceitável que a região secundária precisa alcançar. Quando o retardo para uma região secundária ativa é maior do que a configuração de retardo do usuário, a região primária limita as solicitações de publicação de entrada.
Replicação síncrona
Quando a replicação síncrona é habilitada, os eventos publicados são replicados para a região secundária, que deve confirmar a mensagem antes de sua confirmação na região primária. Com a replicação síncrona, seu aplicativo publica na taxa necessária para publicar, replicar, reconhecer e confirmar. Isso também significa que seu aplicativo está vinculado à disponibilidade de ambas as regiões. Se a região secundária falhar, as mensagens não poderão ser reconhecidas ou confirmadas.
Comparação de consistência de replicação
Com a replicação síncrona:
- A latência é maior devido à confirmação distribuída.
- A disponibilidade está vinculada à disponibilidade de duas regiões. Se uma região falhar, o namespace não estará disponível.
- Os dados recebidos sempre residem em pelo menos duas regiões (apenas duas regiões com suporte na visualização pública inicial).
A replicação síncrona fornece a maior garantia de que seus dados estão seguros. Se você tiver replicação síncrona, quando ela for confirmada, ela será confirmada em todas as regiões configuradas para replicação geográfica. No entanto, quando a replicação síncrona é habilitada, a disponibilidade do aplicativo pode ser reduzida devido à disponibilidade de ambas as regiões.
Habilitar a replicação assíncrona não afeta muito a latência e a disponibilidade do serviço não é afetada pela perda de uma região secundária. Diferentemente da replicação síncrona, a replicação assíncrona não tem a garantia absoluta de que todas as regiões têm os dados antes da confirmação. Você também pode definir por quanto tempo a região secundária pode ficar fora de sincronia antes que o tráfego de entrada seja limitado. A configuração pode ser de 5 minutos a 1.440 minutos, que corresponde a um dia. Se você pretende usar regiões com uma grande distância entre elas, a replicação assíncrona provavelmente é a melhor opção para você.
A configuração de consistência de replicação pode ser alterada após a configuração de replicação geográfica. Você pode ir da replicação síncrona para assíncrona ou da replicação assíncrona para síncrona. Se você for da replicação síncrona para assíncrona, sua latência e disponibilidade do aplicativo melhorarão. Se você for da replicação assíncrona para síncrona, sua região secundária será configurada como síncrona depois que o retardo atingir zero. Se você estiver executando com um atraso contínuo por qualquer motivo, pode ser necessário pausar seus publicadores para que o atraso chegue a zero e seu modo possa ser alterado para síncrono.
Os motivos gerais para habilitar a replicação síncrona estão vinculado à importância dos dados, às necessidades de negócios específicas ou à conformidade. Se sua meta principal for a disponibilidade do aplicativo em vez da garantia de dados, a consistência assíncrona provavelmente é a melhor opção.
Seleção de região secundária
Para habilitar o recurso de replicação geográfica, você precisa usar uma região primária e secundária em que o recurso de replicação geográfica esteja habilitado. É necessário também ter um cluster dos Hubs de Eventos já existente nas regiões primária e secundária.
O recurso de replicação geográfica depende da capacidade de replicar eventos publicados da região primária para a região secundária. Se a região secundária estiver em outro continente, isso terá um grande impacto no retardo da replicação da região primária para a região secundária. Se estiver usando a replicação geográfica para disponibilidade e confiabilidade, é melhor que as regiões secundárias estejam pelo menos no mesmo continente, sempre que possível. Para entender melhor a latência induzida pela distância geográfica, saiba mais em Estatísticas de latência de ida e volta da rede do Azure | Microsoft Learn.
Gerenciamento de replicação geográfica
O recurso de replicação geográfica permite que você configure uma região secundária para replicar a configuração e os dados. Você poderá:
- Configure a replicação geográfica: As regiões secundárias podem ser configuradas em qualquer namespace existente em um cluster dedicado de autoatendimento em uma região com o conjunto de recursos de replicação geográfica habilitado. Ela também pode ser configurada durante a criação do namespace nos mesmos clusters dedicados. Para selecionar uma região secundária, você deve ter um cluster dedicado disponível nessa região secundária e ela também deve ter o conjunto do recurso de replicação geográfica habilitado para essa região.
- Configurar a consistência da replicação: A replicação síncrona e assíncrona é definida quando a replicação geográfica é configurada, mas também pode ser alternada posteriormente. Com a consistência assíncrona, você pode configurar por quanto tempo uma região secundária pode retardar.
- Disparar promoção/failover: Todas as promoções ou failovers são iniciados pelo cliente. Durante a promoção, você pode optar por torná-la forçada desde o início ou até mesmo mudar de ideia depois que uma promoção for iniciada e torná-la forçada.
- Remover um secundário: Se, a qualquer momento, você quiser remover o emparelhamento geográfico entre as regiões primária e secundária, poderá fazê-lo e os dados da região secundária serão excluídos.
Monitorando a replicação de dados
Os usuários podem monitorar o progresso do trabalho de replicação monitorando a métrica de retardo de replicação nos logs de Métricas do Aplicativo.
Habilitar logs de Métricas do Aplicativo no namespace dos Hubs de Eventos seguindo Monitoramento dos Hubs de Eventos – Hubs de Eventos do Azure | Microsoft Learn.
Depois que os logs de Métricas do Aplicativo estiverem habilitados, você precisará produzir e consumir dados do namespace por alguns minutos antes de começar a ver os logs.
Para exibir os logs de Métricas do Aplicativo, navegue até a seção Monitoramento da página Hubs de Eventos e selecione Logs no menu à esquerda. Você pode usar a consulta a seguir para localizar o retardo de replicação (em segundos) entre os namespaces primário e secundário.
AzureDiagnostics | where TimeGenerated > ago(1h) | where Category == "ApplicationMetricsLogs" | where ActivityName_s == "ReplicationLagA coluna
count_dindica o atraso da replicação em segundos entre a região primária e a secundária.
Publicando dados
Aplicativos de publicação de eventos podem publicar namespaces replicados geograficamente por meio de FQDN de namespace do namespace replicado geograficamente. A abordagem de publicação de eventos é a mesma que o caso de DR não geográfico e nenhuma alteração nos aplicativos cliente é necessária.
A publicação de eventos pode não estar disponível nas seguintes circunstâncias:
- Durante o período de tolerância de failover, a região primária existente rejeitará todos os novos eventos publicados no hub de eventos.
- Quando o atraso de replicação entre as regiões primária e secundária atingir a duração máxima do atraso de replicação, a carga de trabalho de entrada do publicador poderá ser limitada. Os aplicativos do publicador não podem acessar diretamente namespaces nas regiões secundárias.
Consumindo dados
Os aplicativos que consomem eventos podem consumir dados usando o FQDN do namespace estável de um namespace replicado geograficamente. Não há suporte para as operações do consumidor, desde quando o failover é iniciado até sua conclusão.
Gerenciamento de deslocamento/ponto de verificação
Os aplicativos de consumo de eventos podem continuar a manter o gerenciamento de deslocamento, pois eles o fariam com um único namespace.
Kafka
Os deslocamentos são confirmados diretamente nos Hubs de Eventos e os deslocamentos são replicados entre regiões. Portanto, os consumidores podem começar a consumir de onde pararam na região primária.
AMQP/SDK dos Hubs de Eventos do Azure
Os clientes que usam o SDK dos Hubs de Eventos precisam atualizar para a versão de abril de 2024 do SDK. A versão mais recente do SDK dos Hubs de Eventos dá suporte ao failover com uma atualização para o ponto de verificação. O ponto de verificação é gerenciado por usuários com um armazenamento de ponto de verificação, como o Armazenamento de Blobs do Azure ou uma solução de armazenamento personalizada. Se houver um failover, o armazenamento de ponto de verificação deverá estar disponível na região secundária para que os clientes possam recuperar dados de ponto de verificação e evitar a perda de mensagens.
Preços
Os clusters dedicados dos Hubs de Eventos são cobrados independentemente da replicação geográfica. O uso da replicação geográfica com Hubs de Eventos Dedicados exige que você tenha pelo menos dois clusters em regiões separadas. Os clusters dedicados usados como instâncias secundárias para replicação geográfica podem ser usados para outras cargas de trabalho. Há uma cobrança pela replicação geográfica com base na largura de banda publicada * o número de regiões secundárias. A taxa de replicação geográfica é dispensada na visualização pública antecipada.
Conteúdo relacionado
Para saber como usar o recurso de replicação geográfica, consulte Usar a replicação geográfica.