Gravar mensagens de evento no Azure Data Lake Storage Gen2 com a API de DataStream do Apache Flink®
Importante
O Azure HDInsight no AKS se aposentou em 31 de janeiro de 2025. Saiba mais com este comunicado.
Você precisa migrar suas cargas de trabalho para microsoft fabric ou um produto equivalente do Azure para evitar o encerramento abrupto de suas cargas de trabalho.
Importante
Esse recurso está atualmente em versão prévia. Os termos de uso complementares para o Microsoft Azure Previews incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, consulte Azure HDInsight em informações de visualização do AKS. Para perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para mais atualizações na Comunidade Azure HDInsight .
O Apache Flink usa sistemas de arquivos para consumir e armazenar dados persistentemente, tanto para os resultados de aplicativos quanto para tolerância e recuperação de falhas. Neste artigo, saiba como gravar mensagens de evento no Azure Data Lake Storage Gen2 com a API datastream.
Pré-requisitos
- cluster de Apache Flink no HDInsight no AKS
-
cluster do Apache Kafka no HDInsight
- Você precisa garantir que as configurações de rede sejam cuidadas conforme descrito em Usando o Apache Kafka no HDInsight. Certifique-se de que o HDInsight no AKS e os clusters HDInsight estejam na mesma Rede Virtual.
- Usar o MSI para acessar o ADLS Gen2
- IntelliJ para desenvolvimento em uma VM do Azure no HDInsight na Rede Virtual do AKS
Conector do Sistema de Arquivos do Apache Flink
Esse conector do sistema de arquivos fornece as mesmas garantias para BATCH e STREAMING e foi projetado para fornecer exatamente uma semântica única para execução de STREAMING. Para obter mais informações, consulte Flink DataStream Filesystem.
Conector do Apache Kafka
O Flink fornece um conector do Apache Kafka para ler e gravar dados em tópicos do Kafka com garantias de processamento exatamente uma vez. Para obter mais informações, consulte Apache Kafka Conector.
Criar o projeto para o Apache Flink
pom.xml no IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
programa para o coletor do ADLS Gen2
abfsGen2.java
Nota
Substitua Apache Kafka no cluster HDInsight bootStrapServers por seus próprios brokers para Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Empacote o jar e envie para o Apache Flink.
Carregue o jar no ABFS.

Passe as informações do JAR do trabalho na criação do cluster
AppMode.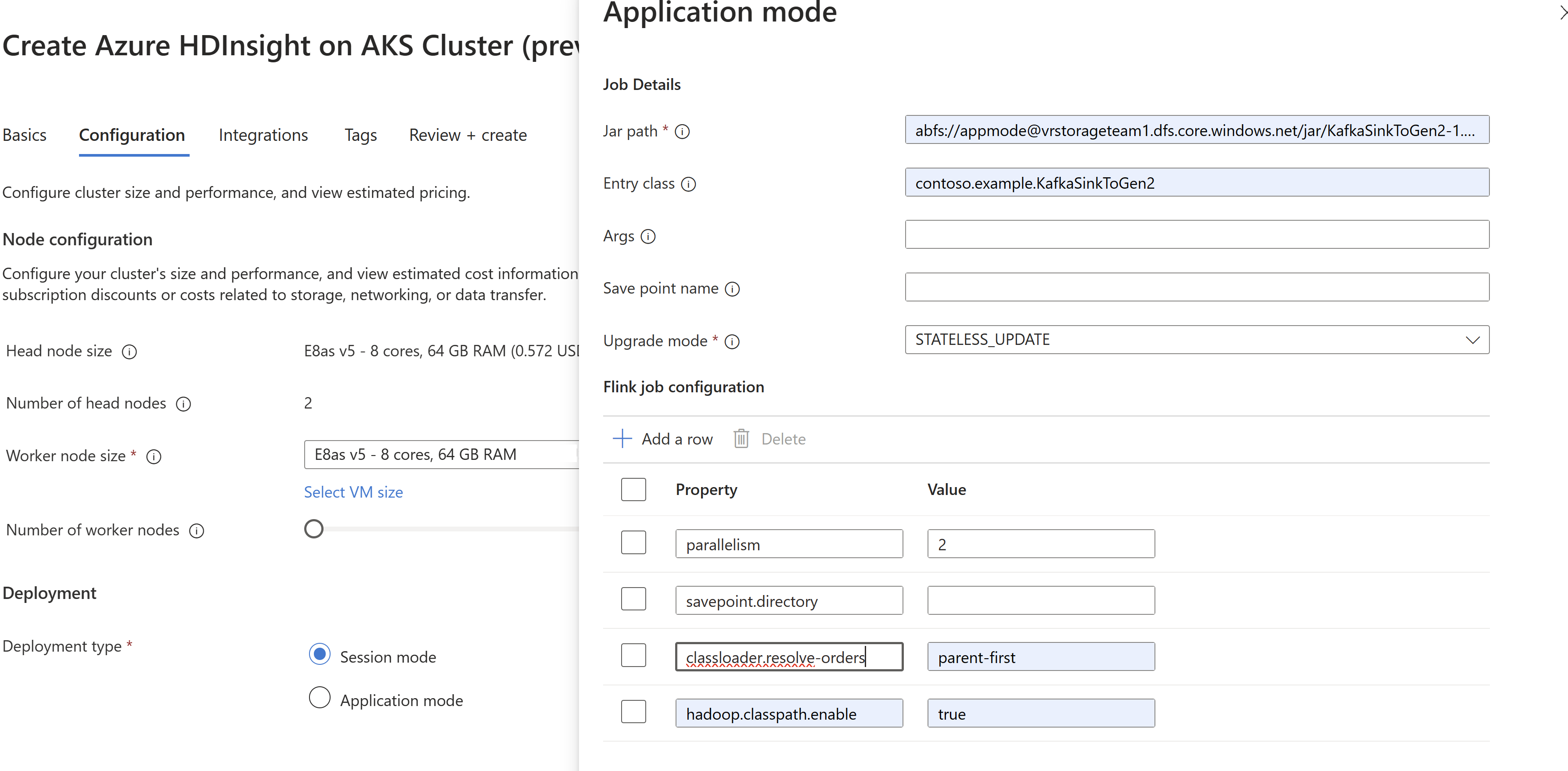
Nota
Certifique-se de adicionar classloader.resolve-order como 'parent-first' e hadoop.classpath.enable como
trueSelecione a agregação de logs de trabalho para enviar os logs para a conta de armazenamento.

Você pode ver a tarefa em execução.





Validar dados de streaming no ADLS Gen2
Estamos observando o click_events sendo transmitido para o ADLS Gen2.

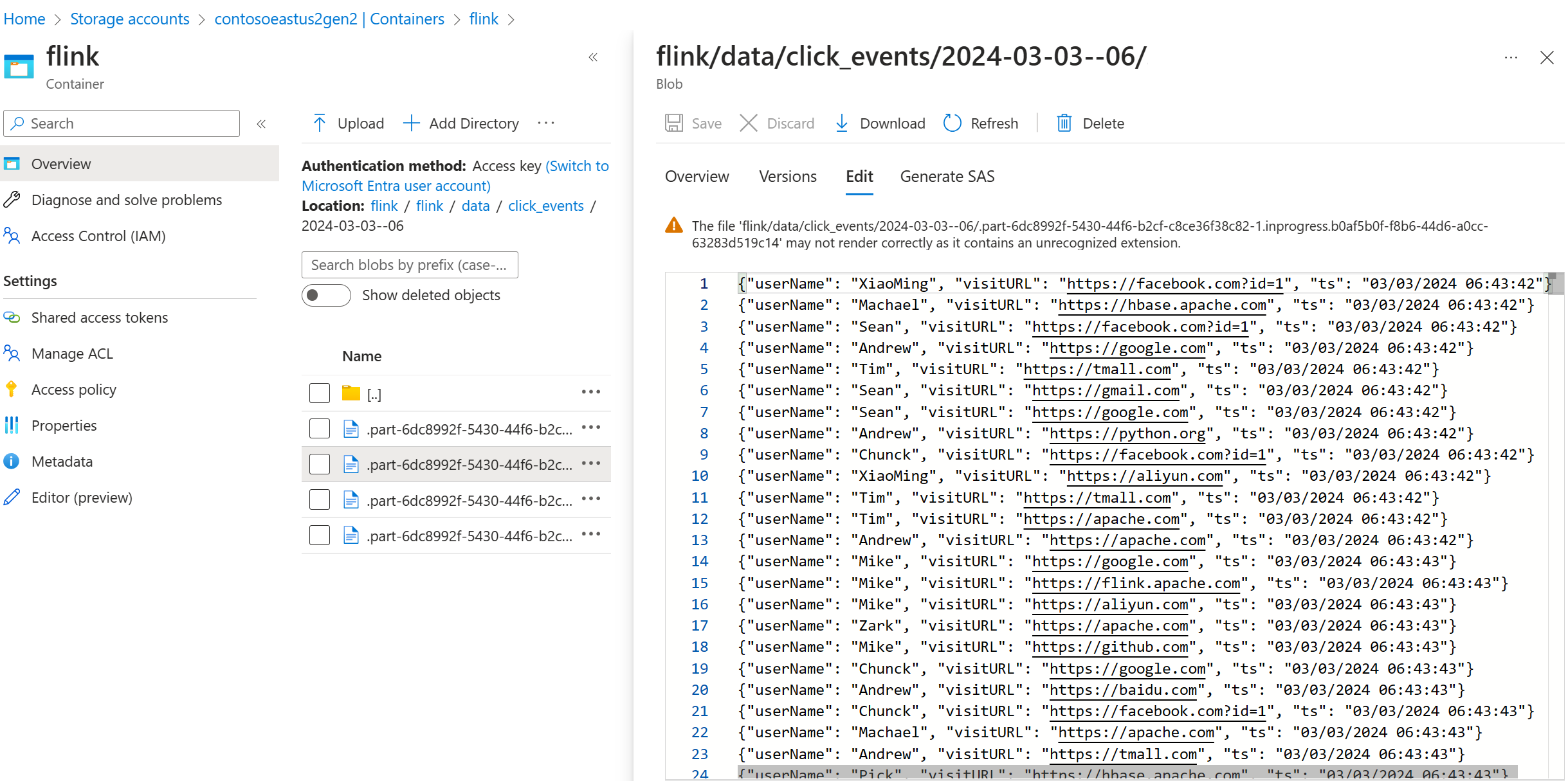
Você pode especificar uma política de rotação que gire o arquivo de parte em execução com base em qualquer uma das três condições a seguir:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Referência
- Conector do Apache Kafka
- do sistema de arquivos Flink DataStream
- site do Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink e nomes de projeto de software livre associados são marcas comerciais da Apache Software Foundation (ASF).