Use as funções definidas pelo usuário do C# com o Apache Hive e o Apache Pig no Apache Hadoop no HDInsight
Aprenda a usar as funções definidas pelo usuário (UDF) do C# com o Apache Hive e o Apache Pig no HDInsight.
Importante
As etapas deste documento funcionam em clusters HDInsight baseados em Linux. O Linux é o único sistema operacional usado no HDInsight versão 3.4 ou superior. Para obter mais informações, consulte Controle de versão do componente do HDInsight.
Tanto o Hive quanto o Pig podem passar dados para aplicativos externos para processamento. Este processo é conhecido como streaming. Ao usar um aplicativo .NET, os dados são passados para o aplicativo em STDIN e o aplicativo retornará os resultados em STDOUT. Para ler e gravar por meio de STDIN e STDOUT, use Console.ReadLine() e Console.WriteLine() de um aplicativo de console.
Pré-requisitos
Familiaridade com gravação e compilação de código em C# que se destina ao .NET Framework 4.5.
Use o IDE que preferir. Recomendamos o Visual Studio ou o Visual Studio Code. As etapas neste tutorial usam o Visual Studio 2019.
Uma forma de carregar arquivos .exe para o cluster e executar trabalhos de Pig e Hive. Recomendamos as Ferramentas do Data Lake para Visual Studio, o Azure PowerShell e a CLI do Azure. As etapas neste documento usam as Ferramentas do Data Lake para Visual Studio para carregar os arquivos e executar o exemplo de consulta do Hive.
Para obter mais informações sobre como executar consultas Hive, consulte O que é o Apache Hive e HiveQL no Azure HDInsight?.
Um Hadoop no cluster do HDInsight. Para obter mais informações sobre como criar um cluster, consulte Criar um cluster do HDInsight.
.NET no HDInsight
Clusters HDInsight baseados em Linux usam Mono (https://mono-project.com) para executar aplicativos .NET. A versão 4.2.1 do Mono está incluída no HDInsight versão 3.6.
Para obter mais informações sobre compatibilidade de Mono com versões do .NET Framework, consulte Compatibilidade de Mono.
Para obter mais informações sobre a versão do .NET Framework e do Mono incluídas no HDInsight, consulte Versões do componente do HDInsight.
Criar os projetos em C#
As seções a seguir descrevem como criar um projeto C# no Visual Studio para um Apache Hive UDF e um Apache Pig UDF.
UDF do Apache Hive
Para criar um projeto C# para um Apache Hive UDF:
Inicie o Visual Studio.
Selecione Criar um novo projeto.
Na janela Criar um novo projeto, escolha o modelo Aplicativo de Console (.NET Framework) (a versão C#). Em seguida, selecione Avançar.
Na janela Configurar seu novo projeto, insira um Nome de Projeto de HiveCSharpe navegue até ou crie um Local para salvar o novo projeto. Em seguida, selecione Criar.
Na IDE do Visual Studio, substitua o conteúdo do Program.cs pelo código a seguir:
using System; using System.Security.Cryptography; using System.Text; using System.Threading.Tasks; namespace HiveCSharp { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Parse the string, trimming line feeds // and splitting fields at tabs line = line.TrimEnd('\n'); string[] field = line.Split('\t'); string phoneLabel = field[1] + ' ' + field[2]; // Emit new data to stdout, delimited by tabs Console.WriteLine("{0}\t{1}\t{2}", field[0], phoneLabel, GetMD5Hash(phoneLabel)); } } /// <summary> /// Returns an MD5 hash for the given string /// </summary> /// <param name="input">string value</param> /// <returns>an MD5 hash</returns> static string GetMD5Hash(string input) { // Step 1, calculate MD5 hash from input MD5 md5 = System.Security.Cryptography.MD5.Create(); byte[] inputBytes = System.Text.Encoding.ASCII.GetBytes(input); byte[] hash = md5.ComputeHash(inputBytes); // Step 2, convert byte array to hex string StringBuilder sb = new StringBuilder(); for (int i = 0; i < hash.Length; i++) { sb.Append(hash[i].ToString("x2")); } return sb.ToString(); } } }Na barra de menus, selecione Compilar>Compilar solução para compilar o aplicativo.
Feche a solução.
UDF do Apache Pig
Para criar um projeto C# para um Apache Hive UDF:
Abra o Visual Studio.
Na janela Iniciar, selecione Criar projeto.
Na janela Criar um novo projeto, escolha o modelo Aplicativo de Console (.NET Framework) (a versão C#). Em seguida, selecione Avançar.
Na janela Configurar seu novo projeto, insira um Nome de Projeto de PigUDFe navegue até ou crie um Local para salvar o novo projeto. Em seguida, selecione Criar.
Na IDE do Visual Studio, substitua o conteúdo do Program.cs pelo código a seguir:
using System; namespace PigUDF { class Program { static void Main(string[] args) { string line; // Read stdin in a loop while ((line = Console.ReadLine()) != null) { // Fix formatting on lines that begin with an exception if(line.StartsWith("java.lang.Exception")) { // Trim the error info off the beginning and add a note to the end of the line line = line.Remove(0, 21) + " - java.lang.Exception"; } // Split the fields apart at tab characters string[] field = line.Split('\t'); // Put fields back together for writing Console.WriteLine(String.Join("\t",field)); } } } }Esse código analisa as linhas enviadas do Pig e reformata as linhas que começam com
java.lang.Exception.Na barra de menus, escolha Compilar>Compilar Solução para compilar o projeto.
Deixe a solução aberta.
Carregar para o armazenamento
Em seguida, carregue os aplicativos do Hive e do Pig UDF para armazenamento em um cluster HDInsight.
No Visual Studio, navegue até Exibir>Gerenciador de Servidores.
Em Gerenciador de Servidores, clique com o botão direito em Azure, selecione Conectar à Assinatura do Microsoft Azure e conclua o processo de logon.
Expanda o cluster HDInsight no qual você deseja implantar esse aplicativo. Uma entrada com o texto (Conta de armazenamento padrão) é listada.
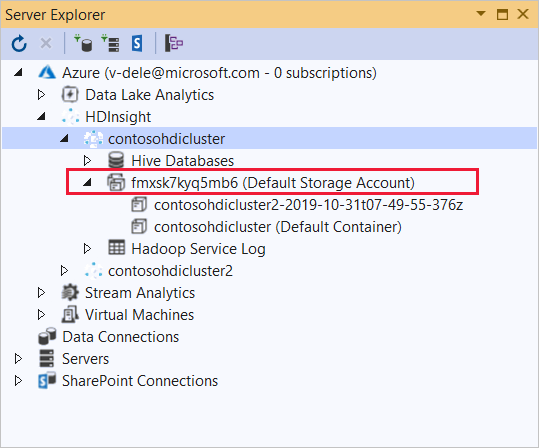
Se essa entrada puder ser expandida, você estará usando uma Conta de Armazenamento do Azure como armazenamento padrão do cluster. Para exibir os arquivos no armazenamento padrão para o cluster, expanda a entrada e clique duas vezes no (Contêiner Padrão).
Se essa entrada não puder ser expandida, você está usando o Azure Data Lake Storage como o armazenamento padrão do cluster. Para exibir os arquivos no armazenamento padrão do cluster, clique duas vezes na entrada (Conta de Armazenamento Padrão).
Para carregar os arquivos .exe, use um dos seguintes métodos:
Se você estiver usando uma Conta de Armazenamento do Azure, selecione o ícone Carregar Blob.

Na caixa de diálogo Carregar Novo Arquivo, em Nome do arquivo, selecione Procurar. Na caixa de diálogo Carregar Blob, vá para a pasta bin\debug do projeto HiveCSharp e escolha o arquivo mapper.exe. Por fim, selecione Abrir e, em seguida, OK para concluir o carregamento.
Se estiver usando o Azure Data Lake Storage, clique com o botão direito em uma área vazia na listagem de arquivos e, em seguida, selecione Carregar. Por fim, selecione o arquivo HiveCSharp.exe e clique em Abrir.
Após o HiveCSharp.exe ser carregado, repita o processo de upload para o arquivo PigUDF.exe.
Executar uma consulta do Apache Hive
Agora você pode executar uma consulta de Hive que usa o aplicativo Hive UDF.
No Visual Studio, navegue até Exibir>Gerenciador de Servidores.
Expanda Azure e expanda HDInsight.
Clique com o botão direito do mouse no cluster em que você implantou o aplicativo HiveCSharp e, em seguida, selecione Escrever uma consulta de Hive.
Use o texto a seguir para a consulta de Hive:
-- Uncomment the following if you are using Azure Storage -- add file wasbs:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen1 -- add file adl:///HiveCSharp.exe; -- Uncomment the following if you are using Azure Data Lake Storage Gen2 -- add file abfs:///HiveCSharp.exe; SELECT TRANSFORM (clientid, devicemake, devicemodel) USING 'HiveCSharp.exe' AS (clientid string, phoneLabel string, phoneHash string) FROM hivesampletable ORDER BY clientid LIMIT 50;Importante
Remova a marca de comentário da instrução
add fileque corresponde ao tipo de armazenamento padrão usado para o cluster.Esta consulta seleciona os campos
clientid,devicemakeedevicemodeldehivesampletable, e passa os campos para o aplicativo HiveCSharp.exe. A consulta espera que o aplicativo retorne três campos, que são armazenados comoclientid,phoneLabelephoneHash. A consulta também espera encontrar o HiveCSharp.exe na raiz do contêiner de armazenamento padrão.Alterne o padrão Interativo para Batche, em seguida, selecione Enviar para enviar o trabalho para o cluster HDInsight. A janela Resumo do trabalho Hive é aberta.
Selecione Atualizar para atualizar o resumo até que Status do Trabalho mude para Concluído. Para exibir o resultado do trabalho, clique em Resultado do Trabalho.
Executar um trabalho do Apache Pig
Você também pode executar um trabalho Pig que usa seu aplicativo Pig UDF.
Use o SSH para conectar-se ao cluster HDInsight. (Por exemplo, execute o comando
ssh sshuser@<clustername>-ssh.azurehdinsight.net.) Para obter mais informações, consulte Usar SSH withHDInsight.Use o comando a seguir para iniciar a linha de comando do Pig:
pigUm prompt de
grunt>é exibido.Digite o seguinte para executar um trabalho do Pig que usa o aplicativo do .NET Framework:
DEFINE streamer `PigUDF.exe` CACHE('/PigUDF.exe'); LOGS = LOAD '/example/data/sample.log' as (LINE:chararray); LOG = FILTER LOGS by LINE is not null; DETAILS = STREAM LOG through streamer as (col1, col2, col3, col4, col5); DUMP DETAILS;A
DEFINEinstrução cria um alias destreamerpara o aplicativo PigUDF.exe, eCACHEo carrega do armazenamento padrão para o cluster. Posteriormente,streameré usado com o operadorSTREAMpara processar as linhas individuais contidas emLOGe retornar os dados como uma série de colunas.Observação
O nome do aplicativo que é usado para streaming deve estar entre o caractere
`(acento grave) quando se tratar de um alias e'(aspas simples) quando usado comSHIP.Depois de inserir a última linha, o trabalho deve ser iniciado. Isso retorna saídas semelhantes ao seguinte texto:
(2019-07-15 16:43:25 SampleClass5 [WARN] problem finding id 1358451042 - java.lang.Exception) (2019-07-15 16:43:25 SampleClass5 [DEBUG] detail for id 1976092771) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1317358561) (2019-07-15 16:43:25 SampleClass5 [TRACE] verbose detail for id 1737534798) (2019-07-15 16:43:25 SampleClass7 [DEBUG] detail for id 1475865947)Use
exitpara sair do Pig.
Próximas etapas
Neste documento, você aprendeu a usar um aplicativo do .NET Framework do Hive e do Pig no HDInsight. Caso deseje saber como usar o Python com o Hive e o Pig, confira Usar o Python com o Apache Hive e o Apache Pig no HDInsight.
Para outras maneiras de usar o Pig e o Hive e para saber como usar o MapReduce, consulte os documentos a seguir: