Otimizar as consultas do Apache Hive no Azure HDInsight
Este artigo descreve algumas das otimizações de desempenho mais comuns que você pode usar para melhorar o desempenho das consultas do Apache Hive.
Seleção de tipo de cluster
No Azure HDInsight, você pode executar consultas do Apache Hive em alguns tipos de cluster diferentes.
Escolha o tipo de cluster apropriado para ajudar a otimizar o desempenho de suas necessidades de carga de trabalho:
- Escolha o tipo de cluster Consulta Interativa para otimizar para
ad hoc, consultas interativas. - Escolha o tipo de cluster Apache Hadoop para otimizar para consultas do Hive usadas como um processo em lote.
- Os tipos de cluster Spark e HBase também podem executar consultas do Hive e podem ser apropriados se você estiver executando essas cargas de trabalho.
Para saber mais sobre como executar consultas Hive em vários tipos de cluster do HDInsight, confira O que é o Apache Hive e HiveQL no Azure HDInsight?.
Escalar nós de trabalho horizontalmente
O aumento do número de nós de trabalho em um cluster HDInsight permite que o trabalho use mais mapeadores e redutores para execução paralela. Existem duas maneiras de você aumentar a redução horizontal no HDInsight:
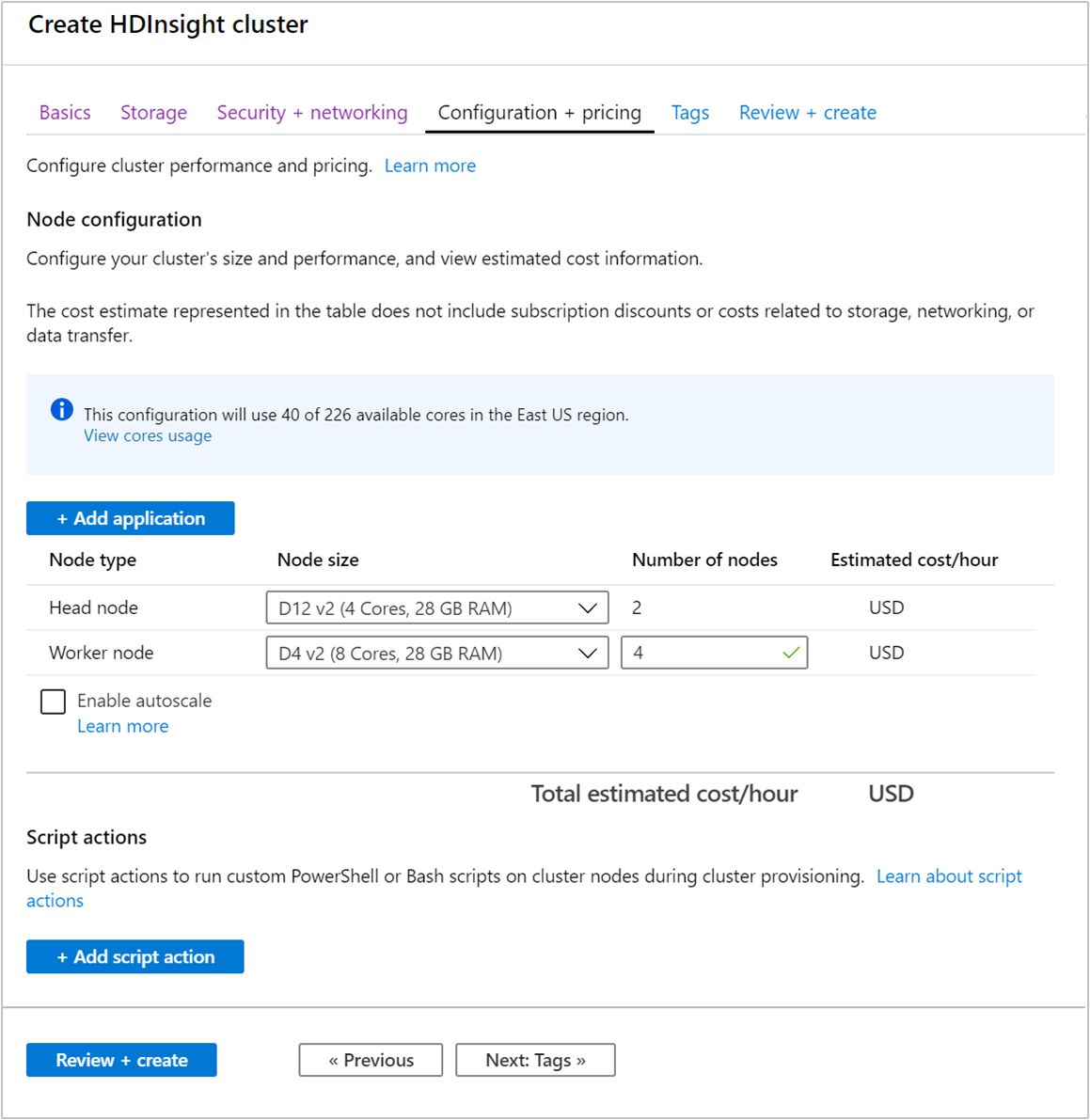
Ao criar um cluster, você pode especificar o número de nós de trabalho usando o portal do Azure, o Azure PowerShell ou a interface de linha de comando. Para saber mais, veja Criar clusters HDInsight. A seguinte captura de tela mostra a configuração de nó de trabalho no Portal do Azure:
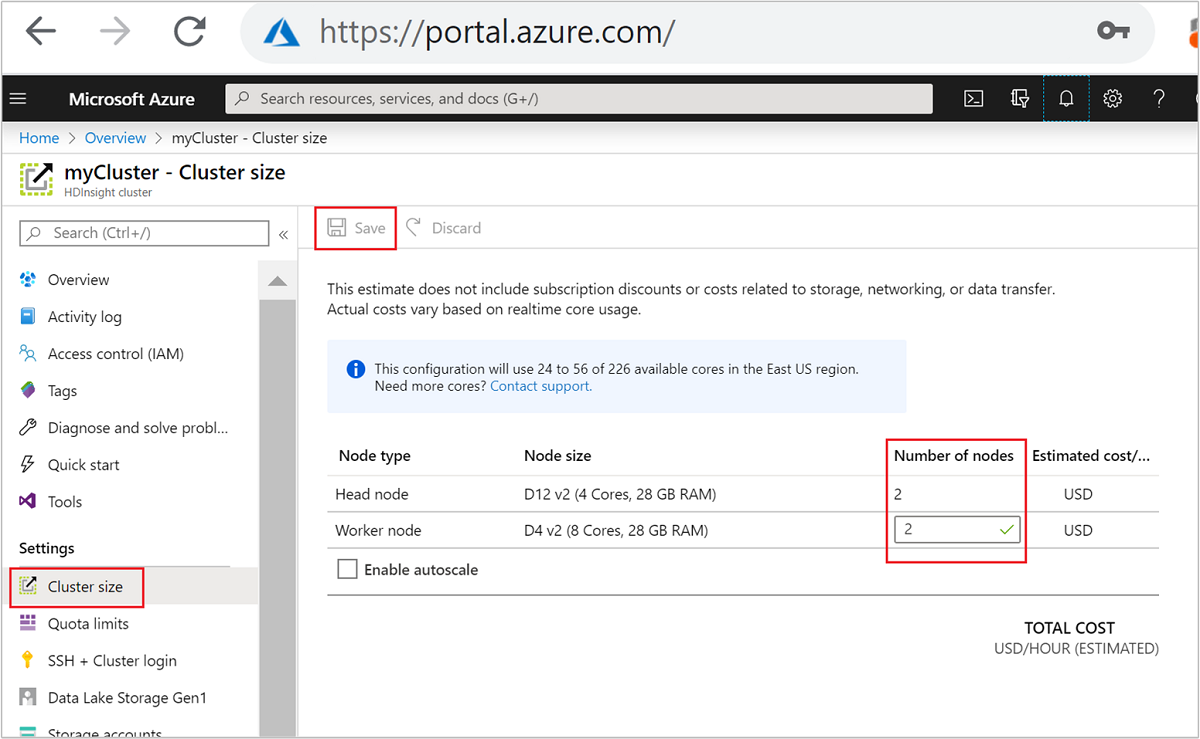
Após a criação, você também pode editar o número de nós de trabalho para escalar horizontalmente ainda mais um cluster sem recriar um:
Para saber mais sobre dimensionamento do HDInsight, consulte Dimensionar clusters HDInsight
Usar Apache Tez, em vez de MapReduce
Apache Tez é um mecanismo de execução alternativo ao mecanismo MapReduce. Clusters HDInsight baseados em Linux têm o Tez habilitado por padrão.
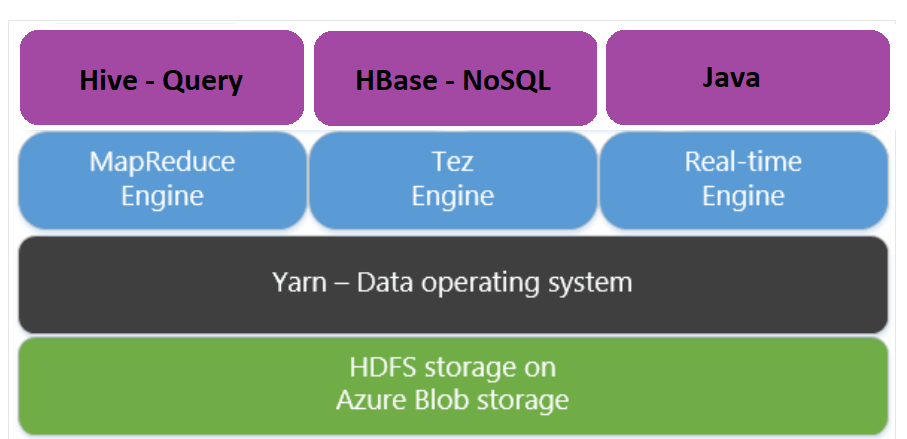
O Tez é mais rápido porque:
- Execute o DAG (grafo direcionado acíclico) como um trabalho único no mecanismo MapReduce. O DAG requer que cada conjunto de mapeadores seja seguido por um conjunto de redutores. Este requisito faz com que vários trabalhos do MapReduce sejam gerados para cada consulta do Hive. O Tez não tem essa restrição e pode processar DAG complexo como um único trabalho, minimizando a sobrecarga de inicialização do trabalho.
- Evita gravações desnecessárias. Vários trabalhos são usados para processar a mesma consulta Hive no mecanismo MapReduce. A saída de cada trabalho do MapReduce é gravada no HDFS para dados intermediários. Como o Tez minimiza o número de trabalhos para cada consulta do Hive, ele pode evitar gravações desnecessárias.
- Minimiza atrasos de inicialização. O Tez é mais capaz de minimizar o atraso de inicialização, reduzindo o número de mapeadores de que precisa para ser iniciado, além de aumentar a otimização de maneira geral.
- Reutiliza contêineres. Sempre que possível, o Tez reutiliza contêineres para garantir que a latência da inicialização dos contêineres seja reduzida.
- Técnicas de otimização contínua. Tradicionalmente, a otimização ocorria durante a fase de compilação. No entanto, há disponibilidade de mais informações sobre as entradas que permitem maior otimização durante o runtime. O Tez usa técnicas de otimização contínua que permitem otimizar ainda mais o plano mais adiante na fase de runtime.
Para obter mais informações sobre esses conceitos, consulte Apache TEZ.
Você pode fazer qualquer consulta do Hive habilitada pelo Tez prefixando a consulta com o seguinte conjunto de comandos:
set hive.execution.engine=tez;
Particionamento do Hive
As operações de E/S são o principal gargalo de desempenho para executar consultas do Hive. O desempenho pode ser melhorado se a quantidade de dados que precisam ser lidos puder ser reduzida. Por padrão, consultas do Hive examinam tabelas inteiras do Hive. Porém, para consultas que só precisam verificar uma pequena quantidade de dados (por exemplo, consultas com filtragem), esse comportamento cria uma sobrecarga desnecessária. O particionamento do Hive permite que as consultas do Hive acessem somente a quantidade necessária de dados nas tabelas do Hive.
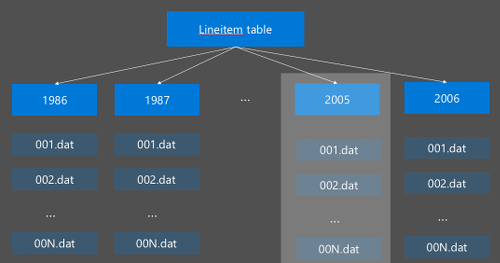
O particionamento do Hive é implementado pela reorganização dos dados brutos em novos diretórios. Cada partição tem seu próprio diretório de arquivos. O usuário define a partição. O diagrama a seguir ilustra o particionamento de uma tabela do Hive pela coluna Ano. Um novo diretório é criado para cada ano.
Algumas considerações sobre particionamento:
- Não subparticione – o particionamento em colunas com poucos valores pode causar poucas partições. Por exemplo, o particionamento por gênero só cria duas partições (masculino e feminino), portanto, reduz a latência no máximo pela metade.
- Não particione em excesso – no outro extremo, criar uma partição em uma coluna com um valor exclusivo (por exemplo, userid) causa várias partições. Partição demais causa muita carga sobre namenode do cluster porque ele precisa manipular o grande número de diretórios.
- Evite distorção de dados -Escolha com bom senso sua chave de particionamento para que todas as partições tenham o mesmo tamanho. Por exemplo, o particionamento na coluna Estado pode afetar a distribuição de dados. Como o estado da Califórnia tem uma população quase 30 vezes maior que a de Vermont, o tamanho da partição é potencialmente distorcido e o desempenho pode variar muito.
Para criar uma tabela de partição, use a cláusula Particionado por :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Depois de criar a tabela particionada, você pode criar particionamento estático ou dinâmico.
Particionamento estático significa que você já fragmentou os dados nos diretórios apropriados. Com partições estáticas, você adiciona partições Hive manualmente com base no local do diretório. O snippet de código a seguir é um exemplo.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Particionamento dinâmico significa que você deseja que o Hive crie partições automaticamente para você. Como você já criou a tabela de partição a partir da tabela de preparo, só precisa inserir dados na tabela particionada:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Para obter mais informações, consulte Partitioned Tables (Tabelas particionadas).
Use o formato ORCFile
O Hive dá suporte a vários formatos de arquivo. Por exemplo:
- Texto: é o formato de arquivo padrão e funciona com a maioria dos cenários.
- Avro: funciona bem para cenários de interoperabilidade.
- ORC/Parquet: mais adequado para desempenho.
O formato ORC é uma maneira altamente eficiente para armazenar dados do Hive. Comparado a outros formatos, o ORC tem as seguintes vantagens:
- suporte para tipos complexos, incluindo a data e hora e tipos complexos e semiestruturados.
- até 70% de compactação.
- indexa a cada 10.000 linhas, o que permite ignorar linhas de índices.
- uma redução significativa no tempo de execução.
Para habilitar o formato ORC, primeiro você deve criar uma tabela com a cláusula Armazenado como ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Em seguida, insira dados na tabela ORC a partir da tabela de preparo. Por exemplo:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Você pode ler mais sobre o formato ORC no manual da linguagem Apache Hive.
Vetorização
A vetorização permite que o Hive processe um lote de 1.024 linhas juntas em vez de processar uma linha por vez. Isso significa que operações simples são concluídas mais rapidamente porque menos código interno precisa ser executado.
Para habilitar a vetorização, prefixe sua consulta do Hive com a seguinte configuração:
set hive.vectorized.execution.enabled = true;
Para obter mais informações, consulte Execução de consultas vetorizadas.
Outros métodos de otimização
Há mais métodos de otimização que você pode considerar, por exemplo:
- Bucketing do Hive: uma técnica que permite clusterizar ou segmentar grandes conjuntos de dados para otimizar o desempenho da consulta.
- Otimização de junção: otimização do planejamento da execução de consultas do Hive para melhorar a eficiência de junções e reduzir a necessidade de dicas de usuário. Para obter mais informações, consulte Otimização de junção.
- Aumentar redutores.
Próximas etapas
Neste artigo, você aprendeu a vários métodos comuns de otimização de consultas do Hive. Confira os seguintes artigos para saber mais: