Serviços de alta disponibilidade com suporte do Azure HDInsight
Para fornecer a você os níveis ideais de disponibilidade para seus componentes de análise, o HDInsight foi desenvolvido com uma arquitetura exclusiva para garantir a alta disponibilidade (HA) de serviços críticos. A Microsoft desenvolveu alguns componentes dessa arquitetura para fornecer failover automático. Outros componentes são componentes padrão do Apache que são implantados para dar suporte a serviços específicos. Este artigo explica a arquitetura do modelo de serviço de HA no HDInsight, como o HDInsight dá suporte ao failover de serviços de HA e as práticas recomendadas para se recuperar de outras interrupções de serviço.
Observação
Este artigo contém referências ao termo servidor subordinado, um termo que a Microsoft não usa mais. Quando o termo for removido do software, também o removeremos deste artigo.
Infraestrutura de alta disponibilidade
O HDInsight fornece uma infraestrutura personalizada para garantir que quatro serviços principais sejam de alta disponibilidade com recursos de failover automático:
- Servidor Apache Ambari
- Linha do Tempo do Aplicativo Server para Apache YARN
- Servidor de histórico de trabalho para o MapReduce do Hadoop
- Apache Livy
Essa infraestrutura consiste em muitos serviços e componentes de software, alguns dos quais são projetados pela Microsoft. Os seguintes componentes são exclusivos da plataforma HDInsight:
- Controlador do failover subordinado
- Controlador do failover mestre
- Serviço subordinado de alta disponibilidade
- Serviço de mestre de alta disponibilidade
Também há outros serviços de alta disponibilidade, que têm suporte de componentes de confiabilidade do Apache de código aberto. Esses componentes também estão presentes em clusters do HDInsight:
- NameNode do Hadoop File System (HDFS)
- YARN ResourceManager
- HBase Master
As seções a seguir trarão mais detalhes de como esses serviços funcionam juntos.
Serviços de alta disponibilidade do HDInsight
A Microsoft oferece suporte para os quatro serviços Apache na tabela a seguir em clusters do HDInsight. Para diferenciá-los dos serviços de alta disponibilidade com suporte dos componentes do Apache, eles são chamados de serviços de HA do HDInsight.
| Serviço | Nós de cluster | Tipos de cluster | Finalidade |
|---|---|---|---|
| Servidor Apache Ambari | Cabeçalho ativo | Tudo | Monitora e gerencia o cluster. |
| Linha do tempo do aplicativo Server para Apache YARN | Cabeçalho ativo | Todos, exceto Kafka | Mantém informações de depuração sobre trabalhos do YARN em execução no cluster. |
| Servidor de histórico de trabalho para o MapReduce do Hadoop | Cabeçalho ativo | Todos, exceto Kafka | Mantém dados de depuração para trabalhos do MapReduce. |
| Apache Livy | Cabeçalho ativo | Spark | Permite uma interação fácil com um cluster Spark em uma interface REST |
Observação
Os clusters do Enterprise Security Package (ESP) do HDInsight fornecem atualmente apenas a alta disponibilidade do servidor Ambari. Linha do tempo do aplicativo Server, servidor de histórico de trabalho e Livy estão todos em execução apenas no headnode0 e não fazem failover para o headnode1 quando ocorre o failover do Ambari. O banco de dados da linha do tempo do aplicativo também está em headnode0 e não no Ambari SQL Server.
Arquitetura
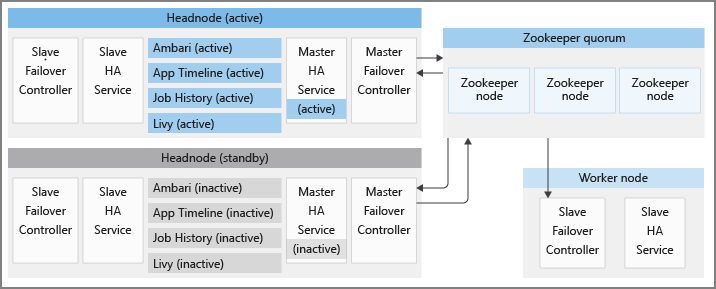
Cada cluster do HDInsight tem dois cabeçalhos nos modos ativo e em espera, respectivamente. Os serviços de alta disponibilidade do HDInsight são executados somente em cabeçalhos. Esses serviços devem estar sempre em execução no cabeçalho ativo e interrompidos e colocados no modo de manutenção no cabeçalho em espera.
Para manter os status corretos dos serviços de HA e fornecer um failover rápido, o HDInsight utiliza o Apache ZooKeeper, que é um serviço de coordenação para aplicativos distribuídos, para realizar a eleição do cabeçalho ativo. O HDInsight também provisiona alguns processos Java em segundo plano, que coordenam o procedimento de failover para os serviços de HA do HDInsight. Esses serviços são: o controlador de failover mestre, o controlador de failover escravo, o master-ha-servicee o slave-ha-service.
Apache ZooKeeper
Apache ZooKeeper é um serviço de coordenação de alto desempenho para aplicativos distribuídos. Em produção, o ZooKeeper geralmente é executado no modo replicado, em que um grupo replicado de servidores ZooKeeper formam um quorum. Cada cluster do HDInsight tem três nós do ZooKeeper que permitem que três servidores ZooKeeper formem um quorum. O HDInsight tem dois quorums ZooKeeper executados em paralelo uns com os outros. Um quorum decide o cabeçalho ativo em um cluster no qual os serviços de HA do HDInsight devem ser executados. Outro quorum é usado para coordenar os serviços de alta disponibilidade fornecidos pelo Apache, conforme detalhado nas seções posteriores.
Controlador do failover subordinado
O controlador de failover do servidor subordinado é executado em cada nó em um cluster do HDInsight. Esse controlador é responsável por iniciar o agente Ambari e o slave-ha-service em cada nó. Ele consulta periodicamente o primeiro quorum ZooKeeper sobre o cabeçalho ativo. Quando os cabeçalhos ativos e em espera são alterados, o controlador de failover escravo executa o seguinte:
- Atualiza o arquivo de configuração do host.
- Reinicia o agente do Ambari.
O slave-ha-service é responsável por parar os serviços de HA do HDInsight (exceto o servidor Ambari) no cabeçalho em espera.
Controlador do failover mestre
Um controlador de failover mestre é executado em ambos os cabeçalhos. Ambos os controladores de failover mestre se comunicam com o primeiro quorum do ZooKeeper para indicar o cabeçalho que estão executando como o cabeçalho ativo.
Por exemplo, se o controlador de failover mestre no cabeçalho 0 vence a eleição, as seguintes alterações ocorrem:
- O Cabeçalho 0 se torna ativo.
- O controlador de failover mestre inicia o servidor Ambari e o master-ha-service no cabeçalho 0.
- O outro controlador de failover mestre interrompe o servidor Ambari e o master-ha-service no cabeçalho 1.
O master-ha-service é executado somente no cabeçalho ativo, ele interrompe os serviços de HA do HDInsight (exceto o servidor Ambari) no cabeçalho em espera e os inicia no cabeçalho ativo.
O processo de failover
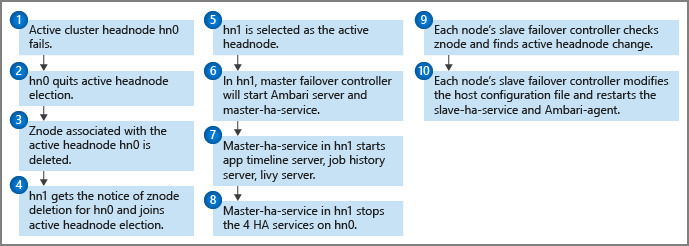
Um monitor de integridade é executado em cada cabeçalho junto com o controlador de failover mestre para enviar notificações de pulsação para o quorum do Zookeeper. O cabeçalho é considerado um serviço de HA nesse cenário. O monitor de integridade verifica se cada serviço de alta disponibilidade está íntegro e se está pronto para ingressar na eleição de liderança. Em caso afirmativo, esse cabeçalho competirá na eleição. Caso contrário, ele encerrará a eleição até que ela fique pronta novamente.
Se o cabeçalho em espera atingir a liderança e se tornar ativo (como no caso de uma falha com o nó ativo anterior), seu controlador de failover mestre iniciará todos os serviços de HA do Azure HDInsight nele. O controlador de failover mestre também parará esses serviços no outro cabeçalho.
Para falhas do serviço de HA do HDInsight, como um serviço inoperante ou não íntegro, o controlador de failover mestre deve reiniciar automaticamente ou parar os serviços de acordo com o status de cabeçalho. Os usuários não devem iniciar manualmente os serviços de HA do HDInsight em ambos os nós do cabeçalho. Em vez disso, permita o failover automático ou manual para ajudar a recuperar o serviço.
Intervenção manual inadvertida
Os serviços de HA do Azure HDInsight só devem ser executados no cabeçalho ativo e serão reiniciados automaticamente quando necessário. Como os serviços de HA individuais não têm seu próprio monitor de integridade, o failover não pode ser disparado no nível do serviço individual. O failover é garantido no nível do nó e não no nível de serviço.
Alguns problemas conhecidos
Ao iniciar manualmente um serviço de HA no cabeçalho em espera, ele não será interrompido até que o próximo failover ocorra. Quando os serviços de HA são executados em ambos os cabeçalhos, alguns possíveis problemas incluem: a interface do usuário do Ambari fica inacessível, o Ambari gera erros, YARN, Spark e trabalhos de Oozie podem travar.
Quando um serviço de HA no cabeçalho ativo para de funcionar, ele não é reiniciado até que o próximo failover ocorra ou o controlador de failover mestre/master-ha-service seja reiniciado. Quando um ou mais serviços de HA param no cabeçalho ativo, especialmente quando o servidor Ambari é interrompido, a interface do usuário do Ambari é inacessível, outros problemas possíveis incluem falhas de trabalhos YARN, Spark e Oozie.
Serviços de alta disponibilidade do Apache
O Apache fornece alta disponibilidade para NameNode do HDFS, YARN ResourceManager e HBase Master, que também estão disponíveis nos clusters do HDInsight. Ao contrário dos serviços de HA do HDInsight, eles têm suporte em clusters ESP. Os serviços de HA do Apache se comunicam com o segundo quorum do ZooKeeper (descrito na seção acima) para eleger os status ativo/em espera e conduzir o failover automático. As seções a seguir detalham como esses serviços funcionam.
NameNode do Hadoop Distributed File System (HDFS)
Os clusters do HDInsight localizados no Apache Hadoop 2.0 ou superior fornecem alta disponibilidade de NameNode. Há dois NameNodes em execução no cabeçalho, que são configurados para failover automático. Os NameNodes usam o ZKFailoverController para se comunicar com o Zookeeper para eleger o status ativo/em espera. O ZKFailoverController é executado em ambos os cabeçalhos e funciona da mesma maneira que o controlador de failover mestre acima.
O segundo quorum do Zookeeper é independente do primeiro quorum, portanto, o Active NameNode pode não ser executado no cabeçalho ativo. Quando o NameNode ativo está inativo ou não íntegro, o NameNode em espera ganha a eleição e se torna ativo.
YARN ResourceManager
Os clusters HDInsight com base no Apache Hadoop 2.4 ou superior oferecem suporte à alta disponibilidade do ResourceManager YARN. Há dois ResourceManagers, rm1 e rm2, em execução no cabeçalho 0 e no cabeçalho 1, respectivamente. Como o NameNode, o ResourceManager YARN também é configurado para failover automático. Outro ResourceManager é automaticamente optado por estar ativo quando o ResourceManager ativo atual fica inativo ou sem resposta.
O ResourceManager YARN usa seu ActiveStandbyElector incorporado como um detector de falha e eleitor de líder. Diferente do NameNod do HDFS, o ResourceManager YARN não precisa de um daemon ZKFC separado. O ResourceManager ativo grava seus status no Apache Zookeeper.
A alta disponibilidade do ResourceManager YARN é independente do NameNode e de outros serviços de HA do HDInsight. O ResourceManager ativo pode não ser executado no cabeçalho ativo ou no cabeçalho em que o NameNode ativo está em execução. Para mais informações sobre a alta disponibilidade do ResourceManager do YARN, consulte alta disponibilidade do ResourceManager.
HBase Master
Os clusters do HBase do HDInsight dão suporte à alta disponibilidade do HBase Master. Ao contrário de outros serviços de alta disponibilidade, que são executados em cabeçalho, o HBase Masters é executado nos três nós do Zookeeper, em que um deles é o mestre ativo e os outros dois ficam em espera. Como o NameNode, o HBase Master coordena com o Apache Zookeeper a eleição do líder e realiza o failover automático quando o mestre ativo atual apresenta problemas. Há apenas um HBase Master ativo a qualquer momento.