Usar armazenamentos de metadados externos no Azure HDInsight
Importante
O metastore padrão fornece uma camada básica Banco de Dados SQL do Azure com apenas 5 DTU e 2 GB de tamanho máximo de dados (NÃO ATUALIZÁVEL). Use esta garantia de qualidade somente para fins de qa e teste. Para cargas de trabalho grandes ou de produção, é recomendável migrar para um metastore externo.
O HDInsight permite que você assuma o controle de seus dados e metadados com armazenamentos de dados externos. Esse recurso está disponível para o metastore do Apache Hive, o metastore do Apache Oozie e o banco de dados do Apache Ambari.
O metastore Apache Hive no HDInsight é uma parte essencial da arquitetura do Apache Hadoop. Um metastore é o repositório de esquema central. O metastore pode ser usado por outras ferramentas de acesso de Big Data, como Apache Spark, Interactive Query (LLAP), Presto ou Apache Pig. O HDInsight usa um Banco de Dados SQL do Azure como metastore do Hive.
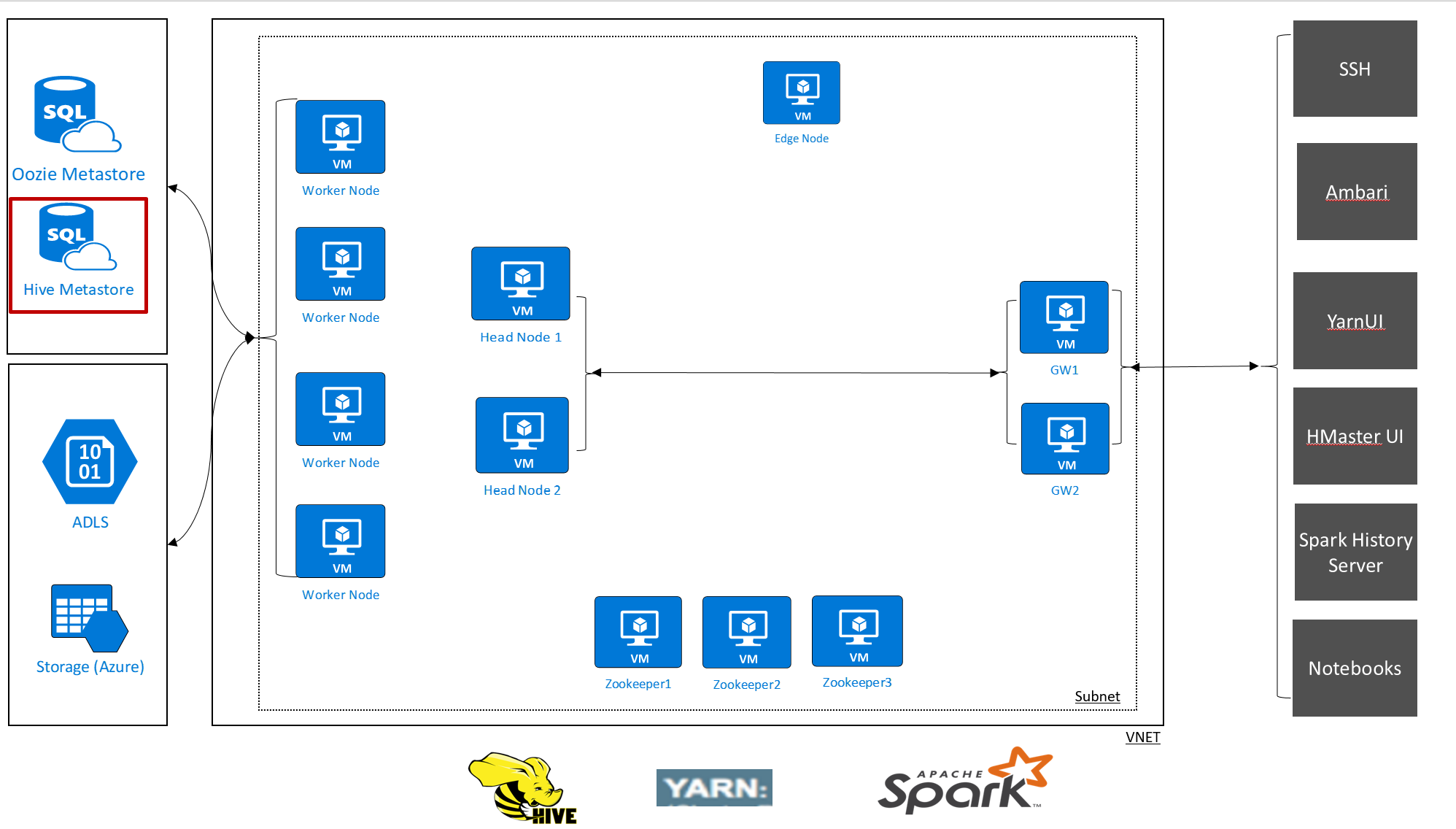
Há duas maneiras de configurar um metastore para seus clusters HDInsight:
Metastore padrão
Por padrão, o HDInsight cria um metastore com cada tipo de cluster. Em vez disso, você pode especificar um metastore personalizado. O metastore padrão inclui as seguintes considerações:
Recursos limitados. Confira o aviso na parte superior da página.
Sem custo adicional. O HDInsight cria um metastore com cada tipo de cluster sem nenhum custo adicional para você.
O metastore padrão faz parte do ciclo de vida do cluster. Quando você exclui um cluster, o metastore e os metadados correspondentes também são excluídos.
O metastore padrão só é recomendado para cargas de trabalho simples. Cargas de trabalho que não exigem vários clusters e não precisam de metadados preservados além do ciclo de vida do cluster.
O metastore padrão não pode ser compartilhado com outros clusters.
Metastore personalizado
O HDInsight também dá suporte a metastores personalizados, que são recomendados para clusters de produção:
Você pode especificar seu próprio Banco de Dados SQL do Azure com o metastore.
O ciclo de vida do metastore não está associado a um ciclo de vida de clusters e, portanto, é possível criar e excluir clusters sem perder metadados. Os metadados, como os esquemas Hive, serão mantidos até mesmo depois de você excluir e recriar o cluster HDInsight.
Um metastore personalizado permite que você anexe vários clusters e tipos de cluster ao metastore. Por exemplo, um único metastore pode ser compartilhado em clusters Interactive Query, Hive e Spark no HDInsight.
Você paga o custo de um metastore (Banco de Dados SQL do Azure) de acordo com o nível de desempenho escolhido.
Você pode expandir o metastore conforme a necessidade.
O cluster e o metastore externo devem estar hospedados na mesma região.
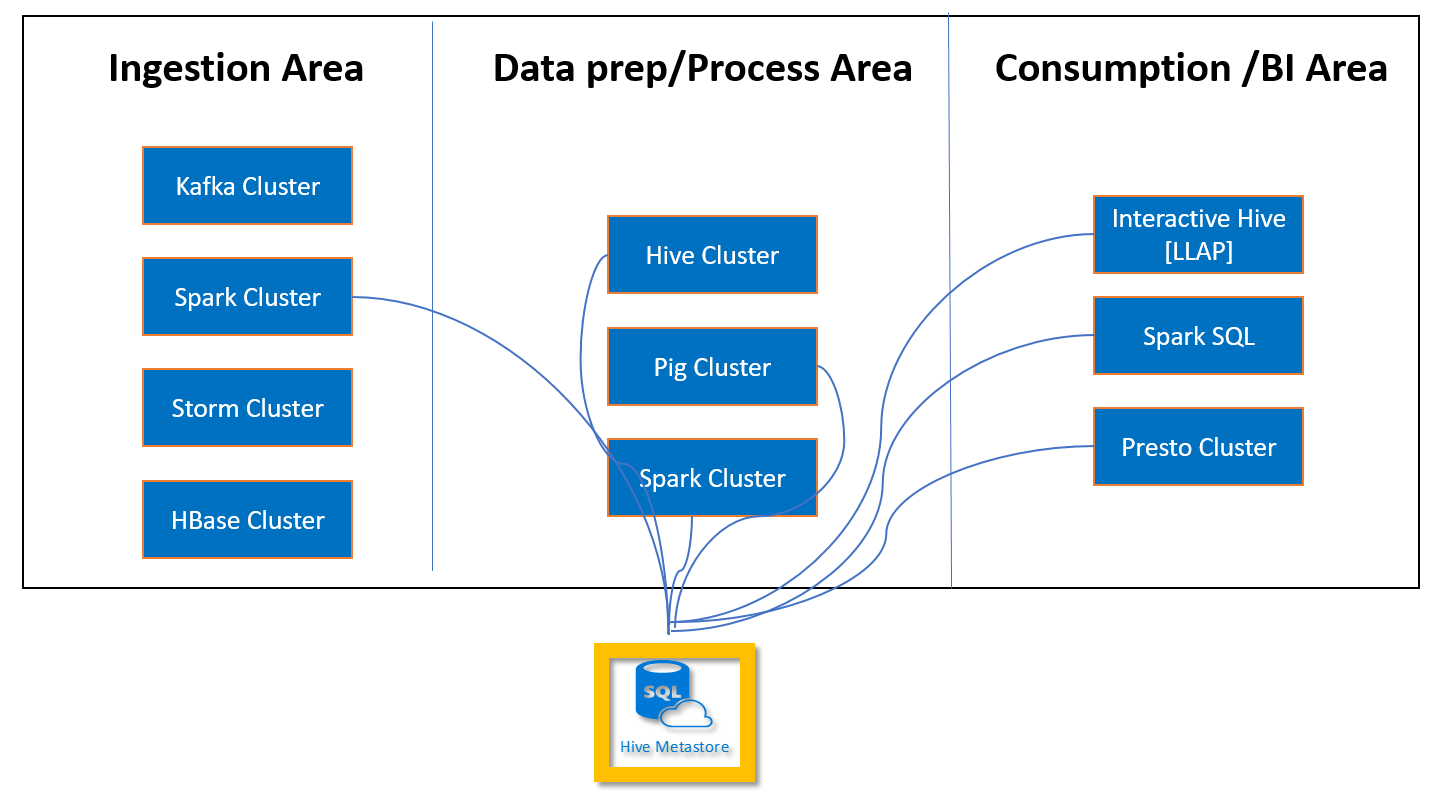
Criar e configurar o Banco de Dados SQL do Azure para o metastore personalizado
Crie ou tenha um Banco de Dados SQL do Azure existente antes de configurar um metastore do Hive personalizado para um cluster HDInsight. Para obter mais informações, confira Início rápido: Criar um banco de dados individual no Banco de Dados SQL do Azure.
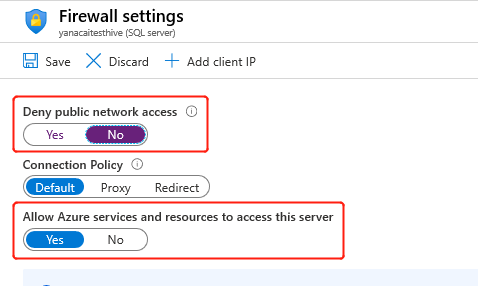
Quando você cria o cluster, o serviço HDInsight precisa se conectar ao metastore externo e verificar suas credenciais. Configure as regras de firewall do Banco de Dados SQL do Azure para permitir que os serviços e recursos do Azure acessem o servidor. Habilite essa opção no portal do Azure selecionando Definir firewall do servidor. Em seguida, selecione Não abaixo de Negar acesso à rede pública e Sim abaixo de Permitir que os serviços e recursos do Azure acessem este servidor para o Banco de Dados SQL do Azure. Para obter mais informações, confira Criar e gerenciar regras de firewall de IP
Os pontos de extremidade privados para repositórios SQL só têm suporte nos clusters criados com ResourceProviderConnection outbound. Para saber mais, confira esta documentação.

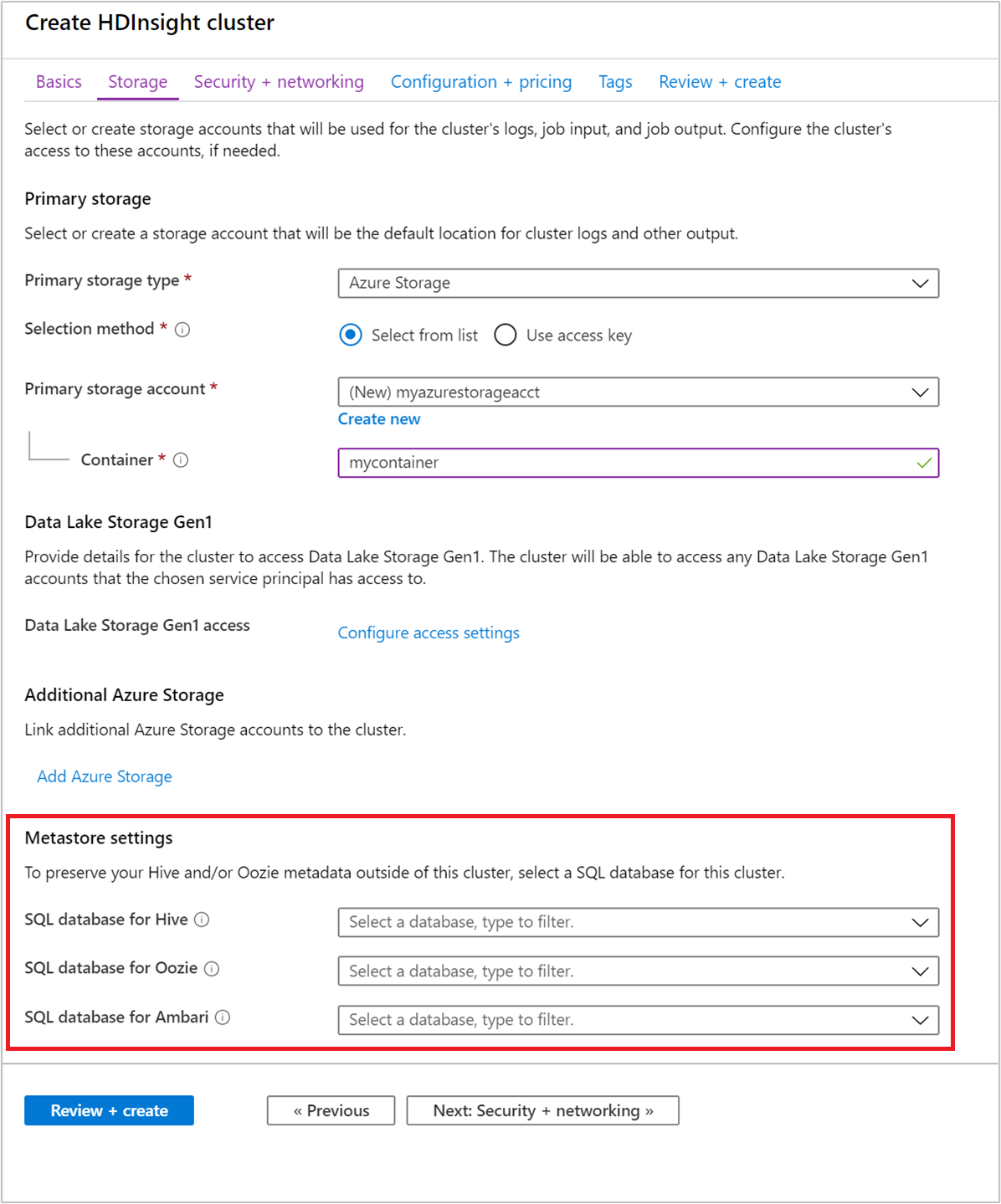
Selecione um metastore personalizado durante a criação do cluster
Você pode apontar seu cluster para um Banco de Dados SQL do Azure criado anteriormente a qualquer momento. Para a criação do cluster por meio do portal, a opção é especificada em Armazenamento > Configurações do metastore.
Diretrizes do metastore do Apache Hive
Observação
Use um metastore personalizado sempre que possível, para ajudar a separar recursos de computação (seu cluster em execução) e metadados (armazenados no metastore). Comece com uma camada S2, que fornece 50 DTU e 250 GB de armazenamento. Se você vir um afunilamento, poderá expandir o banco de dados.
Se você pretende que vários clusters HDInsight acessem dados separados, use um banco de dados separado para o metastore em cada cluster. Se você compartilhar um metastore entre vários clusters do HDInsight, isso significa que os clusters usam os mesmos metadados e arquivos de dados do usuário subjacentes.
Faça backup de seu metastore personalizado periodicamente. O Banco de Dados SQL do Azure gera backups automaticamente, mas o prazo de retenção de backup varia. Para obter mais informações, consulte Saiba mais sobre os backups automáticos do Banco de Dados SQL.
Localize seu metastore e o cluster HDInsight na mesma região. Essa configuração fornecerá o melhor desempenho e os menores preços de saída de rede.
Monitore o metastore quanto ao desempenho e disponibilidade usando ferramentas de monitoramento do Banco de Dados SQL do Azure, ou o Azure Log Analytics.
Quando versão nova e mais recente do Azure HDInsight é criada em um banco de dados de metastore personalizado existente, o sistema atualiza o esquema do metastore. A atualização é irreversível sem restaurar o banco de dados do backup.
Se você compartilhar um metastore em vários clusters, verifique se todos os clusters são da mesma versão do HDInsight. Diferentes versões do Hive usam diferentes esquemas de banco de dados metastore. Por exemplo, você não pode compartilhar um metastore entre os clusters de versão Hive 2.1 e Hive 3.1.
No HDInsight 4.0, o Spark e o Hive usam catálogos independentes para acessar tabelas SparkSQL ou Hive. Uma tabela criada pelo Spark reside no catálogo do Spark. Uma tabela criada pelo Hive reside no catálogo do Hive. Esse comportamento é diferente no HDInsight 3.6, onde o Hive e o Spark compartilham o catálogo comum. A integração do Hive e do Spark no HDInsight 4.0 depende do Hive Warehouse Connector (HWC). O HWC funciona como uma ponte entre o Spark e o Hive. Saiba mais sobre o Hive Warehouse Connector.
No HDInsight 4.0, se quiser compartilhar o metastore entre o Hive e o Spark, você poderá alterar a propriedade metastore.catalog.default para hive no cluster do Spark. Você pode encontrar essa propriedade no spark2-hive-site-override do Ambari Advanced. É importante entender que o compartilhamento do metastore só funciona para tabelas externas do Hive. Isso não funcionará se você tiver tabelas internas/gerenciadas do Hive ou tabelas ACID.
Como atualizar a senha personalizada do metastore do Hive
Ao usar um banco de dados de metastore do Hive personalizado, você tem a capacidade de alterar a senha do banco de dados SQL. Se você alterar a senha do metastore personalizado, os serviços do Hive não funcionarão até que você atualize a senha no cluster do HDInsight.
Para atualizar a senha do metastore do Hive:
- Abra a interface do usuário do Ambari.
- Clique em Serviços --> Hive --> Configurações --> Banco de Dados.
- Atualize os campos Senha do Banco de Dados com a nova senha do banco de dados do SQL Server.
- Clique no botão Testar Conexão para garantir que a nova senha funcione.
- Clique no botão Salvar .
- Siga os prompts do Ambari para salvar a configuração e Reiniciar os serviços necessários.
Metastore do Apache Oozie
Apache Oozie é um sistema de coordenação do fluxo de trabalho que gerencia trabalhos do Hadoop. O Oozie dá suporte a trabalhos do Hadoop para Apache MapReduce, Pig, Hive e outros. O Oozie usa um metastore para armazenar detalhes sobre fluxos de trabalho. Para aumentar o desempenho ao usar o Oozie, você pode usar o Banco de Dados SQL do Azure como um metastore personalizado. O metastore também pode fornecer acesso a dados de trabalho do Oozie após você excluir o cluster.
Para obter instruções sobre como criar um metastore Oozie com o Banco de Dados SQL do Azure, confira Usar o Apache Oozie para fluxos de trabalho.
Como atualizar a senha personalizada do metastore do Oozie
Ao usar um banco de dados de metastore do Oozie personalizado, você tem a capacidade de alterar a senha do banco de dados SQL. Se você alterar a senha do metastore personalizado, os serviços do Oozie não funcionarão até que você atualize a senha no cluster do HDInsight.
Para atualizar a senha do metastore do Oozie:
- Abra a interface do usuário do Ambari.
- Clique em Serviços --> Oozie --> Configurações --> Banco de Dados.
- Atualize os campos Senha do Banco de Dados com a nova senha do banco de dados do SQL Server.
- Clique no botão Testar Conexão para garantir que a nova senha funcione.
- Clique no botão Salvar .
- Siga os prompts do Ambari para salvar a configuração e Reiniciar os serviços necessários.
BD Ambari personalizado
Para usar seu próprio banco de dados externo com o Apache Ambari no HDInsight, consulte Banco de dados personalizado do Apache Ambari.