Use MirrorMaker para replicar tópicos do Apache Kafka com Kafka no HDInsight
Saiba como usar o recurso de espelhamento do Apache Kafka para replicar tópicos para um cluster secundário. Você pode executar o espelhamento como um processo contínuo, ou de forma intermitente, para migrar dados de um cluster para outro.
Neste artigo, você usará o espelhamento para replicar tópicos entre dois clusters do HDInsight. Esses clusters estão em redes virtuais diferentes, em datacenters diferentes.
Aviso
Não use o espelhamento como meio de obter tolerância a falhas. O deslocamento para itens em um tópico é diferente entre os clusters primário e secundário, assim, os clientes não podem usar os dois intercambiavelmente. Se estiver preocupado com a tolerância a falhas, você deverá definir a replicação para os tópicos no cluster. Para saber mais, consulte Introdução ao Apache Kafka no HDInsight.
Como funciona o espelhamento do Apache Kafka
O espelhamento funciona usando a ferramenta MirrorMaker, que faz parte do Apache Kafka. O MirrorMaker consome registros de tópicos no cluster primário e, em seguida, cria uma cópia local no cluster secundário. O MirrorMaker usa um ou mais consumidores que leem do cluster primário e um produtor que grava no cluster secundário local.
A configuração de espelhamento mais útil para recuperação de desastres usa clusters do Kafka em diferentes regiões do Azure. Para conseguir isso, as redes virtuais nas quais os clusters residem são emparelhadas.
O seguinte diagrama ilustra o processo de espelhamento e como a comunicação flui entre os clusters:
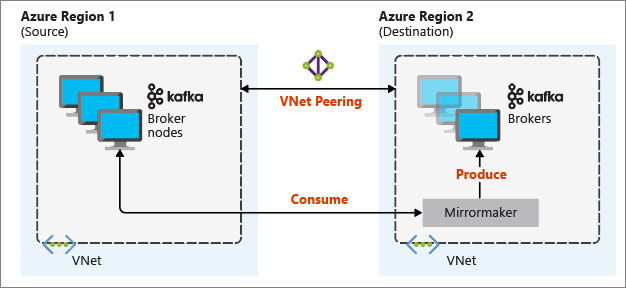
Os clusters primário e secundário podem ser diferentes no número de nós e partições, e os deslocamentos nos tópicos também são diferentes. O espelhamento mantém o valor de chave que é usado para particionamento. Assim, a ordem de registros é preservada por chave.
Espelhamento entre limites de rede
Se você precisa de espelhamento entre clusters Kafka em redes diferentes, há as seguintes considerações adicionais:
Gateways: as redes devem ser capazes de se comunicar no nível de TCP/IP.
Endereçamento de servidor: você pode optar por endereçar seus nós de cluster usando seus endereços IP ou nomes de domínio totalmente qualificados.
Endereços IP: se você configurar seus clusters do Kafka para usar anúncio de endereço IP, poderá prosseguir com a configuração de espelhamento usando os endereços IP dos nós do agente e nós do ZooKeeper.
Nomes de domínio: se você não configurar os clusters do Kafka para anúncio de endereço IP, os clusters deverão ser capazes de se conectar entre si usando FQDNs (nomes de domínio totalmente qualificados). Isso exige um servidor DNS (Sistema de Nomes de Domínio) em cada rede configurada para encaminhar solicitações para outras redes. Ao criar uma Rede Virtual do Azure, em vez de usar o DNS automático fornecido com a rede, você deve especificar um servidor DNS personalizado e o endereço IP do servidor. Depois de criar a rede virtual, você deve criar uma máquina virtual do Azure que use esse endereço IP. Em seguida, você instala e configura o software de DNS nela.
Importante
Crie e configure o servidor DNS personalizado antes de instalar o HDInsight na rede virtual. Não é necessária configuração adicional para que o HDInsight use o servidor DNS configurado para a rede virtual.
Para obter mais informações sobre como conectar duas redes virtuais do Azure, confira Configurar uma conexão.
Arquitetura de espelhamento
Essa arquitetura apresenta dois clusters em grupos diferentes de recursos e redes virtuais: um primário e um secundário.
Etapas de criação
Criar dois novos grupos de recursos:
Resource group Location kafka-primary-rg Centro dos EUA kafka-secondary-rg Centro-Norte dos EUA Crie uma nova rede virtual Kafka-primary-vnet em Kafka-primary-rg. Deixe as configurações padrão.
Crie uma nova rede virtual Kafka-secondary-vnet em Kafka-secondary-rg, também com as configurações padrão.
Crie dois novos clusters Kafka:
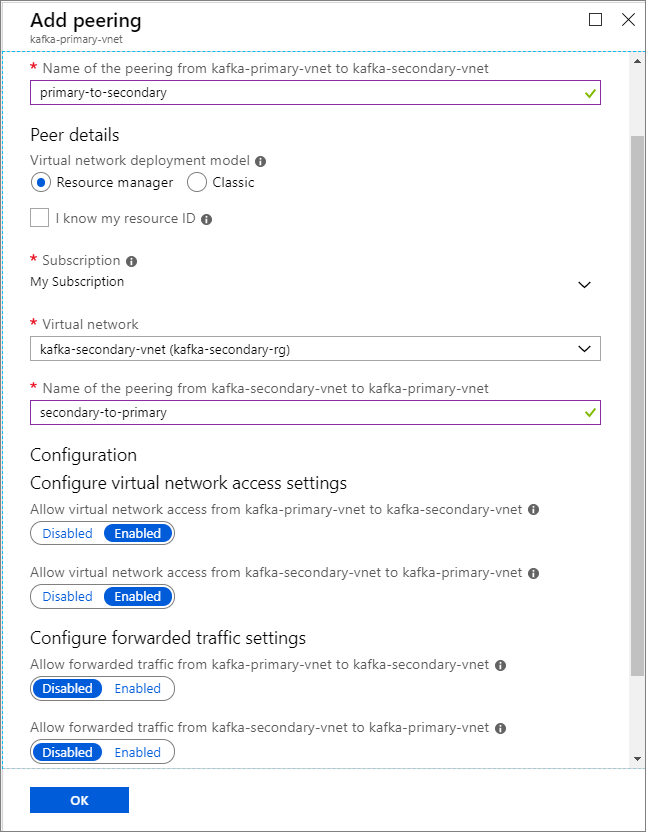
Nome do cluster Grupo de recursos Rede virtual Conta de armazenamento kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Crie emparelhamentos de rede virtual. Esta etapa criará dois emparelhamentos: um de kafka-primary-vnet para kafka-secondary-vnet, e um de volta de kafka-secondary-vnet para kafka-primary-vnet.
Selecione a rede virtual Kafka-primary-vnet .
Em Configurações, selecione Emparelhamentos.
Selecione Adicionar.
Na tela Adicionar emparelhamento, insira os detalhes, conforme mostrado na captura de tela a seguir.
Configurar publicidade de IP
Configure o anúncio de IP para permitir que um cliente se conecte usando endereços IP do agente em vez de nomes de domínio.
Acesse o painel do Ambari para o cluster primário:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Selecione Serviços>Kafka. Selecione a guia Configurações .
Adicione as seguintes linhas de configuração à seção inferior do modelo Kafka-env. Selecione Salvar.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesInsira uma observação na tela Salvar configuração e selecione Salvar.
Se você receber um aviso de configuração, selecione Continuar mesmo assim.
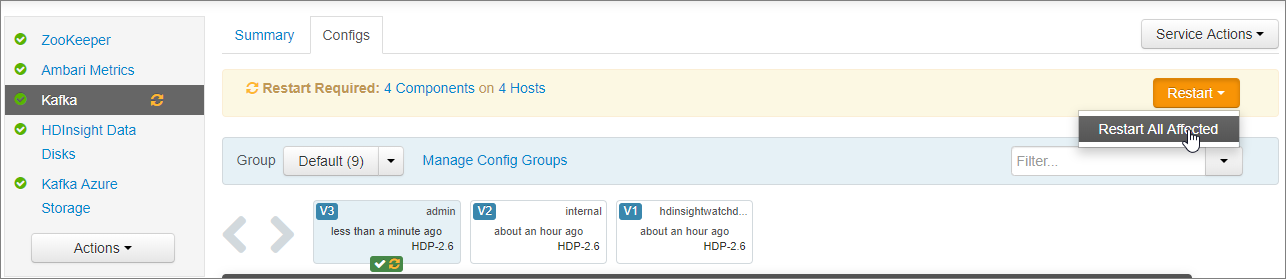
Em Salvar alterações de configuração, selecione Ok.
Na notificação Reinicialização necessária selecione Reiniciar>Reiniciar todos os afetados. Em seguida, selecione Confirmar reiniciar tudo.
Configure o Kafka para escutar em todas as interfaces de rede
- Permaneça na guia Configurações em Serviços>Kafka. Na seção Agente do Kafka, defina a propriedade ouvintes para
PLAINTEXT://0.0.0.0:9092. - Selecione Salvar.
- Selecione Reiniciar>Confirmar reiniciar tudo.
Endereços IP do agente de registro e endereços ZooKeeper para o cluster primário
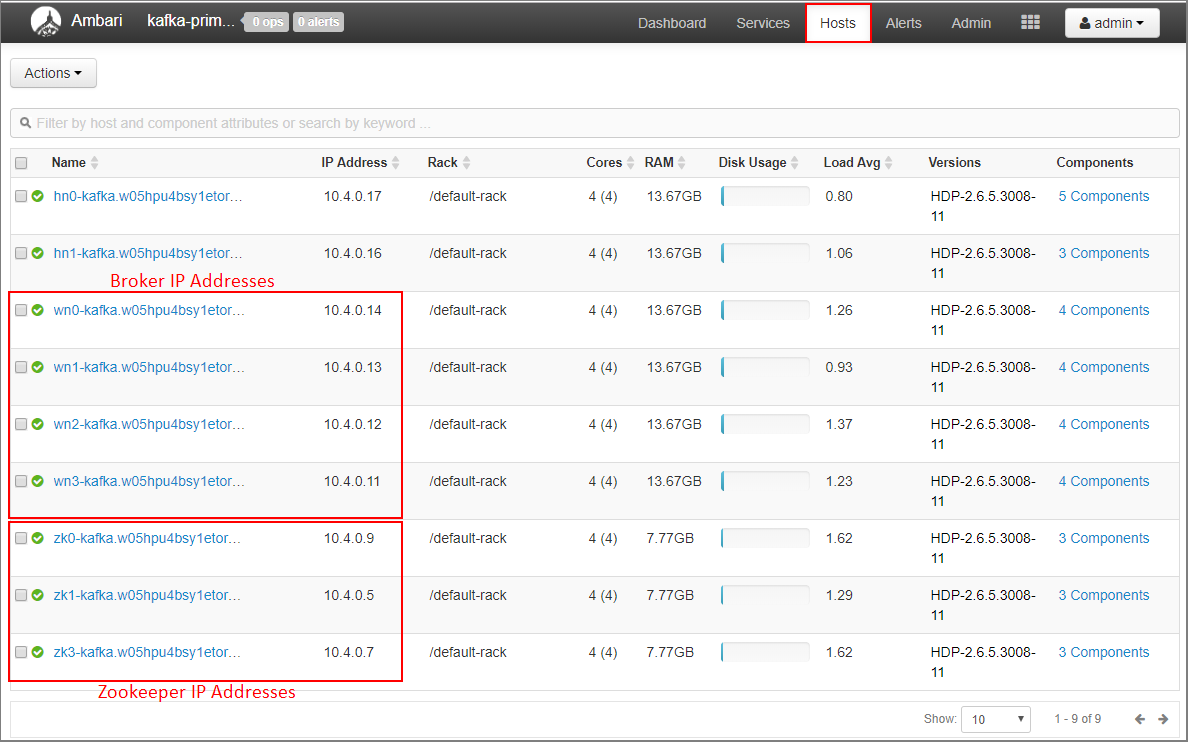
Selecione Hosts no painel do Ambari.
Anote os endereços IP para os agentes e ZooKeepers. Os nós do agente têm wn como as duas primeiras letras do nome do host e os nós ZooKeeper têm zk como as duas primeiras letras do nome do host.
Repita as três etapas anteriores para o segundo cluster kafka-secondary-cluster: configure o anúncio de IP, defina os ouvintes e anote os endereços IP do agente e do ZooKeeper.
Criar tópicos
Conecte-se ao cluster primário usando SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netSubstitua
sshuserpelo nome de usuário do SSH usado ao criar o cluster. SubstituaPRIMARYCLUSTERpelo nome de base usado ao criar o cluster.Para obter mais informações, confira Usar SSH com HDInsight.
Use o comando a seguir para criar duas variáveis de ambiente com os hosts do Apache ZooKeeper e hosts do agente para o cluster primário. Substitua as cadeias de caracteres como
ZOOKEEPER_IP_ADDRESS1pelos endereços IP reais registrados anteriormente, como10.23.0.11e10.23.0.7. O mesmo vale paraBROKER_IP_ADDRESS1. Se você estiver usando a resolução de FQDN com um servidor DNS personalizado, siga estas etapas para obter os nomes do agente e do ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Para criar um tópico nomeado
testtopic, use o seguinte comando:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSUse o seguinte comando para verificar se o tópico foi criado:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSA resposta contém
testtopic.Use o seguinte para exibir as informações de host do agente deste cluster (o primário):
echo $PRIMARY_BROKERHOSTSIsso retorna informações semelhantes ao seguinte texto:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Salve essas informações. Ele será usado na próxima seção.
Configurar o espelhamento
Conecte-se ao cluster secundário usando uma sessão de SSH diferente:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netSubstitua
sshuserpelo nome de usuário do SSH usado ao criar o cluster. SubstituaSECONDARYCLUSTERpelo nome usado ao criar o cluster.Para obter mais informações, confira Usar SSH com HDInsight.
Use um arquivo
consumer.propertiespara configurar a comunicação com cluster primário. Para criar o arquivo, use o seguinte comando:nano consumer.propertiesUse o seguinte texto como o conteúdo do arquivo
consumer.properties:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupSubstitua
PRIMARY_BROKERHOSTSpelos endereços IP do host do agente do cluster primário.Esse arquivo descreve as informações de consumidor a serem usadas ao ler do cluster Kafka primário. Para obter mais informações, consulte Configurações do consumidor em
kafka.apache.org.Para salvar o arquivo, pressione Ctrl+X, pressione Y e, em seguida, pressione Enter.
Antes de configurar o produtor que se comunica com o cluster secundário, configure uma variável para os endereços de IP do agente do cluster secundário. Use os comandos a seguir para criar esta variável:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'O comando
echo $SECONDARY_BROKERHOSTSretornará informações semelhantes ao seguinte texto:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Use um arquivo
producer.propertiespara se comunicar com o cluster secundário. Para criar o arquivo, use o seguinte comando:nano producer.propertiesUse o seguinte texto como o conteúdo do arquivo
producer.properties:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneSubstitua
SECONDARY_BROKERHOSTSpelos endereços IP do agente usados na etapa anterior.Para obter mais informações, consulte Configurações do produtor em
kafka.apache.org.Use os comandos a seguir para criar uma variável de ambiente com os endereços IP dos hosts ZooKeeper para o cluster secundário:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'A configuração padrão do Kafka no HDInsight não permite a criação automática de tópicos. Você deve usar uma das seguintes opções antes de iniciar o processo de espelhamento:
Criar os tópicos no cluster secundário: essa opção também permite que você defina o número de partições e o fator de replicação.
Você pode criar tópicos com antecedência usando o seguinte comando:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSSubstitua
testtopicpelo nome do tópico a ser criado.Configurar o cluster para criação automática de tópicos: essa opção permite que o MirrorMaker crie tópicos automaticamente. Observe que ele pode criá-los com um número diferente de partições ou um fator de replicação diferente do tópico primário.
Para configurar o cluster secundário para criar tópicos automaticamente, execute estas etapas:
- Acesse o painel do Ambari para o cluster secundário:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Selecione Serviços>Kafka. Em seguida, selecione a guia Configurações.
- No campo Filtrar, digite um valor de
auto.create. Isso filtrará a lista de propriedades e exibirá a configuraçãoauto.create.topics.enable. - Altere o valor de
auto.create.topics.enableparatruee selecione Salvar. Adicionar uma observação e, em seguida, selecione Salvar novamente. - Selecione o serviço Kafka, selecione Reiniciar e, em seguida, selecione Reiniciar todos os afetados. Quando solicitado, selecione Confirmar reiniciar tudo.
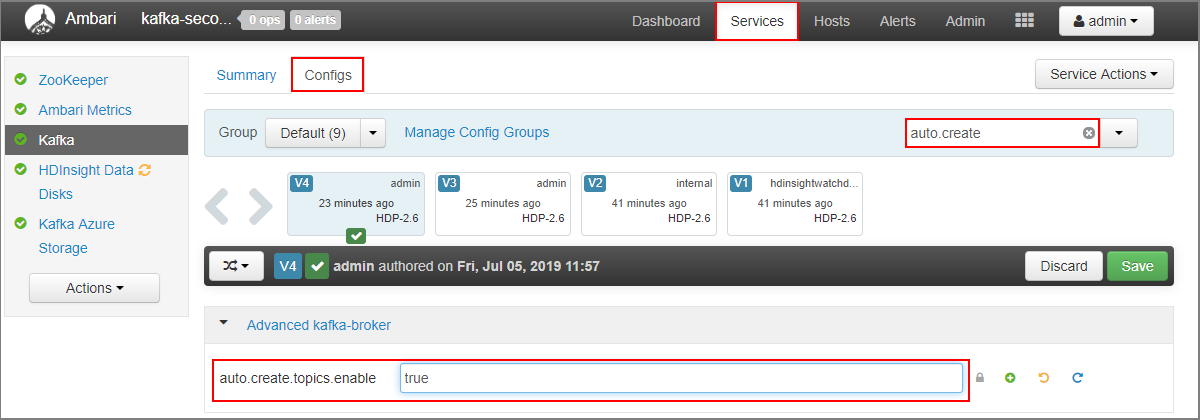
- Acesse o painel do Ambari para o cluster secundário:
Iniciar MirrorMaker
Observação
Este artigo contém referências a um termo que a Microsoft não usa mais. Quando o termo for removido do software, também o removeremos deste artigo.
Na conexão SSH para cluster secundário, use o seguinte comando para iniciar o processo MirrorMaker:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4Os parâmetros usados neste exemplo são:
Parâmetro Descrição --consumer.configEspecifica o arquivo que contém as propriedades do consumidor. Essas propriedades são utilizadas para criar um consumidor que lê a partir do cluster Kafka primário. --producer.configEspecifica o arquivo que contém as propriedades do produtor. Essas propriedades são utilizadas para criar um produtor que grava o cluster Kafka secundário. --whitelistUma lista de tópicos que o MirrorMaker replica do cluster primário para o secundário. --num.streamsNúmero de threads de consumidor a serem criados. O consumidor no nó secundário agora está aguardando para receber mensagens.
Na conexão SSH para o cluster primário, use o seguinte comando para iniciar um produtor e enviar mensagens para o tópico:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicQuando você chega a uma linha em branco com um cursor, digite algumas mensagens de texto. As mensagens são enviadas para o tópico no cluster primário. Depois de concluído, pressione Ctrl + C para finalizar o processo de produtor.
Na conexão SSH para o cluster secundário, pressione Ctrl+C para encerrar o processo do MirrorMaker. O processo pode levar vários segundos para finalizar. Para verificar se as mensagens foram replicadas no cluster secundário, use o seguinte comando:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningA lista de tópicos agora inclui
testtopic, que é criado quando MirrorMaster espelha o tópico do cluster primário para o secundário. As mensagens recuperadas do tópico são as mesmas inseridas no cluster primário.
Excluir o cluster
Aviso
A cobrança de clusters HDInsight é proporcional por minuto, independentemente de você utilizá-los ou não. Certifique-se de excluir o cluster após utilizá-lo. Consulte como excluir um cluster HDInsight.
As etapas neste artigo criaram clusters em diferentes grupos de recursos do Azure. Para excluir todos os recursos criados, você pode excluir os dois grupos de recursos criados: kafka-primary-rg e kafka-secondary-rg. A exclusão dos grupos de recursos remove todos os recursos criados seguindo os passos neste artigo, incluindo clusters, redes virtuais e contas de armazenamento.
Próximas etapas
Neste artigo, você aprendeu a usar o MirrorMaker para criar uma réplica de um cluster do Apache Kafka. Use os links a seguir para descobrir outras maneiras de trabalhar com Kafka: