Tutorial: Compilar um aplicativo de aprendizado de máquina do Apache Spark no Azure HDInsight
Neste tutorial, você aprenderá a usar o Jupyter Notebook para compilar um aplicativo de aprendizado de máquina do Apache Spark para o Azure HDInsight.
A MLlib é a biblioteca de machine learning adaptável do Spark, que consiste em algoritmos e utilitários de aprendizado comuns. (Classificação, regressão, clustering, filtragem colaborativa e redução de dimensionalidade. Além disso, primitivos de otimização subjacentes).
Neste tutorial, você aprenderá como:
- Desenvolver um aplicativo de aprendizado de máquina do Apache Spark
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Veja Criar um cluster do Apache Spark.
Familiaridade com o uso de anotações do Jupyter com Spark no HDInsight. Para obter mais informações, confira Carregar dados e executar consultas com o Apache Spark no HDInsight.
Entender o conjunto de dados
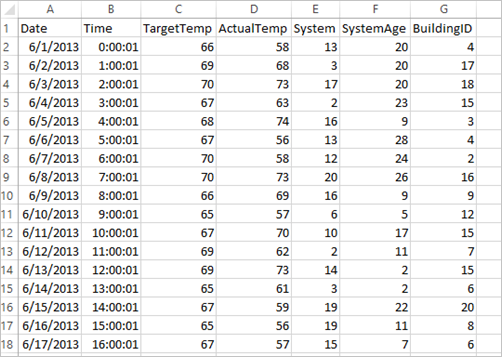
O aplicativo usa os dados de HVAC.csv de exemplo que estão disponíveis em todos os clusters por padrão. O arquivo está localizado em \HdiSamples\HdiSamples\SensorSampleData\hvac. Os dados mostram a temperatura de destino e a temperatura real de algumas compilações com sistemas de HVAC instalados. A coluna System representa a ID do sistema e a coluna SystemAge representa o número de anos que o sistema HVAC foi instalado no prédio. Você pode prever se um prédio será mais quente ou mais frio com base na meta de temperatura, na ID do sistema específico e na idade do sistema.
Desenvolver um aplicativo de aprendizado de máquina do Spark usando o MLlib Spark
Esse aplicativo usa um pipeline do pipeline de ML do Spark para fazer uma classificação de documentos. Os pipelines de ML fornecem um conjunto uniforme de APIs de alto nível criadas com base em DataFrames. Os DataFrames ajudam os usuários a criar e ajustar pipelines práticos de machine learning. No pipeline, você divide o documento em palavras, converte as palavras em um vetor de recurso numérico e, finalmente, cria um modelo de previsão usando as etiquetas e vetores de recurso. Execute as etapas a seguir para criar o aplicativo.
Crie um Jupyter Notebook usando o kernel do PySpark. Para obter as instruções, confira Criar um arquivo do Jupyter Notebook.
Importe os tipos obrigatórios necessários para este cenário. Cole o snippet a seguir em uma célula vazia e pressione SHIFT+ENTER.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayCarregue os dados (hvac.csv), analisá-los e usá-los para treinar o modelo.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()No snippet de código, você definirá uma função que compare a temperatura real com a temperatura de destino. Se a temperatura real é maior, o prédio está quente, indicado pelo valor 1,0. Caso contrário, a compilação fica fria, como indicado pelo valor 0,0.
Configure o pipeline de aprendizado da máquina Spark que consiste de três estágios:
tokenizer,hashingTF, elr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Para obter mais informações sobre o pipeline e como ele funciona, confira Pipeline de aprendizado de máquina Apache Spark.
Ajuste o pipeline para o documento de treinamento.
model = pipeline.fit(training)Verifique o documento de treinamento para o ponto de verificação de seu progresso com o aplicativo.
training.show()A saída deverá ser semelhante a:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Comparando a saída em relação ao arquivo CSV bruto. Por exemplo, a primeira linha do arquivo CSV tem esses dados:

Observe como a temperatura real é menor que a temperatura de destino sugerindo que o prédio está frio. O valor para o rótulo na primeira linha é 0,0, o que significa que o prédio não está quente.
Prepare um conjunto de dados para executar o modelo treinado. Para fazer isso, você passa uma ID do sistema e a idade do sistema (indicada como SystemInfo na saída de treinamento). O modelo prevê se o edifício com essa ID do sistema e idade do sistema será mais quente (indicado por 1,0) ou mais frio (indicado por 0,0).
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Por fim, faça as previsões nos dados de teste.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)A saída deverá ser semelhante a:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Observe a primeira linha na previsão. Para um sistema HVAC com ID 20 e sistema de 25 anos, o prédio está quente (previsão = 1,0). O primeiro valor de DenseVector (0,49999) corresponde à previsão 0,0 e o segundo valor (0,5001) corresponde à previsão 1,0. Na saída, mesmo que o segundo valor seja apenas um pouco mais alto, o modelo mostra previsão = 1,0.
Feche o bloco de anotações para liberar os recursos. Para fazer isso, no menu Arquivo do notebook, selecione Fechar e Interromper. Essa ação desliga e fecha o bloco de anotações.
Use a biblioteca Anaconda scikit-learn para aprendizado de máquina do Spark
Os clusters Apache Spark no HDInsight incluem bibliotecas Anaconda. Também inclui a biblioteca scikit-learn para aprendizado de máquina. A biblioteca também inclui vários conjuntos de dados que você pode usar para criar aplicativos de exemplo diretamente em um Jupyter Notebook. Para obter exemplos sobre como usar a biblioteca scikit-learn, consulte https://scikit-learn.org/stable/auto_examples/index.html.
Limpar os recursos
Se não for continuar a usar este aplicativo, exclua o cluster que criou seguindo estas etapas:
Entre no portal do Azure.
Na caixa Pesquisar na parte superior, digite HDInsight.
Selecione Clusters do HDInsight em Serviços.
Na lista de clusters do HDInsight exibida, selecione … ao lado do cluster que você criou para este tutorial.
Selecione Excluir. Selecione Sim.
Próximas etapas
Neste tutorial, você aprendeu a usar o Jupyter Notebook para criar um aplicativo de aprendizado de máquina do Apache Spark para o Azure HDInsight. Vá para o próximo tutorial para saber como usar IntelliJ IDEA para trabalhos do Spark.