Pré-processar Texto
Este artigo descreve o componente no Azure Machine Learning Designer.
Use o componente Pré-Processamento de Texto para limpar e simplificar o texto. Ele dá suporte a essas operações comuns de processamento de texto:
- Remoção de palavras irrelevantes
- Usar expressões regulares para pesquisar e substituir cadeias de caracteres de destino específicas
- Lematização, que converte várias palavras relacionadas em um único formulário canônico
- Normalização de caso
- A remoção de determinadas classes de caracteres, como números, caracteres especiais e sequências de caracteres repetidos, como "aaaa"
- Identificação e remoção de emails e URLs
No momento, o componente Pré-Processamento de Texto só é compatível com o idioma inglês.
Configurar o pré-processamento de texto
Adicione o componente Pré-Processamento de Texto ao seu pipeline no Azure Machine Learning. Você pode encontrar esse componente em Análise de Texto.
Conecte um conjunto de dados que tenha pelo menos uma coluna contendo texto.
Selecione o idioma na lista suspensa de idioma.
Coluna de texto a ser limpa: selecione a coluna que você deseja pré-processar.
Remover palavras irrelevantes: selecione esta opção se desejar aplicar uma lista de palavras irrelevantes predefinidas à coluna de texto.
As listas de palavras irrelevantes dependem do idioma e são personalizáveis.
Lematização: selecione esta opção se quiser que as palavras sejam representadas em sua forma canônica. Essa opção é útil para reduzir o número de ocorrências exclusivas de outros tokens de texto semelhantes.
O processo lematização é altamente dependente do idioma.
Detectar frases: selecione esta opção se desejar que o componente insira uma marca de limite de frase ao realizar a análise.
Esse componente usa uma série de três caracteres de pipe
|||para representar o terminador de frases.Execute operações de localização e substituição opcionais usando expressões regulares. A expressão regular será processada a princípio, antes de todas as outras opções internas.
- Expressão regular personalizada: defina o texto que você está pesquisando.
- Cadeia de caracteres de substituição personalizada: defina um único valor de substituição.
Normalizar maiúsculas e minúsculas: selecione esta opção se desejar converter caracteres maiúsculos ASCII em formatos minúsculos.
Se os caracteres não forem normalizados, a mesma palavra em letras maiúsculas e minúsculas será considerada duas palavras diferentes.
Você também pode remover os seguintes tipos de caracteres ou sequências de caracteres do texto de saída processado:
Remover números: selecione esta opção para remover todos os caracteres numéricos do idioma especificado. Os números de identificação dependem do domínio e do idioma. Se os caracteres numéricos forem parte integral de uma palavra conhecida, o número poderá não ser removido. Saiba mais em Notas técnicas.
Remover caracteres especiais: use esta opção para remover quaisquer caracteres especiais não alfanuméricos.
Remover caracteres duplicados: selecione esta opção para remover caracteres extras em qualquer sequência que se repita mais de duas vezes. Por exemplo, uma sequência como "aaaaa" seria reduzida a "aa".
Remover endereços de email: selecione esta opção para remover qualquer sequência do formato
<string>@<string>.Remover URLs: selecione esta opção para remover qualquer sequência que inclua os seguintes prefixos de URL:
http,https,ftp,www
Expandir contrações de verbos: essa opção se aplica somente a idiomas que usam contratações de verbo; atualmente, somente em inglês.
Por exemplo, ao selecionar essa opção, você pode substituir a frase "wouldn't stay there" por "would not stay there" .
Normalizar barras invertidas para barras: selecione esta opção para mapear todas as instâncias de
\\para/.Dividir tokens em caracteres especiais: selecione esta opção se desejar quebrar palavras em caracteres como
&,-e assim por diante. Essa opção também pode reduzir os caracteres especiais quando eles se repetirem mais de duas vezes.Por exemplo, a cadeia de caracteres
MS---WORDseria separada em três tokens,MS,-eWORD.Envie o pipeline.
Observações técnicas
O componente Pré-Processamento de Texto no Studio (clássico) e o designer usam modelos de linguagem diferentes. O designer usa um modelo treinado CNN de várias tarefas do spaCy. Modelos distintos fornecem diferentes geradores de tokens e marcadores de parte do discurso, o que gera diferentes resultados.
A seguir estão alguns exemplos:
| Configuração | Resultado de saída |
|---|---|
| Com todas as opções selecionadas Explicação: para casos como '3test' em 'WC-3 3test 4test', o designer remove a palavra inteira '3test', pois, nesse contexto, o marcador de classe gramatical especifica esse token '3test' como algarismo e, de acordo com a classe gramatical, o componente o remove. |
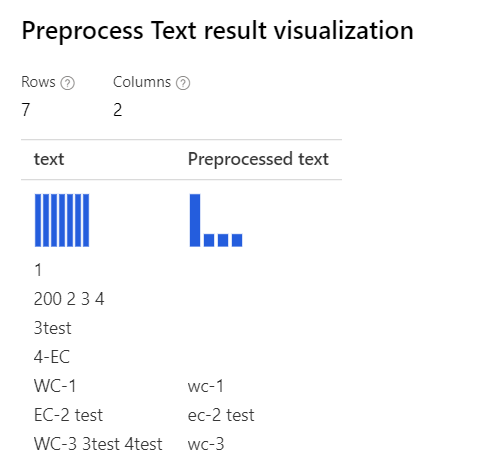
|
Somente com Removing number selecionado Explicação: para casos como "3test", "4-EC", o gerador de tokens do designer não divide os casos e os trata como tokens inteiros. Portanto, ele não removerá os números nessas palavras. |

|
Você também pode usar a expressão regular para gerar resultados personalizados:
| Configuração | Resultado de saída |
|---|---|
| Com todas as opções selecionadas Expressão regular personalizada: (\s+)*(-|\d+)(\s+)* Cadeia de caracteres de substituição personalizada: \1 \2 \3 |

|
Com apenas Removing number a expressão regular personalizada selecionada : (\s+)*(-|\d+)(\s+)* String de substituição personalizada: \1 \2 \3 |
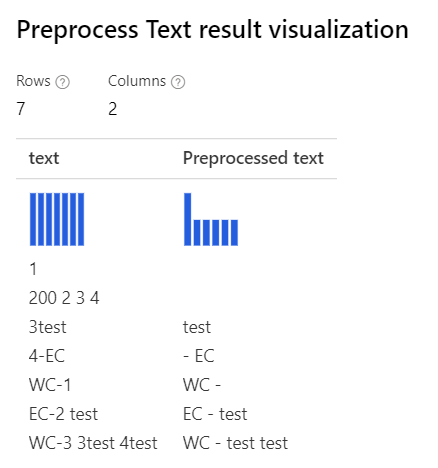
|
Próximas etapas
Confira o conjunto de componentes disponíveis no Azure Machine Learning.