Pontos de extremidade em lotes
O Azure Machine Learning permite implementar pontos de extremidade e implantações em lotes para executar inferências assíncronas e de longa execução com pipelines e modelos de machine learning. Ao treinar um modelo ou pipeline de machine learning, você precisa implantá-lo para que outras pessoas possam usá-lo com novos dados de entrada para gerar previsões. Esse processo de geração de previsões com o modelo ou pipeline é chamado de inferência.
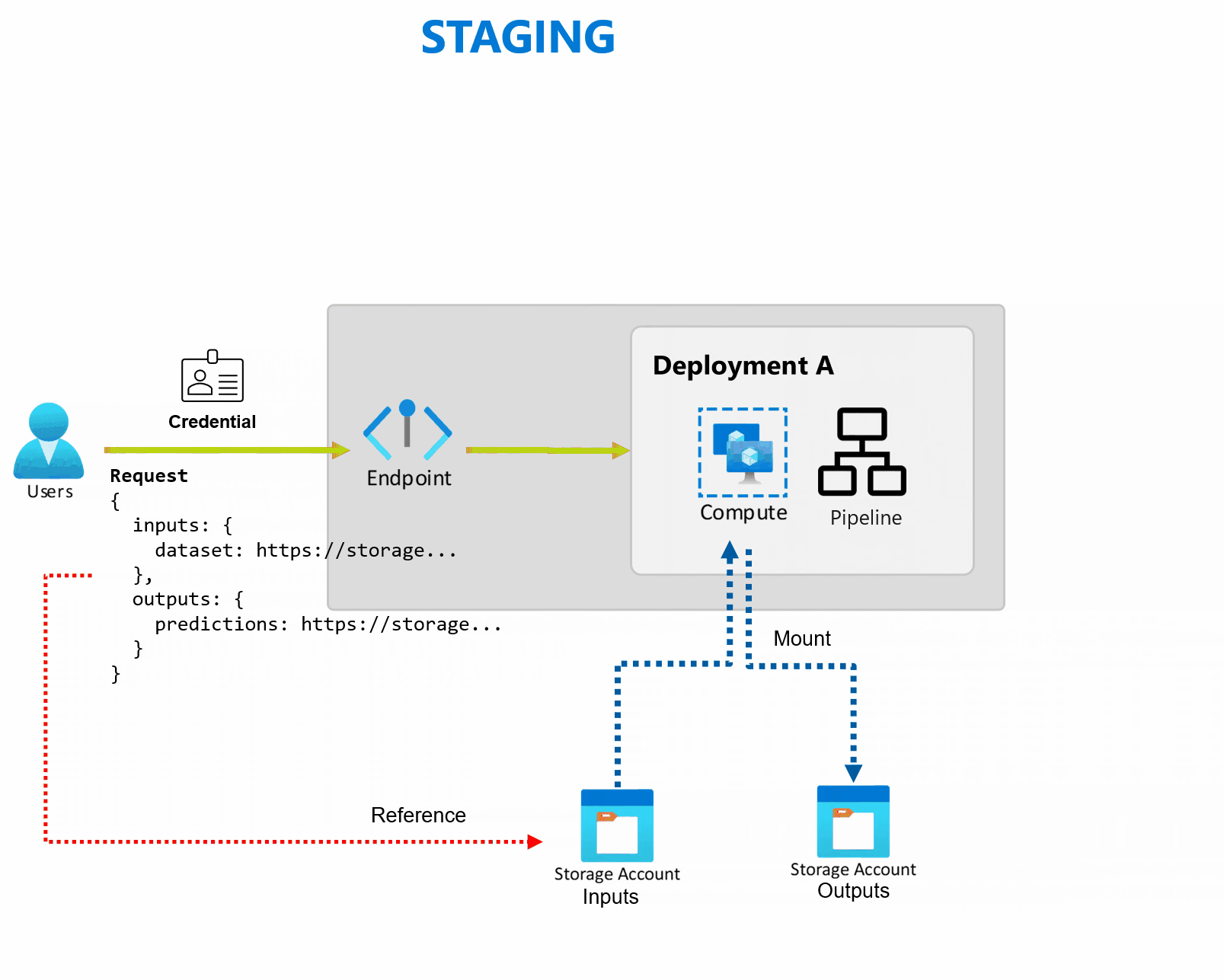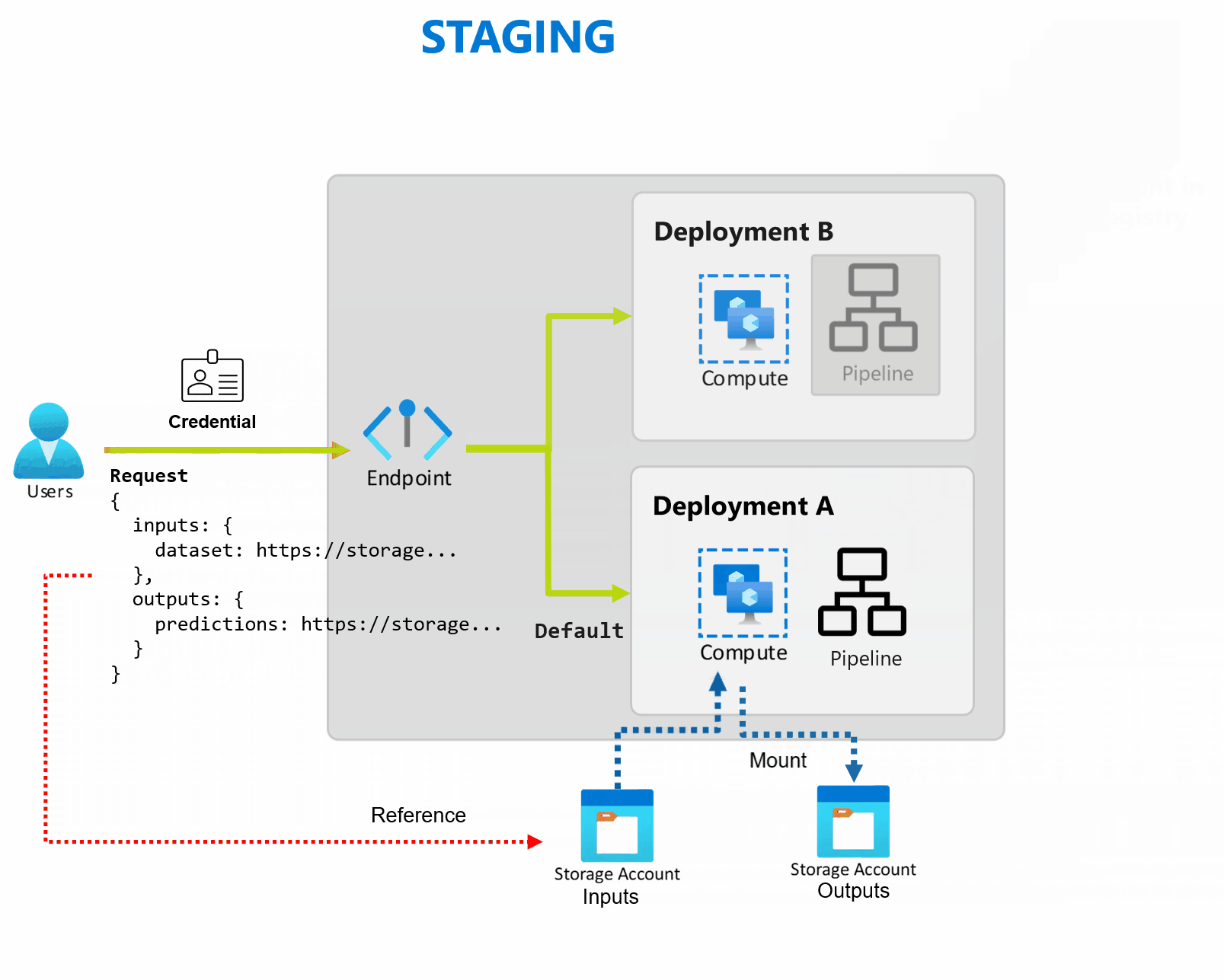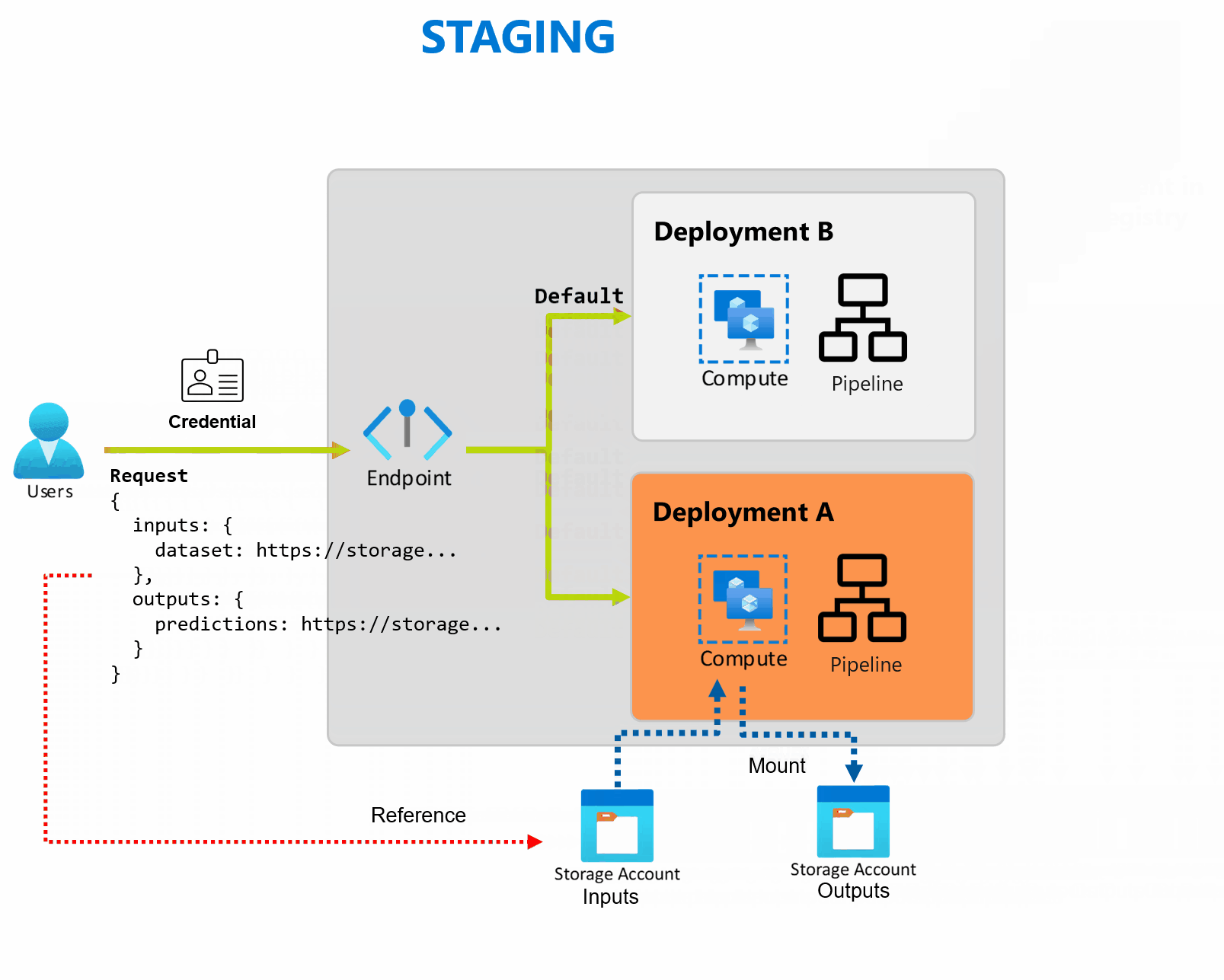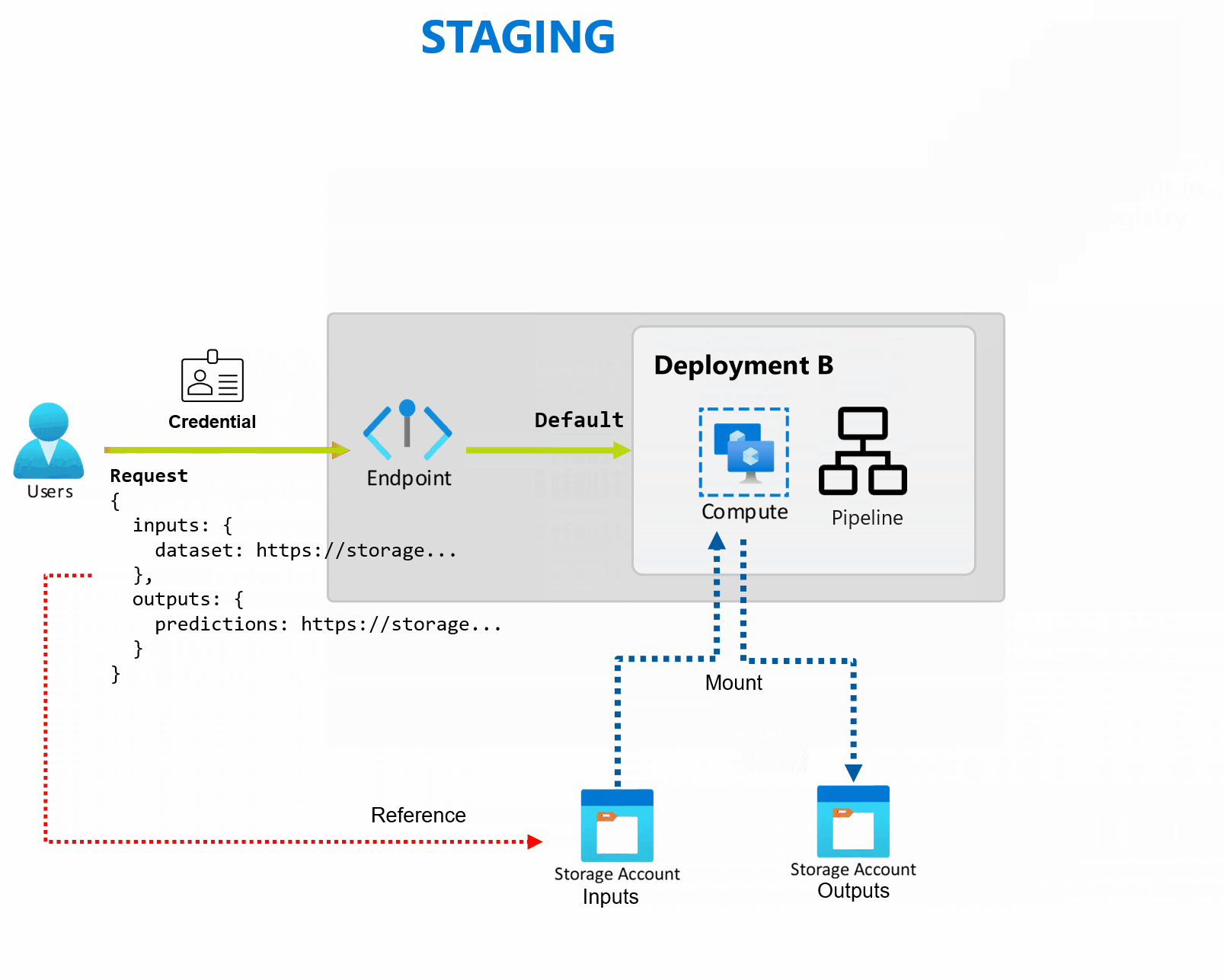
Os pontos de extremidade em lotes recebem ponteiros para dados e executam trabalhos de modo assíncrono para processar os dados em paralelo nos clusters de computação. Os pontos de extremidade em lotes armazenam as saídas em um armazenamento de dados para análise posterior. Use pontos de extremidade em lote quando:
- Você tem modelos ou pipelines caros que exigem mais tempo de execução.
- Você deseja operacionalizar pipelines de aprendizado de máquina e reutilizar componentes.
- Você precisa executar a inferência em grandes quantidades de dados, distribuídas em vários arquivos.
- Você não tem requisitos de baixa latência.
- As entradas do seu modelo são armazenadas em uma Conta de Armazenamento ou em um ativo de dados do Azure Machine Learning.
- Você pode aproveitar a paralelização.
Implantações em lote
Uma implantação é um conjunto de recursos e cálculos necessários para implantar a funcionalidade que o ponto de extremidade fornece. Cada ponto de extremidade pode hospedar várias implantações com configurações diferentes e essa funcionalidade ajuda a desacoplar a interface do ponto de extremidade dos detalhes de implementação definidos pela implantação. Quando um ponto de extremidade em lote é invocado, ele roteia automaticamente o cliente para sua implantação padrão. Essa implantação padrão pode ser configurada e alterada a qualquer momento.

Dois tipos de implantações são possíveis nos pontos de extremidade do lote do Azure Machine Learning:
Implantação de modelo
A implantação de modelo permite a operacionalização da inferência de modelo em escala, permitindo que você processe grandes quantidades de dados de forma assíncrona e de baixa latência. O Azure Machine Learning instrumenta automaticamente a escalabilidade, fornecendo paralelização dos processos de inferência em vários nós em um cluster de computação.
Use Implantação de modelo quando:
- Você tem modelos caros que exigem mais tempo para executar a inferência.
- Você precisa executar a inferência em grandes quantidades de dados, distribuídas em vários arquivos.
- Você não tem requisitos de baixa latência.
- Você pode aproveitar a paralelização.
O principal benefício das implantações de modelo é que você pode usar os mesmos ativos que são implantados para inferência em tempo real para pontos de extremidade online, mas agora, você pode executá-los em escala em lote. Se o modelo exigir pré-processamento simples ou pós-processamento, você pode criar um script de pontuação que execute as transformações de dados necessárias.
Para criar uma implantação de modelo em um ponto de extremidade em lote, especifique os seguintes elementos:
- Modelar
- Cluster de computação
- Script de pontuação (opcional para modelos de MLflow)
- Ambiente (opcional para modelos de MLflow)
Implantação do componente de pipeline
A implantação de componentes de pipeline habilita a operacionalização de gráficos de processamento inteiros (ou pipelines) para realizar inferência em lote de maneira assíncrona e de baixa latência.
Use a implantação de componentes de Pipeline quando:
- Você precisa operacionalizar gráficos computacionais completos que podem ser decompostos em várias etapas.
- Você precisa reutilizar os componentes de pipelines de treinamento no seu pipeline de inferência.
- Você não tem requisitos de baixa latência.
O principal benefício das implantações de componente de pipeline é a reutilização de componentes que já existem em sua plataforma e a capacidade de operacionalizar rotinas de inferência complexas.
Para criar uma implantação de componente de pipeline em um ponto de extremidade em lote, especifique os seguintes elementos:
- Componente de pipeline
- Configuração do cluster de computação
Os pontos de extremidade em lote também permitem que você Crie implantações do componente do Pipeline de um trabalho de pipeline existente. Ao fazer isso, o Azure Machine Learning cria automaticamente um componente de pipeline fora do trabalho. Isso simplifica o uso desses tipos de implantações. No entanto, é uma prática recomendada sempre criar componentes de pipeline explicitamente para simplificar sua prática de MLOps.
Gerenciamento de custos
A invocação de um ponto de extremidade em lotes dispara um trabalho de inferência em lotes assíncrono. O Azure Machine Learning provisiona automaticamente os recursos de computação quando o trabalho é iniciado e os desaloca automaticamente à medida que o trabalho é concluído. Desta forma, você só paga a computação quando a usa.
Dica
Ao implantar modelos, você pode substituir as configurações de recursos de computação (como a contagem de instâncias) e as configurações avançadas (como o tamanho do minilote, o limite de erros e assim por diante) para cada trabalho de inferência em lotes individual. Aproveitando essas configurações específicas, você pode acelerar a execução e reduzir o custo.
Os pontos de extremidade em lotes também podem ser executados em VMs de baixa prioridade. Os pontos de extremidade em lotes podem se recuperar automaticamente das VMs desalocadas e retomar o trabalho de onde foi deixado ao implantar modelos para inferência. Para obter mais informações sobre como usar VMs de baixa prioridade para reduzir o custo de cargas de trabalho de inferência em lotes, consulte Usar VMs de baixa prioridade em pontos de extremidade em lotes.
Por fim, o Azure Machine Learning não cobra pelos pontos de extremidade em lotes ou pelas próprias implantações em lote, para que você possa organizar seus pontos de extremidade e implantações da maneira mais adequada ao seu cenário. Os pontos de extremidade e a implantação podem utilizar clusters independentes ou compartilhados, para que você possa obter um controle refinado sobre qual computação os trabalhos consomem. Use escala para zero em clusters para garantir que nenhum recurso seja consumido quando estiver ocioso.
Simplificar a prática de MLOps
Os pontos de extremidade em lotes pode lidar com várias implantações no mesmo ponto de extremidade, permitindo que você altere a implementação do ponto de extremidade sem alterar a URL que seus consumidores usam para invocá-lo.
Você pode adicionar, remover e atualizar implantações sem afetar o próprio ponto de extremidade.
Fontes de dados e armazenamento flexíveis
Os pontos de extremidade em lotes leem e gravam dados diretamente do armazenamento. Você pode especificar os armazenamentos de dados do Azure Machine Learning, os ativos de dados do Azure Machine Learning ou as contas de armazenamento como entradas. Para obter mais informações sobre as opções de entrada com suporte e como especificá-las, consulte Criar trabalhos e inserir dados nos pontos de extremidade em lotes.
Segurança
Os pontos de extremidade em lotes fornecem todos os recursos necessários para operar cargas de trabalho de nível de produção em uma configuração corporativa. Eles dão suporte a rede privada em workspaces protegidos e Autenticação do Microsoft Entra, usando uma entidade de usuário (como uma conta de usuário) ou uma entidade de serviço (como uma identidade gerenciada ou não gerenciada). Os trabalhos gerados por um ponto de extremidade em lote são executados sob a identidade do invocador, o que lhe dá flexibilidade para implementar qualquer cenário. Para obter mais informações sobre autorização ao usar pontos de extremidade em lotes, consulte Como autenticar em pontos de extremidade em lotes.