Configurar o AutoML para treinar modelos de pesquisa visual computacional com o Python (v1)
APLICA-SE A:  SDK do Python azureml v1
SDK do Python azureml v1
Importante
Alguns comandos da CLI do Azure neste artigo usam a extensão azure-cli-ml ou v1 do Azure Machine Learning. O suporte à extensão v1 terminará em 30 de setembro de 2025. Você poderá instalar e usar a extensão v1 até essa data.
Recomendamos que você faça a transição para a extensão ml ou v2, antes de 30 de setembro de 2025. Para obter mais informações sobre a extensão v2, confira Extensão da CLI do Azure ML e SDK do Python v2.
Importante
Esse recurso está atualmente em visualização pública. Essa versão prévia é fornecida sem um contrato de nível de serviço. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
Neste artigo, você aprenderá a treinar modelos de pesquisa visual computacional em dados de imagem com ML automatizado no SDK do Python do Azure Machine Learning.
O ML automatizado dá suporte ao treinamento de modelos para tarefas de pesquisa visual computacional, como classificação de imagem, detecção de objetos e segmentação de instância. Atualmente, há suporte à criação de modelos de AutoML para tarefas de pesquisa visual computacional por meio do SDK do Python do Azure Machine Learning. As execuções, os modelos e as saídas de experimentação resultantes podem ser acessados na interface do usuário do Estúdio do Azure Machine Learning. Saiba mais sobre ML automatizado para tarefas de pesquisa visual computacional em dados de imagem.
Observação
O ML automatizado para tarefas de pesquisa visual computacional só está disponível por meio do SDK do Python do Azure Machine Learning.
Pré-requisitos
Um Workspace do Azure Machine Learning. Para criar o workspace, confira Criar recursos do workspace.
O SDK do Python do Azure Machine Learning instalado. Para instalar o SDK, você pode:
Criar uma instância de computação, que instala automaticamente o SDK e vem pré-configurada para fluxos de trabalho de ML. Para saber mais, confira Criar e gerenciar uma instância de computação do Azure Machine Learning.
Instalar o pacote
automlpor conta própria, que inclui a instalação padrão do SDK.
Observação
Somente as versões 3.7 e 3.8 do Python são compatíveis com o suporte de ML automatizado a tarefas de pesquisa visual computacional.
Selecionar o tipo de tarefa
O ML automatizado para imagens dá suporte aos seguintes tipos de tarefa:
| Tipo de tarefa | Sintaxe de configuração de AutoMLImage |
|---|---|
| classificação de imagem | ImageTask.IMAGE_CLASSIFICATION |
| classificação de imagem vários rótulos | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| detecção de objetos da imagem | ImageTask.IMAGE_OBJECT_DETECTION |
| segmentação de instâncias da imagem | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
Esse tipo de tarefa é um parâmetro obrigatório e é transmitido pelo uso do parâmetro task em AutoMLImageConfig.
Por exemplo:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
Dados de treinamento e validação
Para gerar modelos de pesquisa visual computacional, você precisa trazer dados de imagem rotulados como entrada para o treinamento do modelo na forma de um TabularDataset do Azure Machine Learning. Você pode usar um TabularDataset que tenha exportado de um projeto de rotulagem de dados ou criar um TabularDataset com seus dados de treinamento rotulados.
Se os dados de treinamento estão em um formato diferente (como Pascal VOC ou COCO), você pode aplicar os scripts auxiliares incluídos nos notebooks de amostra para converter os dados em JSONL. Saiba mais sobre como preparar dados para tarefas de pesquisa visual computacional ML automatizado.
Aviso
Há suporte para a criação de TabularDatasets com base em dados no formato JSONL usando apenas o SDK para essa funcionalidade. Não há suporte à criação de conjuntos de dados por meio da interface do usuário no momento. A partir de agora, a interface do usuário não reconhece o tipo de dados StreamInfo, que é o tipo de dados usado para URLs de imagem no formato JSONL.
Observação
O conjunto de dados de treinamento precisa ter pelo menos 10 imagens para poder enviar uma execução do AutoML.
Exemplos de esquema JSONL
A estrutura do TabularDataset depende da tarefa em questão. Para tipos de tarefa de pesquisa visual computacional, ele consiste nos seguintes campos:
| Campo | Descrição |
|---|---|
image_url |
Contém filepath como um objeto StreamInfo |
image_details |
As informações de metadados de imagem consistem em altura, largura e formato. Esse campo é opcional e, portanto, pode ou não existir. |
label |
Uma representação json do rótulo da imagem, com base no tipo de tarefa. |
Veja abaixo um arquivo JSONL de exemplo para classificação de imagem:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
O código a seguir é um arquivo JSONL de exemplo para detecção de objetos:
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Dados de consumo
Quando os dados estão no formato JSONL, você pode criar um TabularDataset com o seguinte código:
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
O ML automatizado não impõe restrições ao tamanho dos dados de treinamento ou validação para tarefas de pesquisa visual computacional. O tamanho máximo do conjuntos de dados é limitado apenas pela camada de armazenamento por trás do conjuntos de dados (ou seja, o armazenamento de blob). Não há nenhum número mínimo de imagens ou rótulos. No entanto, recomendamos começar com um mínimo de 10 a 15 amostras por rótulo para ter certeza de que o modelo de saída será suficientemente treinado. Quanto maior o número total de rótulos/classes, de mais amostras você precisará por rótulo.
Os dados de treinamento são obrigatórios e são transmitidos pelo uso do parâmetro training_data. Opcionalmente, você pode especificar outro TabularDataset como um conjunto de dados de validação a ser usado para seu modelo com o parâmetro validation_data de AutoMLImageConfig. Se nenhum conjunto de dados de validação for especificado, 20% dos dados de treinamento serão usados para validação por padrão, a menos que você transmita o argumento validation_size com um valor diferente.
Por exemplo:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
Computação para executar o experimento
Forneça um destino de computação para o ML automatizado realizar o treinamento do modelo. Os modelos de ML automatizados para tarefas de pesquisa visual computacional exigem SKUs de GPU e dão suporte às famílias NC e ND. Recomendamos a série NCsv3 (com GPUs v100) para um treinamento mais rápido. Um destino de computação com um SKU de VM com várias GPUs aproveita várias GPUs para também acelerar o treinamento. Além disso, ao configurar um destino de computação com vários nós, você poderá realizar um treinamento de modelo mais rápido por meio de paralelismo com o ajuste de hiperparâmetros para o modelo.
Observação
Se você estiver usando uma instância de computação como destino de computação, verifique se vários trabalhos de machine learning automatizado não são executados ao mesmo tempo. Além disso, verifique se esse max_concurrent_iterations está definido como 1 em seus recursos de experimento.
O destino de computação é um parâmetro obrigatório e é transmitido pelo uso do parâmetro compute_target de AutoMLImageConfig. Por exemplo:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
Configurar hiperparâmetros e algoritmos de modelo
Com suporte a tarefas de pesquisa visual computacional, você pode controlar o algoritmo de modelo e os hiperparâmetros de varredura. Esses algoritmos de modelo e hiperparâmetros são transmitidos como o espaço de parâmetro para a varredura.
O algoritmo de modelo é obrigatório e é transmitido pelo uso do parâmetro model_name. Você pode especificar um único model_name ou escolher entre vários.
Algoritmos de modelo com suporte
A tabela a seguir resume os modelos com suporte em cada tarefa de pesquisa visual computacional.
| Tarefa | Algoritmos de modelo | Sintaxe de literal de cadeia de caracteresdefault_model* anotado com * |
|---|---|---|
| Classificação de imagens (várias classes e vários rótulos) |
MobileNet: modelos leves para aplicativos móveis ResNet: redes residuais ResNeSt: redes de atenção dividida ES-ResNeXt50: redes squeeze-and-excitation ViT: redes de transformador de pesquisa visual |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (pequeno) vitb16r224* (base) vitl16r224 (grande) |
| Detecção de objetos | YOLOv5: modelo de detecção de objetos em uma fase RCNN ResNet FPN mais rápido: modelos de detecção de objetos em duas fases RetinaNet ResNet FPN: resolver desequilíbrio de classe com perda focal Observação: consulte o hiperparâmetro model_size para obter tamanhos de modelo YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentação de instâncias | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
Além de controlar o algoritmo de modelo, você também pode ajustar hiperparâmetros usados no treinamento do modelo. Embora muitos dos hiperparâmetros expostos independam do modelo, há instâncias em que os hiperparâmetros são específicos da tarefa do modelo. Saiba mais sobre os hiperparâmetros disponíveis para essas instâncias.
Aumento de dados
Em geral, o desempenho do modelo de aprendizado profundo costuma melhorar com mais dados. O aumento de dados é uma técnica prática para amplificar o tamanho e a variabilidade dos dados de um conjunto de dados, o que ajuda a evitar sobreajustes e a melhorar a capacidade de generalização do modelo em dados invisíveis. O ML automatizado aplica técnicas de aumento de dados diferentes com base na tarefa de pesquisa visual computacional antes de alimentar o modelo com as imagens de entrada. Atualmente, não há nenhum hiperparâmetro exposto para controlar os aumentos de dados.
| Tarefa | Conjunto de dados afetado | Técnicas de aumento de dados aplicadas |
|---|---|---|
| Classificação de imagem (várias classes e vários rótulos) | Treinamento Validação e teste |
Redimensionamento e corte aleatórios, inversão horizontal, variação de cor (brilho, contraste, saturação e matiz), normalização usando a média e o desvio padrão da ImageNet em termos de canal Redimensionamento, corte centralizado, normalização |
| Detecção de objetos, segmentação de instância | Treinamento Validação e teste |
Corte aleatório em torno de caixas delimitadoras, expansão, inversão horizontal, normalização redimensionamento Normalização, redimensionamento |
| Detecção de objetos usando yolov5 | Treinamento Validação e teste |
Mosaico, afinidade aleatória (rotação, translação, escala, distorção), inversão horizontal Redimensionamento de letterbox |
Configurar as definições do experimento
Antes de fazer uma grande varredura para pesquisar os modelos e hiperparâmetros ideais, recomendamos experimentar os valores padrão para obter uma primeira linha de base. Em seguida, você pode explorar vários hiperparâmetros para o mesmo modelo antes de varrer vários modelos e seus parâmetros. Dessa forma, você pode empregar uma abordagem mais iterativa, pois com vários modelos e vários hiperparâmetros para cada um, o espaço de pesquisa aumenta exponencialmente e você precisa de mais iterações para encontrar configurações ideais.
Se você quiser usar os valores de hiperparâmetro padrão para determinado algoritmo (digamos, yolov5), poderá especificar a configuração para a execução da imagem de AutoML da seguinte maneira:
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
Depois de criar um modelo de linha de base, talvez seja ideal otimizar o desempenho do modelo para varrer o algoritmo do modelo e o espaço de hiperparâmetro. Você pode usar a configuração de exemplo a seguir para varrer os hiperparâmetros de cada algoritmo, escolhendo um intervalo de valores para learning_rate, Optimizer, lr_scheduler etc. a fim de gerar um modelo com a métrica primária ideal. Se os valores de hiperparâmetro não forem especificados, valores padrão serão usados para o algoritmo especificado.
Métrica principal
A métrica primária usada para otimização do modelo e ajuste de hiperparâmetro depende do tipo de tarefa. No momento, não há suporte ao uso de outros valores de métrica primária.
accuracypara IMAGE_CLASSIFICATIONioupara IMAGE_CLASSIFICATION_MULTILABELmean_average_precisionpara IMAGE_OBJECT_DETECTIONmean_average_precisionpara IMAGE_INSTANCE_SEGMENTATION
Orçamento do experimento
Opcionalmente, você pode especificar o orçamento de tempo máximo para o experimento de pesquisa visual do AutoML usando experiment_timeout_hours: a quantidade de tempo em horas antes de o experimento ser encerrado. Se nada for especificado, o tempo limite de experimento padrão será de sete dias (máximo de 60 dias).
Hiperparâmetros de limpeza para o modelo
Ao treinar modelos de pesquisa visual computacional, o desempenho do modelo depende muito dos valores de hiperparâmetro selecionados. Muitas vezes, talvez seja melhor ajustar os hiperparâmetros para obter um desempenho ideal. Com suporte a tarefas da pesquisa visual computacional no ML automatizado, você pode varrer hiperparâmetros a fim de encontrar as configurações ideais para seu modelo. Esse recurso aplica os recursos de ajuste de hiperparâmetros no Azure Machine Learning. Aprenda a ajustar hiperparâmetros.
Defina o espaço de pesquisa de parâmetro
Você pode definir os algoritmos de modelo e hiperparâmetros para varredura no espaço de parâmetro.
- Consulte Configurar algoritmos e hiperparâmetros de modelo para obter a lista de algoritmos de modelo com suporte para cada tipo de tarefa.
- Consulte Hiperparâmetros para tarefas de pesquisa visual computacional, hiperparâmetros para cada tipo de tarefa de pesquisa visual computacional.
- Veja detalhes sobre as distribuições com suporte em hiperparâmetros discretos e contínuos.
Métodos de amostragem para a varredura
Ao varrer hiperparâmetros, você precisará especificar o método de amostragem a ser usado na varredura do espaço de parâmetro definido. Atualmente, os seguintes métodos de amostragem são compatíveis com o parâmetro hyperparameter_sampling:
Observação
Atualmente, apenas amostragem aleatória e de grade têm suporte para espaços de hiperparâmetros condicionais.
Políticas de término antecipado
Você pode encerrar automaticamente execuções de baixo desempenho com uma política de término antecipado. O encerramento antecipado melhora a eficiência computacional, pois economiza recursos de computação que, de outra forma, seriam gastos em configurações menos promissoras. O ML automatizado para imagens dá suporte às políticas de término antecipado abaixo por meio do parâmetro early_termination_policy. Se nenhuma política de encerramento for especificada, todas as configurações serão executadas até a conclusão.
Saiba mais sobre como configurar a política de encerramento antecipado para a varredura de hiperparâmetros.
Recursos para a varredura
Você pode controlar os recursos gastos em sua varredura de hiperparâmetros especificando iterations e max_concurrent_iterations para a varredura.
| Parâmetro | Detalhe |
|---|---|
iterations |
Parâmetro obrigatório para o número máximo de configurações a serem varridas. Precisa ser um número inteiro entre 1 e 1000. Ao explorar apenas os hiperparâmetros padrão para determinado algoritmo de modelo, defina esse parâmetro como 1. |
max_concurrent_iterations |
Número máximo de execuções que podem ser feitas simultaneamente. Se não for especificado, todas as execuções são iniciadas em paralelo. Se especificado, o tempo limite deve ser um número inteiro entre 1 e 100. OBSERVAÇÃO: o número de execuções simultâneas está ligado aos recursos disponíveis no destino de computação especificado. Verifique se o destino de computação tem os recursos disponíveis para a simultaneidade desejada. |
Observação
Para obter um exemplo de configuração de varredura completa, consulte este tutorial.
Argumentos
Você pode transmitir configurações ou parâmetros fixos que não são alterados durante a varredura do espaço de parâmetro como argumentos. Os argumentos são passados em pares nome-valor e o nome deve ser prefixado por um traço duplo.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
Treinamento incremental (opcional)
Após concluir a execução do treinamento, você terá a opção de treinar ainda mais o modelo carregando o ponto de verificação do modelo treinado. Você pode usar o mesmo conjunto de dados ou um diferente para treinamento incremental.
Há duas opções disponíveis para treinamento incremental. Você pode,
- Passar o ID de execução do qual você deseja carregar o ponto de verificação.
- Passar os pontos de verificação por meio de um FileDataset.
Passar o ponto de verificação via ID de execução
Para localizar a ID de execução do modelo desejado, você pode usar o código a seguir.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
Para passar um ponto de verificação por meio do ID de execução, é necessário usar o parâmetro checkpoint_run_id.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Passar o ponto de verificação via FileDataset
Para passar um ponto de verificação por meio de um FileDataset, você precisa usar os parâmetros checkpoint_dataset_id e checkpoint_filename.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
Enviar a execução
Quando o objeto AutoMLImageConfig estiver pronto, você poderá enviar o experimento.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
Métricas de avaliação e saídas
As execuções de treinamento do ML automatizado geram arquivos de modelo de saída, métricas de avaliação, logs e artefatos de implantação, como o arquivo de pontuação e o arquivo de ambiente, que podem ser exibidos na guia de saídas e logs e métricas das execuções filhas.
Dica
Confira como navegar até os resultados do trabalho na seção Exibir resultados da execução.
Para obter definições e exemplos dos gráficos e métricas de desempenho fornecidos para cada execução, confira Avaliar resultados do experimento de machine learning automatizado
Registro e implantação do modelo
Quando a execução for concluída, você poderá registrar o modelo que foi criado da melhor execução (configuração que resultou na melhor métrica primária)
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
Depois de registrar o modelo que você deseja usar, será possível implantá-lo como um serviço Web nas ACI (Instâncias de Contêiner do Azure) ou no AKS (Serviço de Kubernetes do Azure). As ACIs são a opção perfeita para testar as implantações; já o AKS é mais adequado para uso em produção em grande escala.
Este exemplo implanta o modelo como um serviço Web no AKS. Para implantar no AKS, primeiro crie um cluster de computação do AKS ou use um cluster do AKS existente. Você pode usar SKUs de VM com GPU ou CPU como cluster de implantação.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
Em seguida, defina a configuração de inferência, que descreve como configurar o serviço Web que contém seu modelo. Você pode usar o script de pontuação e o ambiente da execução de treinamento em sua configuração de inferência.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
Em seguida, você pode implantar o modelo como um serviço Web do AKS.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
Como alternativa, você pode implantar o modelo da interface do usuário do Estúdio do Azure Machine Learning. Navegue até o modelo que você deseja implantar na guia Modelos da execução do ML automatizado e selecione Implantar.
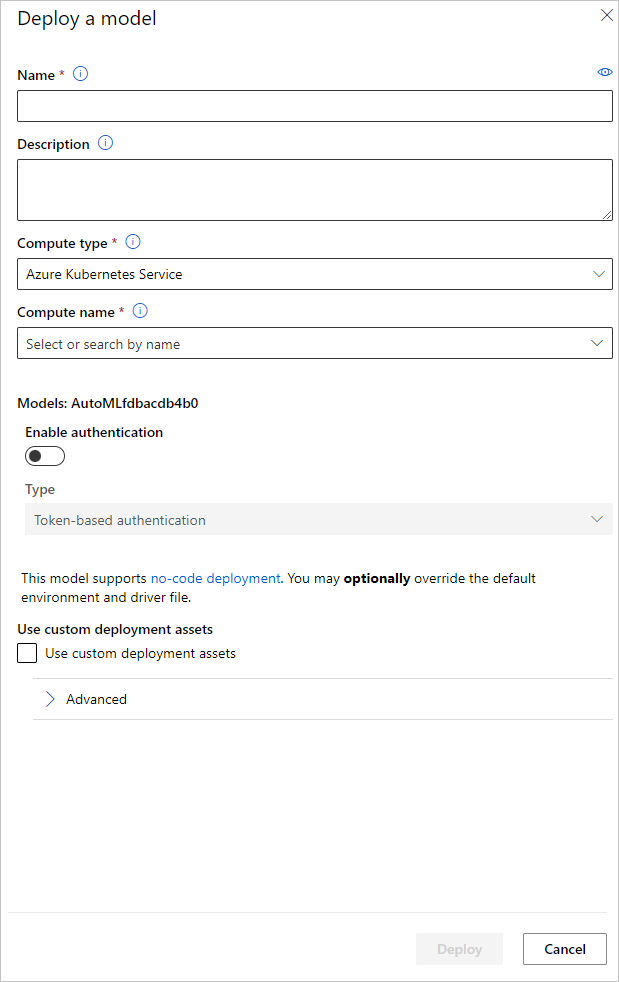
Você pode configurar o nome do ponto de extremidade de implantação do modelo e o cluster inferência a serem usados na implantação do modelo no painel Implantar um modelo.
Atualizar configuração de inferência
Na etapa anterior, baixamos o arquivo de pontuação outputs/scoring_file_v_1_0_0.py do melhor modelo em um arquivo local score.py e o usamos para criar um objeto InferenceConfig. Esse script pode ser modificado para alterar as configurações de inferência específicas do modelo, se necessário, depois de ele ter sido baixado e antes de criar o InferenceConfig. Por exemplo, esta é a seção de código que inicializa o modelo no arquivo de pontuação:
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
Cada uma das tarefas (e alguns modelos) tem um conjunto de parâmetros no dicionário model_settings. Por padrão, usamos os mesmos valores dos parâmetros que foram usados durante o treinamento e a validação. Dependendo do comportamento que buscamos ao usar o modelo de inferência, podemos alterar esses parâmetros. Abaixo, você pode encontrar uma lista de parâmetros para cada tipo de tarefa e modelo.
| Tarefa | Nome do parâmetro | Padrão |
|---|---|---|
| Classificação de imagem (várias classes e vários rótulos) | valid_resize_sizevalid_crop_size |
256 224 |
| Detecção de objetos | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0,5 100 |
Detecção de objetos usando yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 média 0,1 0,5 |
| Segmentação de instâncias | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0,5 100 0,5 100 Falso JPG |
Para obter uma descrição detalhada sobre hiperparâmetros específicos de tarefas, consulte Hiperparâmetros para tarefas de pesquisa visual computacional em machine learning automatizado.
Se você quiser usar blocos e desejar controlar o comportamento dos blocos, os seguintes parâmetros estarão disponíveis: tile_grid_size, tile_overlap_ratio e tile_predictions_nms_thresh. Para obter mais detalhes sobre esses parâmetros, confira Treinar um modelo de detecção de objetos pequenos usando o AutoML.
Blocos de anotações de exemplo
Examine exemplos de código detalhados e casos de uso no Repositório do notebook do GitHub para obter amostras de machine learning automatizado. Encontre nas pastas com o prefixo "image-" exemplos específicos para criar modelos de pesquisa visual computacional.