Treine os modelos TensorFlow em escala com o Azure Machine Learning
APLICA-SE A:  SDK do Python azure-ai-ml v2 (atual)
SDK do Python azure-ai-ml v2 (atual)
Neste artigo, aprenda como executar scripts de treinamento do TensorFlow em escala empresarial usando o SDK do Python do Azure Machine Learning v2.
O código de exemplo neste artigo treina um modelo do TensorFlow para classificar dígitos manuscritos usando uma DNN (rede neural profunda), registrar o modelo e implantá-lo em um ponto de extremidade online.
Se você está desenvolvendo um modelo do TensorFlow do zero ou está usando um modelo existente na nuvem, você pode usar o Azure Machine Learning para escalar horizontalmente execuções de treinamento de open-source usando recursos de computação em nuvem elásticos. Você pode criar, implantar, versionar e monitorar modelos de nível de produção com o Azure Machine Learning.
Pré-requisitos
Para se beneficiar deste artigo, você precisará:
- Acesse uma assinatura do Azure. Se você ainda não tem, crie uma conta gratuita.
- Execute o código nesse artigo usando uma instância de computação do Azure Machine Learning ou em seu próprio Jupyter Notebook.
- Instância de computação do Azure Machine Learning, sem necessidade de fazer downloads ou instalação
- Complete o tutorial Criar recursos para começar para criar um servidor de notebook dedicado pré-carregado com o SDK e o repositório de exemplo.
- Na pasta de aprendizado profundo de exemplos no servidor do notebook, localize um notebook completo e expandido navegando até este diretório: v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- Seu servidor do Jupyter Notebook
- Instância de computação do Azure Machine Learning, sem necessidade de fazer downloads ou instalação
- Baixe os seguintes arquivos:
- script de treinamento tf_mnist.py
- script de pontuação score.py
- arquivo de solicitação de amostra sample-request.json
Você também pode encontrar uma versão completa do Jupyter Notebook deste guia na página de exemplos do GitHub.
Antes de executar o código neste artigo para criar um cluster de GPU, você precisará solicitar um aumento de cota para seu workspace.
Configurar o trabalho
Esta seção configura o trabalho para treinamento carregando os pacotes necessários do Python, conectando-se a um workspace, criando um recurso de computação para executar um trabalho de comando e criando um ambiente para executar o trabalho.
Conectar-se ao workspace
Primeiro, será necessário se conectar ao Workspace do Azure Machine Learning. O workspace do Azure Machine Learning é o recurso de nível superior para o serviço. Ele fornece um local centralizado para trabalhar com todos os artefatos que você criar ao usar o Azure Machine Learning.
Estamos usando DefaultAzureCredential para obter acesso ao workspace. Esta credencial deve poder lidar com a maioria dos cenários de autenticação do SDK do Azure.
Se DefaultAzureCredential não funcionar para você, consulte azure-identity reference documentation ou Set up authentication para obter mais credenciais disponíveis.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Se você preferir usar um navegador para entrar e se autenticar, remova a marca de comentário o código a seguir e use-o.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Em seguida, obtenha um identificador para o workspace fornecendo sua ID de Assinatura, o nome do Grupo de Recursos e o nome do workspace. Para localizar esses parâmetros:
- Procure o nome do workspace no canto superior direito da barra de ferramentas do Estúdio do Azure Machine Learning.
- Selecione o nome do workspace para exibir o Grupo de Recursos e a ID da Assinatura.
- Copie os valores do Grupo de Recursos e da ID da Assinatura no código.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)O resultado da execução desse script é um identificador de workspace que você usa para gerenciar outros recursos e trabalhos.
Observação
- A criação do
MLClientnão conectará o cliente ao workspace. A inicialização do cliente é lenta e aguardará pela primeira vez que precisar fazer uma chamada. Neste artigo, isso ocorrerá durante a criação da computação.
Criar um recurso de computação
O Azure Machine Learning precisa de um recurso de computação para executar um trabalho. Esse recurso pode ser computadores com um ou vários nós com o SO Linux ou Windows ou uma malha de computação específica como o Spark.
No script de exemplo a seguir, provisionamos um Linux compute cluster. Você pode ver na página Azure Machine Learning pricing a lista completa de tamanhos e preços de VM. Como precisamos ter um cluster de GPU para este exemplo, vamos escolher um modelo STANDARD_NC6 e criar uma computação do Azure Machine Learning.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Criar um ambiente de trabalho
Você precisa ter um ambiente para executar um trabalho do Azure Machine Learning. Um ambiente do Azure Machine Learning encapsula as dependências (como bibliotecas e runtime de software) necessárias para executar o script de treinamento de machine learning no recurso de computação. Esse ambiente é semelhante a um ambiente do Python no computador local.
O Azure Machine Learning permite que você use um ambiente coletado (ou pronto), útil para cenários comuns de treinamento e inferência, ou crie um ambiente personalizado usando uma imagem do Docker ou uma configuração do Conda.
Neste artigo, você reutiliza o ambiente AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu coletado do Azure Machine Learning. Use a versão mais recente deste ambiente usando a diretiva @latest.
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"Configurar e enviar trabalhos de treinamento
Nesta seção, começamos introduzindo os dados para treinamento. Em seguida, abordamos como executar um trabalho de treinamento usando um script de treinamento fornecido. Você aprende a criar o trabalho de treinamento configurando o comando para executar o script de treinamento. Em seguida, você envia o trabalho de treinamento para execução no Azure Machine Learning.
Obter os dados de treinamento
Você usará dados do banco de dados do MNIST (Modified National Institute of Standards and Technology) de dígitos manuscritos. Esses dados são provenientes do site de Yan LeCun e armazenados em uma conta de armazenamento do Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Para obter mais informações sobre o conjunto de dados do MNIST, acesse o site de Yan LeCun.
Preparar o script de treinamento
Neste artigo, fornecemos o script de treinamento tf_mnist.py. Na prática, você deve conseguir usar qualquer script de treinamento personalizado no estado em que se encontra e executá-lo com o Azure Machine Learning sem precisar modificar o código.
O script de treinamento fornecido faz o seguinte:
- identifica o pré-processamento de dados, dividindo os dados em dados de teste e de treinamento;
- treina um modelo, usando os dados; e
- retorna o modelo de saída.
Durante a execução do pipeline, você usa o MLFlow para registrar os parâmetros e as métricas em log. Para saber como habilitar o acompanhamento do MLFlow, consulte Acompanhar experimentos e modelos de ML com o MLflow.
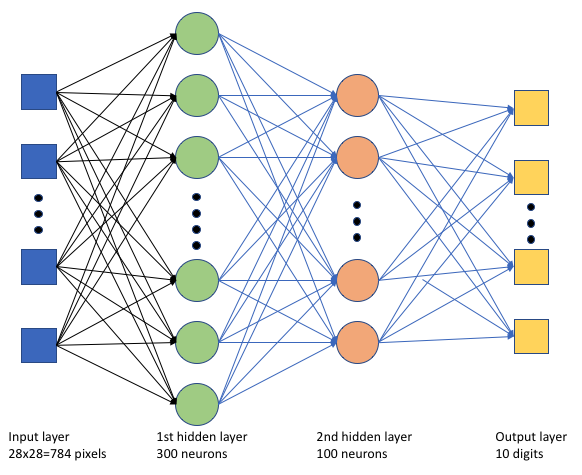
No script de treinamento tf_mnist.py, criamos uma DNN (rede neural profunda) simples. Esta DNN tem:
- Uma camada de entrada com 28 * 28 = 784 neurônios. Cada neurônio representa um pixel de imagem.
- Duas camadas ocultas. A primeira camada oculta tem 300 neurônios e a segunda camada oculta tem 100 neurônios.
- Uma camada de saída com 10 neurônios. Cada neurônio representa um rótulo direcionado de 0 a 9.
Compilar o trabalho de treinamento
Agora que você tem todos os ativos necessários para executar o trabalho, é hora de compilá-lo usando o SDK v2 do Python para o Azure Machine Learning. Neste exemplo, estamos criando um command.
Um command do Azure Machine Learning é um recurso que especifica todos os detalhes necessários para executar o código de treinamento na nuvem. Esses detalhes incluem as entradas e saídas, o tipo de hardware a ser usado, o software a ser instalado e como executar o código. command contém informações para executar um único comando.
Configurar o comando
Você usa o uso geral command para executar o script de treinamento e executar as tarefas desejadas. Crie um objeto Command para especificar os detalhes de configuração do trabalho de treinamento.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)As entradas para esse comando incluem a localização de dados, o tamanho do lote, o número de neurônios na primeira e segunda camada e a taxa de aprendizagem. Observe que passamos no caminho da Web diretamente como uma entrada.
Nos valores dos parâmetros:
- forneça o cluster de computação
gpu_compute_target = "gpu-cluster"que você criou para executar este comando; - forneça o ambiente coletado
curated_env_nameque você declarou anteriormente; - configure a ação da linha de comando em si— nesse caso, o comando é
python tf_mnist.py. É possível acessar as entradas e saídas no comando por meio da notação${{ ... }}; e - configure metadados como o nome de exibição e o nome do experimento; onde um experimento é um contêiner para todas as iterações feitas em um determinado projeto. Todos os trabalhos enviados com o mesmo nome de experimento serão listados um ao lado do outro no Estúdio do Azure Machine Learning.
- forneça o cluster de computação
Neste exemplo, você usará
UserIdentitypara executar o comando. O uso de uma identidade de usuário significa que o comando usará sua identidade para executar o trabalho e acessar os dados do blob.
Enviar o trabalho
Agora é hora de enviar o trabalho a ser executado no Azure Machine Learning. Desta vez, você usará create_or_update em ml_client.jobs.
ml_client.jobs.create_or_update(job)Depois de concluído, o trabalho vai registrar um modelo no seu workspace (como resultado do treinamento) e gerar um link para exibir o trabalho no Estúdio do Azure Machine Learning.
Aviso
O Azure Machine Learning executa scripts de treinamento copiando o diretório de origem inteiro. Se você tiver dados confidenciais que não quer carregar, use um arquivo .ignore ou não o inclua no diretório de origem.
O que acontece durante o trabalho
Conforme o trabalho é executado, ele passa pelos seguintes estágios:
Preparação: uma imagem Docker é criada de acordo com o ambiente definido. A imagem é carregada no registro de contêiner do workspace e armazenada em cache para execuções posteriores. Os logs também são transmitidos para o histórico do trabalho e podem ser exibidos para monitorar o progresso. Mas se um ambiente coletado for especificado, a imagem armazenada em cache desse ambiente coletado é usada.
Dimensionamento: o cluster tenta escalar verticalmente se exigir mais nós para a execução, além do que está disponível no momento.
Execução: todos os scripts na pasta de scripts src são carregados para o destino de computação, os armazenamentos de dados são montados ou copiados e o script é executado. As saídas do stdout e da pasta ./logs são transmitidas para o histórico do trabalho e podem ser usadas para monitorar o trabalho.
Ajustar hiperparâmetros do modelo
Agora que você viu como fazer uma execução de treinamento do TensorFlow usando o SDK, vamos tentar melhorar ainda mais a precisão do modelo. Você pode ajustar e otimizar os hiperparâmetros do modelo usando as funcionalidades sweep do Azure Machine Learning.
Para ajustar os hiperparâmetros do modelo, defina o espaço de parâmetro a ser pesquisado durante o treinamento. Isso deve ser feito substituindo alguns parâmetros (batch_size, first_layer_neurons, second_layer_neurons e learning_rate) passados para o trabalho de treinamento com entradas especiais do pacote azure.ml.sweep.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Em seguida, você configura a varredura no trabalho de comando, usando alguns parâmetros específicos de varredura, como a métrica primária a ser observado e o algoritmo de amostragem a ser usado.
No código a seguir, usamos a amostragem aleatória para tentar diferentes conjuntos de configuração de hiperparâmetros na tentativa de maximizar nossa métrica primária, validation_acc.
Também definimos uma política de encerramento antecipado, BanditPolicy. Essa política opera verificando o trabalho a cada duas iterações. Se a métrica primária validation_acc ficar fora do intervalo superior de 10%, o Azure Machine Learning encerrará o trabalho. Isso faz com que o modelo não precise continuar explorando hiperparâmetros que não mostram uma promessa de ajudar a alcançar a métrica de destino.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)Agora, você pode enviar este trabalho como antes. Desta vez, você estará executando um trabalho de varredura que limpa seu trabalho de treinamento.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)Você pode monitorar o trabalho usando o link de interface do usuário do estúdio apresentado durante a execução do trabalho.
Localizar e registrar o melhor modelo
Depois que todas as execuções forem concluídas, você poderá encontrar a execução que produziu o modelo com a maior precisão.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)Em seguida, você pode registrar esse modelo.
registered_model = ml_client.models.create_or_update(model=model)Implantar o modelo como um ponto de extremidade online
Depois de registrar o modelo, você pode implantá-lo como um ponto de extremidade online, ou seja, como um serviço Web na nuvem do Azure.
Para implantar um serviço de aprendizado de máquina, geralmente você precisa:
- Os ativos do modelo que você deseja implantar. Esses ativos incluem o arquivo e os metadados do modelo que você já registrou em seu trabalho de treinamento.
- Alguns códigos a serem executados como um serviço. O código executa o modelo em uma determinada solicitação de entrada (um script de entrada). Este script de entrada recebe os dados enviados para um serviço Web implantado e os transmite ao modelo. Depois que o modelo processa os dados, o script retorna a resposta do modelo ao cliente. O script é específico para seu modelo e deve compreender os dados que o modelo espera e retorna. Quando você usa um modelo do MLFlow, o Azure Machine Learning cria esse script automaticamente para você.
Para obter mais informações sobre a implantação, confira Implante e pontue um modelo de machine learning com um ponto de extremidade online gerenciado usando o SDK do Python v2.
Criar um ponto de extremidade online
Como uma primeira etapa para implantar seu modelo, você precisa criar um ponto de extremidade online. O nome do ponto de extremidade deve ser exclusivo em toda a região do Azure. Para este artigo, você cria um nome exclusivo usando um UUID (identificador exclusivo universal).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Depois de criar o ponto de extremidade, você pode recuperá-lo da seguinte forma:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Implantar o modelo ao ponto de extremidade
Depois de criar o ponto de extremidade, é possível implantar o modelo com o script de entrada. Um ponto de extremidade pode ter várias implantações. Usando as regras, o ponto de extremidade pode direcionar o tráfego para essas implantações.
No código a seguir, você cria uma única implantação que manipula 100% do tráfego de entrada. Usamos um nome de cor arbitrário (tff-blue) para a implantação. Você também pode usar qualquer outro nome, como tff-green ou tff-red para a implantação. O código para implantar o modelo no ponto de extremidade faz o seguinte:
- implanta a melhor versão do modelo que você registrou anteriormente;
- pontua o modelo, usando o arquivo
score.py; e - usa o mesmo ambiente coletado (que você declarou anteriormente) para executar a inferência.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Observação
Essa implantação demora um pouco para ser concluída.
Testar a implantação com uma consulta de exemplo
Depois de implantar o modelo no ponto de extremidade, é possível prever a saída do modelo implantado, usando o método invoke no ponto de extremidade. Para executar a inferência, use o arquivo de solicitação de exemplo sample-request.json da pasta solicitação.
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)Em seguida, é possível imprimir as previsões retornadas e plotá-las junto com as imagens de entrada. Use a fonte vermelha e a imagem invertida (branco sobre preto), para realçar as amostras classificadas incorretamente.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Observação
Uma vez que a precisão do modelo é alta, talvez seja necessário executar a célula algumas vezes, antes de ver uma amostra classificada incorretamente.
Limpar os recursos
Se você não usar o ponto de extremidade, exclua-o para parar de usar o recurso. Verifique se nenhuma outra implantação está usando o ponto de extremidade antes de excluí-lo.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Observação
Essa limpeza demora um pouco para ser concluída.
Próximas etapas
Neste artigo, você treinou e registrou um modelo do TensorFlow. Você também implantou o modelo em um ponto de extremidade online. Consulte estes outros artigos para saber mais sobre Azure Machine Learning.