Acompanhe experimentos de aprendizado de máquina do Azure Databricks com MLflow e Azure Machine Learning
O MLflow é uma biblioteca de open-source para gerenciar o ciclo de vida dos experimentos de aprendizado de máquina. Você pode usar o MLflow para integrar o Azure Databricks ao Azure Machine Learning para garantir que você obtenha o melhor dos dois produtos.
Neste artigo, você aprende:
- As bibliotecas exigidas necessárias para usar o MLflow com o Azure Databricks e o Azure Machine Learning.
- Como acompanhar execuções do Azure Databricks com o MLflow no Azure Machine Learning.
- Como registrar modelos com o MLflow para registrá-los no Azure Machine Learning.
- Como implantar e consumir modelos registrados no Azure Machine Learning.
Pré-requisitos
- O pacote
azureml-mlflow, que lida com a conectividade com o Azure Machine Learning, incluindo a autenticação. - Um cluster e workspace do Azure Databricks.
- Um Workspace do Azure Machine Learning.
Veja quais permissões de acesso são necessárias para executar suas operações de MLflow com seu workspace.
Blocos de anotações de exemplo
O repositório Treinando modelos no Azure Databricks e implantando-os no Azure Machine Learning demonstra como treinar modelos no Azure Databricks e implantá-los no Azure Machine Learning. Ele também descreve como acompanhar os experimentos e modelos com a instância do MLflow no Azure Databricks. Ele descreve como usar o Azure Machine Learning para implantação.
Instalar bibliotecas
Para instalar as bibliotecas em seu cluster:
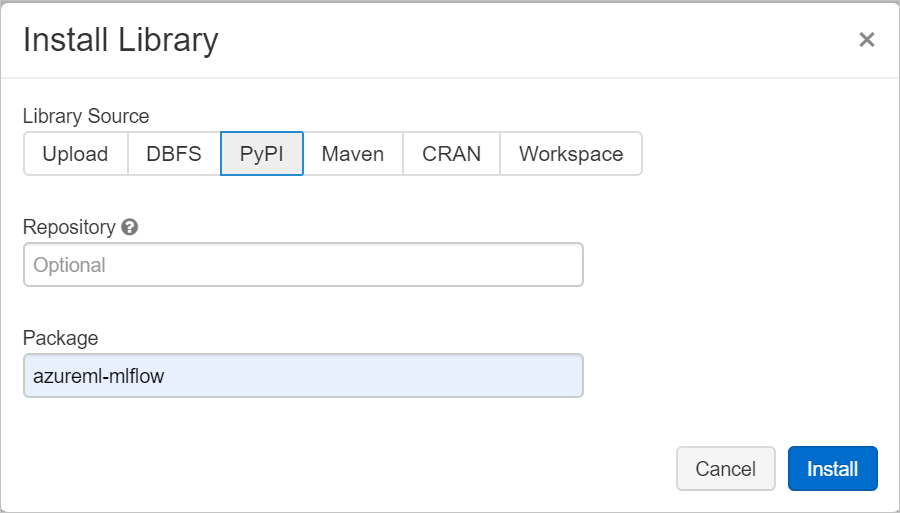
Navegue até a guia Bibliotecas e selecione Instalar Novo.

No campo Pacote, digite azureml-mlflow e selecione Instalar. Repita essa etapa conforme necessário para instalar outros pacotes em seu cluster para seu experimento.
Acompanhar as execuções do Azure Databricks com o MLflow
Você pode configurar o Azure Databricks para acompanhar experimentos usando o MLflow de duas maneiras:
- Rastrear nos workspaces do Azure Databricks e do Azure Machine Learning (rastreamento duplo)
- Rastrear exclusivamente no Azure Machine Learning
Por padrão, quando você vincula seu workspace do Azure Databricks, o acompanhamento duplo é configurado para você.
Acompanhamento duplo no Azure Databricks e no Azure Machine Learning
Vincular o workspace do Azure Databricks ao workspace do Azure Machine Learning permite que você acompanhe os dados do experimento no workspace do Azure Machine Learning e no workspace do Azure Databricks ao mesmo tempo. Essa configuração é chamada Acompanhamento duplo.
Não há suporte para o acompanhamento duplo em um workspace do Azure Machine Learning habilitado para link privado. Configure o rastreamento exclusivo com seu workspace do Azure Machine Learning.
No momento, não há suporte para o rastreamento duplo no Microsoft Azure operado pela 21Vianet. Configure o rastreamento exclusivo com seu workspace do Azure Machine Learning.
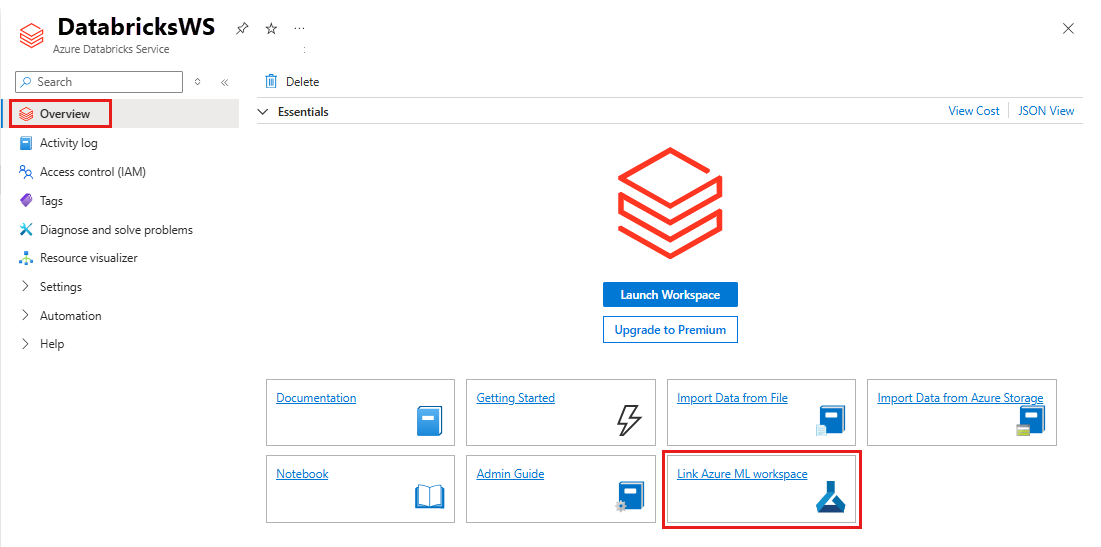
Para vincular seu workspace do Azure Databricks a um workspace do Azure Machine Learning novo ou existente:
Entre no portal do Azure.
Navegue até a página Visão geral do seu workspace do Azure Databricks.
Selecione Vincular workspace do Azure Machine Learning.

Depois que você vincular o workspace do Azure Databricks ao workspace do Azure Machine Learning, o acompanhamento do MLflow será automaticamente rastreado nos seguintes locais:
- O workspace vinculado do Azure Machine Learning.
- Seu workspace do Azure Databricks original.
Você pode usar o MLflow no Azure Databricks da mesma forma que está acostumado. O exemplo a seguir define o nome do experimento como de costume no Azure Databricks e começa a registrar em log alguns parâmetros.
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Observação
Ao contrário do acompanhamento, os registros de modelos não dão suporte ao registro de modelos ao mesmo tempo no Azure Machine Learning e no Azure Databricks. Para mais informações, consulte Registrar modelos no registro com o MLflow.
Acompanhar exclusivamente no workspace do Azure Machine Learning
Se preferir gerenciar seus experimentos acompanhados em um local centralizado, você poderá definir o acompanhamento de MLflow para acompanhar somente em seu workspace do Azure Machine Learning. Essa configuração tem a vantagem de habilitar o caminho mais fácil para a implantação usando Azure Machine Learning opções de implantação.
Aviso
Para o workspace do Azure Machine Learning habilitado para o link privado, você precisa implantar o Azure Databricks em sua rede (injeção de VNet) para garantir a conectividade adequada.
Configure o URI de acompanhamento do MLflow para apontar exclusivamente para o Azure Machine Learning, conforme mostrado no exemplo a seguir:
Configurar o URI de acompanhamento
Obtenha o URI de acompanhamento para seu espaço de trabalho.
APLICA-SE A:
 Extensão de ML da CLI do Azurev2 (atual)
Extensão de ML da CLI do Azurev2 (atual)Entrar e configurar seu espaço de trabalho.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Você pode obter o URI de acompanhamento usando o comando
az ml workspace.az ml workspace show --query mlflow_tracking_uri
Configurar o URI de acompanhamento.
O método
set_tracking_uri()aponta o URI de acompanhamento do MLflow para esse URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
Dica
Ao trabalhar com ambientes compartilhados, como um cluster do Azure Databricks, cluster do Azure Synapse Analytics ou similar, você pode definir a variável de ambiente MLFLOW_TRACKING_URI no nível do cluster. Essa abordagem permite que você configure automaticamente o URI de acompanhamento do MLflow para apontar para o Azure Machine Learning para todas as sessões executadas no cluster, em vez de fazer isso por sessão.
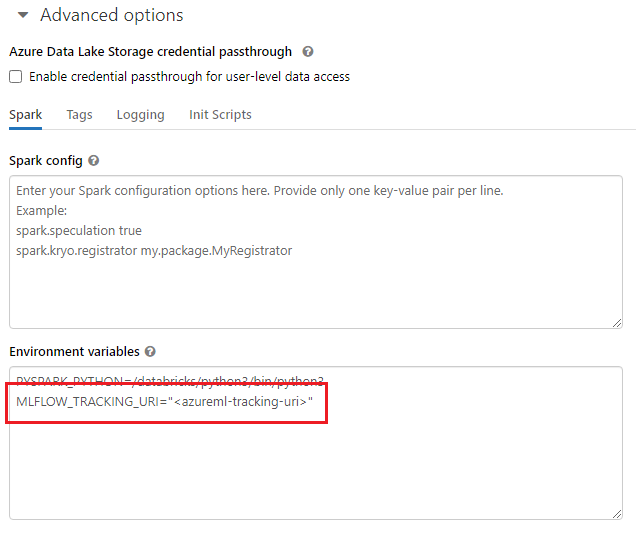
Depois de configurar a variável de ambiente, qualquer experimento em execução nesse cluster será acompanhado no Azure Machine Learning.
Configurar autenticação
Depois de configurar o acompanhamento, configure como autenticar o espaço de trabalho associado. Por padrão, o plug-in do Azure Machine Learning para o MLflow abre um navegador para solicitar credenciais de forma interativa. Para obter outras maneiras de configurar a autenticação para o MLflow nos workspaces do Azure Machine Learning, confira Configurar o MLflow para o Azure Machine Learning: Configurar autenticação.
Para trabalhos interativos em que há um usuário conectado à sessão, você pode contar com a Autenticação Interativa e, portanto, nenhuma ação adicional é necessária.
Aviso
A autenticação por navegador interativo bloqueia a execução do código quando solicita credenciais. Essa abordagem não é adequada para autenticação em ambientes não assistidos, como trabalhos de treinamento. Recomendamos que você configure um modo de autenticação diferente.
Para cenários em que a execução não assistida é necessária, você precisa configurar uma entidade de serviço para se comunicar com o Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Dica
Ao trabalhar em ambientes compartilhados, recomendamos que você configure essas variáveis de ambiente na computação. Como melhor prática, gerencie-os como segredos em uma instância do Azure Key Vault.
Por exemplo, no Azure Databricks, você pode usar segredos em variáveis de ambiente da seguinte maneira na configuração do cluster: AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Para obter mais informações sobre como implementar essa abordagem no Azure Databricks, confira Referenciar um segredo em uma variável de ambiente ou consulte a documentação da sua plataforma.
Experimento de nome no Azure Machine Learning
Quando você configura o MLflow para acompanhar exclusivamente experimentos no workspace do Azure Machine Learning, a convenção de nomenclatura de experimentos deve seguir a convenção usada pelo Azure Machine Learning. No Azure Databricks, os experimentos são nomeados com o caminho para onde o experimento é salvo, por exemplo, /Users/alice@contoso.com/iris-classifier. No entanto, no Azure Machine Learning, você fornece o nome do experimento diretamente. O mesmo experimento seria nomeado iris-classifier diretamente.
mlflow.set_experiment(experiment_name="experiment-name")
Rastrear parâmetros, métricas e artefatos
Após essa configuração, você pode usar o MLflow no Azure Databricks da mesma forma que está acostumado. Para mais informações, confira Registrar e exibir métricas e arquivos de log.
Registrar modelos com o MLflow
Depois que o modelo é treinado, você pode registrá-lo no servidor de acompanhamento de back-end com o método mlflow.<model_flavor>.log_model(). <model_flavor> refere-se à estrutura associada ao modelo. Saiba quais são os tipos de modelo com suporte.
No exemplo a seguir, um modelo criado com a biblioteca Spark MLLib está sendo registrado.
mlflow.spark.log_model(model, artifact_path = "model")
A variante spark não corresponde ao fato de você estar treinando um modelo em um cluster do Spark. Em vez disso, ele decorre da estrutura de treinamento utilizada. Você pode treinar um modelo usando o TensorFlow com o Spark. A variante a ser usada seria tensorflow.
Os modelos são registrados dentro da execução que está sendo controlada. Esse fato significa que os modelos estão disponíveis no Azure Databricks e no Azure Machine Learning (padrão) ou exclusivamente no Azure Machine Learning se você configurou o URI de acompanhamento para apontar para ele.
Importante
O parâmetro registered_model_name não foi especificado. Para obter mais informações sobre esse parâmetro e o registro, confira Registrar modelos no registro com o MLflow.
Registrar modelos no registro com o MLflow
Ao contrário do acompanhamento, os registros de modelos não podem operar ao mesmo tempo no Azure Databricks e no Azure Machine Learning. Eles precisam usar um ou outro. Por padrão, os registros de modelos usam o workspace do Azure Databricks. Se você optar por configurar o acompanhamento do MLflow para acompanhar apenas no seu workspace do Azure Machine Learning, o registro de modelos será o workspace do Azure Machine Learning.
Se você usar a configuração padrão, o código a seguir registrará um modelo dentro das execuções correspondentes do Azure Databricks e do Azure Machine Learning, mas o registrará somente no Azure Databricks.
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- Se um modelo registrado com o nome não existir, o método registrará um novo modelo, criará a versão 1 e retornará um objeto MLflow
ModelVersion. - Se um modelo registrado com o nome já existir, o método criará uma versão do modelo e retornará o objeto de versão.
Usar o registro do Azure Machine Learning com o MLflow
Se quiser usar o Registro de Modelo de Azure Machine Learning em vez do Azure Databricks, recomendamos que você configure o acompanhamento do MLflow para acompanhar somente no workspace do Azure Machine Learning. Essa abordagem elimina a ambiguidade de onde os modelos estão sendo registrados e simplifica a configuração.
Se quiser continuar usando os recursos de acompanhamento duplo, mas registrar modelos no Azure Machine Learning, você pode instruir o MLflow a usar o Azure Machine Learning para registros de modelos configurando o URI do Registro de Modelo do MLflow. Este URI tem o mesmo formato e valor que o MLflow que acompanha o URI.
mlflow.set_registry_uri(azureml_mlflow_uri)
Observação
O valor de azureml_mlflow_uri foi obtido da mesma forma descrita em Configurar o acompanhamento do MLflow para acompanhar somente em seu workspace do Azure Machine Learning.
Para um exemplo completo desse cenário, confira Treinando modelos no Azure Databricks e implantando-os no Azure Machine Learning.
Implantar e consumir modelos registrados no Azure Machine Learning
Os modelos registrados no serviço do Azure Machine Learning usando o MLflow podem ser consumidos como:
- Um ponto de extremidade do Azure Machine Learning (em tempo real e em lote). Essa implantação permite que você use os recursos de implantação do Azure Machine Learning para inferência em tempo real e em lote nas instâncias de contêiner do Azure, no Kubernetes do Azure ou nos pontos de extremidade de inferência gerenciados.
- Objetos de modelo MLFlow ou funções definidas pelo usuário (UDFs) do Pandas, que podem ser usados em notebooks do Azure Databricks em pipelines de streaming ou em lote.
Implantar modelos para ponto de extremidade do Azure Machine Learning
Você pode usar o plug-in azureml-mlflow para implantar um modelo no seu workspace do Azure Machine Learning. Para obter mais informações sobre como implantar modelos em diferentes destinos Como implantar modelos do MLflow.
Importante
Os modelos precisam ser registrados no registro Azure Machine Learning para implantá-los. Se seus modelos estiverem registrados na instância do MLflow dentro do Azure Databricks, registre-os novamente no Azure Machine Learning. Para mais informações, confira Treinando modelos no Azure Databricks e implantando-os no Azure Machine Learning
Implantar modelos no Azure Databricks para pontuação em lote usando UDFs
Você pode escolher clusters do Azure Databricks para pontuação de lote. Ao usar o Mlflow, você pode resolver qualquer modelo do registro ao qual está conectado. Normalmente, você usa um dos seguintes métodos:
- Se o seu modelo foi treinado e criado com bibliotecas do Spark, como
MLLib, usemlflow.pyfunc.spark_udfpara carregar um modelo e usá-lo como um UDF do Spark Pandas para pontuar novos dados. - Se o modelo não foi treinado ou criado com bibliotecas Spark, use
mlflow.pyfunc.load_modeloumlflow.<flavor>.load_modelpara carregar o modelo no driver de cluster. Você precisa orquestrar qualquer paralelização ou distribuição de trabalho que deseja que ocorra no cluster. O MLflow não instala nenhuma biblioteca que seu modelo precise para ser executado. Essas bibliotecas precisam ser instaladas no cluster antes de executá-las.
O exemplo a seguir mostra como carregar um modelo do registro chamado uci-heart-classifier e utilizá-lo como uma UDF do Spark Pandas para pontuar novos dados.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Para obter mais maneiras de referenciar modelos do repositório, confira Carregando modelos do registro.
Depois que o modelo for carregado, você poderá usar esse comando para pontuar novos dados.
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Limpar os recursos
Se você quiser manter seu workspace do Azure Databricks, mas não precisar mais do workspace do Azure Machine Learning, poderá excluir o workspace do Azure Machine Learning. Essa ação causa a desvinculação do workspace do Azure Databricks e do workspace do Azure Machine Learning.
Se não planeja usar as métricas e os artefatos registrados no seu espaço de trabalho, exclua o grupo de recursos que contém a conta de armazenamento e o espaço de trabalho.
- No portal do Azure, pesquise Grupos de recursos. Em serviços, selecione Grupos de Recursos.
- Na lista Grupos de recursos, localize e selecione o grupo de recursos que você criou para abri-lo.
- Na página Visão geral, selecione Excluir grupo de recursos.
- Para verificar a exclusão, insira o nome do grupo de recursos.