Tutorial 1: desenvolver e registrar um conjunto de recursos com repositório de recursos gerenciados
Essa série de tutoriais mostra como os recursos integram perfeitamente todas as fases do ciclo de vida de aprendizado de máquina: prototipagem, treinamento e operacionalização.
Você pode usar o repositório de recursos gerenciados do Azure Machine Learning para descobrir, criar e operacionalizar recursos. O ciclo de vida do aprendizado de máquina inclui uma fase de prototipagem, na qual você experimenta vários recursos. Ele também envolve uma fase de operacionalização, em que os modelos são implantados e as etapas de inferência procuram dados de recursos. Os recursos servem como o tecido conectivo no ciclo de vida do aprendizado de máquina. Para saber mais sobre os conceitos básicos do repositório de recursos gerenciados, confira O que é o repositório de recursos gerenciados? e Entidades de nível superior no repositório de recursos gerenciados.
Este tutorial descreve como criar uma especificação de conjunto de recursos com transformações personalizadas. Em seguida, ele usa esse conjunto de recursos para gerar dados de treinamento, habilitar a materialização e executar um provisionamento. A materialização calcula os valores de recurso para uma janela de recurso e, em seguida, armazena esses valores em um armazenamento de materialização. Todas as consultas de recursos podem então usar aqueles valores do repositório de materialização.
Sem materialização, uma consulta de conjunto de recursos aplica as transformações à fonte em tempo real, para calcular os recursos antes de retornar os valores. Este processo funciona bem para a fase de prototipagem. No entanto, para operações de treinamento e inferência em um ambiente de produção, recomendamos que você materialize os recursos para ter maior confiabilidade e disponibilidade.
Este tutorial é a primeira parte da série de tutoriais do repositório de recursos gerenciados. Aqui, você aprenderá a:
- Criar um recurso mínimo do repositório de recursos.
- Desenvolver e testar localmente um conjunto de recursos com a capacidade de transformação de recursos.
- Registrar uma entidade de repositório de recursos no repositório de recursos.
- Registrar o conjunto de recursos que você desenvolveu com o repositório de recursos.
- Gerar um DataFrame de treinamento de exemplo usando os recursos que você criou.
- Habilitar a materialização offline nos conjuntos de recursos e fazer backup dos dados do recurso.
Essa série de tutoriais tem duas faixas:
- Faixa somente de SDK: usa apenas SDKs do Python. Escolha essa faixa para desenvolvimento e implantação puras baseadas em Python.
- Essa faixa de SDK e CLI usa o SDK do Python somente para desenvolvimento e teste de conjunto de recursos e usa a CLI para operações CRUD (criar, atualizar e excluir). Essa faixa é útil em cenários de CI/CD (integração contínua e entrega contínua) ou GitOps, em que a CLI/YAML é preferido.
Pré-requisitos
Antes de prosseguir com este tutorial, certifique-se de cumprir estes pré-requisitos:
Um Workspace do Azure Machine Learning. Para obter mais informações sobre a criação do workspace, confira o artigo Início Rápido: Criar recursos do workspace.
Em sua conta de usuário, a função Proprietário do grupo de recursos no qual o repositório de recursos é criado.
Se você escolher usar um novo grupo de recursos para esse tutorial, poderá excluir facilmente todos os recursos ao excluir o grupo de recursos.
Preparar o ambiente do notebook
Esse tutorial usa o notebook Spark do Azure Machine Learning para desenvolvimento.
No ambiente Estúdio do Azure Machine Learning, selecione Notebooks no painel esquerdo e, em seguida, selecione a guia Exemplos.
Navegue até o diretório featurestore_sample (selecione Exemplos>SDK v2>sdk>python>featurestore_sample) e selecione Clonar.

O painel Selecionar diretório de destino será aberto. Selecione o diretório Usuários, selecione seu nome de usuário e, por fim, selecione Clonar.

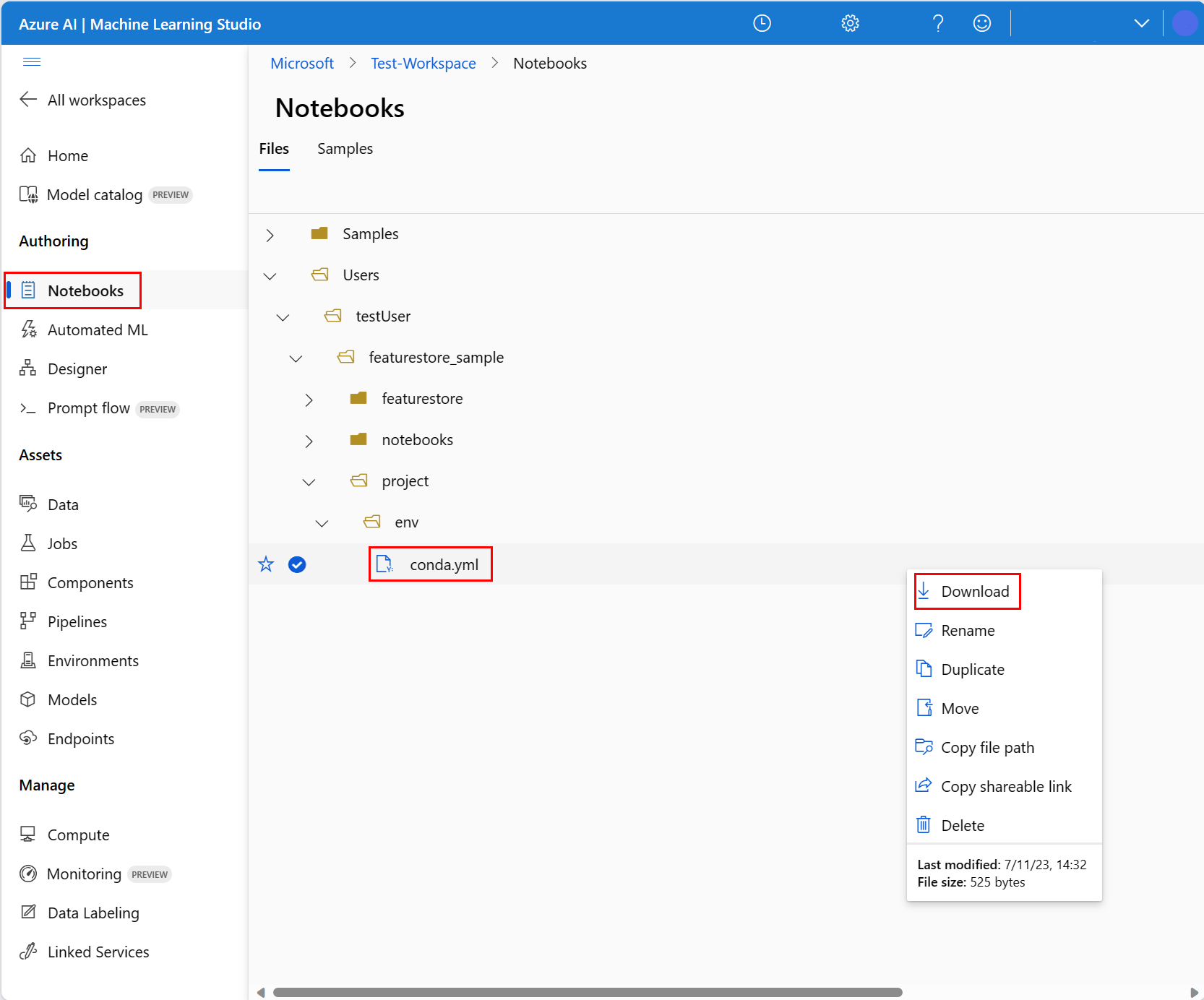
Para configurar o ambiente do notebook, você deve carregar o arquivo conda.yml:
- Selecione Notebooks no painel esquerdo e, em seguida, selecione a guia Arquivos.
- Navegue até o diretório env (selecione Usuários>your_user_name>featurestore_sample>project>env) e selecione o arquivo conda.yml.
- Selecione Baixar.
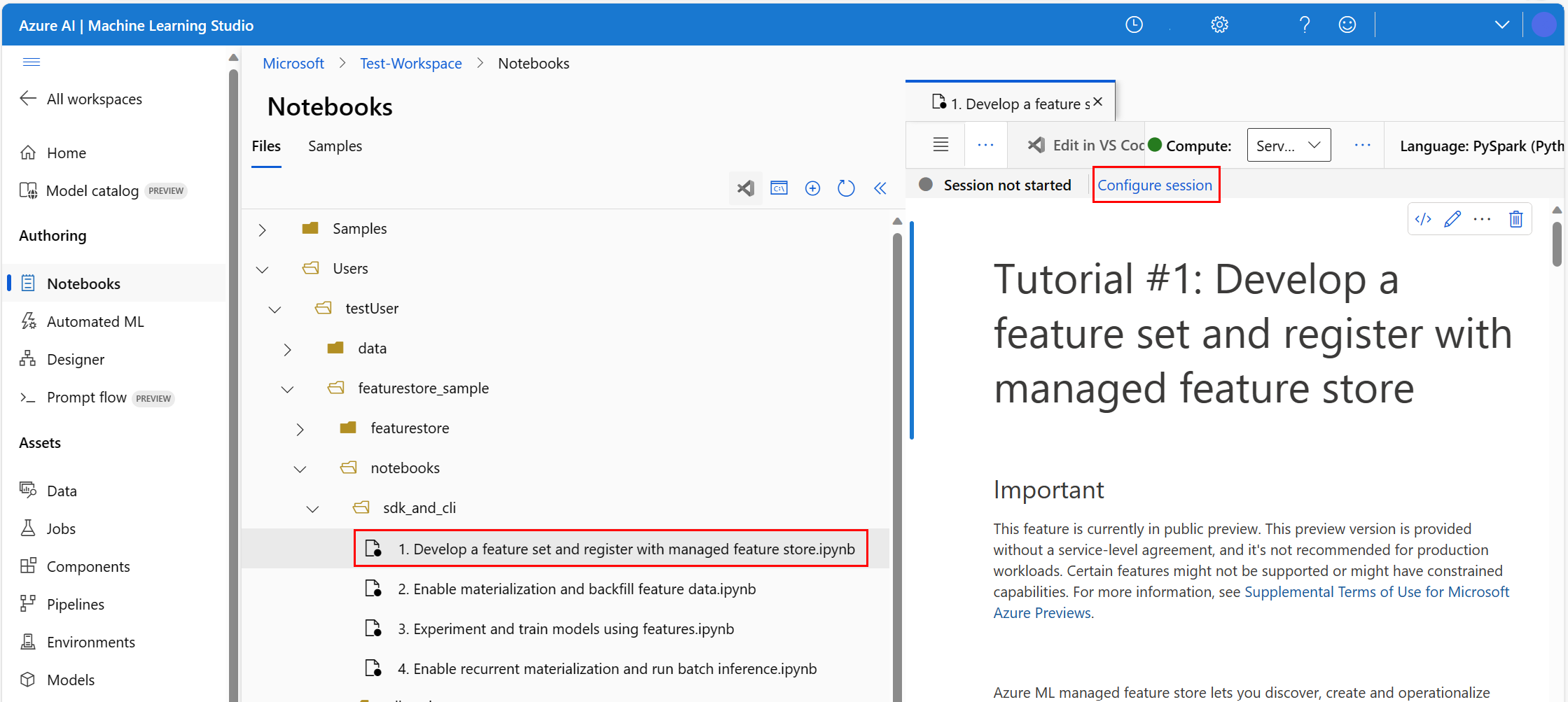
- Selecione Computação do Spark Sem Servidor na lista suspensa Computação do painel de navegação superior. Essa operação poderá demorar um ou dois minutos. Aguarde até que uma barra de status na parte superior exiba o texto Configurar sessão.
- Selecione Configurar sessão na barra de status superior.
- Selecione Pacotes do Python.
- Selecione Carregar arquivos do Conda.
- Selecione o arquivo
conda.ymlque você baixou no dispositivo local. - (Opcional) Aumente o tempo limite da sessão (tempo ocioso em minutos) para reduzir o tempo de inicialização do cluster do Spark Sem Servidor.
No ambiente do Azure Machine Learning, abra o notebook e selecione Configurar sessão.
No painel Configurar Sessão, selecionePacotes do Python.
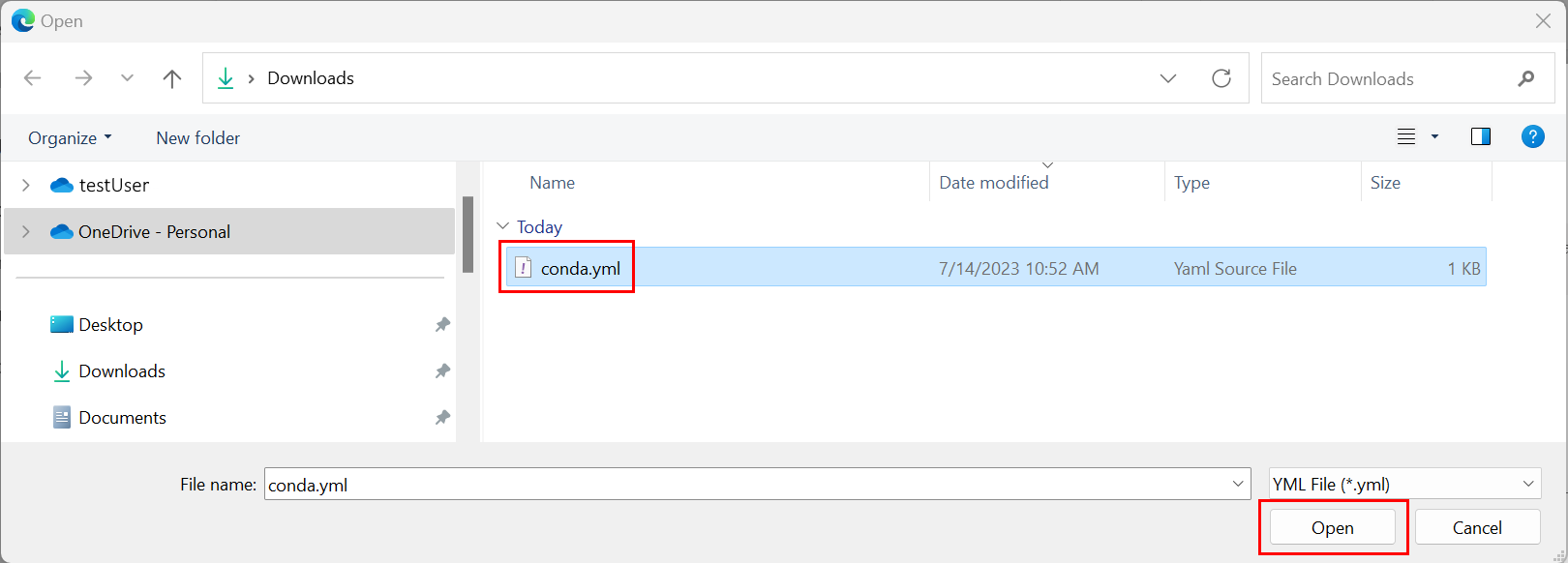
Carregar o arquivo Conda:
- Na guia Pacotes do Python, selecione Carregar arquivo Conda.
- Navegue até o diretório com o arquivo Conda.
- Selecione conda.yml e, em seguida, selecione Abrir.
Escolha Aplicar.







Iniciar a sessão do Spark
# Run this cell to start the spark session (any code block will start the session ). This can take around 10 mins.
print("start spark session")Configurar o diretório raiz para os exemplos
import os
# Please update <your_user_alias> below (or any custom directory you uploaded the samples to).
# You can find the name from the directory structure in the left navigation panel.
root_dir = "./Users/<your_user_alias>/featurestore_sample"
if os.path.isdir(root_dir):
print("The folder exists.")
else:
print("The folder does not exist. Please create or fix the path")Configurar a CLI
Não aplicável.
Observação
Você usa um repositório de recursos para reutilizar recursos entre projetos. Você usará um workspace do projeto (um workspace do Azure Machine Learning) para treinar e fazer a inferência de modelos, aproveitando recursos dos repositórios de recursos. Vários workspaces do projeto podem compartilhar e reutilizar o mesmo repositório de recursos.
Esse tutorial usará dois SDKs:
O SDK CRUD do repositório de recursos
Use o mesmo
MLClient(nome do pacoteazure-ai-ml) usado com o workspace do Azure Machine Learning. Um repositório de recursos é implementado como um tipo de workspace. Como resultado, esse SDK é usado para operações CRUD para os repositórios de recursos, os conjuntos de recursos e as entidades do repositório de recursos.O SDK principal do repositório de recursos
Esse SDK (
azureml-featurestore) destina-se ao desenvolvimento e ao consumo do conjunto de recursos. Etapas posteriores nesse tutorial descrevem estas operações:- Desenvolver a especificação do conjunto de recursos.
- Recuperar dados de recurso.
- Listar ou obter um conjunto de recursos registrados.
- Gerar e resolver especificações da recuperação de recursos.
- Gerar dados de treinamento e inferência usando junções pontuais.
Esse tutorial não requer a instalação explícita desses SDKs, pois as instruções do conda.yml anteriores abrangem essa etapa.
Criar um repositório de recursos mínimo
Definir parâmetros de repositório de recursos, incluindo nome, local e outros valores.
# We use the subscription, resource group, region of this active project workspace. # You can optionally replace them to create the resources in a different subsciprtion/resource group, or use existing resources. import os featurestore_name = "<FEATURESTORE_NAME>" featurestore_location = "eastus" featurestore_subscription_id = os.environ["AZUREML_ARM_SUBSCRIPTION"] featurestore_resource_group_name = os.environ["AZUREML_ARM_RESOURCEGROUP"]Criar o repositório de recursos.
from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for feature store creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())Inicializar o cliente SDK principal do repositório de recursos do Azure Machine Learning.
Conforme explicado anteriormente nesse tutorial, o cliente principal do SDK do repositório de recursos é usado para desenvolver e consumir recursos.
# feature store client from azureml.featurestore import FeatureStoreClient from azure.ai.ml.identity import AzureMLOnBehalfOfCredential featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )Conceda a função "Cientista de Dados do Azure Machine Learning" no repositório de recursos à sua identidade de usuário. Obtenha o valor da ID de objeto do Microsoft Entra no portal do Azure, conforme descrito em Localizar a ID de objeto do usuário.
Atribua a função Cientista de Dados do AzureML à sua identidade de usuário, para que ele possa criar recursos no workspace do repositório de recursos. As permissões podem precisar de algum tempo para serem propagadas.
Para mais informações sobre o controle de acesso, confira Gerenciar o controle de acesso para o repositório de recursos gerenciados.
your_aad_objectid = "<USER_AAD_OBJECTID>" !az role assignment create --role "AzureML Data Scientist" --assignee-object-id $your_aad_objectid --assignee-principal-type User --scope $feature_store_arm_id
Protótipo e desenvolvimento de um conjunto de recursos
Nestas etapas, você criará um conjunto de recursos chamado transactions que tem recursos sem interrupção e baseados em agregação de janela:
Explorar os dados de origem de
transactions.Esse notebook usa dados de exemplo hospedados em um contêiner de blob acessível publicamente. Ele pode ser lido no Spark somente através de um driver
wasbs. Ao criar conjuntos de recursos usando seus próprios dados de origem, hospede-os em uma conta do Azure Data Lake Storage Gen2 e use um driverabfssno caminho de dados.# remove the "." in the roor directory path as we need to generate absolute path to read from spark transactions_source_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet" transactions_src_df = spark.read.parquet(transactions_source_data_path) display(transactions_src_df.head(5)) # Note: display(training_df.head(5)) displays the timestamp column in a different format. You can can call transactions_src_df.show() to see correctly formatted valueDesenvolver o conjunto de recursos localmente.
Uma especificação do conjunto de recursos é uma definição de conjunto de recursos independente que você pode desenvolver e testar localmente. Aqui, criaremos esses recursos de agregação sem interrupção da janela:
transactions three-day counttransactions amount three-day sumtransactions amount three-day avgtransactions seven-day counttransactions amount seven-day sumtransactions amount seven-day avg
Examine o arquivo de código de transformação de recursos: featurestore/featuresets/transactions/transformation_code/transaction_transform.py. Observe a agregação sem interrupção definida para os recursos. Esse é um transformador do Spark.
Para saber mais sobre o conjunto de recursos e as transformações, consulte O que é repositório de recursos gerenciados?.
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) transactions_featureset_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), feature_transformation=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], source_lookback=DateTimeOffset(days=7, hours=0, minutes=0), temporal_join_lookback=DateTimeOffset(days=1, hours=0, minutes=0), infer_schema=True, )Exportar como uma especificação de conjunto de recursos.
Para registrar a especificação do conjunto de recursos no repositório de recursos, você deve salvá-la em um formato específico.
Examine a especificação do conjunto de recursos de
transactionsgerado. Abra esse arquivo da árvore de arquivos para ver a especificação: featurestore/featuresets/accounts/spec/FeaturesetSpec.yaml.A especificação contém estes elementos:
source: uma referência a um recurso de armazenamento. Nesse caso, trata-se de um arquivo Parquet em um recurso de armazenamento de blobs.features: uma lista de recursos e seus tipos de dados. Se você fornecer o código de transformação, o código deve retornar um DataFrame que mapeia os recursos e tipos de dados.index_columns: as chaves de junção necessárias para acessar os valores do conjunto de recursos.
Para saber mais sobre a especificação, confira Noções básicas sobre entidades de nível superior no repositório de recursos gerenciados e o esquema YAML do conjunto de recursos da CLI (v2).
Persistir a especificação do conjunto de recursos oferece outro benefício: a especificação do conjunto de recursos pode ser controlado no código-fonte.
import os # Create a new folder to dump the feature set specification. transactions_featureset_spec_folder = ( root_dir + "/featurestore/featuresets/transactions/spec" ) # Check if the folder exists, create one if it does not exist. if not os.path.exists(transactions_featureset_spec_folder): os.makedirs(transactions_featureset_spec_folder) transactions_featureset_spec.dump(transactions_featureset_spec_folder, overwrite=True)
Registrar uma entidade de repositório de recursos
Como melhor prática, as entidades ajudam a impor o uso da mesma definição de chave de junção entre conjuntos de recursos que usam as mesmas entidades lógicas. Exemplos de entidades incluem contas e clientes. As entidades normalmente são criadas uma vez e reutilizados em conjuntos de recursos. Para saber mais, confira Noções básicas sobre entidades de nível superior em repositório de recursos gerenciados.
Inicializar o cliente CRUD do repositório de recursos.
Conforme explicado anteriormente neste tutorial, o
MLClienté usado para criar, ler, atualizar e excluir um ativo do repositório de recursos. O exemplo de célula de código de notebook mostrado aqui pesquisa o repositório de recursos que criamos em uma etapa anterior. Aqui, não é possível reutilizar o mesmo valor deml_clientusado anteriormente neste tutorial, pois ele está no escopo no nível do grupo de recursos. O escopo adequado é um pré-requisito para a criação do repositório de recursos.Nesse exemplo de código, o escopo do cliente é no nível do repositório de recursos.
# MLClient for feature store. fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, )Registrar a entidade de
accountno repositório de recursos.Crie uma entidade de
accountque tenha a chave de junçãoaccountID, do tipostring.from azure.ai.ml.entities import DataColumn, DataColumnType account_entity_config = FeatureStoreEntity( name="account", version="1", index_columns=[DataColumn(name="accountID", type=DataColumnType.STRING)], stage="Development", description="This entity represents user account index key accountID.", tags={"data_typ": "nonPII"}, ) poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config) print(poller.result())
Registrar o conjunto de recursos de transação com o repositório de recursos
Use este código para registrar um ativo de conjunto de recursos com o repositório de recursos. Em seguida, você pode reutilizar esse ativo e compartilhá-lo facilmente. O registro de ativos do conjunto de recursos oferece recursos gerenciados, incluindo controle de versão e materialização. As etapas posteriores nesta série de tutoriais abrangem recursos gerenciados.
from azure.ai.ml.entities import FeatureSetSpecification
transaction_fset_config = FeatureSet(
name="transactions",
version="1",
description="7-day and 3-day rolling aggregation of transactions featureset",
entities=[f"azureml:account:1"],
stage="Development",
specification=FeatureSetSpecification(path=transactions_featureset_spec_folder),
tags={"data_type": "nonPII"},
)
poller = fs_client.feature_sets.begin_create_or_update(transaction_fset_config)
print(poller.result())Explorar a interface do usuário do repositório de recursos
A criação e as atualizações de ativos do repositório de recursos só podem ocorrer por meio do SDK e da CLI. Você pode usar a interface do usuário para pesquisar ou procurar no repositório de recursos:
- Abra a página de aterrissagem global do Azure Machine Learning.
- Selecione Repositórios de recursos no painel esquerdo.
- Nesta lista de repositórios de recursos acessíveis, selecione o repositório de recursos criado anteriormente nesse tutorial.
Conceder o acesso à função leitor de dados de blob de armazenamento para a sua conta de usuário no repositório offline
A função Leitor de Dados de Blob de Armazenamento deve ser atribuída à sua conta de usuário no repositório offline. Isso garante que a conta de usuário possa ler os dados de recursos materializados do repositório de materialização offline.
Obtenha o valor da ID de objeto do Microsoft Entra no portal do Azure, conforme descrito em Localizar a ID de objeto do usuário.
Obtenha informações sobre o repositório de materialização offline na página Visão Geral do Repositório de Recursos na interface do usuário do Repositório de Recursos. Você pode encontrar os valores para a ID da assinatura da conta de armazenamento, o nome do grupo de recursos da conta de armazenamento e o nome da conta de armazenamento para o repositório de materialização offline no cartão do Repositório de materialização offline.

Para mais informações sobre o controle de acesso, confira Gerenciar o controle de acesso para o repositório de recursos gerenciados.
Execute esta célula de código para atribuição de função. As permissões podem precisar de algum tempo para serem propagadas.
# This utility function is created for ease of use in the docs tutorials. It uses standard azure API's. # You can optionally inspect it `featurestore/setup/setup_storage_uai.py`. import sys sys.path.insert(0, root_dir + "/featurestore/setup") from setup_storage_uai import grant_user_aad_storage_data_reader_role your_aad_objectid = "<USER_AAD_OBJECTID>" storage_subscription_id = "<SUBSCRIPTION_ID>" storage_resource_group_name = "<RESOURCE_GROUP>" storage_account_name = "<STORAGE_ACCOUNT_NAME>" grant_user_aad_storage_data_reader_role( AzureMLOnBehalfOfCredential(), your_aad_objectid, storage_subscription_id, storage_resource_group_name, storage_account_name, )

Gerar um DataFrame de dados de treinamento usando o conjunto de recursos registrado
Carregar dados de observação.
Geralmente, os dados de observação envolvem os dados principais usados para treinamento e inferência. Esses dados se unem aos dados de recursos para criar o recurso de dados de treinamento completo.
Os dados de observação são dados capturados durante o evento em si. Aqui, há os principais dados da transação, incluindo a ID da transação, a ID da conta e os valores da transação. Como a usamos para treinamento, ela também tem a variável de destino acrescentada (is_fraud).
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueObtenha o conjunto de recursos registrado e liste seus recursos.
# Look up the featureset by providing a name and a version. transactions_featureset = featurestore.feature_sets.get("transactions", "1") # List its features. transactions_featureset.features# Print sample values. display(transactions_featureset.to_spark_dataframe().head(5))Selecione os recursos que se tornam parte dos dados de treinamento. Em seguida, use o SDK do repositório de recursos para gerar os próprios dados de treinamento.
from azureml.featurestore import get_offline_features # You can select features in pythonic way. features = [ transactions_featureset.get_feature("transaction_amount_7d_sum"), transactions_featureset.get_feature("transaction_amount_7d_avg"), ] # You can also specify features in string form: featureset:version:feature. more_features = [ f"transactions:1:transaction_3d_count", f"transactions:1:transaction_amount_3d_avg", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features) # Generate training dataframe by using feature data and observation data. training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) # Ignore the message that says feature set is not materialized (materialization is optional). We will enable materialization in the subsequent part of the tutorial. display(training_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueUma junção pontual acrescenta os recursos aos dados de treinamento.
Habilite a materialização offline no conjunto de recursos transactions
Depois que a materialização do conjunto de recursos estiver habilitada, você poderá executar um provisionamento. Você também pode agendar os trabalhos de materialização recorrentes. Para obter mais informações, confira o terceiro tutorial da série.
Definir spark.sql.shuffle.partitions no arquivo yaml de acordo com o tamanho dos dados do recurso
A configuração do Spark spark.sql.shuffle.partitions é um parâmetro OPCIONAL que pode afetar o número de arquivos parquet gerados (por dia), quando o conjunto de recursos é materializado no repositório offline. O valor padrão desse parâmetro é 200. Como melhor prática, evite a geração de muitos arquivos parquet pequenos. Se a recuperação de recursos offline ficar lenta após a materialização do conjunto de recursos, vá para a pasta correspondente no repositório offline para verificar se o problema envolve muitos arquivos parquet pequenos (por dia) e ajuste o valor desse parâmetro adequadamente.
Observação
Os dados de exemplo usados neste notebook são pequenos. Portanto, esse parâmetro é definido como 1 no arquivo featureset_asset_offline_enabled.yaml.
from azure.ai.ml.entities import (
MaterializationSettings,
MaterializationComputeResource,
)
transactions_fset_config = fs_client._featuresets.get(name="transactions", version="1")
transactions_fset_config.materialization_settings = MaterializationSettings(
offline_enabled=True,
resource=MaterializationComputeResource(instance_type="standard_e8s_v3"),
spark_configuration={
"spark.driver.cores": 4,
"spark.driver.memory": "36g",
"spark.executor.cores": 4,
"spark.executor.memory": "36g",
"spark.executor.instances": 2,
"spark.sql.shuffle.partitions": 1,
},
schedule=None,
)
fs_poller = fs_client.feature_sets.begin_create_or_update(transactions_fset_config)
print(fs_poller.result())Você também pode salvar o ativo do conjunto de recursos como um recurso YAML.
## uncomment to run
transactions_fset_config.dump(
root_dir
+ "/featurestore/featuresets/transactions/featureset_asset_offline_enabled.yaml"
)Dados de provisionamento para o conjunto de recursos transactions
Conforme explicado anteriormente, a materialização calcula os valores de recurso para uma janela de recurso e armazena esses valores calculados em um armazenamento de materialização. A materialização de recursos aumenta a confiabilidade e a disponibilidade dos valores computados. Todas as consultas de recursos agora usam os valores do repositório de materialização. Essa etapa executa um provisionamento único, para uma janela de recurso de 18 meses.
Observação
Você pode precisar determinar o valor da janela de dados de provisionamento. A janela deve corresponder à janela dos seus dados de treinamento. Por exemplo, para usar 18 meses de dados para treinamento, você deve recuperar os recursos por 18 meses. Isso significa que você deve executar um provisionamento de uma janela de 18 meses.
Essa célula de código materializa os dados com o status atual Nenhum ou Incompleto para a janela de recursos definida.
from datetime import datetime
from azure.ai.ml.entities import DataAvailabilityStatus
st = datetime(2022, 1, 1, 0, 0, 0, 0)
et = datetime(2023, 6, 30, 0, 0, 0, 0)
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version="1",
feature_window_start_time=st,
feature_window_end_time=et,
data_status=[DataAvailabilityStatus.NONE],
)
print(poller.result().job_ids)# Get the job URL, and stream the job logs.
fs_client.jobs.stream(poller.result().job_ids[0])Dica
- A coluna
timestampdeve seguir o formatoyyyy-MM-ddTHH:mm:ss.fffZ. - A granularidade
feature_window_start_timeefeature_window_end_timeé limitada a segundos. Todos os milissegundos fornecidos no objetodatetimeserão ignorados. - Um trabalho de materialização só será enviado se os dados na janela de recursos corresponderem ao
data_statusdefinido durante o envio do trabalho de provisionamento.
Imprima os dados de amostra do conjunto de recursos. As informações de saída mostram que os dados foram recuperados do repositório de materialização. O método get_offline_features() recuperou os dados de treinamento e inferência. Ele também usa o armazenamento de materialização por padrão.
# Look up the feature set by providing a name and a version and display few records.
transactions_featureset = featurestore.feature_sets.get("transactions", "1")
display(transactions_featureset.to_spark_dataframe().head(5))Explorar ainda mais a materialização de recursos offline
Você pode explorar o status de materialização de recursos para um conjunto de recursos na interface do usuário dos Trabalhos de materialização.
Abra a página de aterrissagem global do Azure Machine Learning.
Selecione Repositórios de recursos no painel esquerdo.
Na lista de repositórios de recursos acessíveis, selecione o repositório de recursos para o qual você executou o provisionamento.
Selecione a guia Trabalhos de materialização.


O status de materialização de dados pode estar
- Completo (verde)
- Incompleto (vermelho)
- Pendente (azul)
- Nenhum (cinza)
O intervalo de dados representa uma parte contígua de dados com o mesmo status de materialização de dados. Por exemplo, o instantâneo anterior tem 16 intervalos de dados no repositório de materialização offline.
Os dados podem ter um máximo de 2.000 intervalos de dados. Se os dados contiverem mais de 2.000 intervalos de dados, crie uma nova versão do conjunto de recursos.
Você pode fornecer uma lista de mais de um status de dados (por exemplo,
["None", "Incomplete"]) em um único trabalho de provisionamento.Durante o provisionamento, um novo trabalho de materialização é enviado para cada intervalo de dados que se enquadra na janela de recursos definida.
Se um trabalho de materialização estiver pendente ou se esse trabalho estiver em execução para um intervalo de dados que ainda não foi preenchido novamente, um novo trabalho não será enviado para esse intervalo de dados.
Você pode repetir um trabalho de materialização com falha.
Observação
Para obter a ID do trabalho de um trabalho de materialização com falha:
- Navegue até o conjunto de recursos da interface do usuário dos Trabalhos de materialização.
- Selecione o Nome de exibição de um trabalho específico com Status de Falhou.
- Localize a ID do trabalho na propriedade Name encontrada na página Visão geral do trabalho. Começa com
Featurestore-Materialization-.
poller = fs_client.feature_sets.begin_backfill(
name="transactions",
version=version,
job_id="<JOB_ID_OF_FAILED_MATERIALIZATION_JOB>",
)
print(poller.result().job_ids)
Atualizar o repositório de materialização offline
- Se um repositório de materialização offline precisar ser atualizado no nível do repositório de recursos, todos os conjuntos de recursos no repositório de recursos deverão ter a materialização offline desabilitada.
- Se a materialização offline estiver desabilitada em um conjunto de recursos, o status de materialização dos dados já materializados nas redefinições do repositório de materialização offline. A redefinição torna inutilizáveis os dados que já estão materializados. Você deve reenviar os trabalhos de materialização depois de habilitar a materialização offline.
Este tutorial criou os dados de treinamento com recursos do repositório de recursos, habilitou a materialização para o repositório de recursos offline e executou um provisionamento. Em seguida, você executará o treinamento de modelo usando esses recursos.
Limpar
O quinto tutorial da série descreve como excluir os recursos.
Próximas etapas
- Veja o próximo tutorial da série: Experimentar e treinar modelos usando recursos.
- Saiba mais sobre conceitos de repositório de recursos e entidades de nível superior no repositório de recursos gerenciados.
- Saiba mais sobre controle de identidade e acesso para armazenamento de recursos gerenciados.
- Veja o guia de solução de problemas para armazenamento de recursos gerenciados.
- Veja a referência YAML.