Como configurar a replicação de dados para o Banco de Dados do Azure para MySQL - Servidor Flexível
APLICA-SE A:  Banco de Dados do Azure para MySQL – Servidor flexível
Banco de Dados do Azure para MySQL – Servidor flexível
Este artigo descreve como configurar a replicação de dados no servidor flexível do Banco de Dados do Azure para MySQL ao configurar os servidores de origem e de réplica. Este artigo pressupõe que você tenha alguma experiência anterior com servidores e bancos de dados MySQL.
Observação
Este artigo contém referências ao termo servidor subordinado, um termo que a Microsoft não usa mais. Quando o termo for removido do software, também o removeremos deste artigo.
Para criar uma réplica na instância do Banco de Dados do Azure para MySQL com servidor flexível, a Replicação de dados sincroniza dados de um servidor MySQL local de origem, em VMs (máquinas virtuais) ou em serviços de banco de dados de nuvem. A replicação de dados pode ser configurada usando uma replicação baseada na posição do arquivo de log binário (binlog) ou uma replicação baseada em GTID. Para saber mais sobre a replicação do binlog, confira a Replicação do MySQL.
Analise as limitações e os requisitos de replicação de dados antes de executar as etapas deste artigo.
Criar uma instância do Banco de Dados do Azure para MySQL com servidor flexível para usar como uma réplica
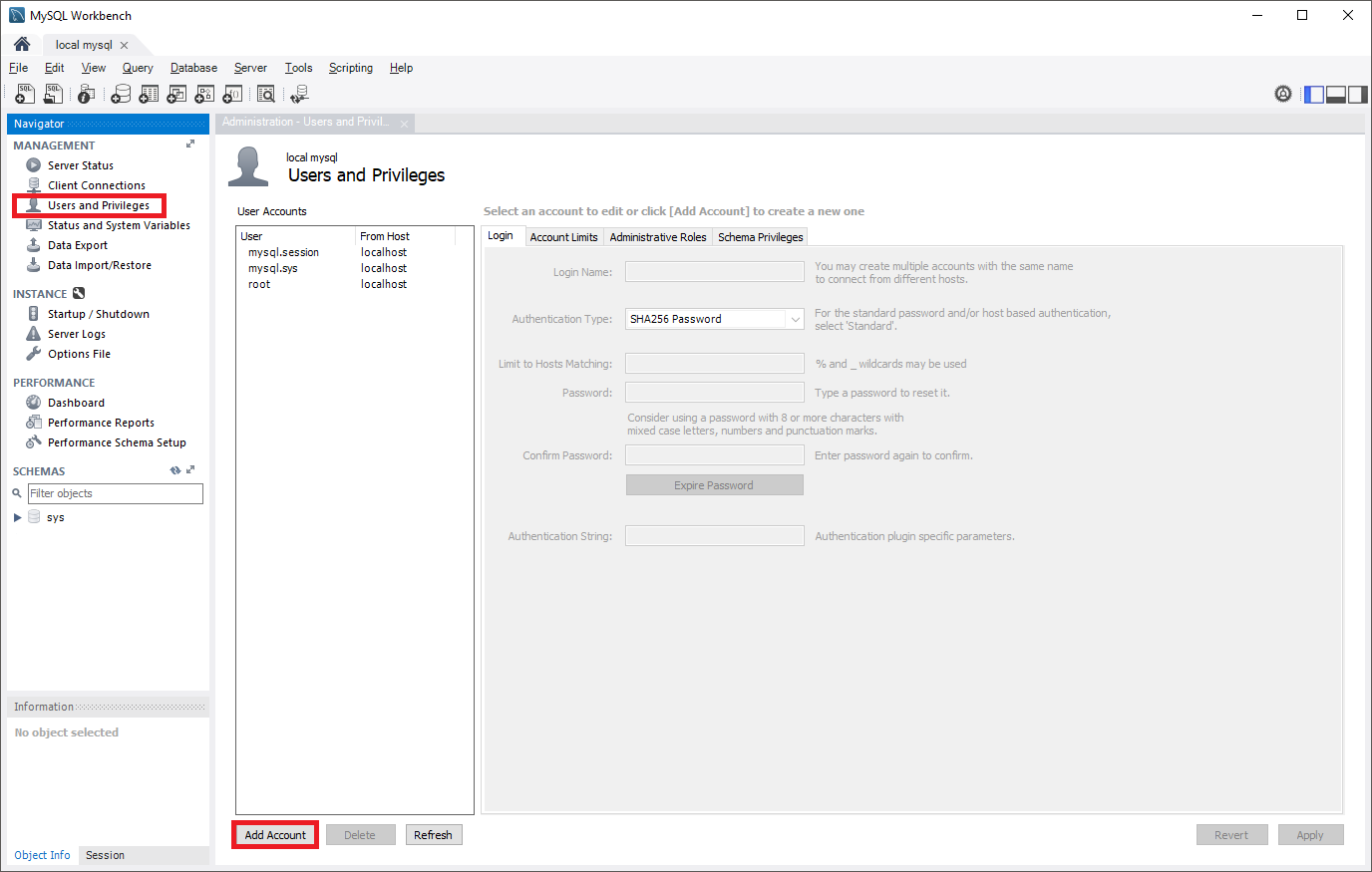
Crie uma nova instância de servidor flexível do Banco de Dados do Azure para MySQL (por exemplo,
replica.mysql.database.azure.com). Consulte Criar uma instância do Banco de Dados do Azure para MySQL com servidor flexível usando o portal do Azure, para verificar a criação do servidor. Esse servidor é o servidor de "réplica" da replicação de dados.Crie as mesmas contas de usuário e privilégios correspondentes.
Contas de usuário não são replicadas do servidor de origem para o servidor de réplica. Caso planeje fornecer aos usuários acesso ao servidor de réplica, você precisa criar manualmente todas as contas e privilégios correspondentes nesta instância do Banco de Dados do Azure para MySQL com servidor flexível recém-criado.
Configurar o servidor MySQL de origem
As etapas a seguir preparam e configuram o servidor MySQL hospedado no local, em uma máquina virtual ou serviço de banco de dados hospedado por outros provedores de nuvem para replicação de dados. Esse servidor é a "origem" da Replicação de dados.
Analise os requisitos do servidor de origem antes de continuar.
Requisitos de rede
Verifique se o servidor de origem permite o tráfego de entrada e de saída na porta 3306 e se ele tem um endereço IP público, se o DNS pode ser acessado publicamente ou se ele tem um FQDN (nome de domínio totalmente qualificado).
Se o acesso privado (Integração de VNet) estiver em uso, certifique-se de que tenha conectividade entre o Servidor de origem e a Vnet na qual o servidor de réplica está hospedado.
Certifique-se de que nós forneçamos conectividade site a site com os servidores de origem locais usando o ExpressRoute ou a VPN. Para obter mais informações sobre como criar uma rede virtual, confira a Documentação da Rede Virtual e, especificamente, os artigos de Início Rápido com detalhes passo a passo.
Se o acesso privado (Integração de VNet) for usado no servidor de réplica e sua origem for a VM do Azure, certifique-se de que a conectividade VNet com VNet seja estabelecida. Há suporte para emparelhamento VNet-Vnet. Você também pode usar outros métodos de conectividade para se comunicar entre VNets em regiões diferentes, como conexão VNet a VNet. Para obter mais informações, você pode consultar gateway de VPN VNet para VNet
Verifique se as regras do grupo de segurança de rede de rede virtual não bloqueiam a porta de saída 3306 (também de entrada se o MySQL estiver em execução na VM do Azure). Para obter mais detalhes sobre a filtragem de tráfego do NSG da rede virtual, confira o artigo Filtrar o tráfego de rede com grupos de segurança de rede.
Configure as regras de firewall do servidor de origem para permitir o endereço IP do servidor de réplica.
Siga as etapas apropriadas com base em se você deseja usar a posição do bin-log ou a replicação de dados baseada em GTID.
Execute o seguinte comando para verificar se o registro em log binário foi habilitado na origem:
SHOW VARIABLES LIKE 'log_bin';Se a variável
log_binfor retornada com o valor "ON", isso significa que o registro em log binário está habilitado no servidor.Se
log_binfor retornado com o valor "OFF" e o servidor de origem estiver em execução no local ou em máquinas virtuais em que você possa acessar o arquivo de configuração (my.cnf), você poderá seguir as seguintes etapas:Localize o arquivo de configuração do MySQL (my.cnf) no servidor de origem. Por exemplo: /etc/my.cnf
Abra o arquivo de configuração para editá-lo e localize a seção mysqld no arquivo.
Na seção mysqld, adicione a seguinte linha:
log-bin=mysql-bin.logReinicie o serviço MySQL no servidor de origem (ou reinicie) para as alterações entrarem em vigor.
Depois que o servidor for reiniciado, verifique se o registro em log binário está habilitado executando a mesma consulta que antes:
SHOW VARIABLES LIKE 'log_bin';
Defina as configurações do servidor de origem.
A replicação de dados requer que o parâmetro
lower_case_table_namesseja consistente entre os servidores de origem e de réplica. Esse parâmetro é 1 por padrão no servidor flexível do Banco de Dados do Azure para MySQL.SET GLOBAL lower_case_table_names = 1;Crie uma nova função de replicação e configure a permissão.
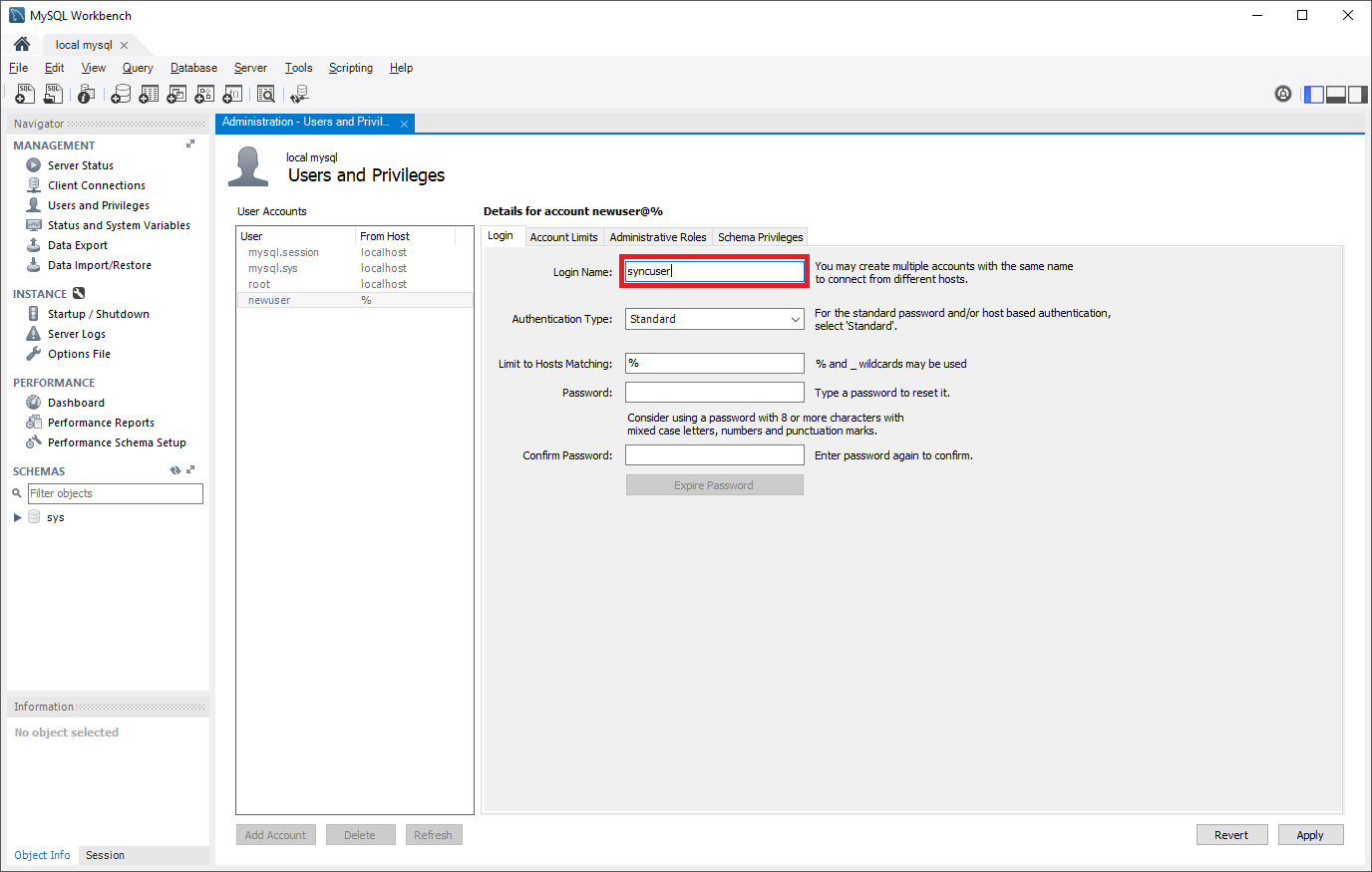
Crie uma conta de usuário no servidor de origem que é configurado com privilégios de replicação. Isso pode ser feito por meio de comandos SQL ou de uma ferramenta como o Workbench do MySQL. Leve em conta se você planeja replicar com SSL, pois isso precisa ser especificado na criação do usuário. Confira a documentação do MySQL para entender como adicionar contas de usuário ao seu servidor de origem.
Nos comandos a seguir, a nova função de replicação criada pode acessar a origem a partir de qualquer máquina, não apenas da máquina que hospeda a própria origem. Isso é feito especificando "syncuser@'%'" no comando create user. Confira a documentação do MySQL para saber mais sobre como especificar nomes de conta.
Replicação com SSL
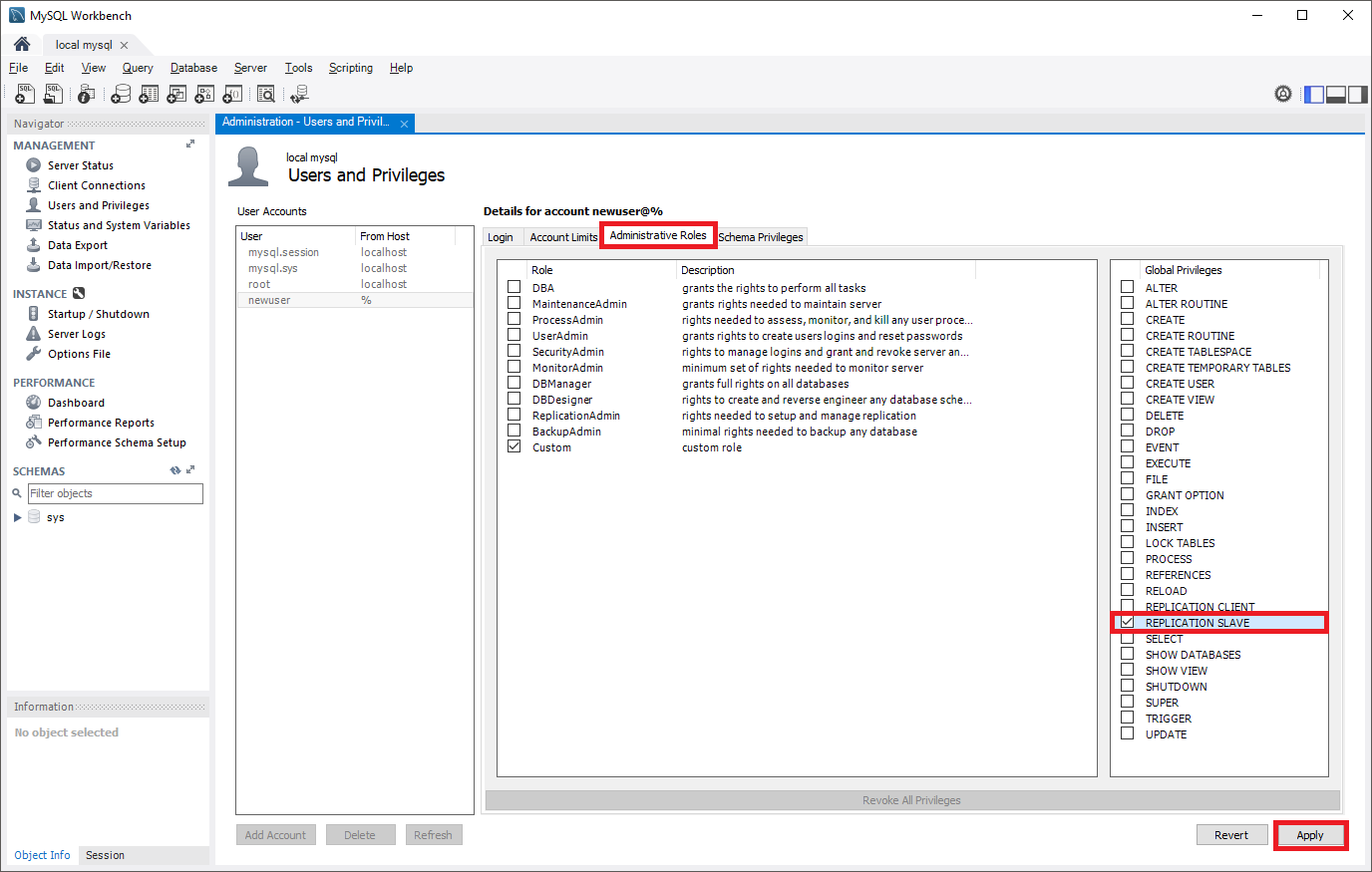
Para exigir SSL em todas as conexões de usuário, use o seguinte comando para criar um usuário:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%' REQUIRE SSL;Replicação sem SSL
Se o SSL não for exigido para todas as conexões, use o seguinte comando para criar um usuário:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO ' syncuser'@'%';Configure o servidor de origem para o modo somente leitura.
Antes de começar a despejar o banco de dados, o servidor precisa ser colocado no modo somente leitura. No modo somente leitura, a origem será capaz de processar todas as transações de gravação. Avalie o impacto em seus negócios e agende a janela de somente leitura em um horário fora de pico, se necessário.
FLUSH TABLES WITH READ LOCK; SET GLOBAL read_only = ON;Obter o nome e o deslocamento do arquivo de log binário.
Execute o comando
show master statuspara determinar o nome e o deslocamento do arquivo de log binário atual.show master status;Os resultados devem ser semelhantes ao seguinte. Anote o nome do arquivo binário para ele ser usado em etapas posteriores.

Despejar e restaurar o servidor de origem
Determine quais bancos de dados e tabelas você deseja replicar no servidor flexível do Banco de Dados do Azure para MySQL e execute o despejo do servidor de origem.
Você pode usar o mysqldump para despejar os bancos de dados do servidor primário. Para obter detalhes, consulte Despejar e restaurar. Não é necessário despejar as bibliotecas normal e de teste do MySQL.
Defina o servidor de origem para o modo de leitura/gravação.
Depois que o banco de dados tiver sido despejado, retorne o servidor MySQL de origem ao modo de leitura/gravação.
SET GLOBAL read_only = OFF; UNLOCK TABLES;Observação
Antes que o servidor seja definido novamente para o modo de leitura/gravação, você pode recuperar as informações de GTID usando a variável global GTID_EXECUTED. Isso será usado no estágio posterior para definir GTID no servidor de réplica.
Restaure arquivo de despejo no novo servidor.
Restaure o arquivo de despejo no servidor criado no servidor flexível do Banco de Dados do Azure para MySQL. Consulte Despejar e restaurar para saber como restaurar um arquivo de despejo em um servidor MySQL. Se o arquivo de despejo é grande, carregue-o em uma máquina virtual do Azure na mesma região do servidor de réplica. Restaure-o na instância do Banco de Dados do Azure para MySQL com servidor flexível da máquina virtual.
Observação
Se você não quiser configurar o banco de dados para leitura somente quando despejar e restaurar, poderá usar mydumper/myloader.
Definir GTID no Servidor de Réplica
Ignore a etapa se estiver usando a replicação baseada na posição do bin-log
As informações GTID do arquivo de despejo obtido na origem são necessárias para redefinir o histórico GTID do servidor de destino (réplica).
Use essas informações GTID da origem para executar a redefinição de GTID no servidor réplica usando o seguinte comando da CLI:
az mysql flexible-server gtid reset --resource-group <resource group> --server-name <replica server name> --gtid-set <gtid set from the source server> --subscription <subscription id>
Para obter mais detalhes, confira Redefinição de GTID.
Observação
Não é possível executar a redefinição de GTID em um servidor habilitado para backup de redundância geográfica. Desabilite a redundância geográfica para executar a redefinição de GTID no servidor. É possível habilitar a opção de redundância geográfica novamente após a redefinição de GTID. A ação de redefinição de GTID invalida todos os backups disponíveis e, portanto, uma vez que a redundância geográfica está habilitada novamente, poderá levar um dia até que a restauração geográfica possa ser executada no servidor
Vincular servidores de origem e de réplica para iniciar a replicação de dados
Defina o servidor de origem.
Todas as funções de replicação de dados são feitas por procedimentos armazenados. Você pode encontrar todos os procedimentos em Procedimentos armazenados de replicação de dados. Os procedimentos armazenados podem ser executados no shell do MySQL ou no Workbench do MySQL.
Para vincular dois servidores e iniciar a replicação, faça logon no servidor de réplica de destino no serviço de Banco de Dados do Azure para MySQL e defina a instância externa como o servidor de origem. Isso é feito por meio do procedimento armazenado
mysql.az_replication_change_masteroumysql.az_replication_change_master_with_gtidno servidor do Banco de Dados do Azure para MySQL.CALL mysql.az_replication_change_master('<master_host>', '<master_user>', '<master_password>', <master_port>, '<master_log_file>', <master_log_pos>, '<master_ssl_ca>');CALL mysql.az_replication_change_master_with_gtid('<master_host>', '<master_user>', '<master_password>', <master_port>,'<master_ssl_ca>');- master_host: nome do host do servidor de origem
- master_user: nome de usuário do servidor de origem
- master_password: a senha para o servidor de origem
- master_port: número da porta na qual o servidor de origem está escutando conexões. (A 3306 é a porta padrão na qual o MySQL está escutando)
- master_log_file: nome de arquivo de log binário de
show master statusem execução - master_log_pos: posição de log binário de
show master statusem execução - master_ssl_ca: contexto do certificado da AC. Se não estiver usando SSL, passe em uma cadeia de caracteres vazia.
É recomendável passar esse parâmetro como uma variável. Para obter mais informações, visite os exemplos a seguir.
Observação
- Se o servidor de origem estiver hospedado em uma VM do Azure, defina "Permitir acesso a serviços do Azure" como "ON" para permitir que os servidores de origem e de réplica se comuniquem entre si. Essa configuração pode ser alterada a partir das opções Segurança de conexão. Para obter mais informações, consulte Gerenciar regras de firewall usando o portal.
- Se você usou mydumper/myloader para despejar o banco de dados, poderá obter master_log_file e master_log_pos no arquivo /backup/metadata.
Exemplos
Replicação com SSL
A variável
@certé criada executando os seguintes comandos do MySQL:SET @cert = '-----BEGIN CERTIFICATE----- PLACE YOUR PUBLIC KEY CERTIFICATE'`S CONTEXT HERE -----END CERTIFICATE-----'A replicação com o SSL é configurada entre um servidor de origem hospedado no domínio “companya.com” e um servidor de réplica hospedado no servidor flexível do Banco de Dados do Azure para MySQL. Esse procedimento armazenado é executado na réplica.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, @cert);CALL mysql.az_replication_change_master_with_gtid('master.companya.com', 'syncuser', 'P@ssword!', 3306, @cert);Replicação sem SSL
A replicação sem o SSL é configurada entre um servidor de origem hospedado no domínio “companya.com” e um servidor de réplica hospedado no servidor flexível do Banco de Dados do Azure para MySQL. Esse procedimento armazenado é executado na réplica.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, '');CALL mysql.az_replication_change_master_with_gtid('master.companya.com', 'syncuser', 'P@ssword!', 3306, '');Inicie a replicação.
Chame o procedimento armazenado
mysql.az_replication_startpara iniciar a replicação.CALL mysql.az_replication_start;Verifique o status da replicação.
Chame o comando
show slave statusno servidor de réplica para exibir o status de replicação.show slave status;Para conhecer o status correto da replicação, consulte as métricas de replicação – Status de E/S da Réplica e Status do SQL da Réplica na página de monitoramento.
Se o
Seconds_Behind_Masterfor "0", a replicação está funcionando corretamente.Seconds_Behind_Masterindica o atraso da réplica. Se o valor não for "0", isso significa que a réplica está processando as atualizações.
Outros procedimentos armazenados úteis para operações de replicação de dados
Parar replicação
Para interromper a replicação entre o servidor de origem e o de réplica, use o seguinte procedimento armazenado:
CALL mysql.az_replication_stop;
Remover relação de replicação
Para remover o relacionamento entre o servidor de origem e o servidor de réplica, use o seguinte procedimento armazenado:
CALL mysql.az_replication_remove_master;
Ignorar erro de replicação
Para ignorar um erro de replicação e permitir que a replicação continue, use o seguinte procedimento armazenado:
CALL mysql.az_replication_skip_counter;
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos][LIMIT [offset,] row_count]

Próximas etapas
- Saiba mais sobre replicação de dados para o servidor flexível do Banco de Dados do Azure para MySQL.