Tamanho do índice vetor e permanecer abaixo dos limites
Para cada campo de vetor, a Pesquisa de IA do Azure constrói um índice de vetor interno usando os parâmetros de algoritmo especificados no campo. Como a Pesquisa de IA do Azure impõe cotas no tamanho do índice vetor, você deve saber como estimar e monitorar o tamanho do vetor para garantir que permaneça abaixo dos limites.
Observação
Uma observação sobre terminologia. Internamente, as estruturas de dados físicas de um índice de pesquisa incluem conteúdo bruto (usado para padrões de recuperação que exigem conteúdo não tokenizado), índices invertidos (usados para campos de texto pesquisáveis) e índices de vetor (usados para campos de vetor pesquisáveis). Este artigo explica os limites para os índices de vetor internos que voltam a cada um dos campos de vetor.
Dica
A configuração de quantização vetorial e armazenamento agora está em disponibilidade geral. Use recursos como tipos de dados estreitos, quantização escalar e eliminação de armazenamento redundante para permanecer sob cota de vetor e cota de armazenamento.
Pontos-chave sobre cota e tamanho do índice de vetor
O tamanho do índice de vetor é medido em bytes.
As cotas de vetor são baseadas em restrições de memória. Todos os índices de vetor pesquisáveis devem ser carregados na memória. Ao mesmo tempo, também deve haver memória suficiente para outras operações de runtime. As cotas de vetor existem para garantir que o sistema geral permaneça estável e equilibrado para todas as cargas de trabalho.
Os índices de vetor também estão sujeitos à cota de disco, no sentido de que todos os índices são cota de disco de entidade. Não há nenhuma cota de disco separada para índices vetoriais.
As cotas de vetor são impostas no serviço de pesquisa como um todo, por partição, o que significa que, se você adicionar partições, a cota de vetor aumentará. As cotas de vetores por partição são maiores em serviços mais novos. Para obter mais informações, veja Limites de tamanho do índice vetorial.
Como verificar o tamanho e a quantidade de partições
Se você não tiver certeza de quais são seus limites de serviço de pesquisa, estas são duas maneiras de obter essas informações:
No portal do Azure, na página Visão Geral do serviço de pesquisa, as guias Propriedades e Uso mostram o tamanho e o armazenamento das partições e também a cota de vetor e o tamanho do índice de vetor.
No portal do Azure, na página Escalar, você pode examinar o número e o tamanho das partições.
Como verificar a data de criação do serviço
Os serviços mais recentes criados após 3 de abril de 2024 oferecem entre cinco e dez vezes mais armazenamento de vetor que os mais antigos, na mesma taxa de cobrança de camada. Se o serviço for mais antigo, considere criar um novo serviço e migrar seu conteúdo.
No portal do Azure, abra o grupo de recursos que contém seu serviço de pesquisa.
No painel de navegação mais à esquerda, em Configurações, selecione Implantações.
Localize a implantação do serviço de pesquisa. Se houver muitas implantações, use o filtro para procurar "pesquisa".
Selecione a implantação. Se você tiver mais de um, clique para ver se ele é resolvido para o serviço de pesquisa.

Expandir detalhes da implantação. Você deve ver Criado e a data de criação.
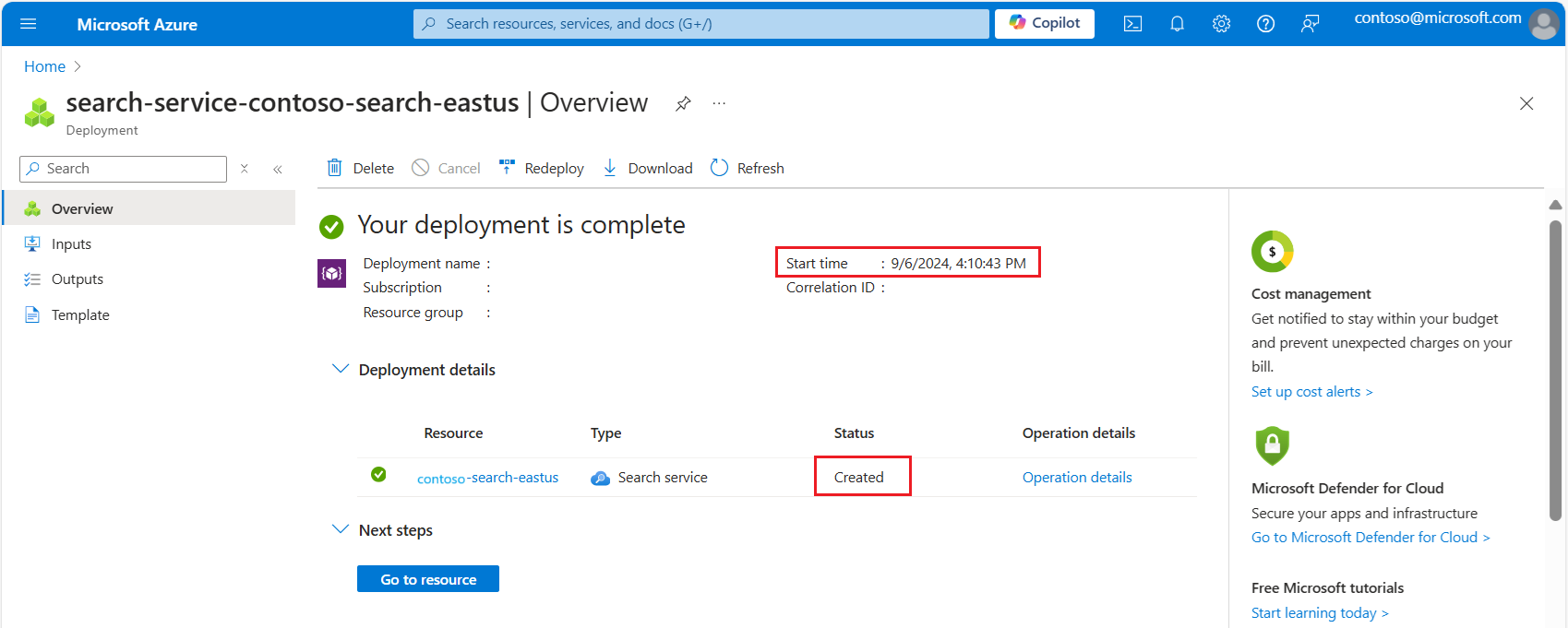
Agora que você sabe a idade do seu serviço de pesquisa, revise os limites de cota do vetor com base na criação do serviço: Limites de tamanho do índice do vetor.


Como obter o tamanho do índice de vetor
Uma solicitação de métricas de vetor é uma operação de plano de dados. Você pode usar o portal do Azure, as APIs REST ou os SDKs do Azure para obter o uso de vetores no nível do serviço por meio de estatísticas de serviço e para índices individuais.
As informações de uso podem ser encontradas na guia Uso da página Visão Geral. As páginas do portal são atualizadas a cada poucos minutos, portanto, se você atualizou recentemente um índice, aguarde um pouco antes de verificar os resultados.
A captura de tela a seguir é para um serviço de pesquisa Standard 1 (S1) mais antigo, configurado para uma partição e uma réplica.
- A cota de armazenamento é uma restrição de disco e inclui todos os índices (vetor e não vetor) em um serviço de pesquisa.
- A cota de tamanho do índice vetor é uma restrição de memória. É a quantidade de memória necessária para carregar todos os índices de vetor internos criados para cada campo de vetor em um serviço de pesquisa.
A captura de tela indica que os índices (vetor e não vetor) consomem quase 460 megabytes de armazenamento em disco disponível. Os índices de vetor consomem quase 93 megabytes de memória no nível do serviço.

As cotas para o armazenamento e o tamanho do índice vetor aumentam ou diminuem à medida que você adiciona ou remove partições. Se você alterar a contagem de partições, o bloco mostrará uma alteração correspondente no armazenamento e na cota de vetor.
Observação
No disco, os índices de vetor não são 93 megabytes. Os índices de vetor no disco ocuparão cerca de três vezes mais espaço do que os índices de vetor na memória. Consulte Como os campos de vetor afetam o armazenamento em disco para obter detalhes.
Fatores que afetam o tamanho do índice de vetor
Há três componentes principais que afetam o tamanho do índice de vetor interno:
- Tamanho bruto dos dados
- Sobrecarga do algoritmo selecionado
- Sobrecarga da exclusão ou atualização de documentos no índice
Tamanho bruto dos dados
Cada vetor é geralmente uma matriz de números de ponto flutuante de precisão simples, em um campo do tipo Collection(Edm.Single).
As estruturas de dados de vetor exigem armazenamento, representadas no cálculo a seguir como o "tamanho bruto" de seus dados. Use esse tamanho bruto para estimar os requisitos de tamanho do índice de vetor de seus campos de vetor.
O tamanho do armazenamento de um vetor é determinado por sua dimensionalidade. Multiplique o tamanho de um vetor pelo número de documentos que contêm esse campo de vetor para obter o tamanho bruto:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| Tipo de dados EDM | Tamanho do tipo de dados |
|---|---|
Collection(Edm.Single) |
4 bytes |
Collection(Edm.Half) |
2 bytes |
Collection(Edm.Int16) |
2 bytes |
Collection(Edm.SByte) |
1 byte |
Sobrecarga de memória do algoritmo selecionado
Cada algoritmo vizinho mais próximo aproximado (ANN) gera estruturas de dados adicionais na memória para habilitar a pesquisa eficiente. Essas estruturas consomem espaço extra na memória.
Para o algoritmo HNSW, a sobrecarga de memória varia entre 1% e 20%.
A sobrecarga de memória é menor para dimensões mais altas porque o tamanho bruto dos vetores aumenta, enquanto as estruturas de dados extras permanecem um tamanho fixo, pois armazenam informações sobre a conectividade no grafo. Consequentemente, a contribuição das estruturas de dados extras constitui uma parte menor do tamanho geral.
A sobrecarga de memória é maior para valores maiores do parâmetro HNSW m, que determina o número de links bidirecionais criados para cada novo vetor durante a construção do índice. Isso ocorre porque m contribui com aproximadamente 8 a 10 bytes por documento multiplicados por m.
A tabela a seguir resume os percentuais de sobrecarga observados em testes internos:
| Dimensões | Parâmetro HNSW (m) | Porcentagem de sobrecarga |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8% |
| 768 | 4 | %2 |
| 1536 | 4 | %1 |
| 3072 | 4 | 0,5% |
Esses resultados demonstram a relação entre as dimensões, o parâmetro HNSW m e a sobrecarga de memória para o algoritmo HNSW.
Sobrecarga da exclusão ou atualização de documentos no índice
Quando um documento com um campo de vetor é excluído ou atualizado (as atualizações são representadas internamente como uma operação de exclusão e inserção), o documento subjacente é marcado como excluído e ignorado durante as consultas subsequentes. À medida que novos documentos são indexados e o índice de vetor interno aumenta, o sistema limpa esses documentos excluídos e recupera os recursos. Isso significa que você provavelmente observará um atraso entre a exclusão de documentos e os recursos subjacentes que estão sendo liberados.
Chamamos isso de taxa de documentos excluídos. Como a taxa de documentos excluídos depende das características de indexação do seu serviço, não há heurística universal para estimar esse parâmetro e não há nenhuma API ou script que retorne a taxa em vigor para seu serviço. Observamos que metade de nossos clientes tem uma taxa de documentos excluídos inferior a 10%. Se você costuma executar exclusões ou atualizações de alta frequência, poderá observar uma maior taxa de documentos excluídos.
Esse é outro fator que afeta o tamanho do índice de vetor. Infelizmente, não temos um mecanismo para exibir a taxa atual de documentos excluídos.
Estimando o tamanho total dos dados na memória
Levando em conta os fatores descritos anteriormente, use o seguinte cálculo para estimar o tamanho total do índice de vetor:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
Por exemplo, para calcular o raw_size, vamos supor que você esteja usando um modelo popular do OpenAI do Azure, text-embedding-ada-002 com 1.536 dimensões. Isso significa que um documento consumiria 1.536 Edm.Single (floats) ou 6.144 bytes, uma vez que cada Edm.Single é de 4 bytes. 1.000 documentos com um único campo de vetor com 1.536 dimensões consumiriam no total 1000 docs x 1536 floats/doc = 1.536.000 floats ou 6.144.000 bytes.
Se você tiver vários campos de vetor, precisará executar esse cálculo para cada campo de vetor em seu índice e somá-los. Por exemplo, 1.000 documentos com dois campos de vetor com 1.536 dimensões, consomem 1.000 docs x 2 campos x 1536 floats/doc x 4 bytes/float = 12.288.000 bytes.
Para obter o tamanho do índice de vetor, multiplique raw_size pela sobrecarga do algoritmo e taxa de documentos excluídos. Se a sobrecarga do algoritmo para os parâmetros HNSW escolhidos for de 10% e a taxa de documentos excluídos for de 10%, teremos: 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB.
Como os campos de vetor afetam o armazenamento em disco
A maioria deste artigo fornece informações sobre o tamanho dos vetores na memória. Se você quiser saber sobre o tamanho do vetor no disco, o consumo de disco para dados de vetor é aproximadamente três vezes o tamanho do índice de vetor na memória. Por exemplo, se o uso de vectorIndexSize estiver em 100 megabytes (10 milhões de bytes), você teria usado pelo menos 300 megabytes de storageSize cota para acomodar seus índices de vetor.