Monitorar a integridade de seus conectores de dados
Para garantir a ingestão completa e ininterrupta de dados em seu serviço do Microsoft Sentinel, acompanhe a integridade, a conectividade e o desempenho dos conectores de dados.
Os recursos a seguir permitem realizar esse monitoramento por meio do Microsoft Sentinel:
Pasta de trabalho de monitoramento de integridade da coleta de dados: oferece monitores adicionais, detecta anomalias e fornece insights sobre o status de ingestão de dados do workspace. Você pode usar a lógica da pasta de trabalho para monitorar a integridade geral dos dados ingeridos e para criar exibições personalizadas e alertas baseados em regras.
Tabela de dados do SentinelHealth (versão prévia): consultar essa tabela fornece informações sobre desvios de integridade, como eventos de falha mais recentes por conector ou conectores com alterações de estados de sucesso a falhas, que é possível usar para criar alertas e outras ações automatizadas. Atualmente, a tabela de dados SentinelHealth tem suporte apenas para conectores de dados selecionados.
Importante
A tabela de dados SentinelHealth está atualmente em VERSÃO PRÉVIA. Veja os Termos de Uso Complementares para Versões Prévias do Microsoft Azure para termos legais adicionais que se aplicam aos recursos do Azure que estão em versão beta, versão prévia ou que, de outra forma, ainda não foram lançados em disponibilidade geral.
Exibir a integridade e o status dos sistemas SAP conectados: examine as informações de integridade dos sistemas SAP no conector de dados SAP e use um modelo de regra de alerta para obter informações sobre a integridade da coleta de dados do agente SAP.
Usar a pasta de trabalho de monitoramento de integridade
Para começar, instale a Pasta de trabalho de monitoramento de integridade da coleta de dados do Hub de conteúdo e exiba ou crie uma cópia do modelo na seção Pastas de Trabalho do Microsoft Sentinel.
Para o Microsoft Sentinel no portal do Azure, em Gerenciamento de conteúdo, selecione o Hub de conteúdo.
Para o Microsoft Sentinel no portal do Defender, selecione Microsoft Sentinel>Gerenciamento de conteúdo>Hub de conteúdo.Em Hub de conteúdo, digite integridade na barra de pesquisa e selecione Monitoramento de integridade da coleta de dados nos resultados.
Selecione Instalar no painel de detalhes. Quando você receber uma mensagem de notificação informando que a pasta de trabalho está instalada ou Configuração for exibido em vez de Instalar, prossiga para a próxima etapa.
No Microsoft Sentinel, em Gerenciamento de ameaças, selecione Pastas de trabalho.
Na página Pastas de trabalho, selecione a guia Modelos, digite integridade na barra de pesquisa e selecione Monitoramento de integridade da coleta de dados nos resultados.
Selecione o Modelo de exibição para usar a pasta de trabalho como está ou selecione Salvar para criar uma cópia editável da pasta de trabalho. Quando a cópia for criada, selecione Exibir pasta de trabalho salva.
Uma vez na pasta de trabalho, selecione a assinatura e o espaço de trabalho que você deseja exibir e defina o TimeRange para filtrar os dados de acordo com suas necessidades. Use a alternância Mostrar ajuda para exibir a explicação in-loco da pasta de trabalho.
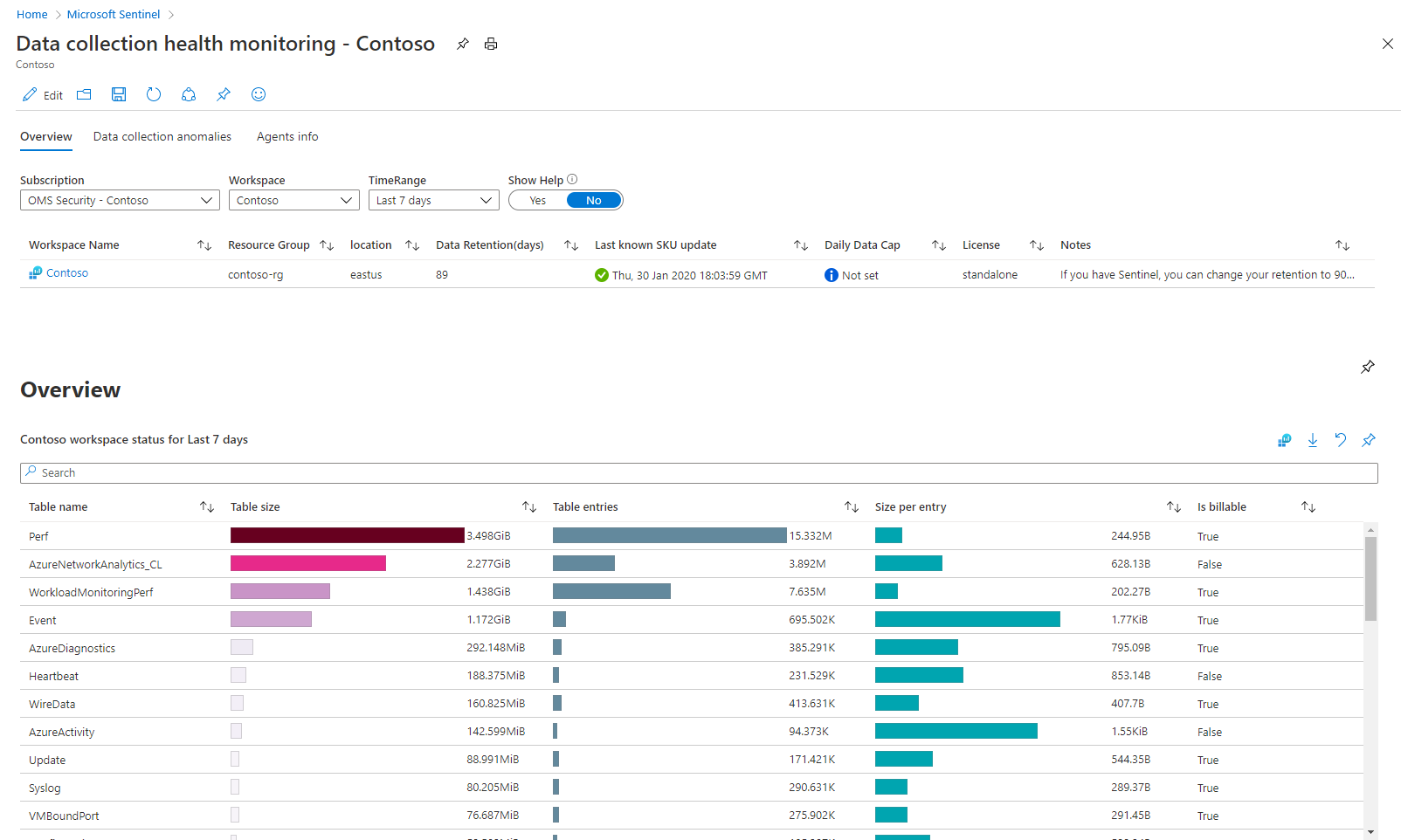

Há três seções com guias nessa pasta de trabalho:
A guia Visão geral mostra o status geral da ingestão de dados no espaço de trabalho selecionado: medidas de volume, taxas de EPS e hora em que o último log foi recebido.
A guia Anomalias de coleta de dados ajudará você a detectar anomalias no processo de coleta de dados, por tabela e fonte de dados. Cada guia apresenta anomalias para uma determinada tabela (a guia Geral inclui uma coleção de tabelas). As anomalias são calculadas usando a função series_decompose_anomalies() que retorna uma pontuação de anomalias. Saiba mais sobre essa função. Defina os seguintes parâmetros para a função a ser avaliada:
AnomaliesTimeRange: este seletor de tempo aplica-se somente à exibição de anomalias de coleta de dados.
SampleInterval: o intervalo de tempo no qual os dados são amostrados no intervalo de tempo determinado. A pontuação de anomalias é calculada somente nos dados do último intervalo.
PositiveAlertThreshold: este valor define o limite positivo da pontuação de anomalias. Ele aceita valores decimais.
NegativeAlertThreshold: este valor define o limite negativo da pontuação de anomalias. Ele aceita valores decimais.

A guia Informações do agente mostra informações sobre a integridade dos agentes instalados em seus vários computadores, seja uma VM do Azure, uma VM de nuvem, uma VM local ou um ambiente físico. Monitore a localização do sistema, o status da pulsação e da latência, a memória e o espaço em disco disponíveis e as operações do agente.
Nesta seção, selecione a guia que descreve o ambiente dos seus computadores: escolha a guia Computadores gerenciados pelo Azure para exibir apenas os computadores gerenciados pelo Azure Arc e escolha a guia Todos os computadores para exibir tanto os computadores gerenciados pelo Azure quanto aqueles que não são gerenciados por ele e que têm o agente do Azure Monitor instalado.



Usar a tabela de dados do SentinelHealth (versão prévia pública)
Para obter dados de integridade do conector de dados da tabela de dados SentinelHealth, você precisa primeiro ativar o recurso de integridade do Microsoft Sentinel para seu workspace. Para obter mais informações, consulte Ativar o monitoramento de integridade do Microsoft Sentinel.
Depois que o recurso de integridade for ativado, a tabela de dados SentinelHealth será criada no primeiro evento de êxito ou falha gerado para os conectores de dados.
Conectores de dados com suporte
Atualmente, a tabela de dados SentinelHealth tem suporte apenas para os seguintes conectores de dados:
- Amazon Web Services (CloudTrail e S3)
- Dynamics 365
- Office 365
- Microsoft Defender para ponto de extremidade
- Inteligência contra ameaças – TAXII
- Plataformas de Inteligência contra Ameaças
- Qualquer conector baseado em Codeless Connector Platform
Noções básicas sobre os eventos da tabela SentinelHealth
Os seguintes tipos de eventos de integridade são registrados na tabela SentinelHealth:
Alteração do status de busca de dados. Registrado uma vez por hora, desde que o status do conector de dados permaneça estável, com eventos de êxito ou falha contínuos. Desde que o status de um conector de dados não mude, o monitoramento a cada hora funcionará para evitar a auditoria redundante e reduzir o tamanho da tabela. Se o status do conector de dados tiver falhas contínuas, detalhes adicionais sobre as falhas serão incluídos na coluna ExtendedProperties.
Se o status do conector de dados for alterado, de êxito para falha, de falha para êxito ou se houver alterações nos motivos da falha, o evento será registrado imediatamente para permitir que sua equipe realize uma ação proativa e imediata.
Erros potencialmente transitórios, como a limitação do serviço de origem, são registrados somente depois de continuarem por mais de 60 minutos. Esses 60 minutos permitem que o Microsoft Sentinel supere um problema transitório no back-end e acompanhe os dados, sem a necessidade de nenhuma ação do usuário. Os erros que são definitivamente não transitórios são registrados imediatamente.
Resumo de falha. Registrado uma vez por hora, por conector, por workspace, com um resumo de falha agregado. Os eventos de resumo de falha são criados somente quando o conector sofreu erros de sondagem durante a hora em questão. Eles contêm os detalhes adicionais fornecidos na coluna ExtendedProperties, como o período de tempo para o qual a plataforma de origem do conector foi consultada e uma lista distinta de falhas encontradas durante o período de tempo.
Para obter mais informações, confira esquema de colunas da tabela SentinelHealth.
Executar consultas para detectar descompassos de integridade
Crie consultas na tabela SentinelHealth para ajudar você a detectar descompassos de integridade em seus conectores de dados. Por exemplo:
Detectar eventos de falha mais recentes por conector:
SentinelHealth
| where TimeGenerated > ago(3d)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId
| where Status == 'Failure'
Detectar conectores com alterações no estado de falha para êxito:
let lastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextToLastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (lastestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
lastestStatus
| join kind=inner (nextToLastestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Failure' and LastStatus == 'Success'
Detectar conectores com alterações no estado de êxito para falha:
let lastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| project TimeGenerated, SentinelResourceName, SentinelResourceId, LastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
let nextToLastestStatus = SentinelHealth
| where TimeGenerated > ago(12h)
| where OperationName == 'Data fetch status change'
| where Status in ('Success', 'Failure')
| join kind = leftanti (lastestStatus) on SentinelResourceName, SentinelResourceId, TimeGenerated
| project TimeGenerated, SentinelResourceName, SentinelResourceId, NextToLastStatus = Status
| summarize TimeGenerated = arg_max(TimeGenerated,*) by SentinelResourceName, SentinelResourceId;
lastestStatus
| join kind=inner (nextToLastestStatus) on SentinelResourceName, SentinelResourceId
| where NextToLastStatus == 'Success' and LastStatus == 'Failure'
Configurar alertas e ações automatizadas para problemas de integridade
Embora você possa usar as regras de análise do Microsoft Sentinel para configurar a automação nos logs do Microsoft Sentinel, se quiser ser notificado e tomar uma ação imediata para descompassos de integridade em seus conectores de dados, recomendamos que você use as regras de alerta do Azure Monitor.
Por exemplo:
Em uma regra de alerta Azure Monitor, selecione seu workspace do Microsoft Sentinel como o escopo da regra e a Pesquisa de logs personalizada como a primeira condição.
Personalize a lógica de alerta conforme necessário, como frequência ou duração de lookback e, em seguida, use consultas para pesquisar descompassos de integridade.
Para as ações de regra, selecione um grupo de ações existente ou crie um, conforme necessário, para configurar notificações por push ou outras ações automatizadas, como disparar um aplicativo lógico, webhook ou Função do Azure no sistema.
Para obter mais informações, confira Visão geral de alertas do Azure Monitor e Log de alertas do Azure Monitor.
Próximas etapas
- Saiba mais sobre a auditoria e o monitoramento de integridade no Microsoft Sentinel.
- Ative a auditoria e o monitoramento de integridade no Microsoft Sentinel.
- Monitore a integridade de suas regras de automação e guias estratégicos.
- Monitore a integridade das suas regras de análise.
- Confira mais informações sobre os esquemas de tabela SentinelHealth e SentinelAudit.