Tutorial: Capturar dados dos Hubs de Eventos no formato parquet e analisar com Azure Synapse Analytics
Esse tutorial mostra como usar o editor sem código do Stream Analytics para criar um trabalho que captura dados dos Hubs de Eventos para o Azure Data Lake Storage Gen2 no formato parquet.
Neste tutorial, você aprenderá como:
- Implantar um gerador de eventos que envia dados de amostra para um hub de eventos
- Criar um trabalho do Stream Analytics com o editor sem código
- Examinar os dados de entrada e o esquema
- Configurar o Azure Data Lake Storage Gen2 no qual os dados do hub de eventos serão capturados
- Executar o trabalho do Stream Analytics
- Usar o Azure Synapse Analytics para consultar os arquivos parquet
Pré-requisitos
Antes de começar, verifique se você concluiu as seguintes etapas:
- Se você não tiver uma assinatura do Azure, crie uma conta gratuita.
- Implante o aplicativo gerador de eventos TollApp no Azure. Defina o parâmetro "interval" como 1 e use um novo grupo de recursos para esta etapa.
- Crie um workspace do Azure Synapse Analytics com uma conta do Data Lake Storage Gen2.
Usar o editor sem código para criar um trabalho do Stream Analytics
Localize o Grupo de Recursos no qual o gerador de eventos TollApp foi implantado.
Selecione o namespace Hubs de Eventos do Azure.
Na página Namespace de Hubs de Eventos, selecione Hubs de Eventos em Entidades no menu à esquerda.
Selecione a instância
entrystream.
Na página Instância dos Hubs de Eventos, selecione Processar dados na seção Recursos do menu à esquerda.
Selecione Iniciar no bloco Capturar dados no ADLS Gen2 no formato parquet.

Nomeie o trabalho
parquetcapturee selecione Criar.
Na página de configuração do hub de eventos, confirme as configurações a seguir e selecione Conexão.
Grupo de Consumidores: padrão
Tipo de serialização dos dados de entrada: JSON
Modo de autenticação que o trabalho usará para se conectar ao hub de eventos: cadeia de conexão.

Em poucos segundos, você verá os dados de entrada de exemplo e o esquema. Você pode optar por descartar campos, renomear campos ou alterar o tipo de dados.

Selecione o bloco Azure Data Lake Storage Gen2 na tela e configure-o especificando:
- Assinatura em que a conta do Azure Data Lake Gen2 está localizada.
- Nome da conta de armazenamento, que deve ser a mesma conta do ADLS Gen2 usada com seu workspace do Azure Synapse Analytics feito na seção Pré-requisitos.
- Contêiner no qual os arquivos parquet serão criados.
- Padrão de caminho definido como {date}/{time}.
- O padrão de data e hora como o aaaa-mm-dd e HH.
- Selecione Conectar

Selecione Salvar na faixa de opções superior para salvar seu trabalho e selecione Iniciar para executá-lo. Depois que o trabalho for iniciado, selecione X no canto direito para fechar a página de trabalho do Stream Analytics.

Em seguida, você verá uma lista de todos os trabalhos do Stream Analytics criados com o editor sem código. E em dois minutos, seu trabalho irá para um estado Em execução. Selecione o botão Atualizar na página para ver o status mudando de Criado –> Iniciando –> Em execução.









Exibir a saída na conta do Azure Data Lake Storage Gen 2
Localize a conta do Azure Data Lake Storage Gen2 que você usou na etapa anterior.
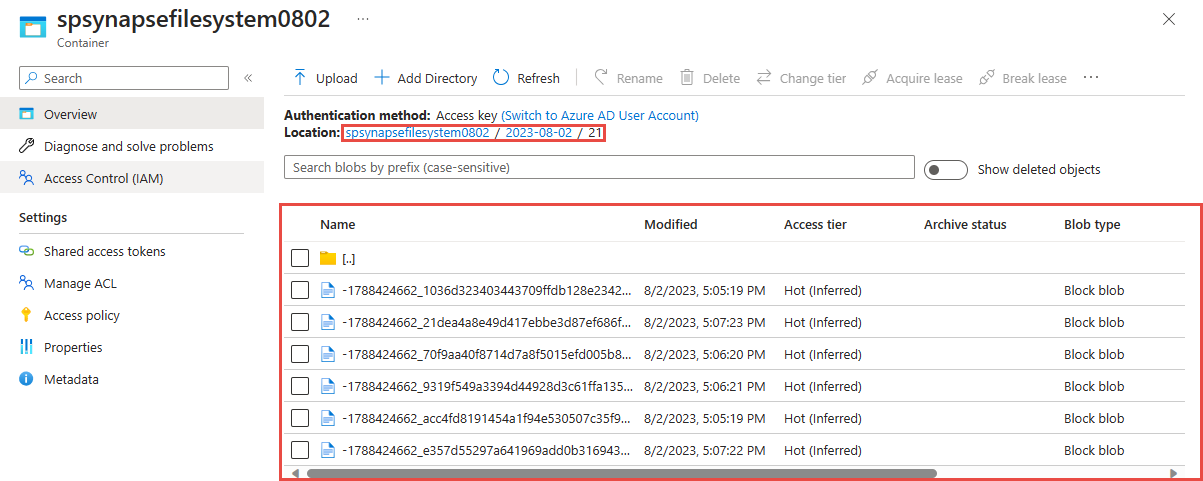
Selecione o contêiner que você usou na etapa anterior. Você verá arquivos parquet criados com base no padrão de caminho {date}/{time} usado na etapa anterior.
Consultar dados capturados no formato parquet com o Azure Synapse Analytics
Consultar usando o Spark do Azure Synapse
Localize seu workspace do Azure Synapse Analytics e abra o Synapse Studio.
Crie um pool do Spark no Apache sem servidor no seu workspace, se ainda não existir.
No Synapse Studio, acesse o hub Desenvolver e crie um Notebook.
Crie uma célula de código e cole o código a seguir nela. Substitua container e adlsname pelo nome do contêiner e pela conta do ADLS Gen2 usada na etapa anterior.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Para Anexar a na barra de ferramentas, selecione o Pool do Spark na lista de seleção.
Selecione Executar Tudo para ver os resultados.


Consultar usando SQL sem servidor do Azure Synapse
No hub Desenvolver, crie um Script SQL.
Cole o script a seguir e Execute usando o ponto de extremidade de SQL sem servidor interno. Substitua container e adlsname pelo nome do contêiner e pela conta do ADLS Gen2 usada na etapa anterior.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]

Limpar os recursos
- Localize sua instância dos Hubs de Eventos e veja a lista de trabalhos do Stream Analytics na seção Dados do Processo. Interrompa quaisquer trabalhos em execução.
- Vá para o grupo de recursos usado durante a implantação do gerador de eventos TollApp.
- Selecione Excluir grupo de recursos. Digite o nome do grupo de recursos para confirmar a exclusão.
Próximas etapas
Neste tutorial, você aprendeu a criar um trabalho do Stream Analytics usando o editor sem código para capturar fluxos de dados dos Hubs de Eventos no formato parquet. Em seguida, você usou o Azure Synapse Analytics para consultar os arquivos parquet usando o Spark do Synapse e o SQL do Synapse.